Kaggle BirdCLEF 2022コンペ 5位解法
こんにちは。NRIデジタルの奥山です。
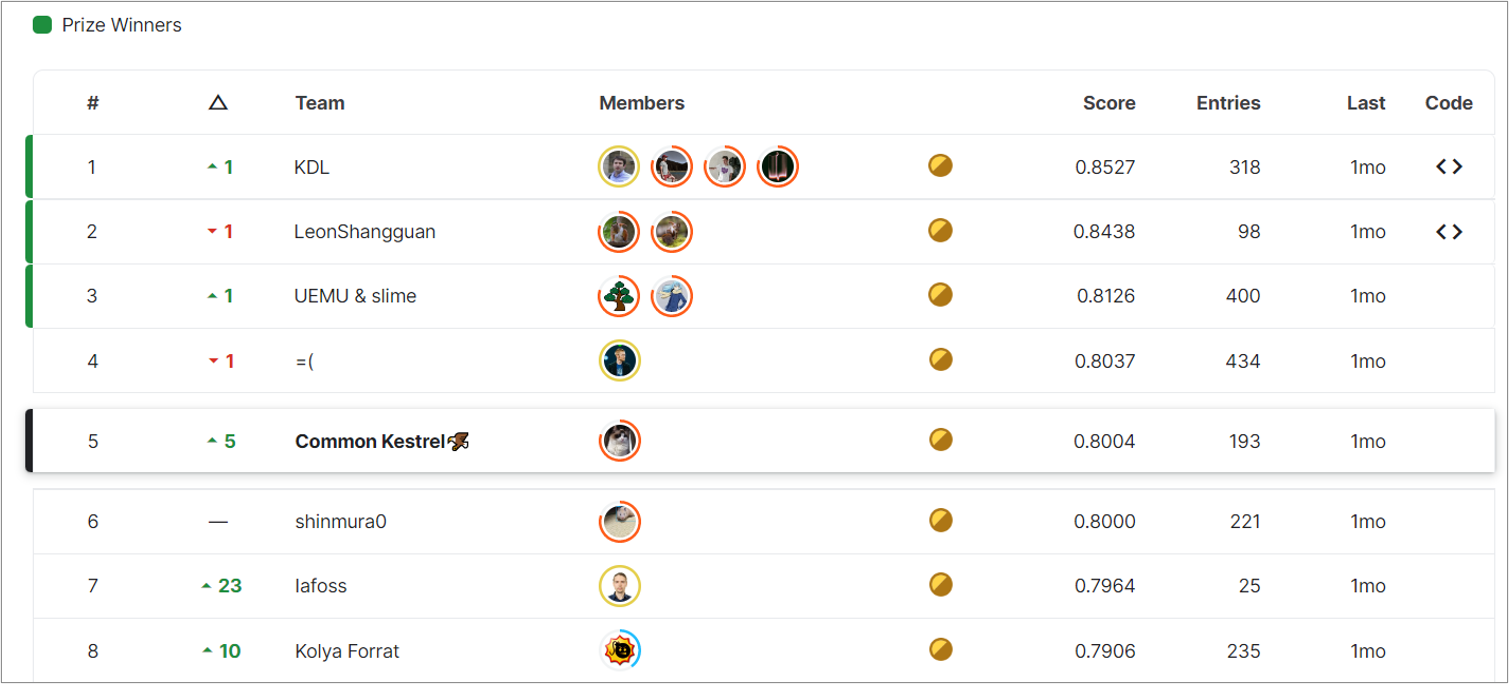
先日Kaggleで行われたBirdCLEF 2022というデータ分析コンペに単独で参加し、807チーム中5位(金メダル1)本コンペでは上位11位までが金メダル、同50位までが銀メダル、100位までが銅メダル入賞圏でした。https://www.kaggle.com/progression)に入賞する事ができました。今回は参加記録として私の取組や上位チームの解法を紹介していきます。
データ分析コンペとは
データ分析の腕を競う競技大会です。データ分析版の競技プログラミングと言えばIT技術者の皆様には伝わり易いかもしれません。コンペの運営者は世界中のデータ分析技術者に対し、解決して欲しい課題と対価としての賞金を提供し、大会の参加者から広く優秀なモデルを募ります。参加者はさまざまな企業の抱える課題解決にチャレンジできると同時に、他の参加者の知見を得ることのできる学習環境としての側面もあります。
Kaggleは2010年にサービスを開始した世界最大のデータ分析コンペ運営プラットフォームであり、2017年にはGoogleに買収され、現在はAlphabetの傘下となっています。Kaggleの登録ユーザー数は800万人以上と言われ、日夜多くのデータ分析技術者がデータ分析の腕を競い合っています。Kaggle以外にも、SIGNATEやNishikaなど多くのコンペプラットフォームが存在し、それぞれにさまざまな興味深いコンペ課題が提供されています。
NRIデジタルでは多くのデータサイエンティストがデータ分析コンペに取り組んでおり、得られた知見を日々の業務に活用しています。直近では自動車の速度推定コンペや類似画像の検索コンペで賞金圏入賞を果たすなど、NRIデジタル社員で組まれたチームが上位入賞を果たすシーンも増えてきました。
BirdCLEF 2022コンペ概要
※ 以下の章は機械学習を使った音声認識タスクの経験があることを前提に記載しています。未経験の方は同タスクの参考書・入門記事と併せてご覧頂ければより分かり易いかもしれません。私のオススメはインプレス社「Pythonで学ぶ音声認識」です。
