SIGNATE 金融データ活用チャレンジ ~Databricks編~
こんにちは。NRIデジタルの髙田です。
昨今、金融業界ではデジタルデータの収集が進んでいますが、収集したデータを活かしてどの様に生産性を向上させるかが課題となっています。また、金融業界の豊富で多様なデータを分析することはデータサイエンティストとしてのスキルアップにも大いに役立つものと思っています。
そんな中、金融データ活用推進協会(FDUA)1)https://www.fdua.org/主催で、「第1回金融データ活用チャレンジ」2)https://signate.jp/competitions/841コンペティションがSIGNATEで開催されています。そこで本コンペティションに、NRIデジタルのKaggle部として、東郷、藤田、滝口、御前、髙田の計5名で参加しました。
本記事では、コンペティションで指定の統合データ分析基盤であるDataBricks3)https://www.databricks.com/jpを用いたデータ分析手法に主眼を置いてご紹介していきたいと思います。(コンペティション終了後に解法編を公開予定です。)
なお、本記事はpythonの基本的な文法を理解しており、これからデータ分析コンペに挑戦したいという方を想定して記載しています。
コンペティション概要
今回私たちが参加している「第1回金融データ活用チャレンジ」は入出金や預金残高などの銀行の口座情報から、顧客が基準年月+3ヶ月目と基準年月+4ヶ月目に連続して住宅ローンを延滞するかどうかを予測するタスクを解くコンペティションです。本コンペティションに類似したコンペティションとして、Kaggleで2018年に開催された「Home Credit Default Risk」4)https://www.kaggle.com/c/home-credit-default-riskが挙げられます。「Home Credit Default Risk」は、個人のクレジットの情報や過去のローン応募情報などから、顧客が債務不履行になるかどうかを予測するタスクを解くコンペティションでした。また評価指標もAUC5)https://atmarkit.itmedia.co.jp/ait/articles/2211/24/news019.htmlであった点も今回の「第1回金融データ活用チャレンジ」と共通しています。