Sparkのチューニング原則をAWS Glueで実践する:観測からボトルネック解消まで
目次
検証背景
AWS Glue はサーバーレスのデータ統合サービスで、Glue for Spark(AWS Glue on Apache Spark)などの実行エンジンを通じて Apache Spark のジョブをマネージドに動かせます。運用やスケーリング、監視をGlueが担い、ユーザーは処理ロジックとデータ設計に集中することができます。
Glue 上で Spark ジョブを速くしたいとき、考えるべき視点は大きく二つあります。
- Sparkそのものの最適化:エンジンの動作原理に即したチューニング
- Glueというデータ統合サービス特有の最適化:S3やメトリクス、カタログ、実行基盤の事情に起因するチューニング
本稿は、Sparkの一般的なパフォーマンスチューニングの原則を前提にしつつ、それをAWS Glue上で「どのメトリクスを見て」「どこから疑い」「どう打ち手に落とすか」を整理したものです。したがって、前半はSparkの実行モデルに即した観点整理、後半はGlue固有の観測・運用機能(Spark UI/CloudWatch/ジョブブックマーク等)を前提にした意思決定の勘所を扱います。
Sparkそのものの最適化
Sparkは、大規模データを複数の計算資源に分散して処理するためのエンジンです。
処理内容は、小さな変換処理を組み合わせる形で記述します。
たとえば、データを条件で絞り込む “filter”や、各レコードを別の形に変換する“map”といった処理関数があり、これらを連ねることでデータ処理の流れを表現します。
一方で Sparkでは、filterやmapといった変換処理をいくら重ねても、その場ですぐに実行されるわけではありません。これらは 「どのような処理を行うか」という情報として内部に蓄えられ、処理全体の構造が組み立てられていきます。
最終的に結果を取得する操作(アクション)が呼ばれたタイミングで、それまでに積み上げられた変換処理がまとめて実行されます。 この 「すぐに実行せず、全体像を見てから処理を走らせる」 性質が、Sparkで性能を引き出すための前提になります。
計画最適化はCatalyst(論理→物理プラン)などが、実行時にはAQE(Adaptive Query Execution)などが担います。例えば、データの実サイズに合わせてシャッフル後のパーティション数を自動再調整したり、JOIN戦略を実行時に切り替えたりするのがAQEの役割です。つまり、書いたコードのとおりに走るのではなく、状況に応じて“計画が変わる”のが前提になります。ゆえに、後段のチューニングでは実際に選ばれた計画(SQLタブの物理プラン)とステージの指標を必ず見に行く必要があります。
Glueというデータ統合サービス特有の最適化
Glueの利点は、観測と運用が最初から揃っていることです。Spark UIを有効化すると、Sparkイベントログが約30秒おきにS3へ保存され、実行中にも完了後にもUIを開いて深掘りできます。履歴の横比較が必要なら、S3のイベントログを指してSpark History Serverで読むことも可能です。
俯瞰的に見るにはAmazon CloudWatchメトリクスを利用することもできます。たとえば ETL Data Movement(S3 I/O)やData Shuffle Across Executors
(glue.driver.aggregate.shuffleBytesWritten /shuffleLocalBytesReadなど)は、いつ・どの程度データが動いたかを把握する助けになります。
さらに Glueには、ジョブブックマーク(既処理データの再処理を防ぐ状態管理)や、JDBCの並列読取(分割列・並列度の指定)といった読みすぎないための素地もあります。S3のファイル形式・サイズ・圧縮・パーティション配置は読み量と並列効率に直結するため、Glueにおける性能改善を考える際にデータの置き方も重要になります。