今回私が参加したBirdCLEFは鳥の鳴き声分類をテーマとしたデータ分析コンペティションのシリーズで、2020年から毎年開催されています。今年で3回目の開催となるためか、SNSなどではBirdCLEF 2022は 鳥コンペ3 という愛称で呼ばれる事が多いようです。今年はハワイに生息する絶滅危惧種の鳥に焦点が当てられ、与えられた学習データセットの中からそれらの鳥達を高精度に識別するモデルの開発が求められました。
今回私はこの問題に対し、画像認識ベースの音声分類モデル(合計9モデル)のアンサンブルを開発し最終サブミッションとしました。
以下ではベースとなった音声分類モデルの簡単な解説と、スコア向上に有効だったと考えるポイント3点を紹介します。ここで説明しきれなかった解法の詳細や説明についてはKaggleのDiscussionに記載していますので、是非そちらもご参照ください。
音声分類
音声分類をする際、よく用いられるのが画像認識向け深層学習モデルを使用した手法です。音声は時系列データの中でもサンプリング周波数の高い(時間当たりのデータ数量の多い)データであるため、時系列データから直接クラス分類をするような手法は計算コストが非常に高く付いてしまいます。そこで、この手法では短時間フーリエ変換などを用いて音声データを一度画像データに変換した後、その画像を分類する問題に落とし込むというアプローチを取ります。
画像データに変換する事でデータ量がある程度間引ける上に、画像分類は昨今発展の著しい深層学習が得意とする分野の一つであるため、その豊富な知見を流用することも可能というわけです。鳥コンペ3でも多くの参加者がこの画像データを介した手法を利用していました。
ポイント1: 弱ラベル対策
本コンペの精度評価では60秒の音声ファイルが複数個提供され、その60秒のファイル内で5秒毎に何の鳥が鳴いているのか、という予測値を提出する事が求められていました。つまり、予測モデルは何の鳥が鳴いているのか、というクラスラベルだけではなく、いつその鳥が鳴いたかという時間ラベルも予測する必要があります。一方で学習用データとしては音声ファイルとクラスラベルしか与えられず、更に音声ファイルの長さは数秒から数時間までさまざまで、かつファイル内で鳥の鳴く箇所もかなりバラツキがあるという状況でした。例えばこちらは実際に学習データとしてホストより提供された音声ファイルの一つですが、全く鳥の鳴かない時間が相当時間存在する事が分かります。
