Azure Synapse Link for SQLの非機能検証
こんにちは、NRIデジタルの湯川です。
業務システムで発生したばかりのデータをほぼリアルタイムで分析したいという場合、AzureではEventHubsやStream Analyticsを使ったストリーム処理を作り込む方式がリファレンスアーキテクチャとして提示されています。
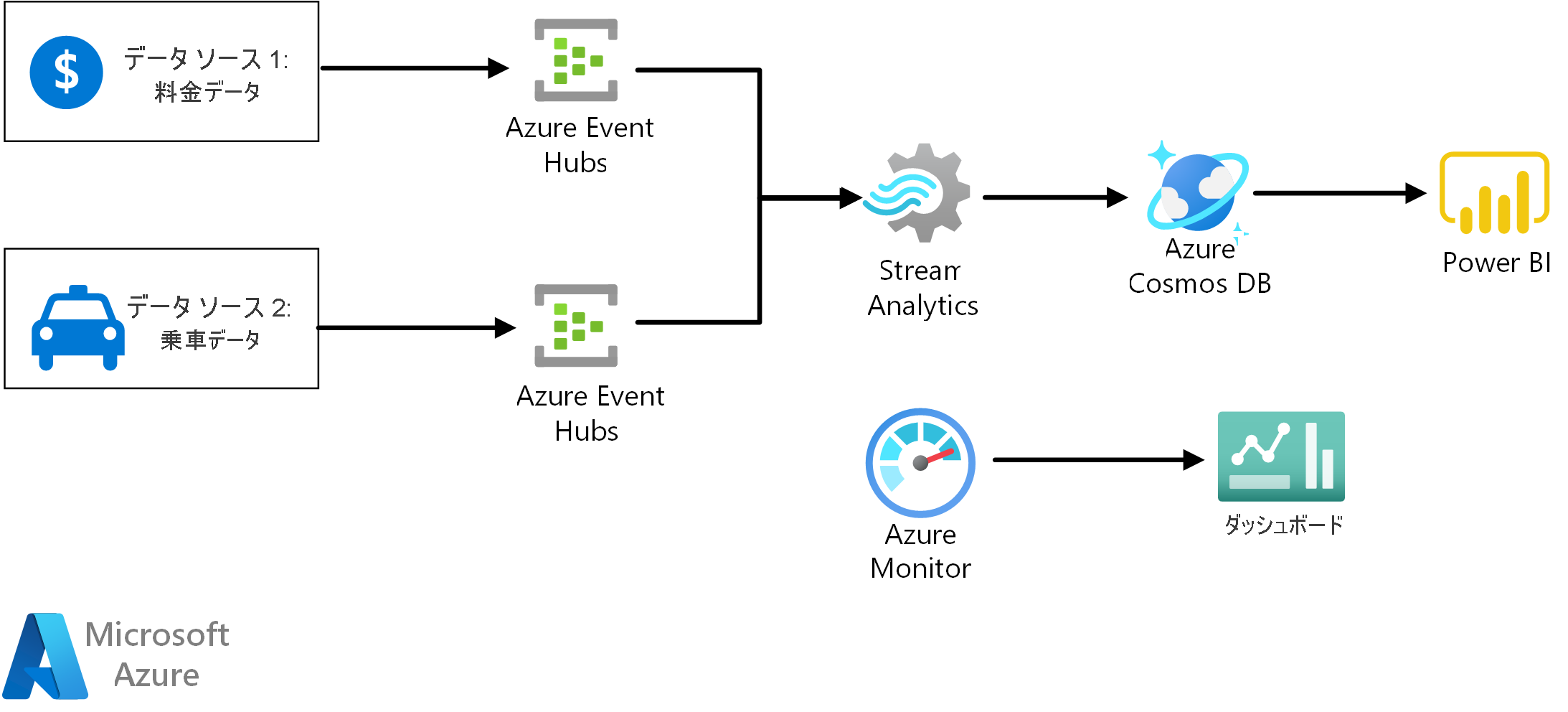
こうしたアプローチは業務システムか分析システムのどちらかで、もともとストリーム処理を扱っているのであれば、特に問題なく採用できるのだと思いますが、リアルタイム化のためだけに新たにストリーム処理を設計しなければならない場合には比較的重いデータ連携手法になると思います。
もっと手軽に、業務システムの中にあるデータをなるべくリアルタイムに分析したいという要望に応えるために生まれたのがAzure Synapse Link for SQLです。
今回、性能、制約、可用性に着目し、Azure Synapse Link for SQLを実案件で使っていく上での課題を整理してみたので共有したいと思います。
Azure Synapse Link for SQLとは
Azure SQL DatabaseやSQL Server2022からSynapse AnalyticsのSQL専用プール ※に対して、間にETLツール等を挟まずにデータ同期することができる機能です。
通常のレプリケーションとは異なり、Synapse側にデータ元にはないインデックスを持たせることが可能になります。
※SQL専用プールはSynapse Analyticsで提供されているいわゆるDWです。Synapse Analyticsのサービスラインナップとその内容についてはこちらを参照してください。
公式では以下利点として謳われています。


