Azure AI Searchを活用したフルテキスト検索ガイドライン – 設計から精度改善まで
目次
1. はじめに
昨今のAIブームによりRAGやベクトル検索が注目される一方で、実務における検索体験では、今なお「特定のキーワードを確実にヒットさせること」が最優先される場面が少なくありません。
たとえば、ECサイトにおける商品名や型番での検索、あるいはサポートFAQでのエラーコード検索などがその典型です。ユーザーの目的が特定のピンポイントな情報にある場合、意味の近さを曖昧に捉えるセマンティックな検索よりも、入力された文字列に対して「意図した結果を漏れなく、かつノイズを排して上位に表示する」という決定論的な精度が求められます。
検索品質の良し悪しは、以下の3つの設計要素の組み合わせによって決まります。
- インデックス設計:データをどのような構造で保持するか
- クエリ設計:ユーザーの入力をどのように解釈し、検索条件へ変換するか
- ランキング設計:ヒットした結果をどのような評価軸で並べるか
これらの設計が不十分だと、「期待した結果が埋もれる」「無関係な情報が上位を占める」「表記ゆれひとつでヒットしなくなる」といった、ユーザー体験を損なう課題が容易に発生してしまいます。なお、本記事では詳しくは触れませんが、こうした設計改善を効かせるためには、検索対象データの品質(表記や項目粒度の統一、欠損・重複の解消など)が揃っていることが前提条件となります。データが不統一なままだと、検索エンジン側の工夫だけでは限界が生じ、改善が頭打ちになりやすいためです。
こうした検索品質の制御において、今改めて真価を発揮するのがフルテキスト検索です。フルテキスト検索は、検索対象フィールドの選定から、形態素解析をはじめとする字句解析、類義語(シノニム)の定義、そしてランキングアルゴリズムの微調整に至るまで、開発者が介入できるポイントが非常に明確です。つまり、「狙った通りの検索挙動」を作り込みやすいという大きなメリットがあります。
本記事では、Azure AI Search のフルテキスト検索機能を活用し、前半ではインデックス設計・クエリ設計の一連の開発プロセスを包括的に解説しつつ、後半では、「期待したキーワードでヒットしない」「並び順が直感と合わない」「表記ゆれに対応したい」といったよくある課題ごとに、精度改善手法を説明します。検索機能を単に「動く状態にする」レベルから、ビジネス要件に合わせて検索結果を「意図通りにコントロールする」レベルへと引き上げるための実践的な勘所を探っていきましょう。
本編に入る前に、検索技術の標準的な存在である「Lucene」と「Solr」について補足します。
- Apache Lucene (アパッチ・ルシーン)
フルテキスト検索のオープンソースライブラリです。インデックス作成や解析、スコアリングといった、検索の核となる基本機能を提供しています。現代の主要な検索エンジンのほとんどが、このLuceneを土台に構築されています。- Apache Solr(アパッチ・ソーラー)
Luceneをエンジンとして搭載し、外部からAPIなどで利用できるようにしたオープンソースの検索プラットフォーム(OSS)です。Azure AI Search のフルテキスト検索はベースとして Lucene を採用しており、Microsoft が機能の取捨選択および拡張を行っています。また、一部では Solr の記法が取り入れられています。
2. インデックス設計
2-1. インデックスとは
「インデックス」とは、検索対象となるデータを、検索に特化した形式に変換して格納したものです。その構造はリレーショナルデータベース(RDB)におけるテーブルに近い見た目をしていますが、その目的はデータの永続化や保存ではなく、検索の高速化と高度な検索機能の実現にあります。Azure AI Search においては、各フィールド(項目)に対して「検索対象にするか」「絞り込みに使うか」「並べ替えに使うか」といった属性を定義し、その定義に基づいて検索エンジンが「転置インデックス」などの内部構造を構築します。
