オンラインからの利用を想定したDatabricksの性能検証
こんにちは、NRIデジタルの湯川です。
Azure Databricksはビッグデータ分析サービスですが、その活用のためのリファレンスアーキテクチャとして、Microsoftのドキュメントには以下の異なる2つのパターンの記載があります。
パターン1:分析レポート環境用のデータストアにCosmos DBなどDatabricks以外のサービスを利用する
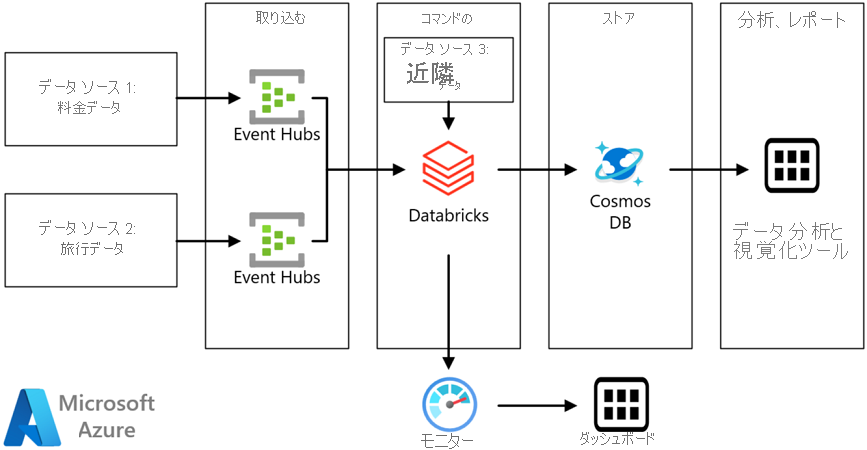
Databricks によるストリーム処理 – Azure Reference Architectures
パターン2:分析レポート環境からDatabricksに直接SQLクエリを投げる(下記図の⑥+⑦)
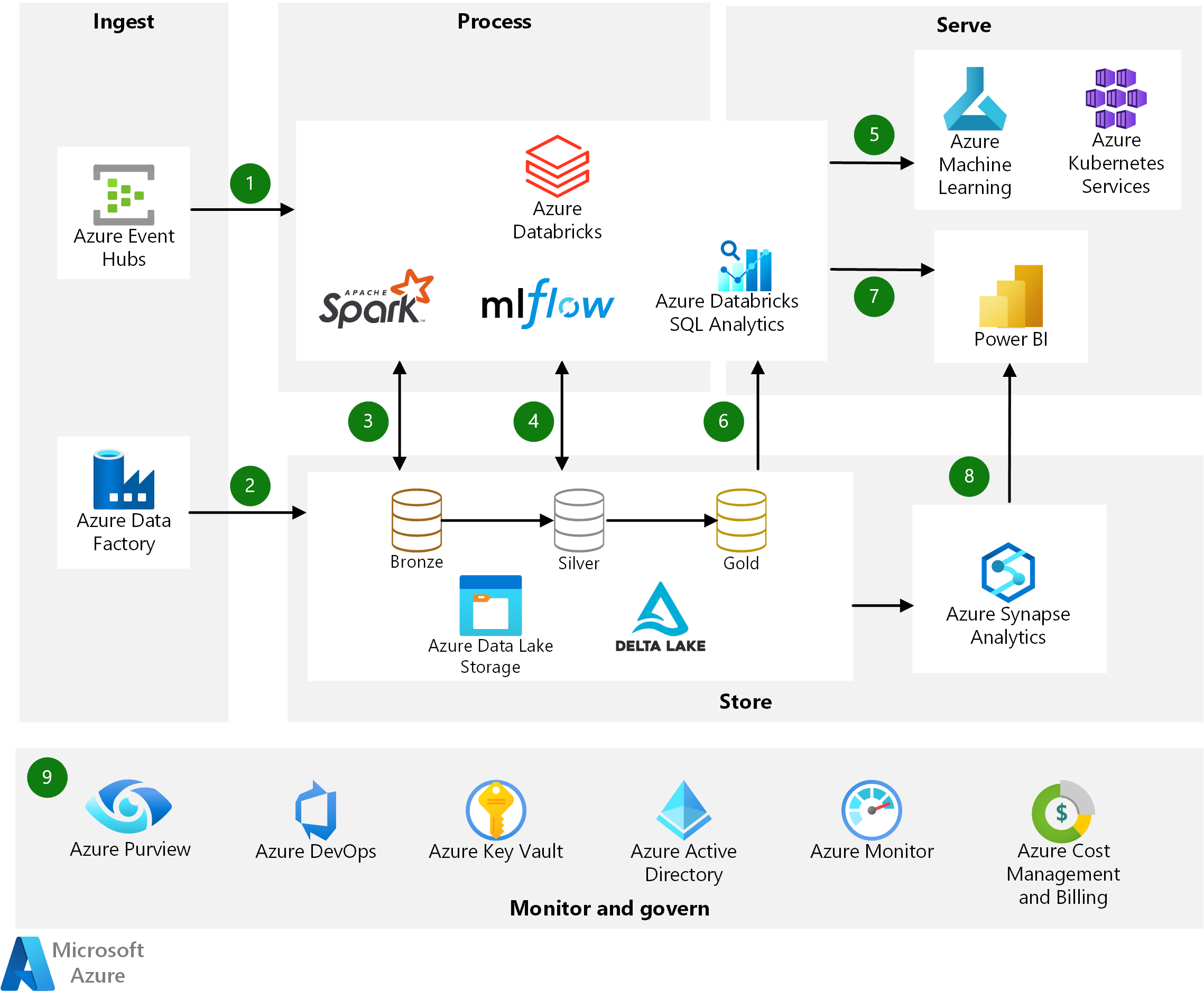
Azure Databricks を使用した最新の分析アーキテクチャ – Azure Architecture Center
オンラインシステムからクエリを受け付けるという場合、パターン1のように加工後、頻繁に利用するデータはCosmos DBやSQL Databaseのようなオンラインからの利用に強いDBに持たせるのではなく、パターン2のように「Databricksに直接SQLクエリで問い合わせを行った場合、どの程度の応答性能とスループットが出せるのか?」が今回のテーマです。
目次
Azure Databricksとは
Azure Databricks はApache Spark ベースのビッグ データ分析サービスです。
Azureの場合、Sparkベースのビッグデータ分析はDatabricks以外にもAzure Synapse AnalyticsとAzure HDInsightがあります。Sparkの生みの親であるMatei Zaharia氏らが設立したDatabricks社とMicrosoftが、協業して提供しているAzureのファーストパーティサービスがAzure Databricksです。
Databricks社は数年遅れで自社で開発した新機能をOSS化しているものの、Photon※など最新の機能を持ったSpark環境を使いたい場合はDatabricks社が提供しているAzure Databricks(以降、Databricksと記載した場合はサービスを指します)を選択することになります。
※PhotonはSparkを高速化するC++で開発されたベクトライズドエンジンです。PhotonについてはDatabricksの弥生さんが紹介記事を書かれていますのでこちらを参照ください。
Photonエンジン:Databricksレイクハウスプラットフォームにおける次世代クエリーエンジン – Qiit
想定環境
以下の図のように、AKSなどKubernetes上で動作するSpring Bootのアプリケーションから、JDBCでDatabricksに接続し、Delta Lake※に保存されたデータに対してアクセスするケースを想定します。
※Delta LakeはParquetファイルにトランザクションログ(Delta Log)を追加することで、トランザクションやMVCCを実現したものです。
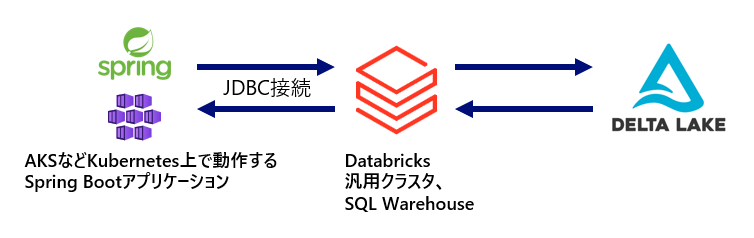
性能検証の観点
今回はオンラインシステムから普通のDBのように扱う場合を想定し、以下を前提としました。
- 応答時間を測定する。許容できる最大応答時間は5秒とする