したがって、Home Credit Default Riskの上位解法を参考にすることで、本コンペティションでも良いスコアを出すことができると考えています。本コンペティションの詳細な解法については、コンペティション終了後に寄稿する予定です。
本コンペティションでは、金融機関が扱うデータを模して人工的に作成されたデータの権利保護のため、データの提供はDatabricks Inc.社のDatabricksというクラウド型の統合データ分析基盤上で行われます。
さらにDatabricks外へのデータの持ち出しが禁止されているため、データ分析やモデル構築もDatabricks上で行うことが必須となっています。そこで、本記事では「第1回金融データ活用チャレンジ」を題材に、EDA~モデル構築/管理までをDatabricksで実施する方法をご紹介したいと思います。
Databricksとは
DatabricksとはDatabricks Inc. が提供するクラウド型の統合データ分析基盤です。データベースでのデータ管理からデータ分析/加工・機械学習モデルの構築/管理までを1つのブラウザ上で行うことができます。
Databricksでは、Jupyter Lab6)https://jupyter.org/やColaboratory7)https://colab.research.google.com/の様にブラウザ上で動作する対話型実行環境でデータを分析することができます。さらに、分析したデータからGUIでグラフを作成できたり、mlflow8)https://mlflow.org/を用いての実験管理が容易であったりと、サクッとEDA~モデル作成ができる点が便利だと感じました。
データ
Databricksでの分析方法を紹介する前に、本コンペティションのデータについて説明します。
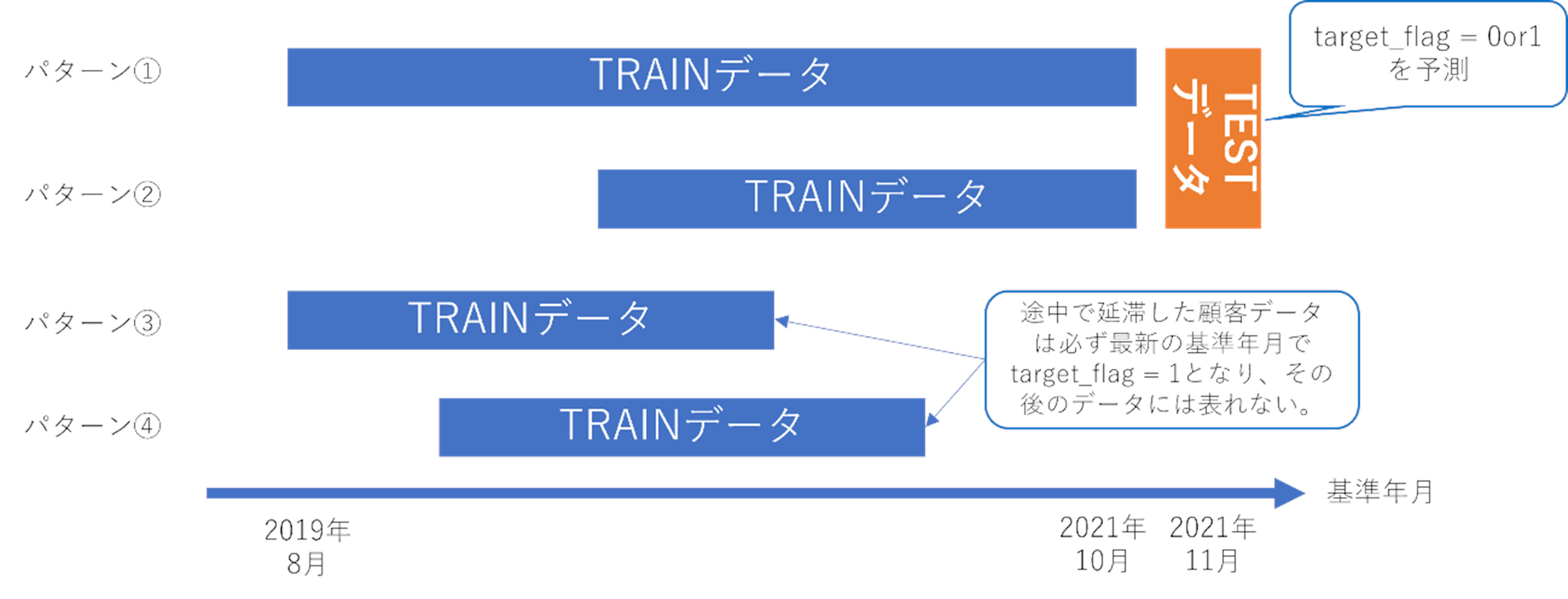