この設計のポイントは、RDBであればSQL(クエリ側)で柔軟に吸収できていた検索要件の多くを、インデックス設計の時点で前倒しして定義しておく必要がある点にあります。
検索エンジンのインデックスは、正規化されたデータをクエリ実行時にJOINで組み立てるのではなく、あらかじめ検索効率を最大化するためにデータを非正規化することが前提となります。そのため、どの項目を検索対象にするか、あるいは絞り込み・集計・並べ替えに利用するかといった要件は、クエリ実行時ではなくインデックス設計の段階で確定させておかなければなりません。つまり、検索の挙動はクエリの書き方以上に、土台となるインデックス定義そのものに強く依存するのです。
※ 一方、「実際にどの検索語を与えるか」「どの条件を適用し、どの順序で結果を表示するか」といった実行時の具体的な制御については、クエリ設計の段階で考慮することとなります。
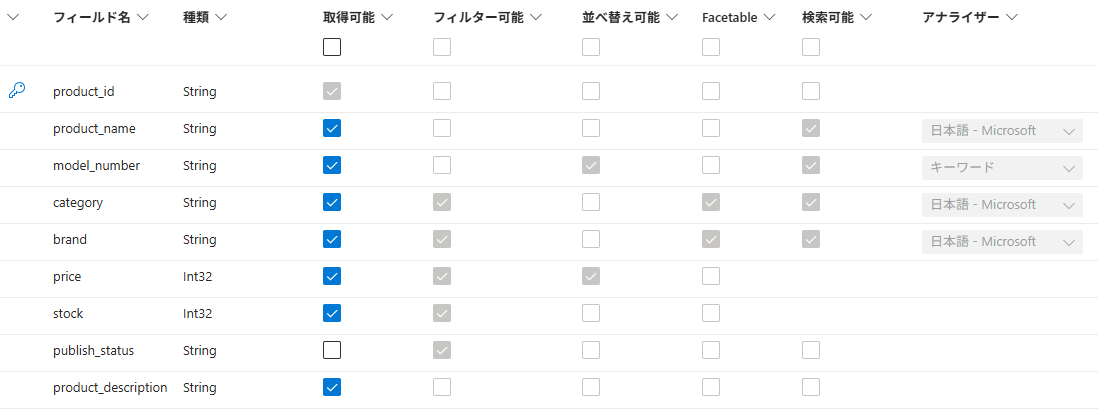
したがって、インデックス設計の段階でまず向き合うべきは、「そのインデックスを通じて、どのような検索操作を実現したいか」という機能的な境界線の整理です。これを実現するために、Azure AI Search では主に以下のような属性をフィールドごとに定義します。
| フィールド属性 | 型 | 内容 |
|---|---|---|
| type | Enum | フィールドのデータ型。型により利用できる属性や操作が変わります。 サポートされているデータ型 – Azure AI Search |
| key | boolean | ドキュメントの一意識別子。 1フィールドのみ指定可能で、型はEdm.Stringである必要があります。 |
| retrievable | boolean | 検索結果として項目値を返却するかどうかを設定します。 |
| filterable | boolean | フィルター式による絞り込みの対象とするかどうかを設定します。 |
| sortable | boolean | 検索結果の並び替えに利用するかどうかを設定します。 |
| facetable | boolean | ファセット取得の対象とするかどうかを設定します。 |
| searchable | boolean | フルテキスト検索の対象とするかどうかを設定します。 |
| analyzer | Enum | 文字列を字句解析(トークン化)する規則を設定します。searchableかつ型がEdm.Stringの項目に対しては、必ずアナライザーが適用されます。(明示的に指定しない場合、既定のアナライザーstandard.lucene が適用されます。) 詳細は後述しますが、Azure AI Search では、インデックス作成時とクエリ実行時の両方でアナライザーによる字句解析が行われます。インデックスアナライザー(indexAnalyzer)と検索アナライザー(searchAnalyzer)を分けて指定することも可能です。 |
| synonymMaps | string[ ] | 検索時に適用するシノニムマップ(類語辞書)を指定します。 |
2-2. フィールド属性の最適化
インデックス設計で最も重要なのは、各フィールドに役割を持たせること(=必要最小限の属性だけを付与すること)です。フィールド属性を「念のため・とりあえずTrueにしておく」というアプローチは、検索精度の劣化とリソースの浪費を招きます。
まず考えるべきは、フルテキスト検索に使うデータと、絞り込み・集計・並べ替えに使うメタデータを混同しないことです。例として家電 EC サイトを考えてみましょう。