AWSのGlue のパフォーマンス・プラクティス
ではAWSではパフォーマンスチューニングをどのようにした方がいいとしているか。
AWS Prescriptive Guidanceでは、前提(クラスタ容量の調整、Glueの最新版利用など)を含めた上で、複数のチューニング観点が整理されています。
本稿では、その中でも実装・設計として効きやすい次の5つに絞って説明します。
- データスキャンを減らす
- タスクを並列化する
- シャッフルを最適化する
- 計画オーバーヘッドを最小化する
- UDF を最適化する
パフォーマンス・プラクティス
以降では、AWS Prescriptive Guidanceの5項目について、なぜ重要なのかという理由と、具体的な方法について説明します。方法は、Spark UIを用いずに可能なものと、活用したものに分けて説明します。
Spark UIは有用ではあるものの全体的に重い傾向があり、用いない範囲で改善できるならその方が効率的である場合も多いためにこのような構成を取ります。
以下はAWSが提供しているパフォーマンス・プラクティスの項目に沿って章立てし、順に説明していきます。
1.データスキャンを減らす
なぜ“データスキャンを減らす”ことが重要か
性能チューニングを語るときデータスキャン量の話は避けては通れません。分散処理の入口にある「読む」という行為が、処理全体の土台コストになりやすい構造を持っているからです。
Glueジョブは基本的に、S3上のデータを読み込み、デコードし、必要な行や列を残しつつ変換し、最後に結合や集約、書き戻しへ進みます。この最初の読み込み段階で対象が大きいと、I/Oが増えるだけでなく、読み込んだデータを解釈するためのCPUコストや、タスクの数・スケジューリングのオーバーヘッドも増えます。
さらに厄介なのは、スキャン量が後段の重さを増幅させる点です。Sparkでコストが跳ねやすい操作の代表がjoinやgroupByのようなシャッフルを伴う処理ですが、スキャン量が大きいほどシャッフルに流れ込む材料が増え、中間データの転送・並べ替え・ハッシュ計算・メモリ圧迫が連鎖します。入力量と時間の比例関係といった単純な伸び方では済まず、より多くの時間を要することも多いです。だからこそ、後段のシャッフル最適化に取り組む前に、そもそも読まない状態を作ることが非常に重要になります。
加えてGlueでは、実行時間が伸びるほどコストにも反映されやすい料金設計になっています。DPUを増やして押し切ろうとしても、ボトルネックが読む量そのものにある場合、伸びしろは限定的になりがちです。一方で、スキャン量が減ればI/OもCPUもシャッフルの材料も同時に減り、実行時間短縮がそのままコスト改善に繋がりやすい、という分かりやすい効果が得られます。
要するに、データスキャン量削減はGlue・Sparkが持つ入出力中心の実行モデルと、シャッフルによる増幅リスク、そしてコスト構造が噛み合った結果として、優先的に解消しなければならない問題となると言えます。
データスキャン量を把握する方法
Spark UIを用いずに可能な方法
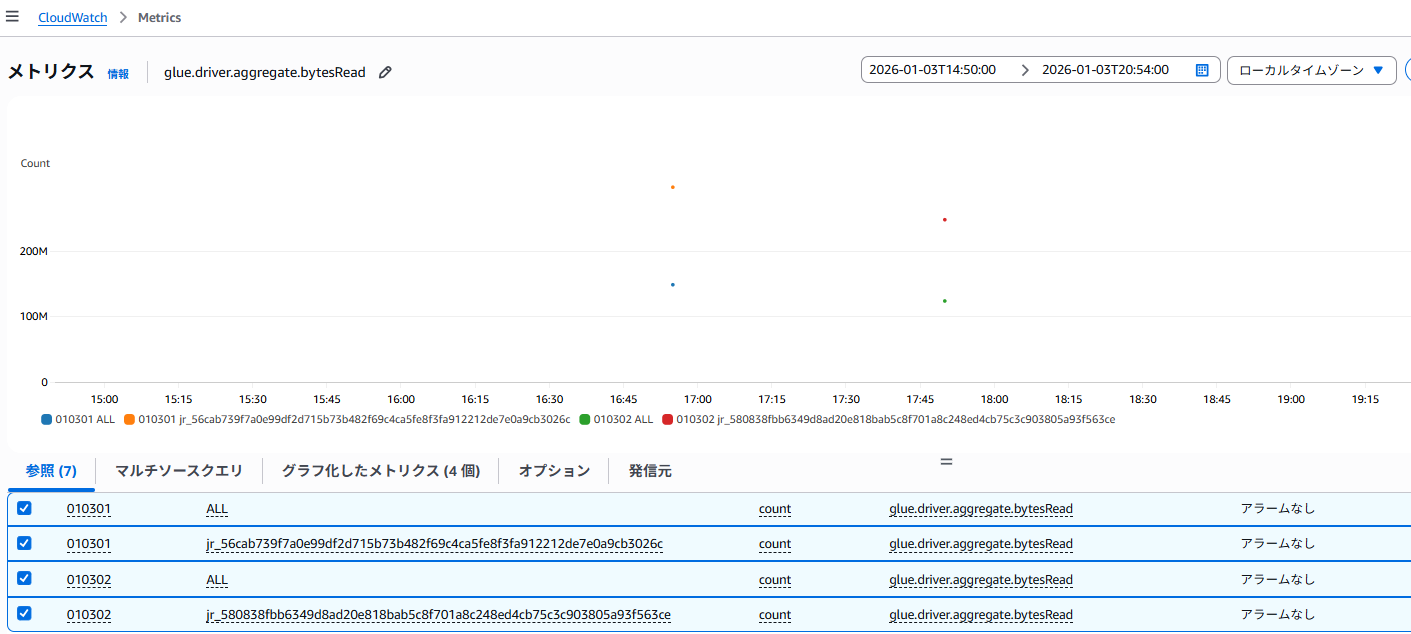
・CloudWatch/Glueメトリクスでの bytesRead の比較・explain( ) による論理/物理計画の確認GlueジョブのメトリクスでbytesReadを確認できるのでまずはそこを確認することで読み込んでいるデータの総量は確認することができます。
また、df.explain(extended=True)などで計画を出力し、最適化やシャッフルが想定通りになっているかを確認することも基本的かつ有効な確認手段と言えます。