本コンペティションでは教師データとして、1,144,674件の金融データが与えられています。また、教師データの期間は2019年8月~2021年10月であり、2021年11月のテストデータに対して住宅ローンの延滞確率を予測するタスクとなっています。顧客id(gid)のユニーク数は50,622人であり、その中で下図パターン①②に該当する顧客は36,859人となっており、これらの顧客に対する予測を行います。教師データの中でtarget_flag=1となるデータは、下図パターン③④に該当する顧客の最新基準年月のデータのみとなります。
今回のコンペティションでは特徴量エンジニアリングやアルゴリズムだけではなく、不均衡データの扱い方によって大きくスコアが左右されそうです。
DatabricksでのEDA
本コンペティションでは各参加者アカウントに対してDatabricks上でtrain/testデータがテーブルに格納されて共有される形式でした。
Databricks上では以下のコードでテーブルデータを読み込み、pandasのDataFrameに変換することができます。
# テーブルを pandas dataframe に変換
df_train = spark.table("main.db_fdua_org.train").toPandas()
また、display()関数を使用することで、pandas DataFrameの出力をGUIで操作することが可能になります。
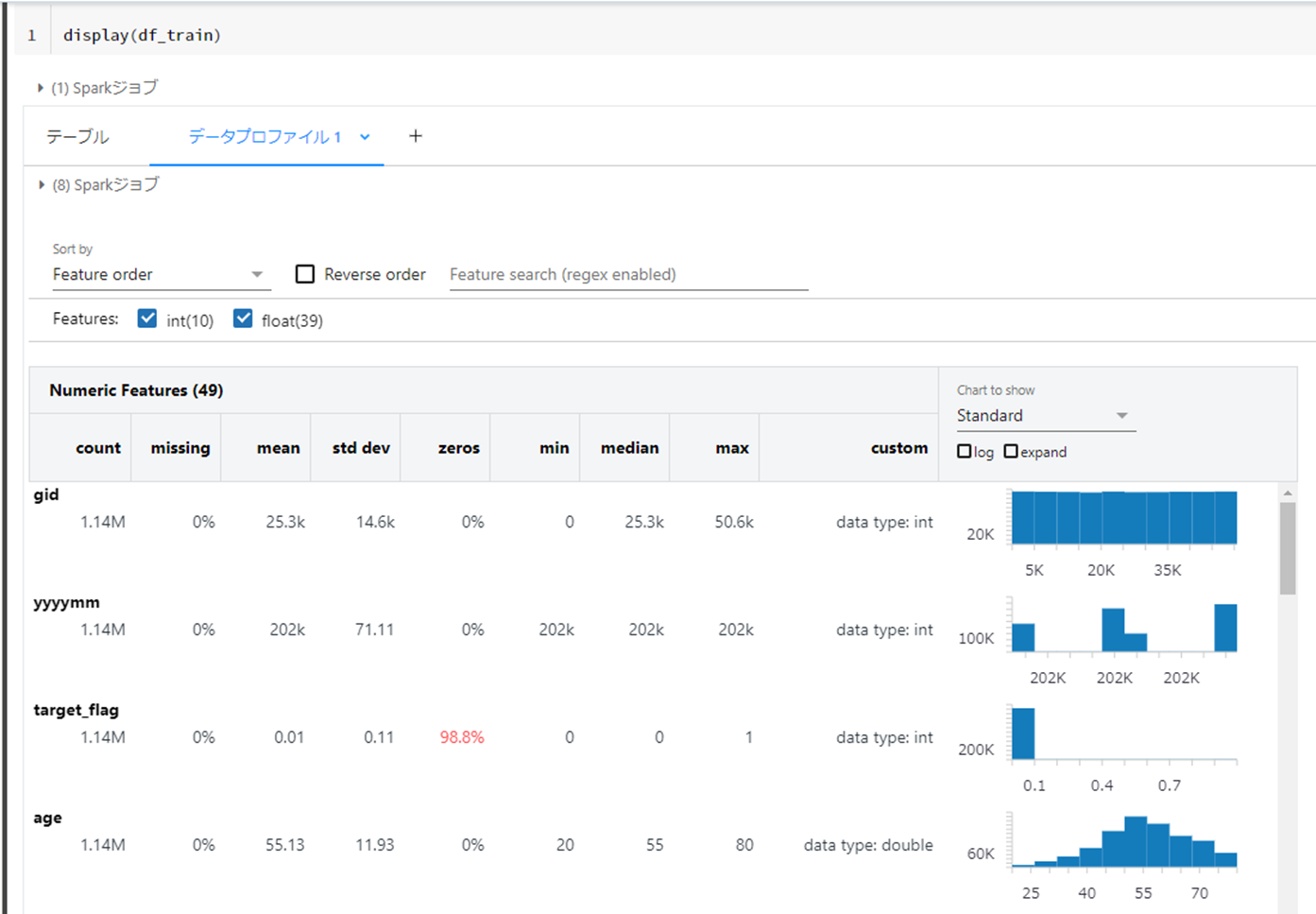
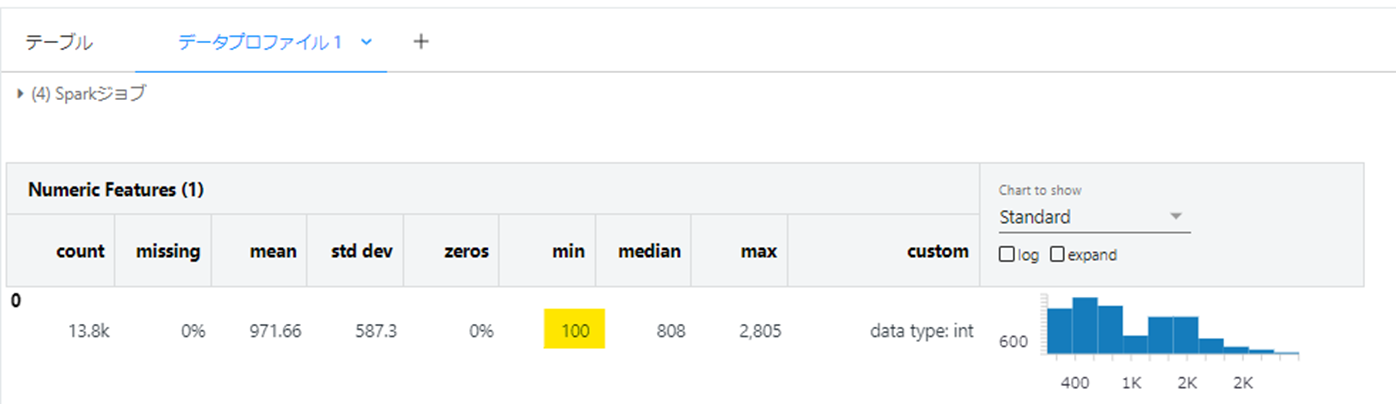
pandas.DataFrameのdescribe()メソッドでの基礎統計量の確認やmatplotlibを使用した可視化作業等が、GUIで実施できるイメージです。
下図ではtarget_flag=0の割合が98.8%と非常に不均衡な正解ラベルであることがわかります。
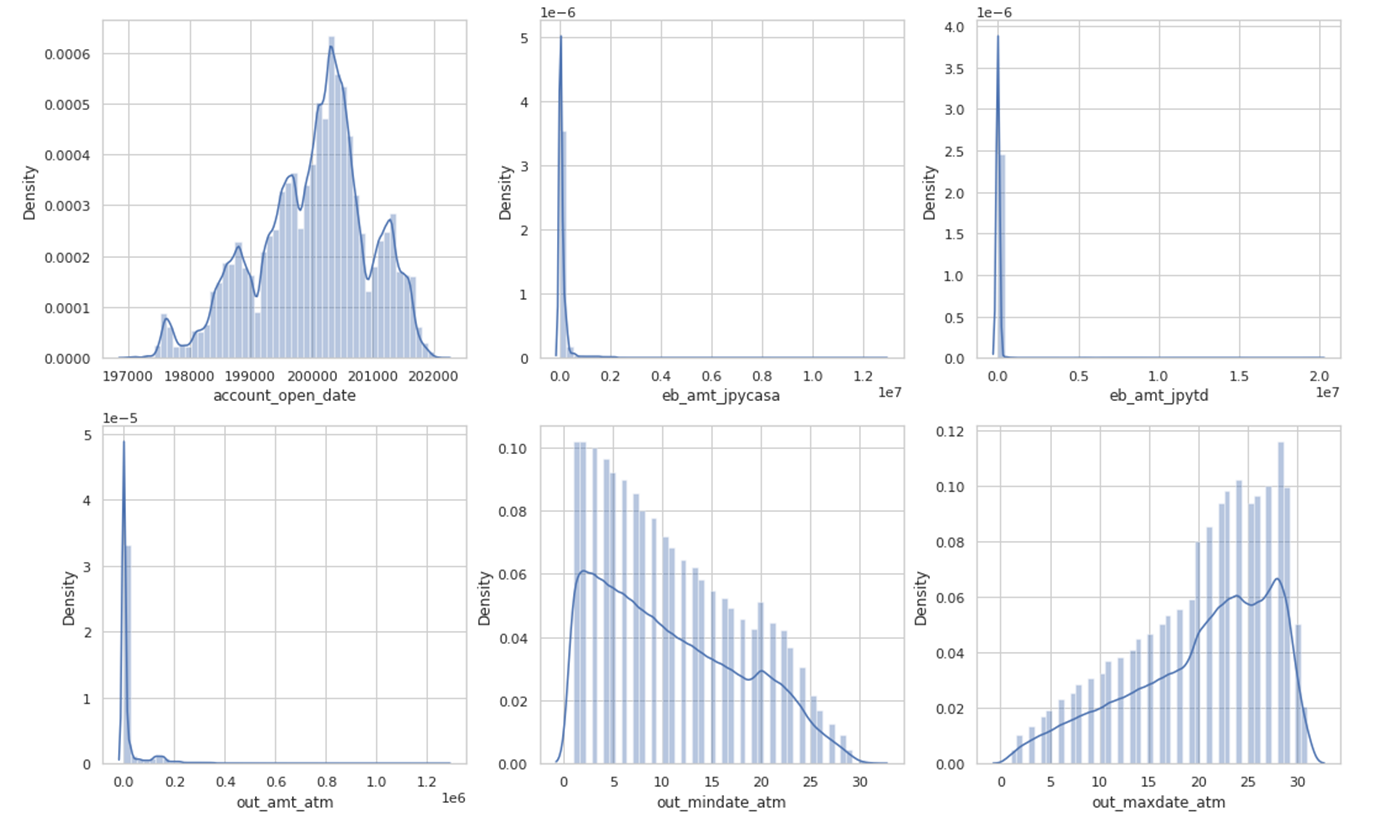
次に、seabornのdistplotを用いて各特徴量の分布を確認します。今回seabornはデフォルトで分析環境にインストールされていましたが、必要なライブラリはセル上で!pipを用いてインストールが可能です。
amt系の特徴量、つまり資産残高や月のATM利用金額等に外れ値が含まれていることがわかりました。IQRの1.5倍を上下限としてクリップするなどの外れ値補間処理を入れることが考えられます。