- ユーザーが検索窓に入力しそうな情報:商品名、型番…
- 絞り込み・並べ替えに使うメタデータ:カテゴリ、ブランド、価格、在庫、公開状態…
ここで陥りがちな失敗が、「検索にヒットしないと困るから」という理由で、価格や在庫状況、公開状態といった、本来検索キーワードに入力されることを想定していない項目までsearchable(検索対象)に含めてしまうことです。
例えば、ユーザーが特定の型番を探そうと「100」というキーワードを入力した際、在庫数「100個」やポイント「100倍」といった意図しないフィールドがヒットしてしまい、結果としてノイズの多い検索体験を強いることになります。フルテキスト検索の対象は、ユーザーがキーワードとして探したい項目だけに絞るのが鉄則です。
また、フィールドに不要な属性を付与することは、単に設計が美しくないだけでなく、実運用において以下のような具体的なデメリットをもたらします。
- ストレージ容量の増大:属性を付与するごとに内部構造が生成されるため、容量が増大します。
- インデックス更新の遅延:データの登録・更新時に更新すべき構造が増えるため、スループットが低下します。
- クエリ応答速度の悪化:検索エンジンが走査すべき範囲が広がり、検索時のレスポンスが遅くなります。
さらに重要な前提として、インデックスを構築した後は、既存フィールドの定義を原則として変更できません。変更が必要な場合、多くのケースでインデックスの作り直し(再構築)とデータの再投入が必要になります。システム規模が大きくなるほどこの再構築コストが重くなるため、初期設計の精度が運用の成否を分けます。
したがって、インデックス設計は「とりあえず作る」のではなく、「どのような検索画面を提供し、どう並べ替え、どう絞り込むか」という検索体験のゴールから逆算して落とし込んでいく必要があるのです。
| ユーザー体験のゴール例 | フィールド属性の設定例 |
|---|---|
| ① サイドバーでカテゴリ・ブランドを選んで絞り込みたい(ファセット検索) | category,brandをfilterableかつfacetableに設定します。検索結果にカテゴリ・ブランドを表示したいため、retrievableも有効にします。 |
| ② 特定の価格範囲で検索し、さらに価格順でソートしたい | priceをfilterableかつsortableに設定します。検索結果に価格を表示したいため、retrievableも有効にします。 |
| ③ 販売停止中や非公開の商品は、検索結果に一切出したくない | publish_statusをfilterableに設定します。 ※クエリ側で常にpublish_status eq ‘public’の絞り込みを指定する運用になります。(詳細は後述) 検索結果への表示は不要のため、retrievableはオフのままとします。 |
2-3. データパイプライン
インデックス定義が固まったら、次に考えるべきは「検索結果をいかに最新状態に保つか」という更新戦略です。
検索インデックスはシステムのマスタデータそのものではなく、基幹DBやストレージに存在する一次データから、検索に必要な情報を抽出して保持する「派生データ」に過ぎません。そのため、一度取り込んで終わりではなく、元データの変更をインデックス側へどう追従させるか、という設計が不可欠になります。
もちろん、すべての要件で自動更新の仕組みを作る必要はありません。更新頻度が極めて低いマニュアルなどの静的コンテンツであれば、初期投入と必要に応じた手動更新で十分です。しかし、商品情報やFAQのように日々内容が変わるデータ、あるいは価格や在庫のように変動が激しいデータを扱う場合、検索体験を維持するために「継続的な更新パイプライン」の構築が前提となります。
Azure AI Searchでは、このインデックスを最新化する仕組みとして、大きく分けて以下2つのアプローチが用意されています。
