SIGNATE 金融データ活用チャレンジ ~解法編~
こんにちは。NRIデジタルの髙田です。
NRIデジタルのKaggle部として東郷、藤田、滝口、御前、髙田の計5名で参加していた、金融データ活用推進協会(FDUA)1)https://www.fdua.org/主催の「第1回金融データ活用チャレンジ」2)https://signate.jp/competitions/841のコンペティションが終了したため、私たちの解法を紹介します。
結果は特別賞としてSIGNATE賞、Databricks賞を受賞しました。3)https://prtimes.jp/main/html/rd/p/000000008.000103937.htmlまた精度面では、投稿:12286件、参加:1658人中で21位の銀メダルでした。
SIGNATE 金融データ活用チャレンジ ~Databricks編~では、コンペティションの概要と統合データ分析基盤のDatabricks4)https://www.databricks.com/jpについて記載しました。本記事では私たちが実装した解法を紹介していきたいと思います。


評価指標
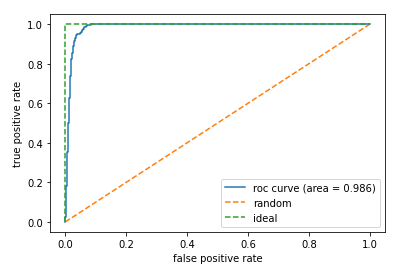
本コンペティションは評価指標がROC-AUCでした。ROC-AUCを一言で説明すると、予測値で降順ソートした際に、真のPositiveデータを上位にどの程度集められたかを表している指標です。
また、定量的には、TPR(全ての Positive のうち、実際に Positive だったものを正しく Positive と判定できた割合)を縦軸、FPR(全ての Negative のうち、実際には Negative だったが間違えて Positive と判定した割合)を横軸に取り、Positive-Negative判定の閾値を0~1で動かした際の曲線下の面積で表せます。
ROC-AUCは、Positiveを正しくPositiveと、Negativeを正しくNegativeと予測できているかを評価ポイントとしています。したがって、不均衡データを評価する際にはNegativeデータが大多数を占めるため、ほとんどのデータが、「Negativeを正しくNegativeと予測できている」ことになってしまい、高精度な(=1に近い)値が算出されます。今回のコンペティションのデータは不均衡データであったため、この評価指標への対策が勝敗を分ける1つの要因となったと考えています。
validation
学習データでモデルを評価するためのvalidationですが、今回はテストデータに最も近い1年月のデータをvalidationデータとするHold Out法を採用しました。今回のデータは顧客毎に年月単位でデータが存在し、target_flag=1となると以降のデータには出現しないためvalidationの切り方が難しかったです。
その他のvalidation方法として、時系列を考慮しない5-fold CVや、5-foldのTime split、顧客IDをtrainデータとvalidationデータで分け、Positive、Negativeの比率も保持するStratified Group 5 foldも試しました。しかし、どれもリーダーボード上のスコアが悪化したため、Hold Out法を採用しました。
結果として、PublicスコアとPrivateスコアでの乖離が大きかったため、最終提出では別のvalidation方法で評価したモデルも提出したり、アンサンブルを行ったりすれば良かったと思っています。
特徴量エンジニアリング
私たちのチームでは、多種多様な特徴量を作成しました。本記事では、有効であった特徴量を紹介します。
- 期間系特徴量の経過日数
今回は時系列データであり、いつ延滞するかを特徴量として与えたかったため、「口座開設日からの経過月数」「住宅ローン開始日からの経過月数」などの自レコードとの差分特徴量を作成しました。 - 資産・住宅ローン金額系特徴量の比率
自分の資産に対する住宅ローンの割合が高いほど延滞確率は高いと考え、普通預金残高に対する住宅ローン借入額などの、住宅ローン/資産比率特徴量を作成しました。 - 入出金系特徴量の合計値・比率
ATM、振込、振替に対してそれぞれ入出金データがあったため、それらを合計することで月当たりのトータルの入出金額特徴量を作成しました。また、それぞれの入出金データについて比率算出することで、入出金のどちらがどの程度多いかを示す特徴量を作成しました。 - ラグ特徴量
各特徴量について、前月のデータに対する当月データの比率特徴量を作成しました。最初は単なるラグ特徴量や複数期間のラグ特徴量を作成したのですが、メモリの関係上最も効果的だった、前月との比率特徴量を採用しました。 - 過去データの累積特徴量