EXPLAIN – Spark 4.1.1 Documentation
コードやSQLの構造上で不必要に対象のデータを読み込む構造になってしまっていないか といった点も確認することは重要です。例えば、Glue データカタログやIceberg/Hiveテーブルで、そもそもパーティションが切られていなかったり、日付や区分コードでパーティションが切られているのに非効率的にデータを読む構造(クエリ側でそのパーティションキーをWHERE条件に含んでいない・不要なカラムまで読み込んでいる、s3//bucket/top-level-folder/のようにパスを丸ごと読んでいる)になってしまっていないかといった点もチェックが必要です。
・小さいファイル/フォーマットの問題単純に“ファイル数が異様に多いディレクトリを丸ごと読んでいないか”や、“小さなファイルを多数読み込んでいないか”も、基本的なことですが注意が必要です。また、gzip 圧縮単一大ファイル(スプリット不可)などは、1タスクで全体を読み切る → 並列化もできず、フルスキャン必須なため負荷分散の面で取り扱いが難しい場合があります。どのようなデータを処理対象にしているのかというのは常に意識をしている必要があります。
Spark UIを活用した方法
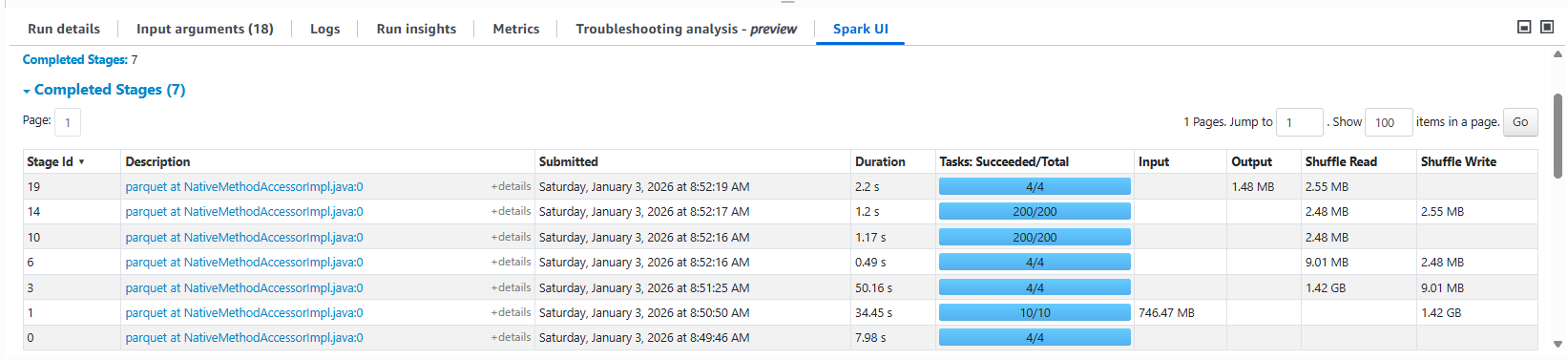
・StagesタブのInput/OutputSpark UIでは各ステージの「Input Size」と「Output Size」を確認することができます。例えば「Input: 50GB に対して Output: 500MB」など、入力に対して出力が極端に小さいケースなどでは、読み込んだ大半を捨てるような処理になっている可能性が考えられます。また、特に最初のステージ(データソースを読むステージ)で Input が突出しているケースでは、最初のステージ内で必要データを処理している可能性があり、そういった場合は“そもそも受け取る前に削れないか”を考えるなど、これらのヒントを元に、データ読み込み量を減らせないか検討する足掛かりになることがあります。
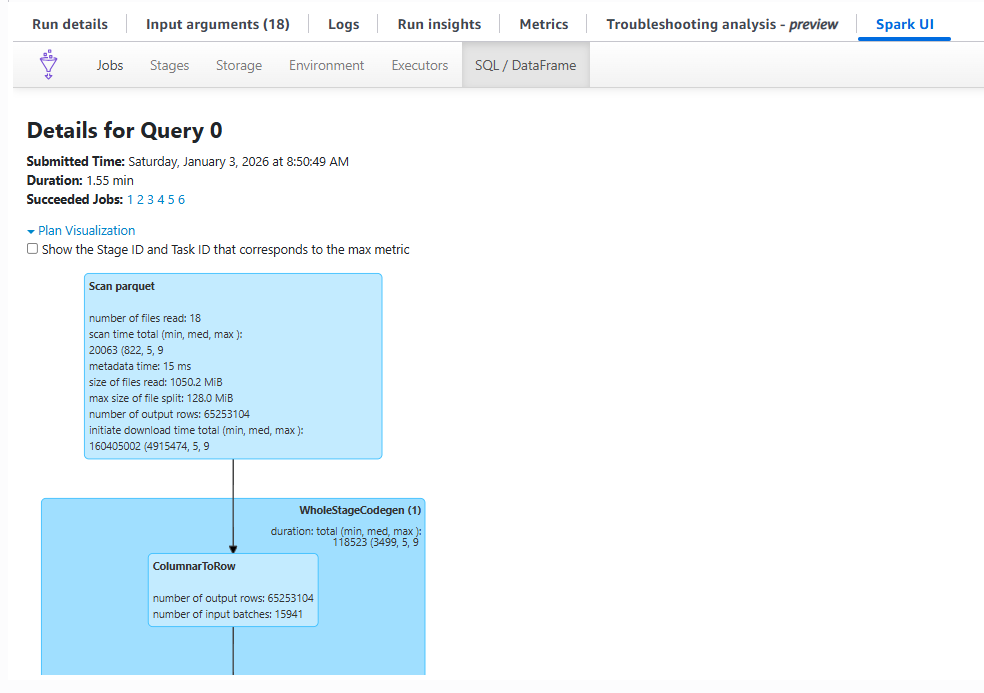
DataFrame/Spark SQLを使っていれば、SQLページから該当クエリを開くことができます。Scanノードの詳細では、読み込んだファイル数/ファイルサイズ/出力行数などが見えることが多く、ここで、フィルタがScanに近い位置にあるか(FilterノードがScanのすぐ上にあるか)を、データソースからの読み取り時に、クエリなどで先に絞ってしまう対応を行うべきかどうかの目安にするといった活用法が考えられます。
読み込みに偏りがないかを確認します。例えば、1つのExecutorだけ大量にディスク読み込みしている場合は、単一大ファイルのフルスキャンなどが疑われます。Spark UIのExecutorsタブが提供する情報(タスク・シャッフル等)も合わせて眺めると、偏りの検知がしやすくなります。
2. タスクを並列化する
なぜ「タスクを並列化する」ことが重要か
Spark/Glueジョブは「多くの小さなタスクをクラスタ全体にばらまいて並列に処理する」ことでスループットを稼ぐ設計になっています。
にもかかわらず、タスク数が極端に少なかったり、逆に細切れになりすぎていたりすると、持っている計算資源をうまく使い切ることができません。
並列度が不足している場合、クラスタの大半のExecutorがアイドル状態のまま一部のタスクだけが長時間走り続けることになります。たとえばスプリットできない巨大なgzipファイルを1タスクで読み続けているようなケースでは、「DPUを増やしたのに実行時間がほとんど変わらない」といった事象が起こりやすくなります。