- Pull型(インデクサー):AI Search 側がデータソースを定期的に巡回(設定メイン)
- Push型(REST API):アプリケーション側から任意のタイミングでデータを登録・更新(実装メイン)
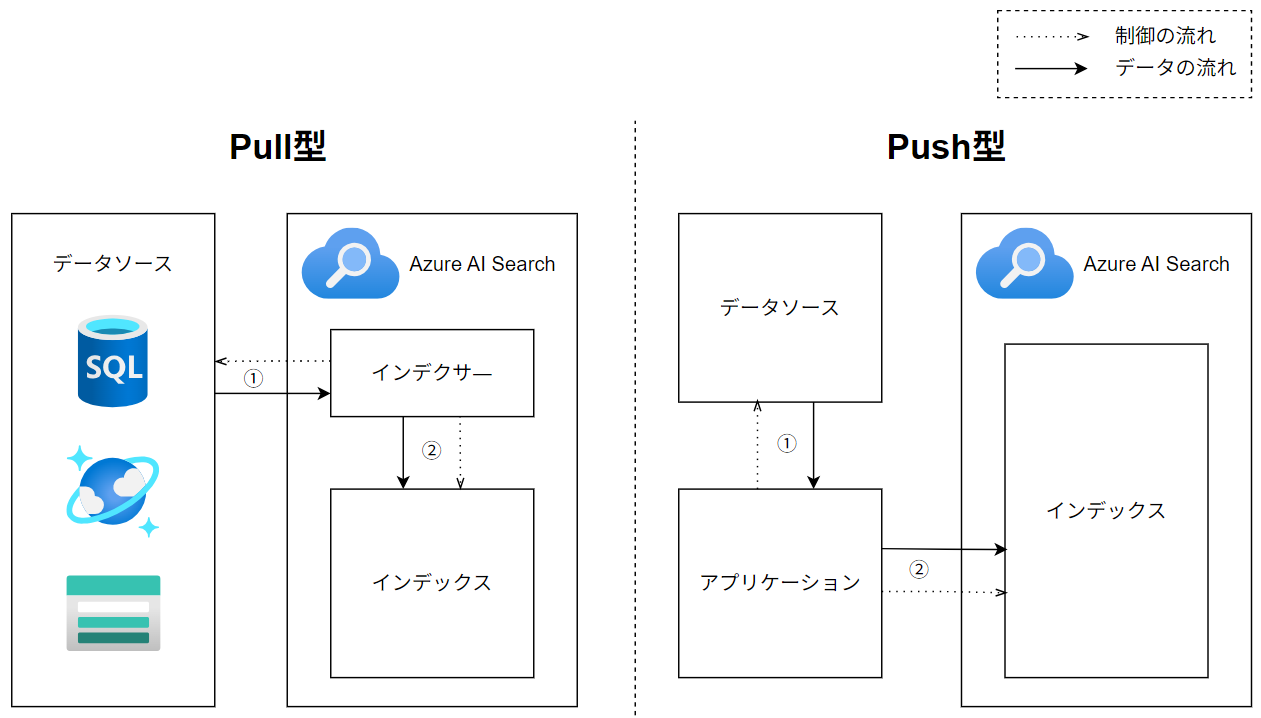
2-3-1. Pull型(インデクサー)
Pull型は、Azure AI Search がデータソースからデータを取りに行く(Pull)方式で、「インデクサー」がデータ抽出とインデックスへの登録・更新を担います。対応するデータソース(Azure SQL Database, Cosmos DB, Blob Storage 等)であれば、同期ロジックのコードを自前で書く必要がなく、「設定」ベースでパイプラインを完結できるのが最大のメリットです。共有プライベートリンクを活用することで、プライベートなAzureリソースをデータソースとすることもできます。
データソース側が変更検知をサポートしていれば、定期実行のたびに差分(追加・更新)のみを拾う運用が成立します。一方で削除については、データソースの種類によっては自動追跡されないケースがあります。たとえば Azure Blob Storage をソースにした場合、一般的な構成では物理削除の自動検知はできないため、論理削除(ソフトデリート)などの工夫をデータソース側に組み込む必要がある点には注意が必要です。
また、インデクサーはオンデマンド実行に加えてスケジュール実行が可能で、最短間隔は5分です(※2026年3月現在)。したがって、更新反映に分単位の遅延が許容でき、かつ運用・性能・セキュリティの観点でデータソースへの定期的・継続的なアクセスが可能な要件であれば、 Pull型を採用することで実装も運用も軽量化できます。逆に、価格や在庫のようにリアルタイムの同期が求められる場合は、Pull型だけでは完結させることは難しく、Push型の採用または併用を検討する必要が出てきます。
さらにインデクサーでは、取り込みパイプラインの途中にスキルセットを差し込むことができます。Azure AI Search における「スキル」は、インデクサーの実行プロセス内でデータに適用される加工ステップ(エンリッチメント)を指します。翻訳や抽出・変換といった特定タスクを独立したモジュールとして呼び出す構造は、昨今の生成AI文脈で語られる「スキル(=ツール/機能呼び出し)」と似た概念です。
スキルセットを用いることで、OCR・翻訳などの組み込みスキルや、外部の Web API を呼び出すカスタムスキルを活用し、インデックス投入直前のデータを柔軟に加工できます。たとえば、特定のフィールドをあらかじめ英語に翻訳しておくことで、英語でのキーワード検索にも対応する、といった使い方が考えられるでしょう。
2-3-2. Push型(REST API)
もう一方の Push型は、アプリケーション側が REST API を使って、インデックスにドキュメントを直接登録・更新する方式です。この方式の強みは、インデクサーがサポートしていないデータソースも扱えること、そして取り込み頻度をアプリ側で自由に制御できることです。
Index Documents API を使うことで、ドキュメントごとに追加・更新・削除を行うことができます。つまり Push型は「いつ・何を・どう登録/更新するか」をアプリ側の意思で厳密に制御できる一方で、リトライや監視などの責任もアプリ側に寄る設計になります。また、投入前にデータ加工が必要な場合は、自前で前処理を実装してから投入する形になりやすい点も押さえておくべきポイントです。たとえば、次のような要件がある場合には Push型を選択すべきと言えるでしょう。
- 即時反映が必須(在庫状況や価格など)
- データソースがインデクサーでサポートされていない