当月時点での顧客の特性を表すデータとして、過去データを全て集計し、最小値、最大値、平均値、件数のデータを作成しました。 - 過去に返済が滞った回数
過去に返済が滞った回数が多いと2か月連続での延滞が発生する可能性が高いと考え、顧客毎に過去住宅ローン月額返済額=0となった回数をカウントした特徴量を作成しました。 - 住宅ローン貸出日、口座開設日別に延滞が発生しているかどうかのフラグと延滞人数をカウント
今回のデータをよく見てみると、特定の住宅ローン貸出日、口座開設日にterget_flag=1となっている人が固まっていることがわかりました。そこで、住宅ローン貸出日、口座開設日毎にtarget_flag=1となる人がいるかどうかの情報を特徴量にしました。また、追加の情報としてtarget_flag=1となる人数も特徴量としました。こちらはリーダーボード上のスコアでは効果的な特徴量でしたが、過学習気味となったため、PublicとPrivateが乖離してしまった原因の1つであると考えています。
不均衡データ対策
今回のデータは基準年月毎にPositiveの割合が1%未満と不均衡なデータとなっていました。そのまま学習を進めると、予測値のほとんどが0に近い値となってしまうため、不均衡データの対策が必要でした。
そこで私たちは以下の2つの対策を試しました。結果としてはリーダーボードの精度が高かった1のweightを使用する方法を採用しました。
- 学習データセットにweightを使用し、PositiveとNegativeの割合を等しくする
こちらはscikit-learn5)https://scikit-learn.org/stable/のcompute_sample_weightメソッドを用いて実装しました。 - Undersampling + bagging
こちらはNegativeデータを減らすことでデータの割合をならす方法です。この場合、学習に使用するデータが少なくなってしまうため、baggingを行うことで精度の向上を図っています。
アルゴリズム
今回私たちは最終的にLightGBM6)https://lightgbm.readthedocs.io/en/v3.3.2/#とCatBoost7)https://catboost.ai/を使用しました。
特徴量エンジニアリングはLightGBMで進め、最終版で他のアルゴリズムを試しました。AutoMLを用いてrandom forestやneural network、XGBoost8)https://xgboost.readthedocs.io/en/stable/#等の出力を確認した際に、CatBoostの精度がLightGBMと同等だったため、アンサンブル対象に選択しました。このアンサンブルは非常に効果が大きかったです。
LightGBMの場合、2値分類の場合損失関数がLogLossとなり、Positiveである0~1の確率値を出力するのですが、CatBoostの場合、AUCで最適化を行うことで確率値ではない出力ができた点も、今回の不均衡データ×AUCという評価指標に効果的であったと考えられます。
結果と反省点
私たちのチームの最終順位は1658人中21位の銀メダルでした。Publicスコアでは14位であったため、Privateスコアで順位を落としてしまったことが悔やまれますが、初めて金融データに関するコンペティションに参加し、銀メダルを獲得できたことは嬉しく思います。
今回は異なるアルゴリズムでアンサンブルをすると精度が向上したため、LightGBMとCatBoostだけでなく、他のアルゴリズムとのアンサンブルにも取り組むことができればよかったと思っています。また、PublicとPrivateスコアの乖離が大きかったため、よりロバストなモデルの作成や、データの分割手法の調査をする方法もあったかもしれません。
おわりに
今回はKaggle部として出場した「第1回金融データ活用チャレンジ」のコンペティションを紹介しました。
今回のコンペティションは、参加者のslackチャンネルがあり活発な議論が交わされていたり、Databricksというデータ分析基盤が提供されていたりと、初心者の方でも気軽に取り組めるコンペティションとなっていました。私自身もデータサイエンティストとして働いて1年半程度ですが、今回のコンペティションは大変勉強になりました。
金融データ活用チャレンジコンペティションの第2回が開催されれば、また参戦したいと思います。
本記事を見て少しでも興味を持っていただけた方は、ぜひ第2回に参加してみていただけると嬉しいです。
References