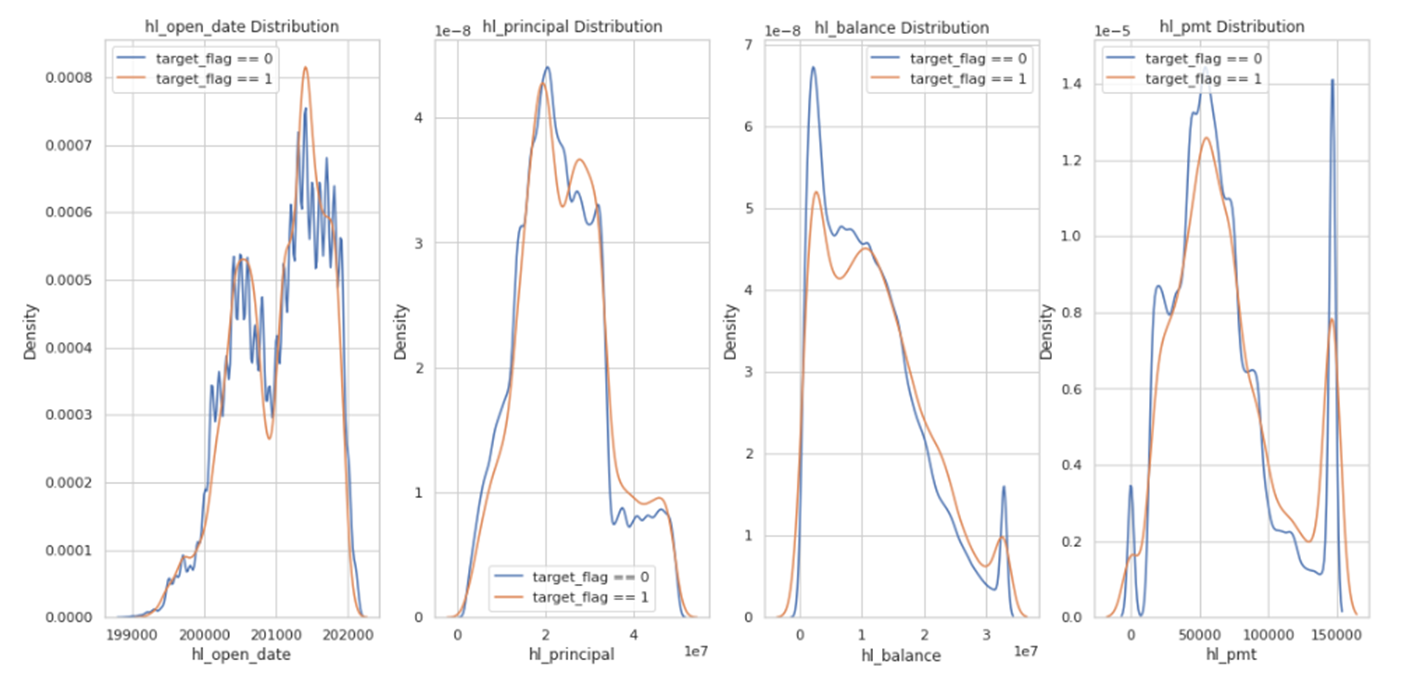
さらにtarget_flag=0 or 1での特徴量の分布の違いを確認しておきます。
こちらの分布に大きな違いがある特徴量はターゲットを説明する際に有用な情報を持っていると考えられるのですが、今回はターゲットによる特徴量の分布に大きな差は見られませんでした。
最後に、ローン開始日から延滞(target_flag=1)となるまでの期間を見てみます。
tmp_df = df_train[~df_train["gid"].isin(df_test.gid.unique())]
tmp_ser = tmp_df.groupby("gid").max()["yyyymm"]
# ローン開始日から延滞までの期間
default_loan_kikan_list = []
tmp_df["default_loan_kikan"] = tmp_df["yyyymm"] - tmp_df["hl_open_date"]
for i, ym in tmp_ser.items():
default_month = tmp_df[(tmp_df["gid"] == i) & (tmp_df["yyyymm"] == ym)]["default_loan_kikan"].values
default_loan_kikan_list.append(default_month)
display(pd.DataFrame(default_loan_kikan_list))
target_flag=1になるのはローン開始日から必ず1年以上経ってからということがわかりました。
このことより、Testデータのhl_open_date > 202011のデータのtarget_flagを全て0とする後処理を入れるとスコアアップが望めるかもしれません。
mlflowでのモデル管理
Databricksのメリットの1つは、mlflowがDatabricksのUIおよびノートブックと統合されていることで、学習結果をシームレスに確認できることだと思っています。
今回はLight GBMを用いて予測モデルを作成し、実験管理を行っていきたいと思います。