環境構築
東日本リージョン
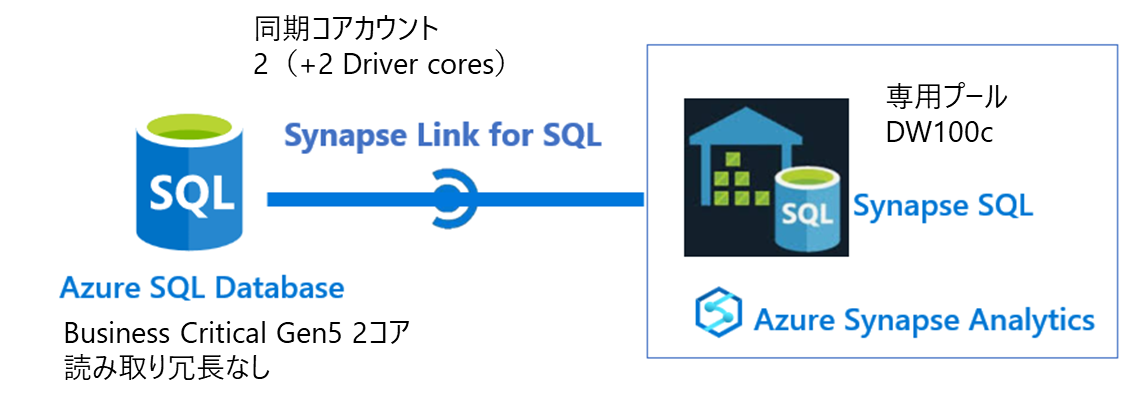
SQL DBのプライマリレプリカからSynapse 専用プールへの同期
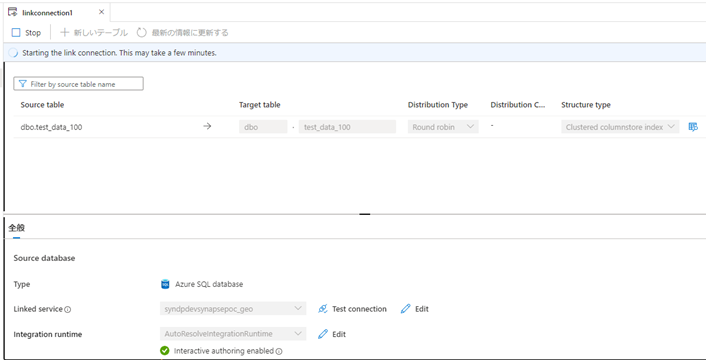
Synapse ワークスペースの画面でIntegrateを選び、Link connectionを選択します。
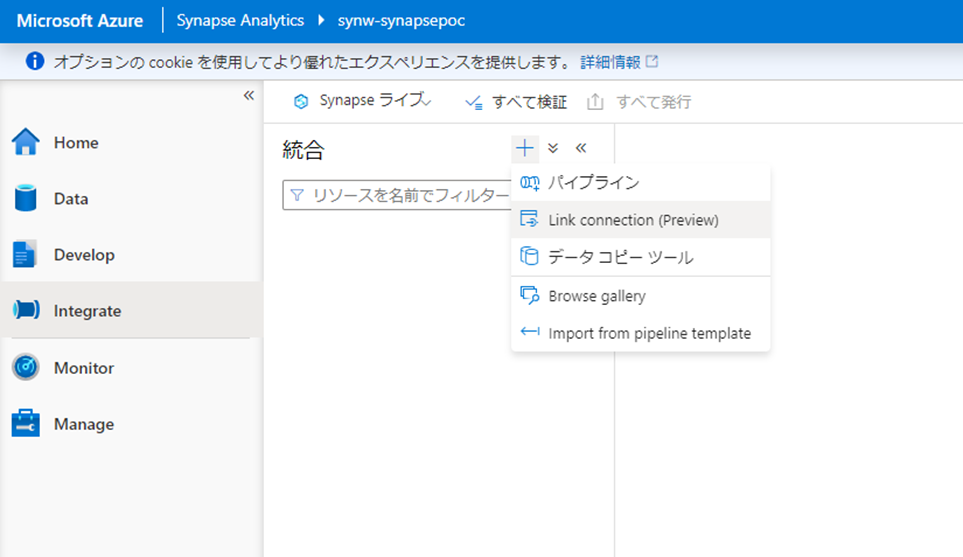
リンクサービスを作ります。
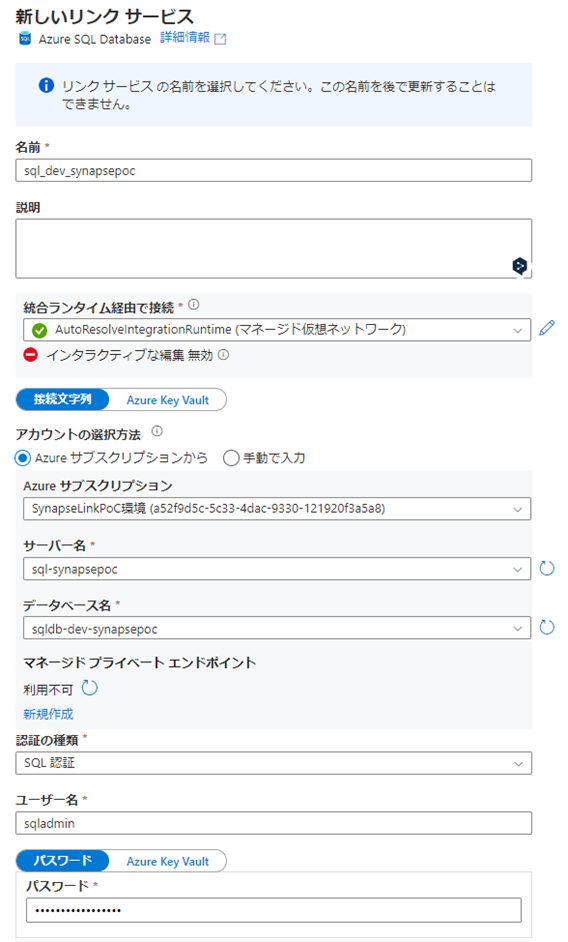
SQL DBに繋ぐためのプライベートエンドポイントを作ります。
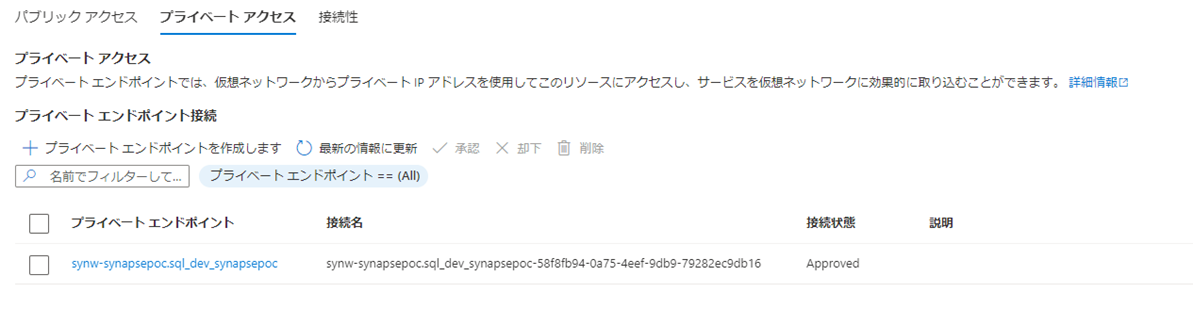
同期対象とするとテーブルを選択します。
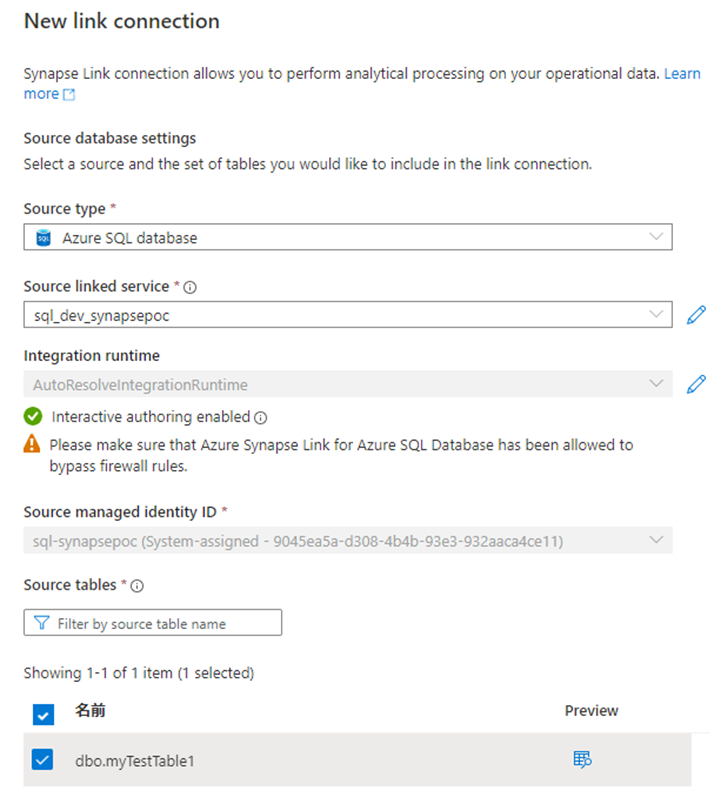
宛先の専用プールを選択します。
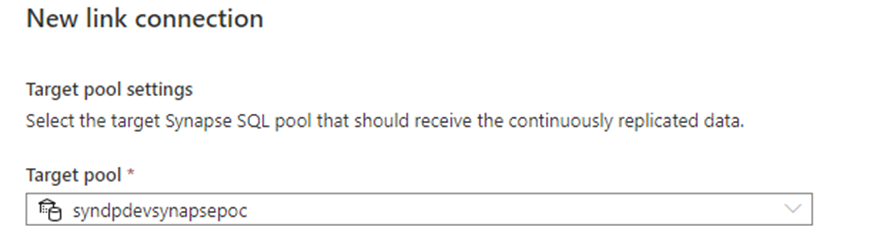
同期頻度と同期処理に割り当てるリソースを選択します。
同期を発行すると、同期が始まります。
SQL DBのセカンダリレプリカからSynapse 専用プールへの同期はできない
SQL DBのセカンダリレプリカをソースにすることはできません。
Linkの設定の最後で、読み取り専用DBをソースにできないというエラーがでます。