- スループットを測定する。一部の限られたデータ分析担当者ではなく多数の人が利用する場合を想定
5秒以上の待ち時間を許容できるケースも、限られた人しか利用しないケースもあると思いますが、汎用的に利用できると言えるかどうかの判断基準として上記を条件としています。
Databricks環境準備
Azureの東日本リージョンにDatabricksのワークスペース※1を用意し、汎用クラスタ※2とSQL Warehouse※3をポータルから作成します。
※1 ワークスペースはDatabricksの各種リソースを束ねる論理的な枠組みです。Databricksの各種リソースはワークスペースを経由して操作します。
※2 汎用クラスタは汎用的なSparkジョブを実行するためのクラスタです。
※3 SQL WarehouseもSparkジョブを実行するクラスタですが、SQLを使った操作に特化しています。
汎用クラスタは以下の画面で、PolicyをUnrestrictedに設定して作成しました。
SQL Warehouseは以下の画面から作成しています。
どちらもクラスタを作成すると、JDBCドライバで接続するためのエンドポイント情報が表示されます。
汎用クラスタの場合はAdvanced optionsにJDBC/ODBCというタブがあるので選択し、JDBC URLの2.6.25 or laterを選びます。以下のキャプチャでは消しています。
SQL Warehouseの場合はConntection detailsに表示されます。以下のキャプチャでは消しています。
接続文字列にはトークンが必要なので、User SettingsからGenerate new tokenを選択し、トークンを作成します。
JDBCドライバはbuild.gradleに以下のように記載し、Spring Boot+Mybatisから利用するようにしました。
springboot-databricks-rest-api-master.zip
HikariCPのコネクション数は30にしています。
implementation 'com.databricks:databricks-jdbc:2.6.32'
Javaの起動時に以下のオプションがないとJDBCの初期化に失敗するので追加します。
--add-opens=java.base/java.nio=ALL-UNNAMED
検証データ
検証に使用するデータはSynapse Link for SQLの検証をした時のデータを流用することにしました。
Azure SQL Databaseに以下のテーブルを定義し、sys.objectsを増幅させてテストデータとしています。
件数は1000万件です。
CREATE TABLE [dbo].[test_data_10000000]( [name] [sysname] NOT NULL, [object_id] [int] NOT NULL, [principal_id] [int] NULL, [schema_id] [int] NOT NULL, [parent_object_id] [int] NOT NULL, [type] [char](2) NULL, [type_desc] [nvarchar](60) NULL, [create_date] [datetime] NOT NULL, [modify_date] [datetime] NOT NULL, [is_ms_shipped] [bit] NOT NULL, [is_published] [bit] NOT NULL, [is_schema_published] [bit] NOT NULL, [id] [bigint] IDENTITY(1,1) NOT NULL, pkey AS (id % 10) PERSISTED --計算列を定義する場合 CONSTRAINT [pk_test_data] PRIMARY KEY CLUSTERED ( [id] ASC ));