そのため、参加者は何らかの手段で鳥の鳴いている箇所を学習データから推測する必要がありました。このように、機械学習で本来必要なラベルに対して部分的にしかラベル付けされていないデータセットは弱ラベルデータと呼ばれます。
昨年行われた鳥コンペ2も鳥コンペ3同様、時間ラベルのない音声分類タスクだった事から、鳥コンペ2で有効性の高かった弱ラベル対策を今回も引き続き採用するチームが多かったようです。
私も鳥コンペ2の上位解法で採用されていたmixupベースの対策手法を最終サブでは使用させて頂きました。この手法では
- 学習用音声ファイルからランダムに30秒間の区間を切り出し
- 切り出した音声ファイルを画像ファイルに変換
- 画像ファイルを5秒毎の6つの区間に分割
- 6区間の画像ファイルを学習バッチ全体にわたって相互に混合(mixup)
という操作を学習時の前処理として行います。
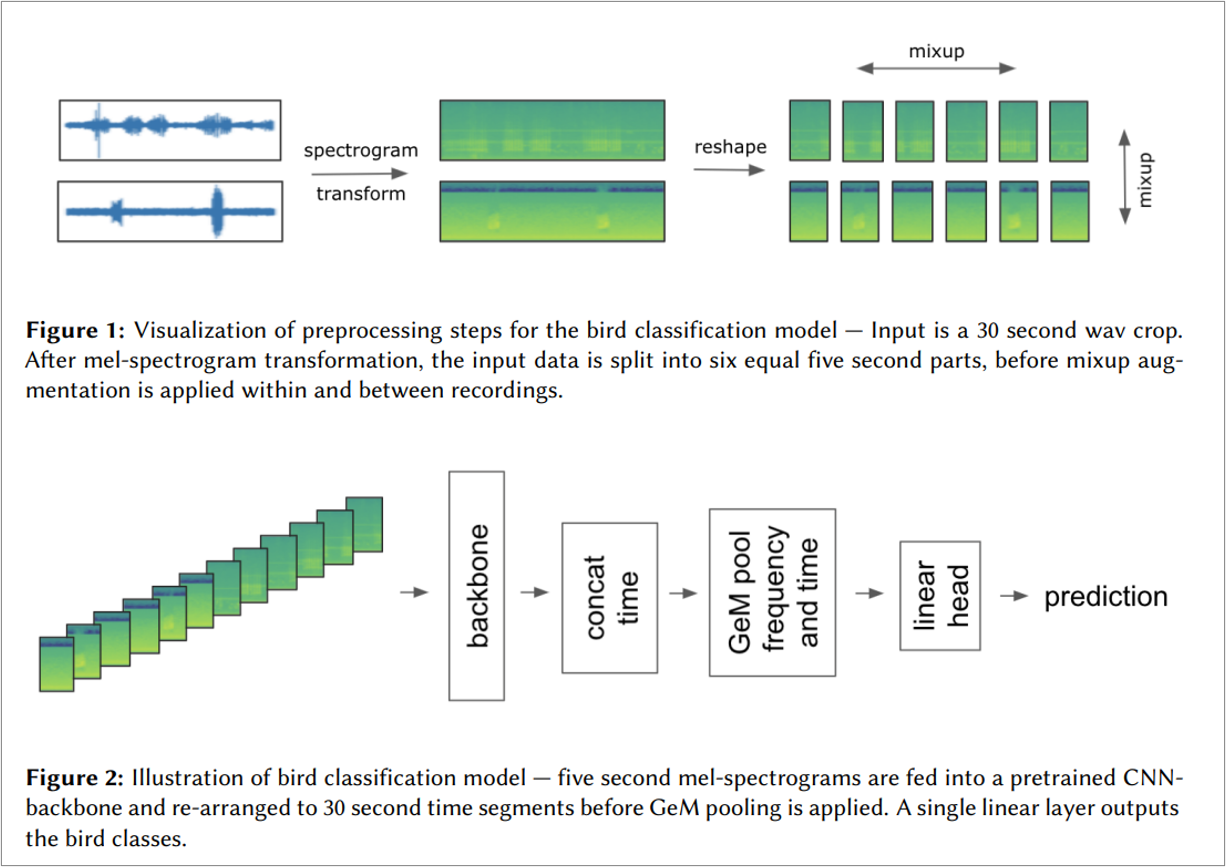
直観的には、どのタイミングで鳴いているかは不明だが、どこかで鳥が鳴いているはずの音声ファイルを前後ごちゃまぜにしてミキシングする事で、ファイルのどこでも満遍なく鳥が鳴いている音声ファイルを作成する…というイメージでしょうか。詳細についてはこの解法のオリジナルの考案者である、best fittingチームによる論文が非常に参考になります。
コンペ中盤、弱ラベル対策が中々上手く行かずスコアが伸び悩んでいた所、この手法を採用してからは終盤まで安定したペースで精度向上を進める事ができました。mixupというテクニックは一般的にはData Augmentation2)学習データに様々なエフェクトを適用し(例えば音声データの場合、音量増減や各種ノイズの挿入など)、データを水増しすることでモデルの性能を上げるテクニックのために使用するものとして知られていますが、それを弱ラベル問題への対策として使用するアイディアのスマートさには驚かされました。
ポイント2: データ不均衡