性能
環境
リソースはすべて東日本リージョンで構成しました。
| 設定内容 | |
|---|---|
| SQL DB | Business Critical – プロビジョニング済みコンピューティング Gen5 2コア 読み取り冗長なし |
| Synapse 専用プール | DW100c |
| 同期Core count | 2(+2 Driver cores) |
テストデータの準備
簡単に準備ができるので、今回はsys.objectsを増幅させてテストデータとしました。
以下がテーブル定義です。
CREATE TABLE [dbo].[test_data_10000000]( [name] [sysname] NOT NULL, [object_id] [int] NOT NULL, [principal_id] [int] NULL, [schema_id] [int] NOT NULL, [parent_object_id] [int] NOT NULL, [type] [char](2) NULL, [type_desc] [nvarchar](60) NULL, [create_date] [datetime] NOT NULL, [modify_date] [datetime] NOT NULL, [is_ms_shipped] [bit] NOT NULL, [is_published] [bit] NOT NULL, [is_schema_published] [bit] NOT NULL, [id] [bigint] IDENTITY(1,1) NOT NULL, pkey AS (id % 10) PERSISTED --計算列を定義する場合 CONSTRAINT [pk_test_data] PRIMARY KEY CLUSTERED ( [id] ASC ));
スナップショットの作成時間