Azure SQL DatabaseのデータをDelta Tableに取り込みます。この作業はDatabricksノートブックを使って実行しました。
まずは外部テーブルとして、SQL Server上のテーブルを定義します。
CREATE TABLE sqldb USING org.apache.spark.sql.jdbc OPTIONS ( url "jdbc:sqlserver://sql-synapsepoc.database.windows.net:1433;database=sqldb-dev-synapsepoc;selectMethod=cursor;", dbtable "[dbo].[test_data_10000000]", user "xxxxxxxxxxxxxxxxxxxxxxx", password "xxxxxxxxxxxxxxxxxxxx" )
Delta Tableを定義します。
CREATE TABLE testdata (name string, object_id int, principal_id int, schema_id int, parent_object_id int, type string, type_desc string, create_date timestamp, modify_date timestamp, is_ms_shipped boolean, is_published boolean, is_schema_published boolean, id bigint );
Delta Tableに流し込みます。
MERGE INTO default.testdata
USING sqldb
ON testdata.object_id = sqldb.object_id
WHEN MATCHED THEN
UPDATE SET
id = sqldb.id,
name = sqldb.name,
object_id = sqldb.object_id,
principal_id = sqldb.principal_id,
schema_id = sqldb.schema_id,
parent_object_id = sqldb.parent_object_id,
type = sqldb.type,
type_desc = sqldb.type_desc,
create_date = sqldb.create_date,
modify_date = sqldb.modify_date,
is_ms_shipped = sqldb.is_ms_shipped,
is_published = sqldb.is_published,
is_schema_published = sqldb.is_schema_published
WHEN NOT MATCHED
THEN INSERT