一方で、タスクが過剰に細かくなっている場合は、今度はドライバやスケジューラのオーバーヘッドが支配的になります。何万・何十万もの小さなファイルをそのまま読み込むと、タスクの生成・スケジューリングだけで相応の CPU を消費し、実データ処理そのものに割ける時間が相対的に減ってしまいます。
同様の問題はファイル数だけでなく、過剰に多いパーティション数によっても発生します。Sparkでは基本的にパーティション単位でタスクが生成されるため、repartitionやspark.sql.shuffle.partitionsの設定などによってパーティション数が極端に多くなると、タスク数も増加しスケジューリングのオーバーヘッドが無視できなくなる場合があります。
Sparkではspark.sql.shuffle.partitionsどの設定で、join や groupBy などシャッフルが発生する処理のパーティション数を制御します。この値がデフォルト(200など)のままだと、データ量によっては並列度が過剰になったり不足したりすることがあります。
AQEによりシャッフル後のパーティション数が調整される場合がありますが、入力データのパーティション数や明示的に指定したパーティション数が自動的に調整されるわけではありません。
つまり、「どの程度の粒度でタスクを分割するか」は、クラスタサイズ・データ量・ジョブのパターンに強く依存するチューニングポイントであり、これを外すと「DPU を増やしても速くならない」「スケーリングしてもコストだけ上がる」といった歪んだ状態になりがちです。
並列度を把握する方法
Spark UIを用いずに可能な方法
・CPU利用率とタスク数の感触から当たりをつけるCloudWatchや監視基盤からGlueジョブのCPU利用率を見ると、「並列化が足りているか」のざっくりした雰囲気をつかむことができます。クラスタの vCPU に対して、常にごく一部だけが100%で他は低い 場合、並列化不足の可能性を疑ったり、逆に Driver だけ CPU が高く、Executor 側は仕事量の割に軽い場合はタスク細切れによるスケジューリングオーバーヘッドも疑うといった余地があります。
・getNumPartitions( )でパーティション数を確認するDataFrame を扱えるのであれば、df.rdd.getNumPartitions( )で今どのくらいに分割されているかを確認できます。例えば、数百 GB 級のデータなのに 1〜2 パーティションしかない場合は明らかに少なすぎるといった当たりをつけたり、逆に数百 MB 程度しかないのに数千パーティションある場合はタスク過剰の可能性を考えることができます。
・入力データ構造からボトルネック候補を洗い出すスプリット不可なフォーマット(単一の巨大gzipなど)でS3に保存していると、どう頑張っても読み込み時は 1 タスクになってしまいます。逆に数十KB程度の超小さいファイルが何万個もあるような構成では、タスク数が爆発し、計画オーバーヘッドやスケジューリングコストが無視できなくなります。そのため、ファイル構造自体が並列度の上限/下限を決めていることを意識する必要があります。
・パーティション戦略と設定値を見直すシャッフルを多用するジョブであれば、spark.sql.shuffle.partitionsがタスク数に直結します。
デフォルトの200が常に最適とは限らないので、データ規模とクラスタのコア数に対して「多すぎ/少なすぎ」になっていないか、設定値そのものを見直す余地があります。
Spark UIを活用した方法
・Stagesタブでタスク数と時間のバランスを確認する各ステージのTasks: Xを見ることで、そのステージが何タスクに分割されているかを確認できます。例えば、クラスタの総コア数(例:36コア)に対して、明らかにタスク数が少ない(例:数タスクだけ)場合、 並列度不足が疑われ、逆に数万タスクなど極端に多い場合は、オーバーヘッドが支配的になっている可能性があります。