同期はスナップショットを取得後、トランザクションの連携が開始される流れになっています。
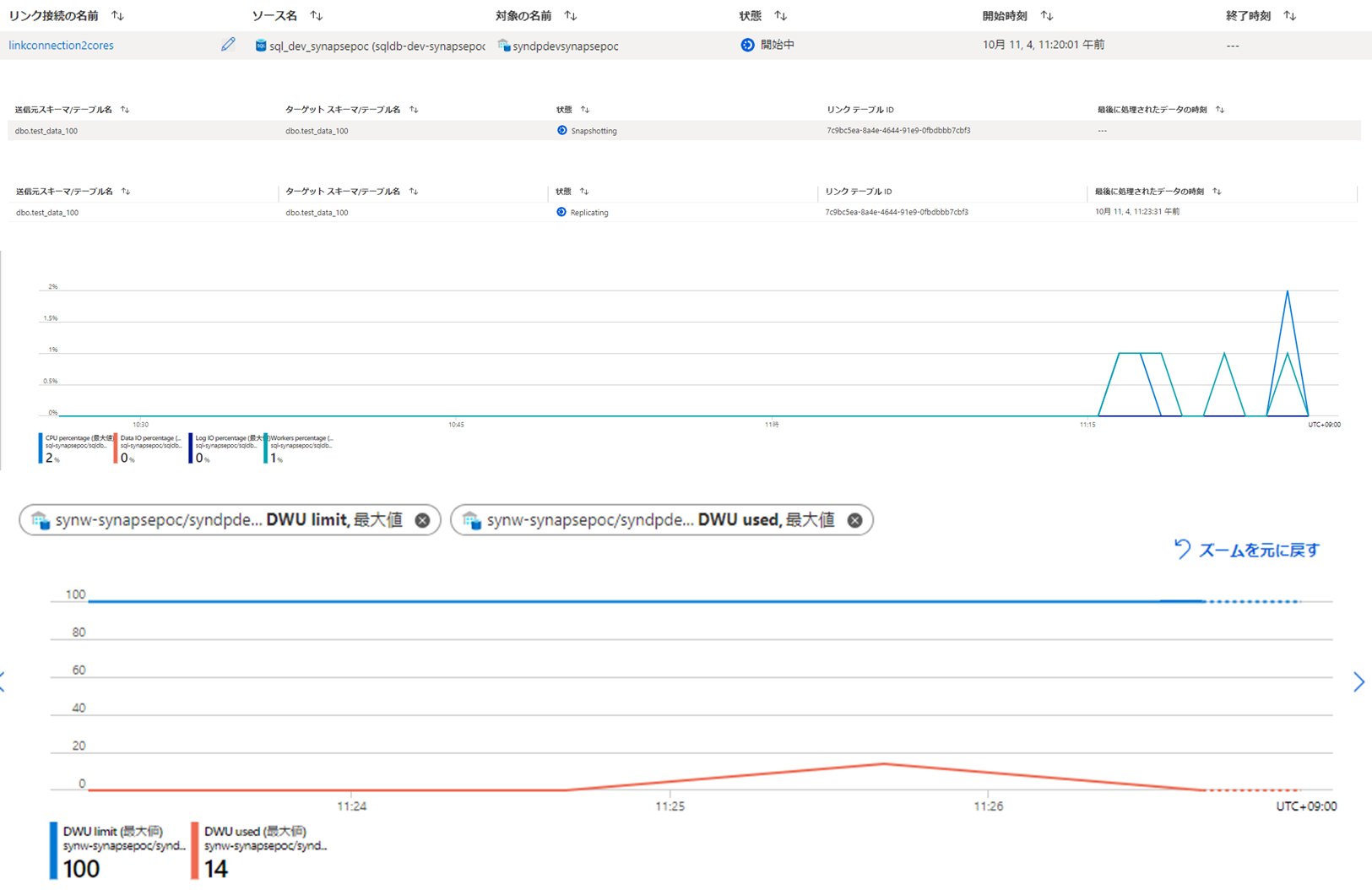
まずは100件だけ入れてスナップショットにかかる時間をみてみます。
ステータスの推移をみると3分30秒で同期完了したようです。
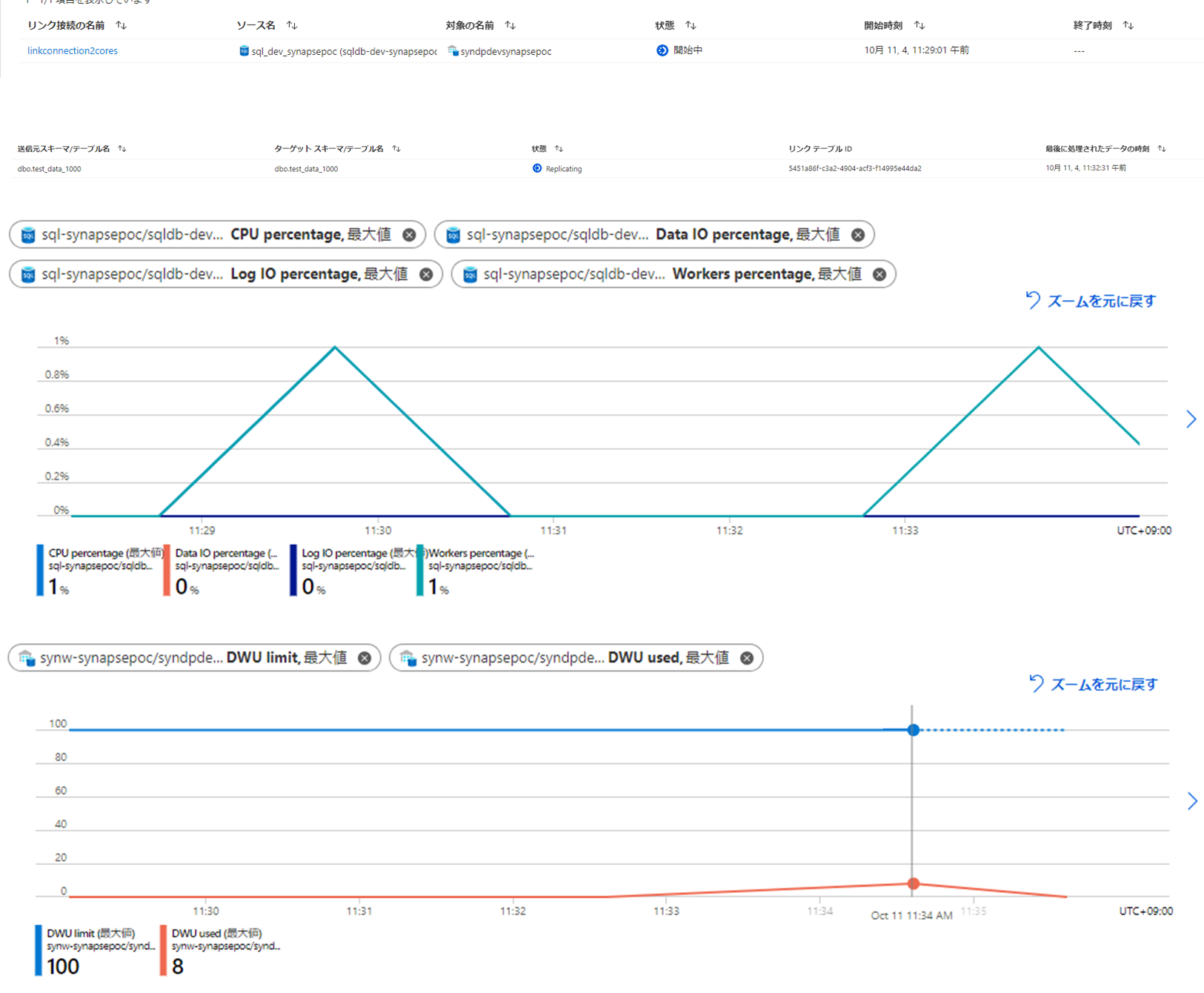
同じ条件で1000件に増やして試してみます。
今回も3分30秒でした。
最後に1000万件で試してみます。
3分23秒で完了しましたが、SynapseのDWUを100や1000と比べて大きく消費していました。
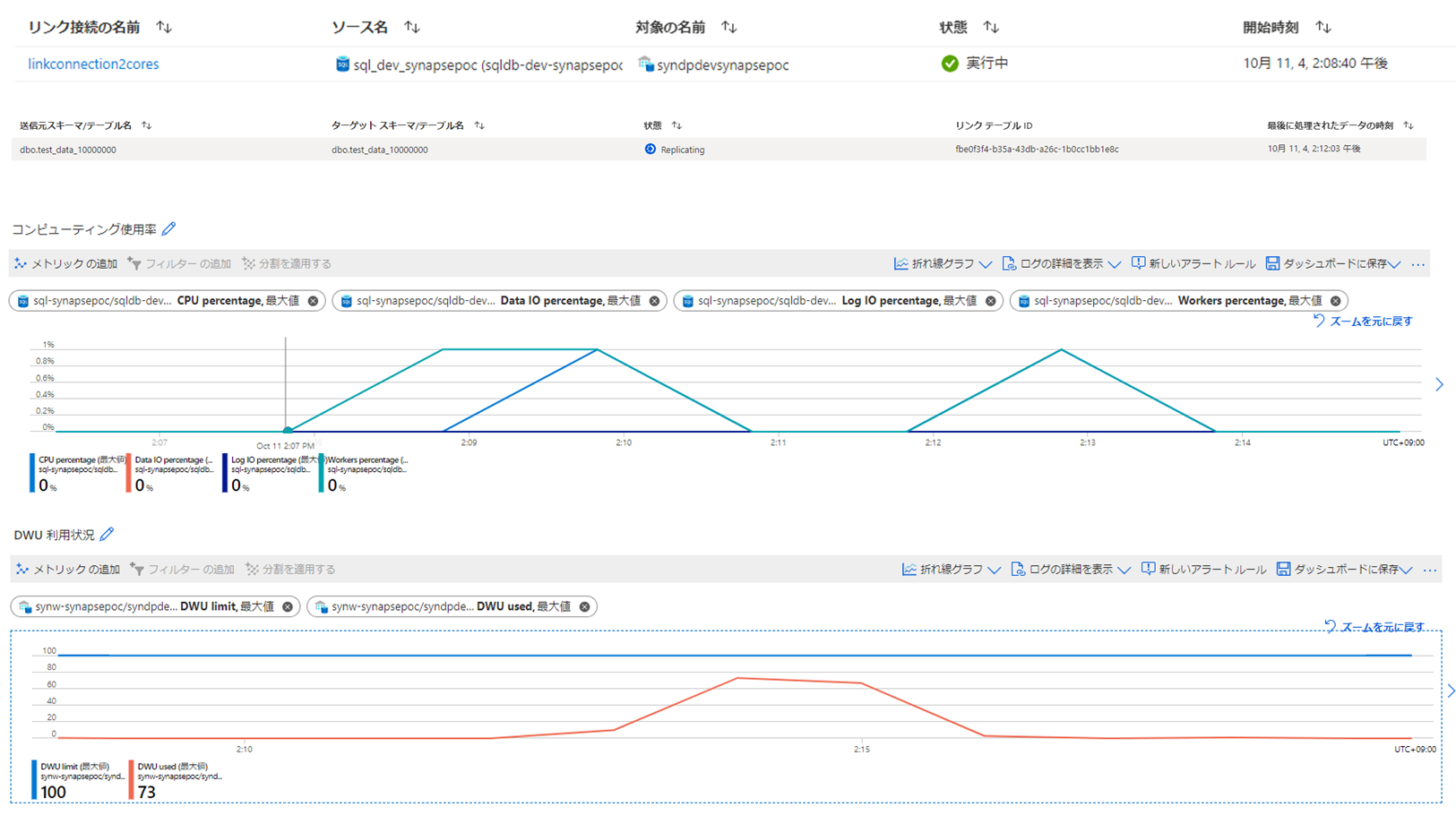
スナップショットの時間が100~1000万で大きく差が出ず、3分半前後で収まるのは内部的に存在しているその他の処理にかかる時間の影響の方が、この程度のデータ量だと多いということなのではないかと思われます。
ソース側のDBがBCなので、性能的に十分すぎるということなのか、ソース側には負荷がかかりにくいデータの取得方法が内部的に行われているのかは分かりませんが、ソース側のDBにかかる負荷は特に変動しているように見えませんでした。
一方でSynapse側の負荷は大きく変動しました。どちらかというと、Synapse側のリソースに与える影響の方が大きい同期方式なのではないかと思います。
スナップショット後の同期遅延時間
スナップショット後の同期にかかる時間をみてみます。
以下のクエリで1件更新した場合です。
UPDATE [dbo].[test_data_10000000] SET modify_date = SYSDATETIME() WHERE id = 10000000
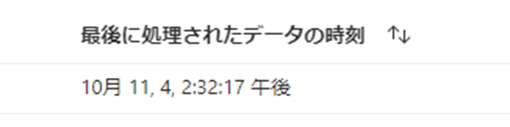
modify_dateの値をみてみると、以下のようになっています。