(id, name, object_id, principal_id, schema_id, parent_object_id, type, type_desc, create_date, modify_date, is_ms_shipped, is_published, is_schema_published)
VALUES (
sqldb.id,
sqldb.name,
sqldb.object_id,
sqldb.principal_id,
sqldb.schema_id,
sqldb.parent_object_id,
sqldb.type,
sqldb.type_desc,
sqldb.create_date,
sqldb.modify_date,
sqldb.is_ms_shipped,
sqldb.is_published,
sqldb.is_schema_published
)
以上でデータの準備ができました。
性能測定
単純にレコードを1行持ってくる場合
以下のような非常に単純なSQLで応答時間とスループットを確認してみます。
パラメータはJavaのコード内でランダムになるようにして、Apache Benchを使って負荷をかけました。
SELECT id, name, object_id, principal_id, schema_id, parent_object_id, type, type_desc, is_ms_shipped, is_published, is_schema_published FROM default.testdata WHERE id = #{id}
汎用クラスタ
Photonを有効にしていない場合は通常時でも応答に1秒程度かかるようです。
Photonを有効にすることで、応答時間は500-600ms程度に短縮されました。
D4sv51台(Photon有効)の場合、秒間の処理件数は5.25程度で頭打ちになるようです。
D4sv5は4コア16GBメモリのVMですが、これをD8sv5(8コア32GBメモリ)のVMにスケールアップしても、台数を2倍に増やしても、秒間の処理件数はほぼ単純に倍になりました。
| No. | Pho ton |
VM数 | VM タイプ |
並列度 | リクエ スト数 |
リクエ スト/秒 |
50% | 90% | 95% | 100% |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | ON | 1 | D4sv5 | 1 | 100 | 1.8 | 548 | 590 | 615 | 713 |
| 2 | ON | 1 | D4sv5 | 2 | 100 | 3.22 | 602 | 664 | 718 | 756 |
| 3 | ON | 1 | D4sv5 | 3 | 100 | 4.24 | 677 | 753 | 774 | 914 |
| 4 | ON | 1 | D4sv5 | 4 | 100 | 4.91 | 766 | 880 | 961 | 1006 |
| 5 | ON | 1 | D4sv5 | 5 | 100 | 5.12 | 924 | 1042 | 1072 | 1388 |
| 6 | ON | 1 | D4sv5 | 6 | 100 | 5.24 | 1088 | 1246 | 1356 | 1785 |
| 7 | ON | 1 | D4sv5 | 7 | 100 | 5.23 | 1234 | 1548 | 1673 | 2753 |
| 8 | OFF | 1 | D4sv5 | 1 | 100 | 1.03 | 976 | 1022 | 1035 | 1155 |