ステージの詳細画面からタスクのタイムラインを見ると、1本だけ極端に長いタスクがあり、他の Executorが早々に終わって待っている場合は、並列化不足やスキューの疑いが考えられ、極端に短いタスクが大量に並んでいて、Executor全体にばらまかれている場合は、タスク細切れによるスケジューリング過剰の可能性などが考えられます。時系列で「Executor がどれくらい詰まっているか」を視覚的に見られるのは Spark UI の強みと言えます。

Executor ごとの「実行したタスク数」やCPU時間を眺めると、特定のExecutorだけ異常にタスクが集中していないか、といった偏りも見えてきます。特定Executorだけタスク数/時間が突出している場合は、データスキューやタスクスケジューリングの偏りが発生している可能性を疑うヒントになります。
3. シャッフルを最適化する
なぜ「シャッフルを最適化する」ことが重要か
SparkにおけるjoinやgroupBy、distinct、repartitionなどは、データをExecutor間で再分配する「シャッフル」と呼ばれる処理を伴います。シャッフルはネットワーク I/O・ディスク I/O・ソート・ハッシュ計算が重なり合う、もっともコストの高いフェーズの一つです。
データスキャン量が同じでも、シャッフルの設計を誤ると、中間データが巨大になり、ネットワーク転送量が爆発し、ディスクへの一時書き出しが頻発し、極端に大きなパーティション(スキュー)により「最後の1タスクだけが何分も終わらない」といった症状に繋がります。
Spark3以降ではAQEにより、シャッフルパーティションの再調整やjoin戦略の切り替え、スキューしたjoinの緩和などが行えるようになってきています。ただし、これらは「シャッフルが重い/偏っている」という現象に対する最適化であり、シャッフルがボトルネックになりやすい事実自体は変わりません。だからこそ、スキャン量・並列度と並んで、シャッフルを明示的に最適化対象に据える必要があります。
シャッフル負荷を把握する方法
Spark UIを用いずに可能な方法
・ログやメトリクスからシャッフルステージを特定するジョブの実行時間の中で、特定の区間だけ極端に長くなっている場合、その直前の処理がjoin/groupBy/distinct/repartitionなど、シャッフルを伴う処理になっていないかを確認します。
これらの処理では、データを一度クラスタ全体で再分配する必要があるため、データ量が多い場合や分布が偏っている場合に処理時間が大きく伸びることがあります。特に、ある処理を境にして実行時間が急に長くなっている場合は、シャッフルによる負荷が発生している可能性を疑うことができます。
また、Executorログに“spilling in-memory map to disk”のようなメッセージが出ている場合は、中間データがメモリに収まりきらずディスク退避が発生している可能性があります。
・explain( )で物理計画を確認するdf.explain(extended=True)などで物理プランを出し、ExchangeやSortMergeJoin/ShuffledHashJoinといったノードがどこで発生しているかを確認します。ここで「同じ列に対して不要に repartition していないか」「小さいテーブルとの join なのに常に SortMergeJoin になっていないか」といった構造的な問題を拾えます。
・データスキューを疑う「タスクの大半はすぐ終わるが、残り数タスクだけ異様に時間がかかる」「join 中にメモリ不足で落ちる」などの症状がある場合は、joinキーやgroupキーに偏りがある可能性があります。この場合は、頻出キーの扱いを分ける・疑似的にキーを分散させる・AQEのスキュー最適化を有効にする、といった方向性が候補になります。