3. クエリ・ランキング設計
インデックス設計が「データの持ち方」を決める静的な工程であるのに対し、クエリ・ランキング設計はユーザーの入力に応じて「検索の振る舞い」を決める動的な工程です。大きく以下の3ステップに分解して考えると、要件を整理しやすくなります。
- STEP1:絞り込み(Filter):属性条件で対象範囲を削ぎ落とす
- STEP2:検索(Search):絞り込まれた集合から関連度を計算する
- STEP3:並べ替え(Sort): ビジネス要件に基づき最終的な順序を決定する
STEP1:絞り込み(Filter)
まず初めに、条件による絞り込みを行います。あらかじめ母集団を限定することで、ノイズを大幅に減らし、関連度計算のコスト(検索エンジンの負荷)を最小化できます。絞り込みには、カテゴリ、在庫状況、価格、公開ステータスといった、完全一致や範囲条件で指定できるメタデータが適しています。
Azure AI Search における絞り込みでは、OData $filter構文のフィルター式を使用します。これはSQLのWHERE句に近い感覚で記述でき、複数の条件を論理演算子(and,orなど)で柔軟に組み合わせることが可能です。
category eq '冷蔵庫' and stock gt 0 and price ge 50000 and price le 100000
また、インデックス定義でfacetableを有効にしたフィールドからは、一致するドキュメントの件数(ファセット)を取得できます。これを利用すれば、「カテゴリ別のヒット件数」をサイドバーに表示するなど、ユーザーが直感的に条件を絞り込めるUI(ファセット検索)を容易に構築できます。
STEP2:検索(Search)
絞り込まれた対象に対して、検索エンジンが 「クエリとドキュメントの関連度」を計算します。この手順をブラックボックスのまま扱うと、後の改善フェーズで手詰まりになってしまうため、内部で行われている5つの処理を順に解説します。
①クエリ解析
ユーザーが入力した検索文字列は、まず初めにクエリパーサーによって構文解析され、検索演算子(AND/OR/NOT 等)やフレーズ指定といった要素に分解されます。
Azure AI Search のフルテキスト検索には、Luceneベースの2種類のパーサーがあり、リクエストのqueryTypeで選択します。デフォルトはSimpleです。
| 種類 | 説明 |
|---|---|
| Simple | 一般的な検索ユースケースを広くカバーします。 |
| Full | Simpleの機能に加え、フィールド指定、正規表現、近接検索、あいまい検索、ワイルドカードなどの高度な検索式を扱えます。ただし、その分処理コストがかかるため、Simpleと比べて実行時間が伸びる可能性がある点に注意が必要です。 |
ここで併せて押さえておきたいのが、searchModeです。searchMode は、検索文字列に明示的な演算子が書かれていない場合の既定の結合(any / all)を制御します。つまり、ユーザーがスペース区切りで複数語を入力したときに、それをOR条件とするか、AND条件とするかを決定します。
- any(既定):空白区切りの語句を「OR(should)」として扱い、ヒットの網羅性を広げます。
- all:空白区切りの語句を「AND(must)」として扱い、すべての語句を含むドキュメントに絞ります。
②シノニムマップによる拡張・置換
シノニムマップを適用しているフィールドがある場合、クエリ内の語句に対してシノニムマップ(類語辞書)による拡張・置換が適用されます。
表記ゆれ・略語対策の中核となるため、インデックス設計と併せて、「どのフィールドにシノニムを適用するか」を意識することが重要です。
③字句解析