Synapse側の同期ステータスをみると、以下のように表示されました。
3秒程度で反映されたということのようです。
今度は100万件で試してみます。
BEGIN TRANSACTION tx UPDATE [dbo].[test_data_1000000] SET modify_date = SYSDATETIME() WHERE id < 1000000 COMMIT TRANSACTION tx UPDATE [dbo].[test_data_1000000] SET modify_date = SYSDATETIME() WHERE id = 1000000
8秒程度で反映されました。DWを41ほど消費しています。


今度は1000万件で試してみます。
BEGIN TRANSACTION tx UPDATE [dbo].[test_data_10000000] SET modify_date = SYSDATETIME() WHERE id < 10000000 COMMIT TRANSACTION tx UPDATE [dbo].[test_data_10000000] SET modify_date = SYSDATETIME() WHERE id = 10000000
キャプチャを取る時に日本時間にしなかったので分かりにくいですが、1分18秒かかりました。

DWは91消費しています。

100万件が8秒で同期されるなら、1000万件まで滞留することはあまりないのだろうと思いますが、バッチ等でデータの洗い替えをするようなテーブルの場合は同期が分単位で遅延することは発生しそうです。
ネットワーク
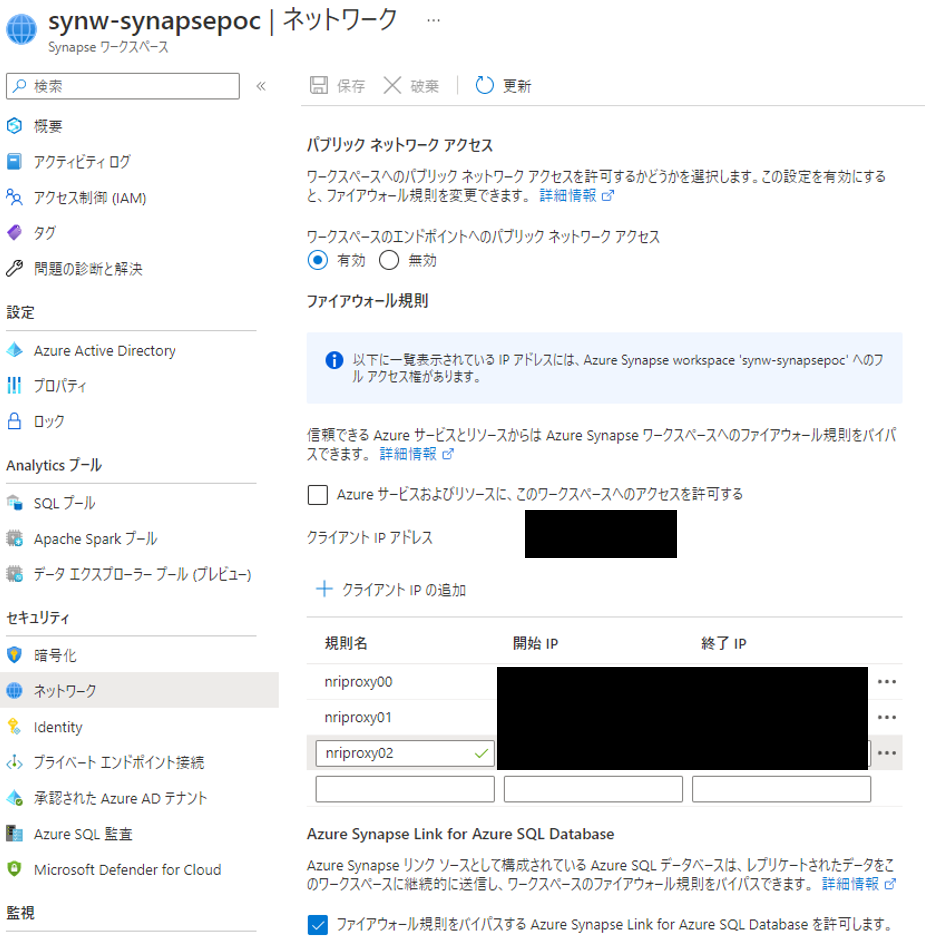
公式にはマネージド仮想ネットワークを利用できないと記載されています。

サポートはされないのかもしれませんが、実際は構成することが可能でした。
可用性
Synapseの専用プールはコスト削減のために、使わない時には停止することができます。
Synapse Linkを構成した状態で停止を行うとどうなるのでしょうか。
まず、Synapse Linkを構成した状態でも停止はできます。
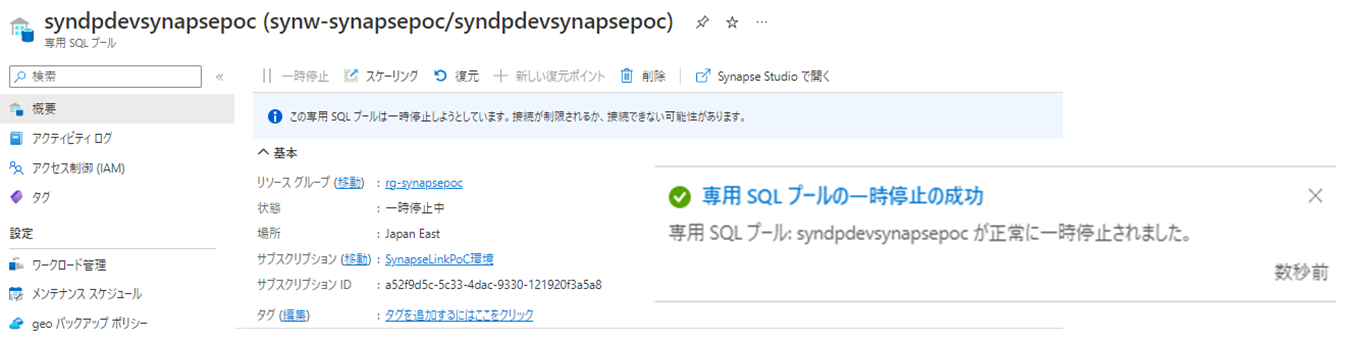
専用プールを停止しただけではLinkもエラーになりません。


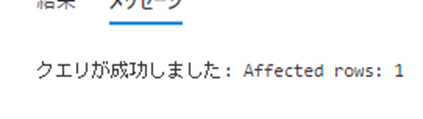
ソース側で更新を発生させてみます。更新は問題なく成功します。
UPDATE test_data_10000000 SET modify_date = SYSDATETIME() WHERE id = 10000000
数分後に同期状態がエラーになってしまいました。