訓練データのクラス数が大きく偏っている事もこのコンペの大きな特徴でした。下記は予測対象である21鳥種それぞれの学習用データ数を表したグラフです。
最も頻出のskylar(ヒバリ) は500ファイル以上の学習データに出現する一方、maupar(オウムハシハワイマシコ)はわずか1ファイルしかデータとして与えられていません。その他にも数ファイルしか学習データのない鳥種がいくつもあり、クラス毎のファイル数に大きな不均衡が存在することが分かります。
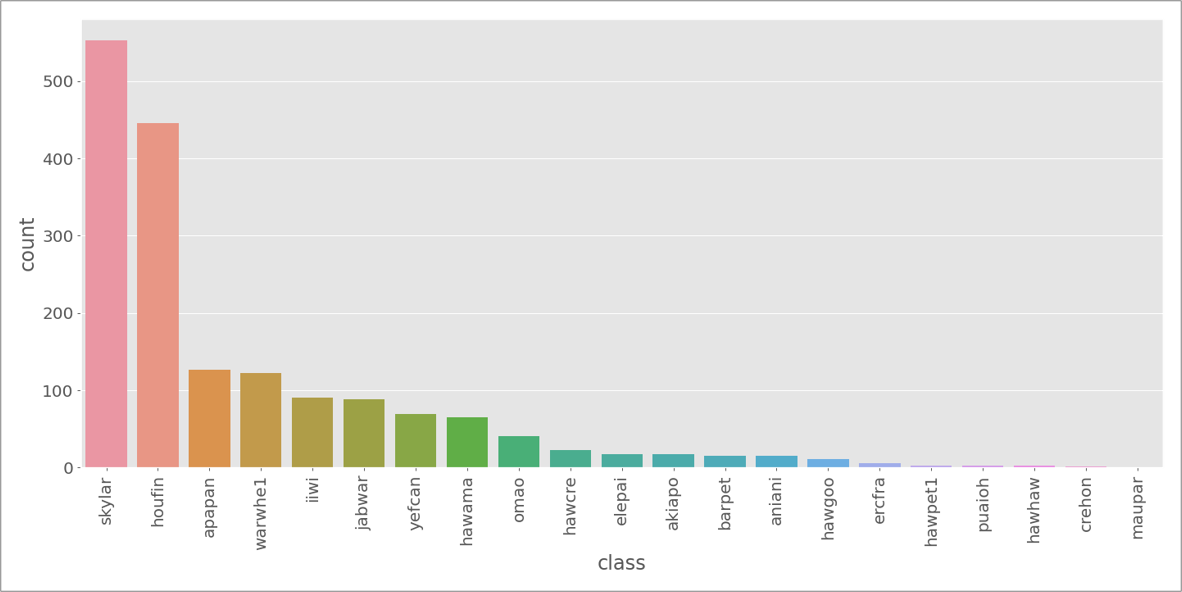
こうしたデータをそのまま学習すると、多数派クラスの識別精度ばかりが良いモデルができてしまいます。一方、本コンペは評価指標としてマクロ平均のF1スコアを用いていたため、少数派クラスの識別精度もバランスよく上げないとスコアの改善が難しいという課題がありました。
データ不均衡への対策は色々な手法が知られていますが、私はシンプルにオーバーサンプリングによる解決を試みました。オーバーサンプリングとは少数派クラスのデータを複製する等して、数を増幅する手法です。
今回の解法では単純にファイルをコピーするのではなく、実際の学習データ音声を聞きながら手作業で増幅すべき音声を取捨選択するという、いわゆるハンドラベリングに近いスタイルで増幅を行いました。具体的には、少数クラス(目安として1クラス当たりのファイル数が20ファイル未満のクラス)に対して次のような作業を行っています。
- 音声エディタで学習用ファイルを開く
- 対象の鳥種が鳴いている部分を別ファイルに切り出し
- 切り出した音声ファイルにリバーヴ・エコー・ノイズ増減といったエフェクトを適用
- エフェクト毎に別ファイルとして保存
こうした増幅作業を行う事で、各鳥種で少なくとも20ファイル以上のクラス数を確保する事ができました。
また、増幅されたファイルは(私が聞き間違えていなければ)確実にその鳥が鳴いている箇所のみを切り出しているため、間接的にポイント1で指摘した弱ラベル対策としても有効でした。スコア上もこのオーバーサンプリングは非常に効果的で、銀メダル圏上位から金メダル圏へと一気にスコアを向上させることができました。
ポイント3: 閾値調整