Spark UIを活用した方法
・StagesタブでShuffle Read / Write を確認する各ステージのメトリクスにはShuffle Read(読み込みバイト数)、Shuffle Write(書き込みバイト数)、Spill(メモリ/ディスク)が表示されます。ここが GB 単位で大きく、ステージの経過時間も長い場合、そのステージがジョブ全体のボトルネックとなっている可能性が高くなります。
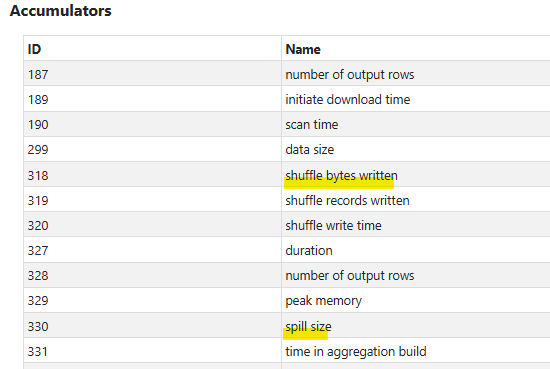
BroadcastHashJoin / SortMergeJoin など、実際に使われているjoinアルゴリズムを確認します。片側が明らかに小さいテーブルなのにSortMergeJoinになっている場合、broadcastの適用余地があるかを検討します。(参考: 結合ヒントの使用 Spark SQL-AWS 規範ガイダンス)
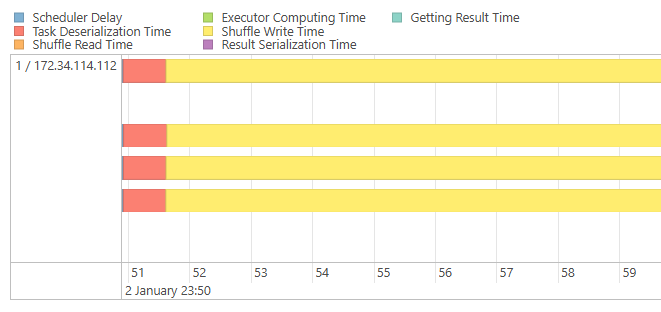
・Task Timeline でスキューを可視化するほとんどのタスクが短時間で終わる中、数タスクだけ極端に長い場合はスキューの可能性が高いです。最大タスク時間が中央値の数倍〜数十倍なら、スキューを前提に対策を検討するべきサインになります。
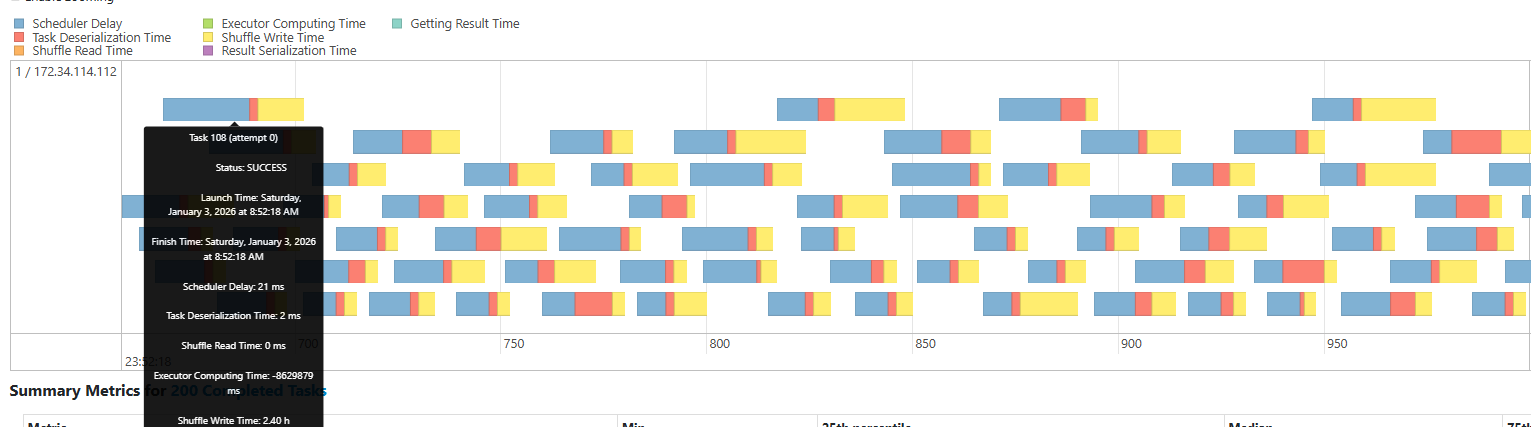
カーソルを合わせれば各処理時間の具体的な数値も確認できる
4. 計画オーバーヘッドを最小化する
なぜ「計画オーバーヘッドを最小化する」ことが重要か
Sparkジョブは、タスクを実行する前にS3上のファイル一覧やGlueカタログのパーティション情報を列挙し、論理計画から物理計画へ最適化し、DAGを構築し、という準備フェーズを経ます。この「計画」のオーバーヘッドが大きいと、Executorが何もしていないのにジョブ全体の経過時間だけが積み上がっていく状態が発生します。
典型的な例が「何万もの小さなファイルを含むS3プレフィックス」や「非常に多いパーティションを持つテーブル」です。これらは実データ量以上にメタデータやファイルリスト取得のコストが効いてしまい、ジョブ開始〜最初のステージ開始までに長い待ち時間が発生します。
Glue/Spark のコストモデルでは、この準備時間もDPU利用時間として課金対象になります。「実際の集計は数分なのに、最初の1時間はずっと何も動いていない」といった状況は、ユーザー体感としてもコスト観点としても避けたいものです。
Adaptive Query Execution やパーティションインデックスなどの仕組みも、この「メタデータの扱い方」や「パーティションの粒度」に関わるため、計画オーバーヘッドを意識して設計しておくことは中長期的にも効いてきます。
計画オーバーヘッドを把握する方法
Spark UIを用いずに可能な方法
・ジョブ開始〜最初のタスク開始までの時間を測るGlueジョブのログやメトリクスから、ジョブ開始時刻と最初のステージ/タスク開始時刻の差を確認します。クラスタ立ち上げを超えて長時間 Executor がアイドルなら、計画オーバーヘッドが支配している可能性があります。
・入力ファイル数・パーティション数を棚卸しする対象のS3プレフィックスに何ファイル存在するか、Glueカタログのテーブルにいくつのパーティションがあるかを確認します。数十万パーティション・数十万ファイルといった規模になっている場合、 列挙だけで相応の時間がかかることを前提に設計を見直す必要があります。