詳細のところをみると、以下のようなスタックトレースが表示されました。
このメッセージからDataflowが内部で利用されていることが分かりますね。
Some internal error happened due to ‘Some unknown error happened: Cannot connect to SQL database: ‘jdbc:sqlserver://synw-synapsepoc.sql.azuresynapse.net:1433;database={syndpdevsynapsepoc};loginTimeout=60;sslProtocol=TLSv1.2’, ‘Managed Identity (factory name): synw-synapsepoc’.[SQL Exception]Error Code:40892, Error Message: Cannot connect to database when it is paused. ClientConnectionId:9bd2a57a-7136-4684-bc11-507f617fcb66, error stack:com.microsoft.sqlserver.jdbc.SQLServerException.makeFromDatabaseError(SQLServerException.java:262)
com.microsoft.sqlserver.jdbc.TDSTokenHandler.onEOF(tdsparser.java:283)
com.microsoft.sqlserver.jdbc.TDSParser.parse(tdsparser.java:129)
com.microsoft.sqlserver.jdbc.TDSParser.parse(tdsparser.java:37)
com.microsoft.sqlserver.jdbc.SQLServerConnection.sendLogon(SQLServerConnection.java:5233)
com.microsoft.sqlserver.jdbc.SQLServerConnection.logon(SQLServerConnection.java:3988)
com.microsoft.sqlserver.jdbc.SQLServerConnection.access$000(SQLServerConnection.java:85)
com.microsoft.sqlserver.jdbc.SQLServerConnection$LogonCommand.doExecute(SQLServerConnection.java:3932)
com.microsoft.sqlserver.jdbc.TDSCommand.execute(IOBuffer.java:7375)
com.microsoft.sqlserver.jdbc.SQLServerConnection.executeCommand(SQLServerConnection.java:3206)
com.microsoft.sqlserver.jdbc.SQLServerConnection.connectHelper(SQLServerConnection.java:2713)
com.microsoft.sqlserver.jdbc.SQLServerConnection.login(SQLServerConnection.java:2362)
com.microsoft.sqlserver.jdbc.SQLServerConnection.connectInternal(SQLServerConnection.java:2213)
com.microsoft.sqlserver.jdbc.SQLServerConnection.connect(SQLServerConnection.java:1276)
com.microsoft.sqlserver.jdbc.SQLServerDriver.connect(SQLServerDriver.java:861)
com.microsoft.dataflow.store.mssql.CustomSqlServerDriver$$anonfun$3.apply(CustomSqlServerDriver.scala:89)
com.microsoft.dataflow.store.mssql.CustomSqlServerDriver$$anonfun$3.apply(CustomSqlServerDriver.scala:89)
scala.util.Try$.apply(Try.scala:192)
com.microsoft.dataflow.store.mssql.CustomSqlServerDriver.connect(CustomSqlServerDriver.scala:89)
org.apache.spark.sql.execution.datasources.jdbc.DriverWrapper.connect(DriverWrapper.scala:45)
org.apache.spark.sql.execution.datasources.jdbc.JdbcUtils$$anonfun$createConnectionFactory$1.apply(JdbcUtils.scala:63)
org.apache.spark.sql.execution.datasources.jdbc.JdbcUtils$$anonfun$createConnectionFactory$1.apply(JdbcUtils.scala:54)
com.microsoft.dataflow.store.mssql.MSSQLCharacteristic.newConnection(MSSQLStore.scala:105)
com.microsoft.cdc.flow.store.JdbcUtil$.newConnection(JdbcConnection.scala:24)
com.microsoft.cdc.flow.store.dw.BaseAzureSqlDwGen2CdcWriter.(AzureSqlDwGen2CdcWriter.scala:18)