上述の通り本コンペでは評価指標としてF1スコアが用いられている事から、予測の後処理として、音声認識モデルの出力する予測確信度(0~100%)を予測クラス(ある鳥種が 鳴いた/鳴いていない というbool値)に変換するための閾値設定が必要になってきます。この閾値調整はスコアへのインパクトが極めて大きく、多くの参加者を悩ませた問題でした。
多くの参加者が全鳥種で同一固定値の閾値をLBスコアやモデル予測値の分布から探索するアプローチを取っていました。一方、私は21鳥種毎の閾値を予測値の分布から探索するアプローチを取っています。こう書くと複雑な最適化のプログラムを書いたように見えるかもしれませんが、実際にはこちらのPost Processingの節に記載した通りPandasの関数1行で済んでしまいます。
こうした実装をした意図として、今回はポイント2で記載した通り、極めてデータ不均衡な問題設定であることが念頭にありました。
下図は最終サブミッションに使用したモデルで検証データに対し出力した、先ほどのskylar(最多クラス)と maupar(最小クラス)の予測確信度の分布を示しています。両者の分布の形状はまったく異なっており、それぞれに異なる閾値を設定した方が良さそうです。
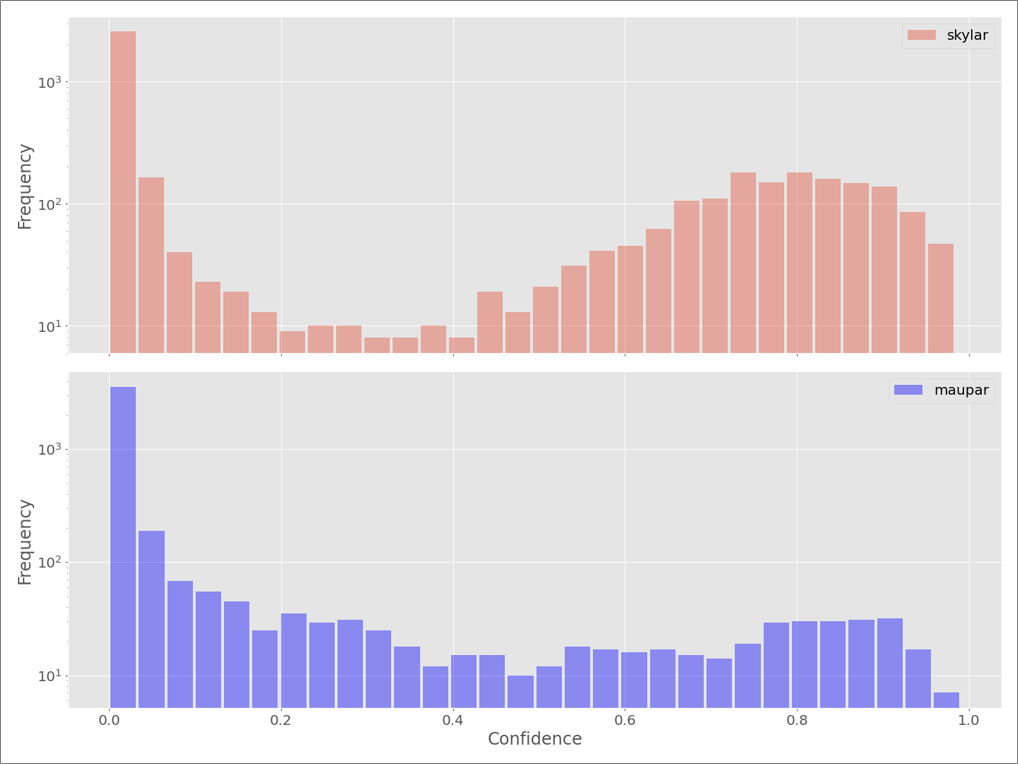
結果として、この閾値設定方法もスコアの押し上げに大きく貢献してくれました。スコアの向上もさることながら、この手法を採用してからは予測提出毎のスコアのブレ幅が小さくなり、トライアンドエラーで実験を繰り返す際の安定感が非常に高くなった点も副次的なメリットでした。
他チームの動向
最終的には上位チームの多くが比較的似た手法を採用していたのですが、その中から気になった2点を紹介します。
BirdNET
1位・2位のTop2チームが解法として採用していました。BirdNETは本コンペのホストであるコーネル大学の方が開発している鳥の音声分類モデルで、Githubでソースコードや学習済のモデルが公開されています。実はこのBirdNET、コンペ開始当初は利用が禁止されていたところ、終了直前になって一転許可されたという曰くつきのモデルになります。最上位2チームがそんなモデルを使用していた事から、コンペ終了直後はホストの判断に疑問を投げかける投稿でDiscussionやSNSがちょっとした炎上状態になってしまったのですが…最終的には順位変動もなく、利用問題なしという所で落ち着きました。