MlflowではExperiment > Run > Description, Parameters, Metrics, Tags, Artifactsという構成でモデルが管理されています。DatabricksではExperimentにノートブック名が割り当てられます。また、Runはモデル学習時にwith句を用いて設定することができます。Run名を指定することで、1つのノートブック(Experiment)に複数のRunを紐づけて記録することが可能です。さらに、Runに対してモデルのパラメータ(Parameters)やvalidationスコア(Metrics)等を紐づけて記録することができます。
実装例を以下に示します。
import mlflow
# RUN(≒実験)の名称
RUN_NAME = "EXP_01"
# モデルの名称
MODEL_NAME = "lgbm_model_01"
# 実験の概要
DESCRIPTION = "Light GBMで予測モデルを構築"
# Light GBMのパラメータ定義
lgb_params = {
'num_leaves': 63, # default = 31,
'learning_rate': 0.01, # default = 0.1
'feature_fraction': 0.8, # default = 1.0
'bagging_freq': 1, # default = 0
'bagging_fraction': 0.8, # default = 1.0
"objective": "binary",
"metric": "auc",
"boosting": "gbdt",
"random_state": SEED,
"verbose": -1,
}
# 学習定義
def lgb_train_val(X_train: pd.DataFrame, y_train: pd.Series, X_val: pd.DataFrame, y_val: pd.Series, params: dict):
lgb_train = lgb.Dataset(X_train, y_train, weight=compute_sample_weight(class_weight='balanced', y=y_train).astype('float32'))
lgb_val = lgb.Dataset(X_val, y_val)