| 9 | OFF | 1 | D4sv5 | 2 | 100 | 1.91 | 1020 | 1119 | 1165 | 1325 |
| 10 | OFF | 1 | D4sv5 | 3 | 100 | 2.48 | 1175 | 1282 | 1320 | 1651 |
| 11 | OFF | 1 | D4sv5 | 4 | 100 | 2.94 | 1292 | 1404 | 1523 | 1732 |
| 12 | OFF | 1 | D4sv5 | 5 | 100 | 3.27 | 1414 | 1657 | 1817 | 2833 |
| 13 | OFF | 1 | D4sv5 | 6 | 100 | 3.27 | 1629 | 2256 | 2345 | 2435 |
| 14 | ON | 1 | D8sv5 | 1 | 100 | 1.71 | 549 | 600 | 627 | 865 |
| 15 | ON | 1 | D8sv5 | 3 | 100 | 4.93 | 577 | 619 | 653 | 890 |
| 16 | ON | 1 | D8sv5 | 6 | 100 | 7.79 | 707 | 804 | 860 | 916 |
| 17 | ON | 1 | D8sv5 | 9 | 100 | 8.89 | 905 | 1061 | 1093 | 1477 |
| 18 | ON | 1 | D8sv5 | 10 | 100 | 9.74 | 921 | 1074 | 1178 | 1472 |
| 19 | ON | 1 | D8sv5 | 11 | 100 | 9.76 | 999 | 1184 | 1280 | 1805 |
| 20 | ON | 1 | D8sv5 | 12 | 100 | 8.13 | 1155 | 1450 | 1643 | 3741 |
| 21 | ON | 2 | D4sv5 | 1 | 100 | 1.75 | 559 | 605 | 635 | 846 |
| 22 | ON | 2 | D4sv5 | 3 | 100 | 4.76 | 595 | 691 | 763 | 855 |
| 23 | ON | 2 | D4sv5 | 6 | 100 | 8 | 669 | 655 | 973 | 1079 |
| 24 | ON | 2 | D4sv5 | 9 | 100 | 9.88 | 788 | 1027 | 1135 | 1281 |
| 25 | ON | 2 | D4sv5 | 10 | 100 | 10.61 | 791 | 1115 | 1156 | 1702 |
| 26 | ON | 2 | D4sv5 | 11 | 100 | 10.51 | 897 | 1140 | 1208 | 1764 |
| 27 | ON | 2 | D4sv5 | 12 | 100 | 11.05 | 926 | 1093 | 1274 | 1603 |
SQL Warehouse
SQL WarehouseにはPhotonの有効無効という選択肢がなく、クラスターサイズと台数のみを選択します。
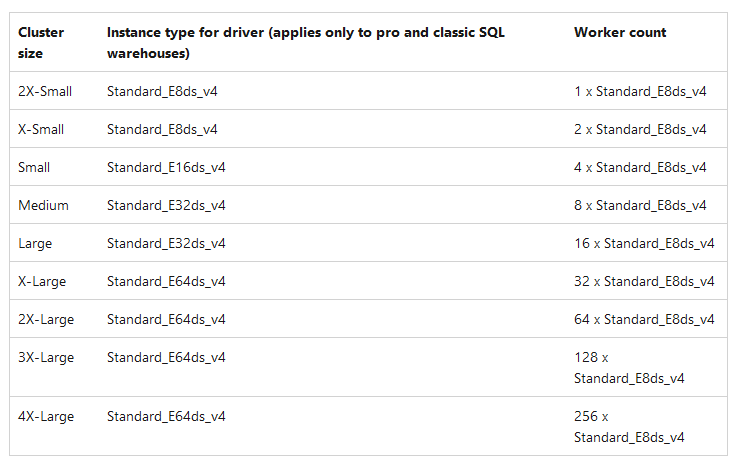
今回、クラスターサイズは最小の2X-Smallのみを試しました。Azureのドキュメントによると、これはE8dsv4(8コア64GBメモリ)に相当するようです。