com.microsoft.cdc.flow.store.dw.AzureSqlDwGen2CopyStmtBasedCdcWriter.(AzureSqlDwGen2CopyStmtBasedCdcWriter.scala:17)
com.microsoft.cdc.flow.store.dw.AzureSqlDwGen2Store$.cdcWriter(AzureSqlDwGen2Store.scala:24)
com.microsoft.cdc.CdcExecutor$$anonfun$start$1$$anonfun$apply$mcV$sp$1$$anonfun$apply$mcV$sp$2.apply$mcV$sp(CdcExecutor.scala:155)
scala.util.control.Breaks.breakable(Breaks.scala:38)
com.microsoft.cdc.CdcExecutor$$anonfun$start$1$$anonfun$apply$mcV$sp$1.apply$mcV$sp(CdcExecutor.scala:128)
com.microsoft.cdc.CdcExecutor$$anonfun$start$1$$anonfun$apply$mcV$sp$1.apply(CdcExecutor.scala:96)
com.microsoft.cdc.CdcExecutor$$anonfun$start$1$$anonfun$apply$mcV$sp$1.apply(CdcExecutor.scala:96)
scala.concurrent.impl.ExecutionContextImpl$DefaultThreadFactory$$anon$2$$anon$4.block(ExecutionContextImpl.scala:48)
scala.concurrent.forkjoin.ForkJoinPool.managedBlock(ForkJoinPool.java:3640)
scala.concurrent.impl.ExecutionContextImpl$DefaultThreadFactory$$anon$2.blockOn(ExecutionContextImpl.scala:45)
scala.concurrent.package$.blocking(package.scala:123)
com.microsoft.cdc.CdcExecutor$$anonfun$start$1.apply$mcV$sp(CdcExecutor.scala:96)
com.microsoft.cdc.CdcExecutor$$anonfun$start$1.apply(CdcExecutor.scala:96)
com.microsoft.cdc.CdcExecutor$$anonfun$start$1.apply(CdcExecutor.scala:96)
scala.concurrent.impl.Future$PromiseCompletingRunnable.liftedTree1$1(Future.scala:24)
scala.concurrent.impl.Future$PromiseCompletingRunnable.run(Future.scala:24)
scala.concurrent.impl.ExecutionContextImpl$AdaptedForkJoinTask.exec(ExecutionContextImpl.scala:121)
scala.concurrent.forkjoin.ForkJoinTask.doExec(ForkJoinTask.java:260)
scala.concurrent.forkjoin.ForkJoinPool$WorkQueue.runTask(ForkJoinPool.java:1339)
scala.concurrent.forkjoin.ForkJoinPool.runWorker(ForkJoinPool.java:1979)
scala.concurrent.forkjoin.ForkJoinWorkerThread.run(ForkJoinWorkerThread.java:107)’.
制約
照合順序の制限
おそらく多くの方が最初に遭遇すると思われるのが照合順序の制限です。
照合順序でSynapseがまだサポートしていないものをソース側で利用していると同期がエラーになります。
Japanese_XJIS_140_CS_AS_KS_WSを試してみます。
CREATE TABLE dbo.Test_Japanese_XJIS_140_CS_AS_KS_WS (cl NVARCHAR(50) COLLATE Japanese_XJIS_140_CS_AS_KS_WS_UTF8 PRIMARY KEY); INSERT INTO dbo.Test_Japanese_XJIS_140_CS_AS_KS_WS (cl) VALUES (N’いいいい’);
この場合、Linkの構成をすることはできるのですが、同期はエラーになります。
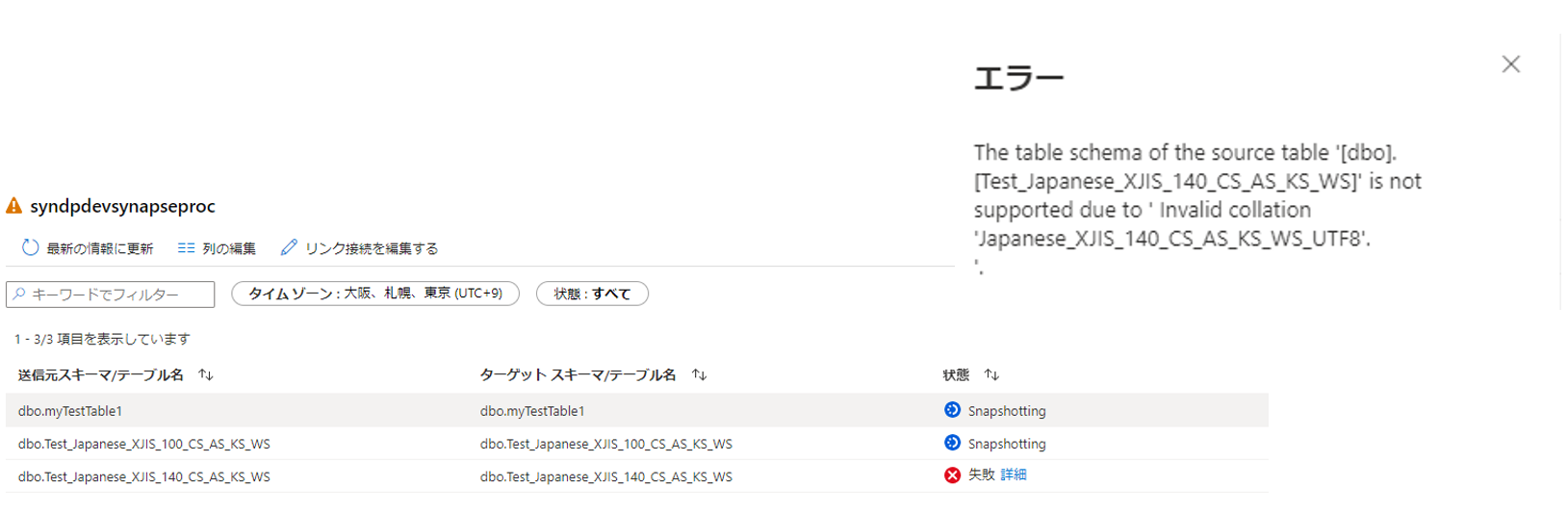
Japanese_XJIS_100_CS_AS_KS_WSであればSynapseでサポートされているので同期してくれます。
CREATE TABLE dbo.Test_Japanese_XJIS_100_CS_AS_KS_WS (cl NVARCHAR(50) COLLATE Japanese_XJIS_100_CS_AS_KS_WS PRIMARY KEY); INSERT INTO dbo.Test_Japanese_XJIS_100_CS_AS_KS_WS (cl) VALUES (N’いいいい’);
TRUNCATEができない
同期中のテーブルはTRUNCATEできません。Change Data Captureが有効になっているか、レプリケーション対象として発行されているので、TRUNCATEはできないというエラーになります。
TRUNCATE TABLE [dbo].[test_data_10]