lgb_result = {}
lgb_model = lgb.train(
params,
lgb_train,
valid_sets=[lgb_train, lgb_val],
valid_names=["train", "val"],
evals_result=lgb_result,
num_boost_round= 10000,
early_stopping_rounds = 100,
verbose_eval=500,
)
lgb_y_pred = lgb_model.predict(X_val, num_iteration=lgb_model.best_iteration)
return lgb_model, lgb_y_pred, lgb_result
with mlflow.start_run(run_name=RUN_NAME) as run:
# lightgbmでの学習を記録
mlflow.lightgbm.autolog()
# 実験の内容をタグに記載
mlflow.set_tag("実験概要", DESCRIPTION)
# モデルの学習&検証
lgb_model, lgb_y_pred, lgb_result = lgb_train_val(X_train, y_train, X_val, y_val, lgb_params)
# モデルを記録する
mlflow.lightgbm.log_model(lgb_model, MODEL_NAME, input_example=X_train)
# validationのauc値を計算する
auc = roc_auc_score(y_val, lgb_y_pred)
# auc値を記録する
mlflow.log_metric("auc", auc)
Databricksでは、mlflowの結果をGUI上で確認することができます。
画面左上のペルソナからMachine Learning を選択します。
すると左のタブにエクスペリメントが追加されます。このエクスペリメントが先ほど実行したノートブックの名称となっています。
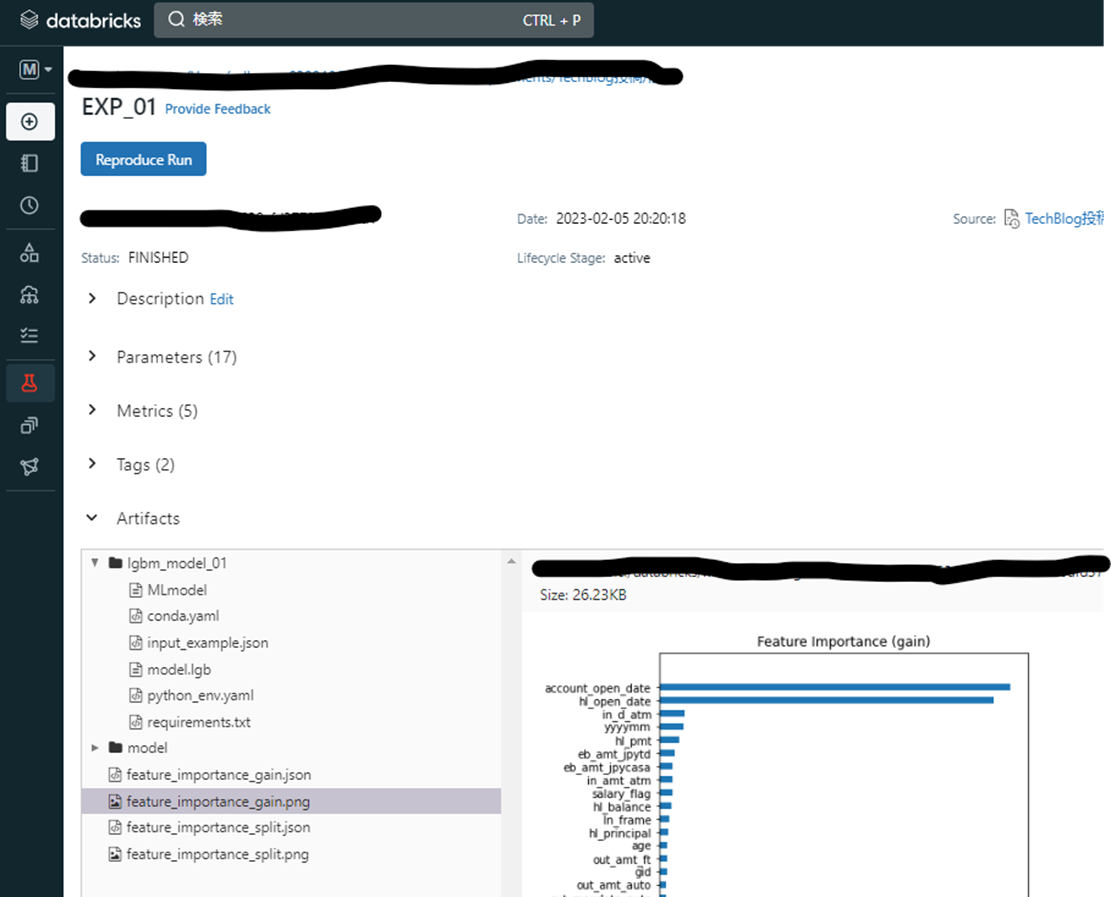