アナライザーによって、入力文字列を「検索可能な単位(トークン)」に変換します。具体的には、ストップワード(助詞など)や句読点の除去、単語境界での分割、大小文字の正規化など、規則に従って文字列を変形しながらトークンを生成します。Azure AI Searchでは、大きく以下の3系統のアナライザーを利用できます。
- 言語アナライザー:各言語の特性に合わせた解析(Microsoft 系/Lucene 系)
- 組み込みアナライザー:keyword/whitespace/patternなど、特定用途向け
- カスタムアナライザー:トークナイザーとフィルターを任意で組み合わせた独自定義
詳細は後述しますが、Azure AI Search では、インデックス作成時とクエリ実行時の両方でアナライザーによる字句解析が行われ、「インデックス側で作られたトークン」と「クエリ側で作られたトークン」が噛み合うことで検索にヒットするようになるため、ここでどのように分割・正規化されるかが、検索品質に直結します。
④文書検索
分割されたトークンをキーに転置インデックスを参照し、該当トークンを含むドキュメントを高速で見つけ出します。
⑤スコアリング
最後に、ヒットしたドキュメントに対してBM25に基づく関連度スコアを計算します。BM25はTF/IDFタイプのスコアリングアルゴリズムであり、主に以下の要素を踏まえて統計的にスコアを決定します。
- TF(Term Frequency):ドキュメント内での単語の出現回数
- IDF(Inverse Document Frequency):ドキュメント間での該当単語の珍しさ(出現頻度の低さ)
- 文書の長さ:短い文書内でのマッチをより高く評価する等の補正
STEP3:並び替え(Sort)
フルテキスト検索における並び替えのデフォルトは、検索エンジンが計算した「関連度スコア(@search.score)」の降順です。しかし実務では、ユーザーの利便性やビジネス上の優先度に基づき、「価格の安い順」「新着順」「人気順」といった任意の項目で並べ替えたい場面も多いはずです。
Azure AI Searchにおいては、OData $orderby 構文でこれを実現します。インデックス定義で sortableを有効にしたフィールドを指定して制御します。
# 価格の安い順 price asc # 新着順(発売日) release_date desc
また、search.score( )関数を並べ替えキーに明示的に含めることも可能です。これにより、「特定の項目でソートしつつ、同じ値の中では関連度が高いものを優先する」といった柔軟な制御が可能になります。
# 価格の安い順 かつ 関連度スコア順 かつ 新着順 price asc, search.score(), release_date desc
このように、単にスコア順のみに頼るのではなく、ビジネス要件に合わせてソート順を組み合わせることで、ユーザーにとって納得感のある検索結果を提供できます。
4. 課題に応じた検索精度の改善手法
ここまで、インデックスとクエリ・ランキングの基本的な振る舞いを押さえてきました。本章ではそれらを前提に、実際の運用で頻出する課題ごとに、その精度改善手法について整理します。
課題1:期待したキーワードでヒットしない
フルテキスト検索は、単なる文字列の「部分一致(Like検索)」ではありません。検索にヒットするための条件は、「クエリから生成されたトークン」と「インデックスに保存されているトークン」が完全に一致することです。どれほど検索対象の文字列内にキーワードが含まれていても、このトークン同士が噛み合わない限り、1件もヒットしません。
Azure AI Search では、searchableな文字列フィールドに対して インデックス作成時とクエリ実行時の両方で字句解析を行い、文字列からトークンを生成します。この両者で同様のトークンが生成されていることが、検索でヒットするための必須条件となります。