・取得側での絞り込みが効いているかを確認するWHERE句でパーティションキーを指定せず「全期間」「全顧客」を読み込むようなクエリになっていないか。s3//bucket/top-level-folder/のように広いプレフィックスを丸ごと指定していないかを確認します。クエリ側で絞れるのであれば、計画段階で列挙すべきファイルやパーティションの数を減らすことができます。
Spark UIを活用した方法
・Jobタイムラインで準備時間の長さを把握するSpark UIのJob画面で、「Job submitted」から最初のステージが実際に開始されるまでの時間を確認します。この差分が大きい場合、クラスタの初期化と合わせて計画オーバーヘッドが支配している可能性が高くなります。
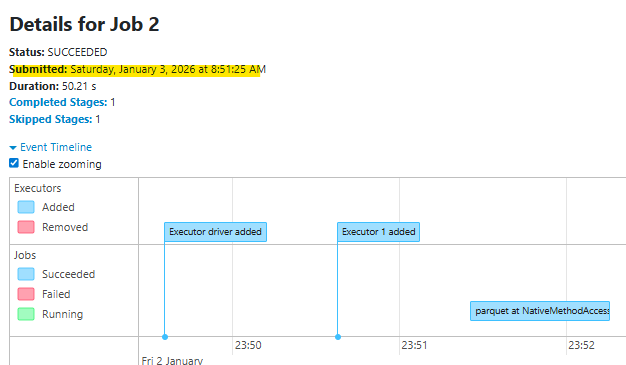
StageのTasks数が常に数万〜数十万になっている場合、それだけ多くの入力ファイル・パーティションを扱っていることの裏返しです。特に初期のステージで異常なタスク数が表示されている場合は、ファイル/パーティションの分割戦略そのものを見直すべきサインになります。

DriverのCPU利用率だけが長時間高く、Executorはほぼアイドルという時間帯がある場合、その区間はDAG生成やメタデータ処理に偏っている可能性があります。Spark UIの時間軸とCloudWatchのメトリクスを突き合わせることで、「どのあたりから実際のタスク実行が始まっているのか」を視覚的に把握できます。
5. UDFを最適化する
なぜ「UDFを最適化する」ことが重要か
PySparkのUDF(ユーザー定義関数)は、柔軟なロジックを表現できる一方で、性能面ではかなり重い存在になりがちです。
特にPython UDFは、JVM上のSparkとPythonプロセスの間でデータをシリアライズ/デシリアライズしながら行単位で処理するため、そのオーバーヘッドが無視できません。
各行ごとに「JVM→Pythonへのシリアライズ」「Python内での処理」「Python→JVMへの逆シリアライズ」が繰り返され、行数が多いほどこのコストが積み上がります。
UDF内部はCatalyst オプティマイザからはブラックボックス扱いのため、式の簡約・フィルタのプッシュダウン・列単位の最適化といったSparkの強みが活かしづらくなります。
Glue 公式の推奨でも、まずは組み込みのSpark SQL関数で書けないか検討する・どうしてもUDFが必要な場合はJava/Scala UDFの利用やpandas UDF/Arrowベースのベクトル化UDFを検討するといった方針が示されています。
したがって、UDFを意識なく多用すると、ジョブ全体がUDFのオーバーヘッドに支配され、DPUを増やしてもほとんど性能が伸びない、という状況に陥ります。どこにUDFがあり、どれくらい支配的になっているかを把握し、可能な限り排除・軽量化することが重要です。
UDFの影響度を把握する方法
Spark UIを用いずに可能な方法
・コードレビューでUDFの有無と位置を確認するpyspark.sql.functions.udfやspark.udf.register、@pandas_udfの利用箇所を洗い出します。特に大きなDataFrameに対してパイプラインの中間で複数回チェーンして呼び出しているUDFは、処理速度に寄与する可能性も高くなっているので注意が必要です。
・explain( )でUDFを含むノードを確認する物理プランにBatchEvalPython(Python UDF)やArrowEvalPython(pandas UDF)が現れている箇所があれば、そこがUDFを伴うステージになります。その前後の処理がjoinやgroupByと重なっていないか・不必要な列までUDFに渡していないかを確認することで、UDFの影響範囲を狭める余地を探せます。