私の開発したモデルも結局BirdNETのスコアには及ばず、ホストのモデルに勝てなかったことついては悔しい思いもありますが、一方、自分の調査能力が至らなかった(そもそもコンペ終了までBirdNETの存在に気が付かなかった)点については反省せざるを得ません。鳥コンペ3に限らず、最近のデータ分析コンペでは公開されている学習済モデルをあえて再学習せずにそのままソリューションに組み込むというのは一つの常套テクニックになっており、今後もこうしたソリューションは増えて行くのではないかと言うのが個人的な予想です。
ハンドラベリング
私も含め、多くの上位参加者がハンドラベリング(やそれに類するテクニック)を使っている点も印象的でした。ハンドラベリングや人工データ生成によってデータの質と量を改善するテクニックも、昨今のKaggleコンペでは欠かせないものとなっていますが、今回は上述した弱ラベル・ラベル不均衡というコンペ特性から、とりわけハンドラベリングが有効な問題設定でした。今後もコンペ参加の際は常にオプションの一つとして意識していきたいです。
まとめ
結果として5位入賞の金メダルとなり、これまで個人的な目標としていたKaggle Competition Masterに昇格する事ができました。Grand Master昇格への山場であるソロ参加での金メダル獲得の実績解除ができた点も嬉しい誤算です。一方、賞金圏(3位以内)をあと一歩の所で逃したのは非常に悔しく、やりきる力・調べきる力が不足していたという反省を次回に活かしたいです。今後も賞金圏入賞やGM昇格を目指しKaggleへの取組を続けていきます。
References
| 1. | ↑ | 本コンペでは上位11位までが金メダル、同50位までが銀メダル、100位までが銅メダル入賞圏でした。https://www.kaggle.com/progression |
| 2. | ↑ | 学習データに様々なエフェクトを適用し(例えば音声データの場合、音量増減や各種ノイズの挿入など)、データを水増しすることでモデルの性能を上げるテクニック |