結果ですが、応答時間は汎用クラスタより速く、450msから550msに収まりました。
1台の場合、秒間の処理件数は22程度で頭打ちになるようです。
台数を2台にすると、秒間の処理件数は倍になりました。
| No. | 並列度 | リクエスト数 | 1台 | 2台 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| リクエスト/秒 | 50% | 90% | 95% | 100% | リクエスト/秒 | 50% | 90% | 95% | 100% | |||
| 1 | 1 | 300 | 2.12 | 460 | 510 | 544 | 957 | 2.34 | 420 | 464 | 471 | 580 |
| 2 | 2 | 300 | 4.41 | 444 | 482 | 498 | 829 | 4.8 | 406 | 448 | 459 | 633 |
| 3 | 3 | 300 | 6.56 | 446 | 485 | 499 | 891 | 5.67 | 413 | 546 | 590 | 26076 |
| 4 | 4 | 300 | 8.62 | 453 | 483 | 494 | 845 | 9.05 | 424 | 492 | 516 | 579 |
| 5 | 5 | 300 | 10.96 | 438 | 482 | 495 | 844 | 10.93 | 440 | 510 | 530 | 717 |
| 6 | 6 | 300 | 13.08 | 436 | 485 | 509 | 830 | 13.06 | 438 | 483 | 496 | 929 |
| 7 | 7 | 300 | 15.02 | 439 | 496 | 527 | 902 | 15.55 | 427 | 474 | 504 | 819 |
| 8 | 8 | 300 | 16.5 | 449 | 530 | 673 | 839 | 17.74 | 431 | 481 | 495 | 643 |
| 9 | 9 | 300 | 18.85 | 442 | 524 | 560 | 894 | 20.17 | 419 | 468 | 484 | 811 |
| 10 | 10 | 300 | 20.51 | 449 | 532 | 613 | 899 | 21.97 | 425 | 476 | 508 | 658 |
| 11 | 11 | 300 | 21.92 | 459 | 525 | 648 | 1363 | 23.89 | 430 | 484 | 530 | 801 |
| 12 | 12 | 300 | 22.16 | 471 | 601 | 877 | 2722 | 25.34 | 433 | 498 | 551 | 834 |
| 13 | 13 | 300 | 22.33 | 503 | 725 | 852 | 1845 | 27.57 | 439 | 487 | 529 | 603 |
| 14 | 14 | 300 | 21.86 | 485 | 896 | 1100 | 2564 | 28.36 | 443 | 518 | 601 | 921 |
| 15 | 15 | 300 | 23.51 | 500 | 867 | 1149 | 2595 | 30.45 | 451 | 519 | 593 | 893 |
| 16 | 16 | 300 | 21.65 | 497 | 1063 | 2120 | 3273 | 31.9 | 447 | 527 | 622 | 1014 |