さらにエクスペリメントの中にRunがあり、Runの中にParameters等が記録されています。Light GBMの場合、Artifactsにfeature_importaceを自動で可視化してくれているため、matplotlibで可視化することなく重要度を確認することができます。
またDatabricksでは、モデルをモデルレジストリに登録することでDatabricks内で簡単にモデルを呼び出すことが可能となります。Mlflowでは、Run単位で学習が管理されているため、まず登録したいモデルを学習した際のRun IDを取得します。そして取得したRun IDとモデル名を用いてモデルレジストリに登録します。以下にモデル登録を行うコードを記載します。
# RUN(≒実験)の名称
RUN_NAME = "EXP_01"
# モデルの名称
MODEL_NAME = "lgbm_model_01"
# 指定したRun名のうち最新のもののidを取得する
run_id = mlflow.search_runs(filter_string=f'tags.mlflow.runName = "{RUN_NAME}"').iloc[0].run_id
model_uri = f"runs:/{run_id}/{MODEL_NAME}"
model_details = mlflow.register_model(model_uri=model_uri, name=MODEL_NAME)
モデルのロードと予測
Databricksでは、前項で登録したモデルを簡単に呼び出して使用することができます。ただし注意が必要な点があり、それはモデルのバージョン指定です。Mlflowでは1つのモデル名に対して、実行毎にバージョンを分けて保存することができます。したがって、呼び出し時にもモデル名に対してバージョンを指定する必要があります。
以下に最新バージョンを取得してモデルを呼び出す方法を記載します。
# モデルのロード
import mlflow.pyfunc
from mlflow import MlflowClient
# モデルの名称
MODEL_NAME = "lgbm_model_01"
client = MlflowClient()
model_version = client.get_latest_versions(MODEL_NAME)