列追加ができない
同期中のテーブルは列の追加はできません。Change feedが有効だとスキーマ変更はできないというエラーになります。
ALTER TABLE dbo.test_data_10000000_idx_pkey ADD newkey BIGINT

主キーがないテーブルは同期対象にできない
主キーがないテーブルは同期対象にできません。

INDEX追加は可能
同期中のテーブルであってもINDEXの追加はできました。
CREATE INDEX [idx_type_desc_test_data_10000000_idx_pkey] ON test_data_10000000_idx_pkey(type_desc)

計算列は無視される
計算列はPERSISTEDであっても無視されます。エラーにはなりません。

以下のようにSynapseには反映されません。

その他:実機検証はしていないが公式に記載があるもの
制約、制限事項は以下に記載されています。
SQL 用 Azure Synapse Link に関する既知の制限事項と問題 – Azure Synapse Analytics
ここでは特に注意を要するものをピックアップしておきます。
作成時期の制限

主キーとして利用できるデータ型の制限

同期がサポートされない列

データの切り捨て
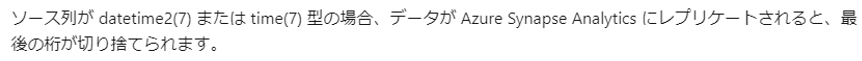
DDL+DMLが明示的なトランザクションで実行されると同期が壊れる

レプリケーションにフェイルオーバーする時、データベース名が異なるとSynapse Linkが有効にできない
![]()
以下、GAになった時にはなくなっていてくれないと恐ろしい制限です。

注意を要する挙動
制限事項として列挙したもの以外で、注意を要すると思われる仕様に以下があります。
- 再同期をかけると、スナップショットから再実行され、この時にデータが一度すべて消える
- 同期対象のテーブルを追加すると、一度同期を止めて再同期を書ける必要がある
- 複数のテーブルを同期対象としている場合、照合順序等が原因で同期されないテーブルが発生しても、残りのテーブルは同期状態になる
まとめと所感
2022/10/21現在、Synapse Link for SQLはまだプレビューの段階です。今後改善される部分もあるのだと思いますが、実際に本番環境で利用するのは辛いなと感じたのは以下の部分です。
- ソース側でTRUNCATEができなくなる
- 再同期をかけるとスナップショットから再実行され、この時にデータが一度すべて消える
- SQL DB側の最新の照合順序を利用できない
逆に上記のようなポイントを許容できる場合は手軽にSQL DBのデータを専用プールに同期できる方法だということも言えると思います。照合順序以外はトランザクションレプリケーションに似たような制約があるので、トランザクションレプリケーションを利用できるようなシーンでは、この機能を活用していけるのではないでしょうか。