| 17 | 17 | 300 | 23.11 | 500 | 1459 | 1855 | 3402 | 33.48 | 462 | 530 | 570 | 734 |
| 18 | 18 | 300 | 21.32 | 504 | 2091 | 2383 | 3754 | 33.89 | 461 | 613 | 713 | 978 |
| 19 | 19 | 300 | 23.74 | 500 | 1541 | 2009 | 3749 | 37.27 | 452 | 522 | 653 | 840 |
| 20 | 20 | 300 | 20.72 | 502 | 2152 | 3282 | 4643 | 38.37 | 455 | 566 | 656 | 946 |
| 21 | 21 | 300 | 23.35 | 498 | 2289 | 2757 | 3550 | 39.57 | 463 | 584 | 660 | 946 |
| 22 | 22 | 300 | 22.32 | 498 | 2295 | 3215 | 4363 | 39.82 | 472 | 639 | 756 | 1335 |
| 23 | 23 | 300 | 23.45 | 501 | 2467 | 2774 | 3533 | 42.87 | 472 | 558 | 621 | 1109 |
| 24 | 24 | 300 | 21.77 | 516 | 3322 | 3950 | 4862 | 39.42 | 504 | 701 | 880 | 2482 |
| 25 | 25 | 300 | 21.96 | 493 | 2887 | 4091 | 6268 | 39.92 | 510 | 767 | 951 | 2273 |
| 26 | 26 | 300 | 21.91 | 491 | 3093 | 4955 | 5973 | 45.16 | 488 | 579 | 635 | 1629 |
| 27 | 27 | 300 | 22.18 | 490 | 3957 | 4938 | 5664 | 42.01 | 506 | 872 | 1028 | 2437 |
| 28 | 28 | 300 | 21.6 | 501 | 3976 | 4833 | 6357 | 41.65 | 515 | 902 | 995 | 1467 |
| 29 | 29 | 300 | 21.51 | 496 | 4130 | 5670 | 7288 | 45.59 | 509 | 634 | 700 | 2784 |
| 30 | 30 | 300 | 22.21 | 497 | 4303 | 5089 | 5923 | 42.5 | 514 | 1034 | 1334 | 2548 |
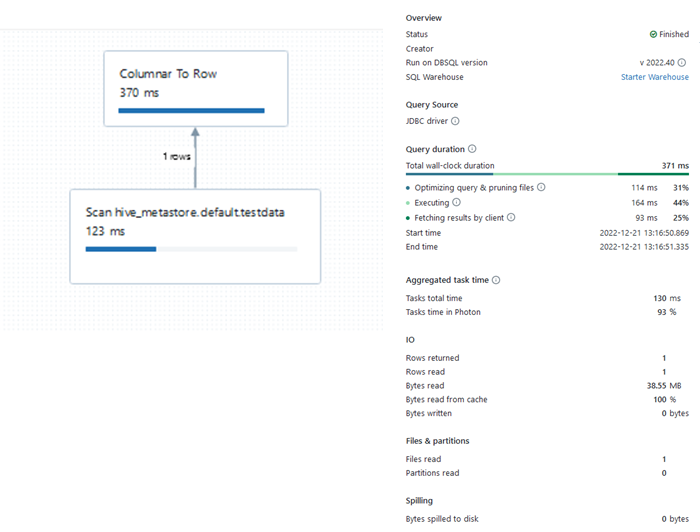
単純にレコードを1行持ってくる場合の実行計画
SQL Warehouseで先ほどの単純にレコードを1行持ってくる場合の実行計画をみてみます。
対象のデータを探す部分より、Columnar To Rowの方に時間がかかっているようです。
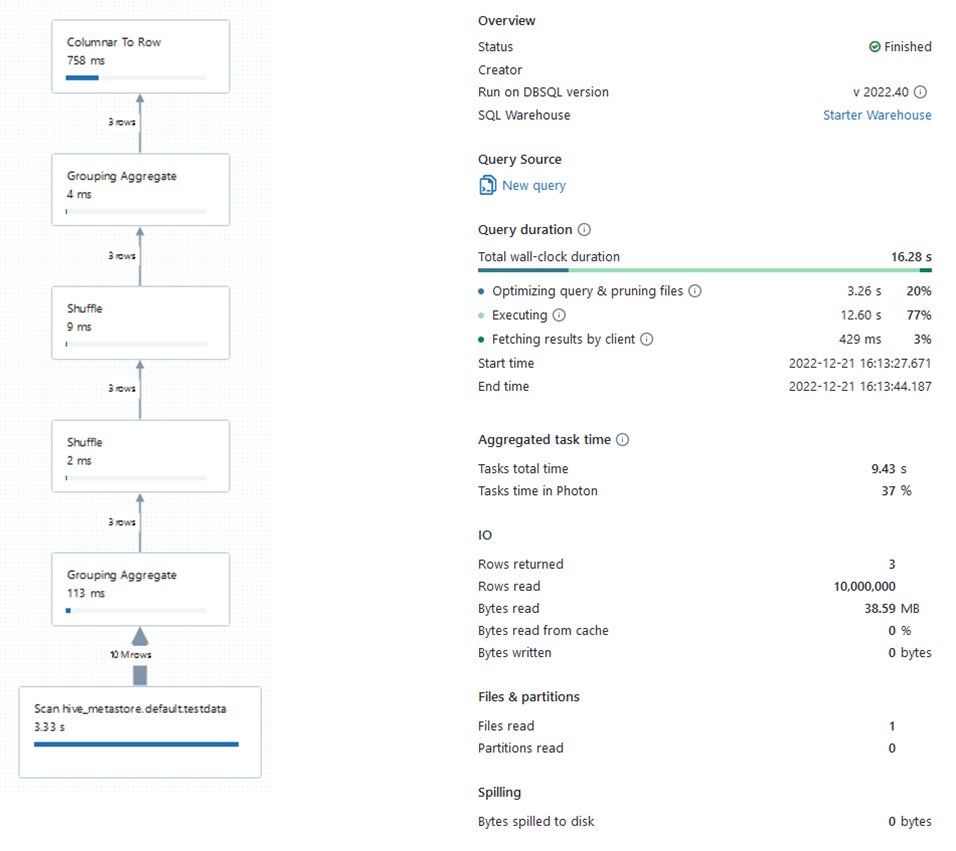
簡単な集計をさせた場合の実行計画
次に以下のような簡単な集計をさせた場合を試してみます。