# 結果はdictのリストで返ってくるので、その中のversion内に最新のバージョンが入っている
print(model_version[0].version)
# 1つのモデル名に実行毎にversionが付与されるため、指定が必要
model_version_uri = f"models:/{MODEL_NAME}/{model_version[0].version}"
print("Loading registered model version from URI: '{model_uri}'".format(model_uri=model_version_uri))
lgb_model = mlflow.pyfunc.load_model(model_version_uri)
最後に予測ですが、こちらは先ほどロードしたモデルでpredictするだけです。
y_preds = lgb_model.predict(X_test) y_pred_ser = pd.Series(y_preds) y_pred_ser.name = target_col result_df = pd.concat([X_test["gid"].reset_index(drop=True), y_pred_ser], axis=1)
SIGNATEへの投稿はDatabricks上でSIGNATE CLIを用いて行うことができます。
まとめ
本記事では、「第1回金融データ活用チャレンジ」を題材に、Databricks上でEDA~モデル学習/管理までを行う方法をご紹介しました。私自身、本コンペティションで初めてDatabricksを触りましたが、データの統計量を自動で可視化したり、mlflowを用いてシームレスに実験管理ができたりするため、特徴量エンジニアリングやアルゴリズムの構築に時間を割くことができるようになると感じました。可視化やモデル管理のハードルが下がることで、データ分析に携わる人が増えると嬉しいです。今後もコンペティション等で利用する機会が増えてきそうなため、引き続き注目していこうと思います。
次回は本コンペティションの具体的な解法について記事を書く予定のため、ご興味を持っていただけた方は次回もお楽しみにお待ちください。
References