・組み込み関数との比較実験を行うサンプルデータを用意し、UDF版・組み込み関数版(書ける範囲で)をそれぞれ小さなジョブとして実行してみると、性能差の感触をつかむことができます。差が大きい処理ほど、本番ジョブでの影響も大きくなりやすいため、優先的にリファクタリング候補に挙げられます。
Spark UIを活用した方法
・SQLタブでUDFを含むノードを特定するSQLプラン内にBatchEvalPythonやArrowEvalPythonといったノードが存在するステージを探します。そのステージの経過時間が他より極端に長ければ、UDFがCPU時間を支配している可能性があります。
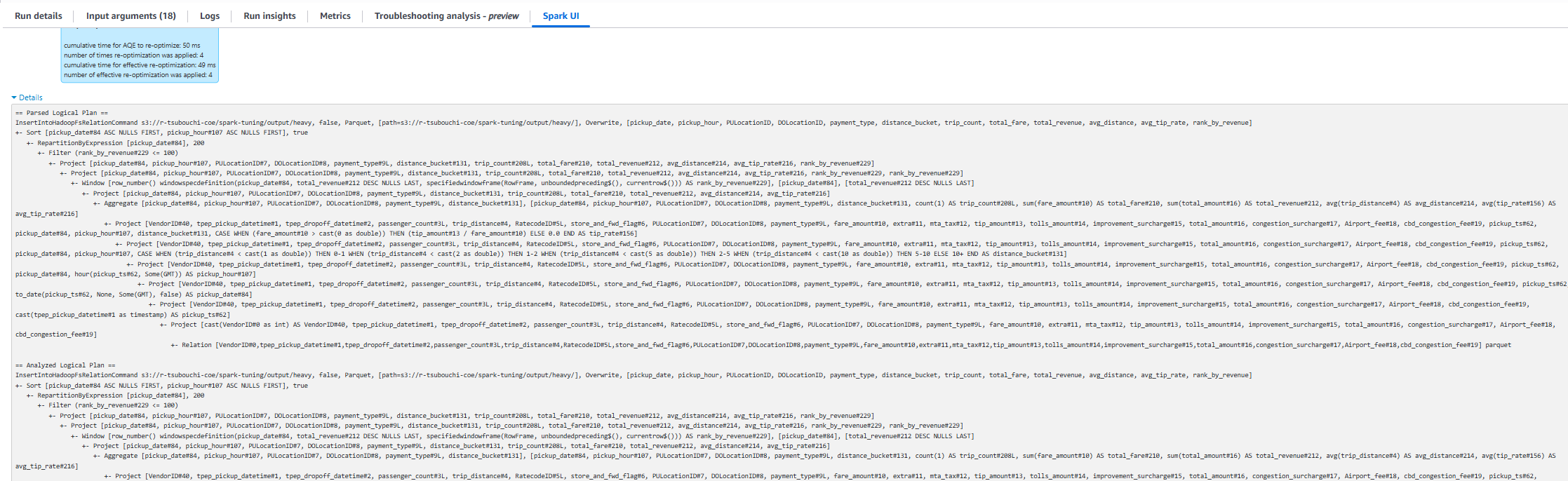
StagesタブでInputサイズやShuffleサイズはそこまで大きくないのにステージ全体の所要時間だけ長いといったステージがあれば、「I/O ではなく計算側(UDF含む)が支配している」疑いがあります。そのステージにUDFが含まれていれば、まずはそこを組み込み関数化/pandas UDF 化/Scala UDF化することが有力な改善ポイントになります。
・ExecutorsタブでCPU使用状況を眺めるUDFが重い場合、ExecutorのCPU使用率は高いものの、入力データ量やシャッフル量の割に処理が進んでいない、といった状況が表れます。ステージタイムラインとExecutor CPUを突き合わせることで、「I/O ではなく純粋な計算オーバーヘッド」が支配的なフェーズを洗い出せます。
まとめ
本稿では、AWS Glue上でSparkジョブを速くするための見立てを、「Sparkの実行原理に沿った最適化」と「Glueという運用基盤を前提にした最適化」に分けて整理しました。Glueは観測と運用が揃っているため、性能改善では“観測→仮説→検証”の反復が回しやすい点が強みになります。
(GlueでSpark UIを有効化するとイベントログがS3に定期退避され、CloudWatchメトリクスでも俯瞰できる、という前提に基づきます)
性能改善は原因の種類を先に分類する
Sparkは遅延評価で計画を立て、アクションで実行されます。したがって、チューニングは“書いたコード”ではなく“実際に選ばれた計画とステージの挙動”を起点にする必要があります。これはSparkの設計に由来する前提であり、Glue上でも同じです。
そのうえで実務的には、最初から細部に潜るより、まず「何が支配して遅いのか」を大づかみに分類すると、打ち手が自然に絞れます。GlueではCloudWatchメトリクスで俯瞰し、Spark UIでステージを見る、という進め方が取れるため、この分類が特にやりやすいです。
本稿の5観点は、Glue上で原因を切り分けるための整理
AWSのガイダンスでは、Glue for Sparkの性能改善観点が整理されています。本稿はそれらを参照しつつ、Glue上で実際に原因を切り分けて手を打てる形にするために、観測しやすさと影響の大きさの観点から5つ(データスキャン/並列化/シャッフル/計画オーバーヘッド/UDF)に再整理しました。
この5つは、個別のテクニックを並べたものではなく、Sparkジョブが遅くなるときにボトルネックが現れやすい層を意識して並べたものです。たとえばスキャン量はI/Oだけでなく後段のシャッフル負荷まで増幅させやすく、並列度はスケールの効き方を決めます。シャッフルはネットワークとスキューを通じて「最後の数タスクが終わらない」症状に直結し、計画オーバーヘッドは開始から最初のタスク開始までの空白時間として現れます。UDFはI/Oが軽いのに時間だけ伸びるときの有力候補になります。こうした因果関係を、CloudWatchで俯瞰し、Spark UIでステージに降りて確認できるように結び付けたのが本稿の意図になります。本稿の整理が、Glue上での性能改善を進める際の手がかりとして、少しでも役に立てば幸いです。