SELECT name, COUNT(id) AS cnt_id FROM testdata t GROUP BY name LIMIT 1000
2X-Small1台の場合ですが、結果は次のようになりました。
全体としては16秒程度かかっています。
汎用クラスタとSQL Warehouseのコスト
性能評価に入る前にコストの考え方について確認しておきたいと思います。
汎用クラスタの場合
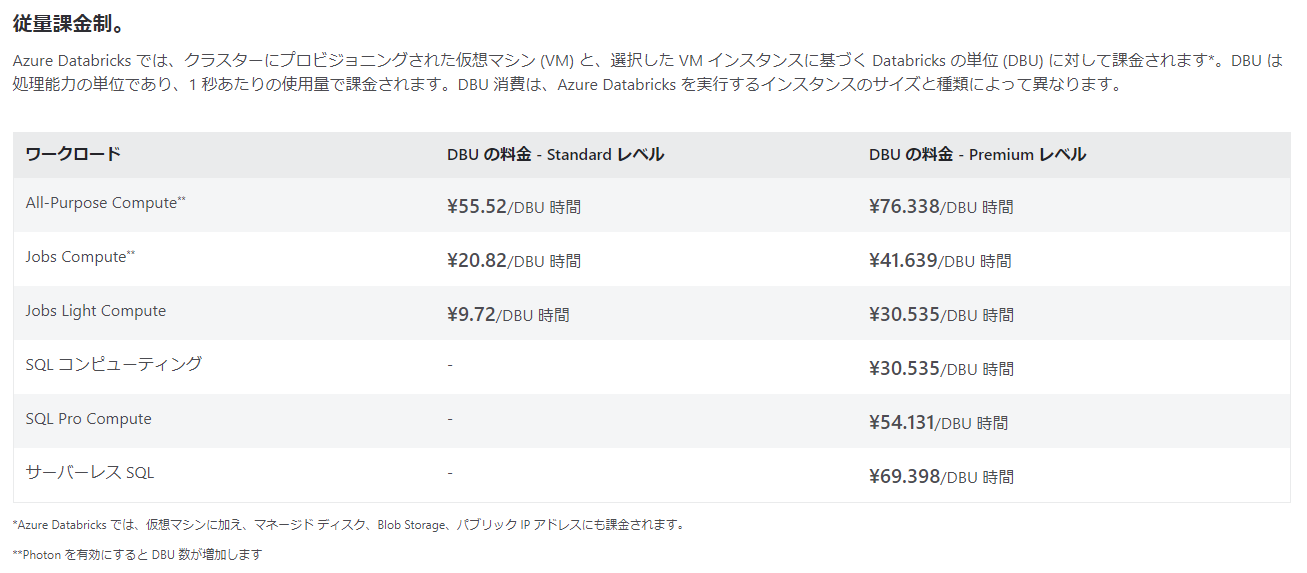
汎用クラスタの場合、料金はVMと消費するDBUの合計になります。
D4sv51台で消費するDBUは1。Photonを有効にすると2です。
以下が2022/12/30現在の料金表です。
Photonが有効なD4sv52台のクラスタを1ヶ月Premiumレベルで稼働させると278,400円程度かかります。

SQL Warehouseの場合
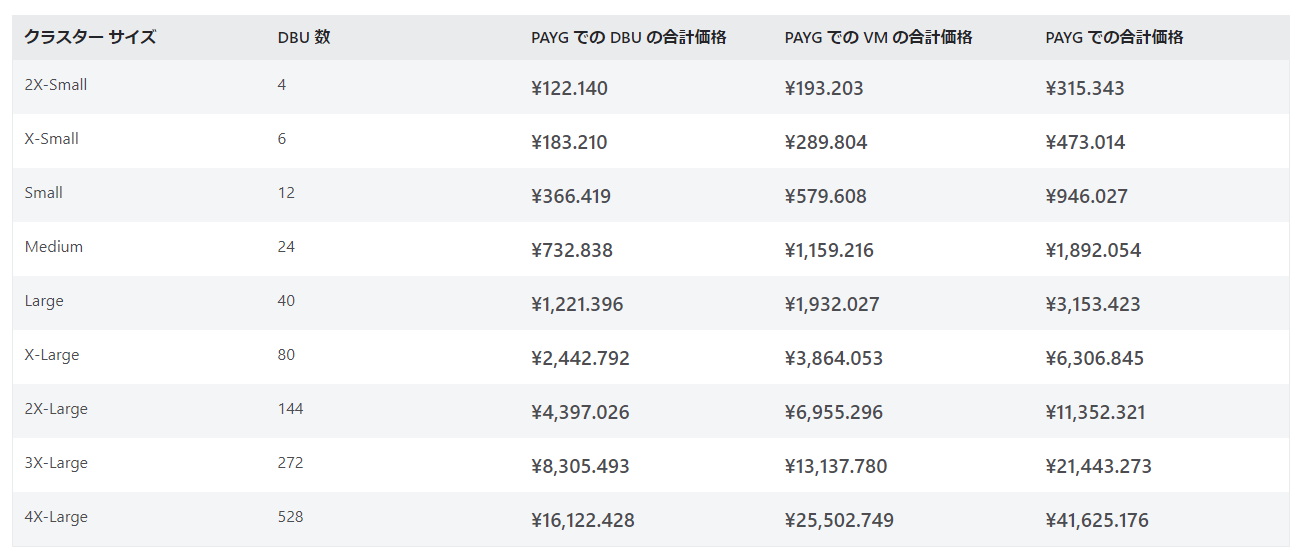
SQL WarehouseではクラスタサイズとDBUで料金が決まります。
2X-Smallの場合、スケールが1でもDBUは4消費します。
以下が2022/12/30現在の料金表です。
2X-Smallを1ヶ月稼働させたままにすると、234,360円程度かかります。

性能測定結果評価
汎用クラスタにおけるPhotonの有効性
オンラインから汎用クラスタにクエリを投げる場合はPhotonを有効にした方が良いでしょう。
オンラインで1回の応答にかかる時間が500ms程度なのか1秒程度なのかは大きな違いだと思います。
汎用クラスタとSQL Warehouseの差が想定より大きい
今回、一番驚いたのは汎用クラスタとSQL Warehouseの違いです。おおよそ同じ費用の環境でSQL Warehouseの方が応答速度で50ms-100ms程度勝り、秒間で倍以上の量を処理することができました。
Databricks社のエンジニアさんからもSQLのみを実行するのであれば、SQL Warehouseを使ってほしいと言われていましたが、同じSparkベースの基盤でここまで差があったのは驚きでした。
スケールアップ、スケールアウトの効果が非常に分かりやすい
汎用クラスタでもSQL Warehouseでもスケールアップ、スケールアウトで非常に分かりやすくスループットが改善しました。
サイジングを考える上で、この単純さは非常にありがたいなと思います。
Materialized Viewが待ち遠しい
1000万件程度の簡単な集計結果を返すのに単発で16秒かかりました。
この時間が許容できない場合は事前に集計を終わらせておく必要があるでしょう。
DatabricksではMaterialized Viewがまだプレビューですが、非常に強力な武器になると思います。
結論
非常に簡易なシナリオではありますが、冒頭で掲げていたオンラインシステムからクエリを受け付けるという場合に「Databricksに直接SQLクエリで問い合わせを行った場合、どの程度の応答性能とスループットが出せるのか?」についてです。
事前に加工をすべて終えられる前提で単純に数行とってくるようなSELECT文を投げるようなシナリオの場合、SQL Warehouseであれば現実的な時間内に応答を返すことはできそうです。
ストレージの限界がどこかできてしまうのだろうと思いますが、スケールアップやスケールアウトでスループットを簡単に増強できるところも魅力です。
Materialized ViewがGAになってからまた試してみたいと思います。