Analyze APIを使うと、指定したテキストが特定のアナライザーによってどのようにトークン化されるかを直接確認できます。ここでのポイントは、「ユーザーが入力するキーワード(クエリ側)」だけでなく、「データソースから投入した文字列(ドキュメント側)」も同じように解析して比較することです。
Analyze APIは、textやanalyzerなどを指定してトークン列を返します。両方の解析結果を突き合わせることで、「インデックス側では分割されているのに、クエリ側では結合されたままになっている」といった不一致を機械的に特定できます。
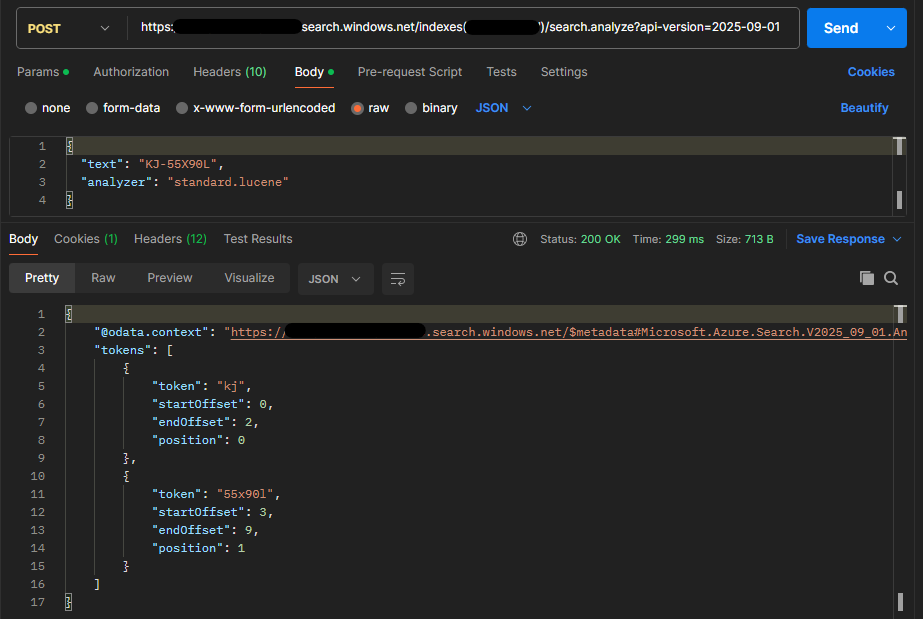
トークンの不一致が確認できたら、要件に合わせてアナライザーを調整します。通常は、以下の優先順位で検討を進めます。
- 言語アナライザーの検討:
既定のstandard.luceneと、各言語専用のアナライザーを比較します。日本語であればja.lucene(オープンソース版)と ja.microsoft(Microsoft独自の自然言語処理)の2種類が用意されており、分かち書きの精度や辞書の性質に違いがあります。 - 特殊な用途向けの組み込みアナライザー:
型番、エラーコード、URLなどのように「記号や桁数が重要な意味を持つ」文字列には、keyword(文字列全体を1つのトークンとして扱う)やwhitespace(空白のみで分割し、記号は維持する)といった組み込みアナライザーの適用を検討してください。 - カスタムアナライザーの検討:
既存のアナライザーでは「どうしても余計な変形が入る」「特定のルールでトークンを抽出したい」といったズレが解消できない場合、カスタムアナライザーの作成を検討します。カスタムアナライザーは、以下の3つの部品を組み合わせて、トークン化の「工程」と「順序」を独自に定義できる仕組みです。
ただし、カスタムアナライザーは「何でもゼロから自作できる」わけではなく、Azure AI Searchが用意している既存の部品(フィルタやトークナイザー)を組み合わせるものである点に注意が必要です。
| 部品 | 説明 |
|---|---|
| 文字フィルター | トークン化の前に、HTMLタグの除去や特定の文字置換を行います。 |
| トークナイザー | 文字列をトークンに分割する際の中核ロジック(単語区切りや文字数区切りなど)を指定します。 |
| トークンフィルター | 分割されたトークンに対し、小文字化、ストップワード除去、同義語展開などを行います。 |
また、Azure AI Search はフィールドごとに 検索アナライザー(searchAnalyzer)とインデックスアナライザー(indexAnalyzer)を分けて指定することができます。要件によっては「同じアナライザーを両方に使う」より、あえて分けた方が一致を作りやすい場面があり得ます。
- 原則:
まずは両方に同じアナライザーを使い、トークンが素直に一致する状態を目指します。 - 例外(分けた方が良い典型):
インデックス側だけ特殊なトークンを作りたいケースがこれに当たります。例えば、部分一致を強化するためにインデックス側で n-gram(文字単位の断片)を生成して「ヒットしやすさ」を最大化しつつ、検索語側は通常の分割にとどめて「過剰なヒット(ノイズ)」を抑制したい場合などです。
このように、indexAnalyzer に「ヒットさせたい断片トークン」を、searchAnalyzerに「ユーザーの意図を汲むトークン」をそれぞれ持たせる設計にすることで、より高度な検索制御が可能になります。
課題2:検索結果の並び順が意図と合わない
「新着順」「安い順」「人気順」といったビジネス要件が明確な場合は、前述した$orderbyよる明示的なソートが最も安全な解決策です。しかし、「関連度の計算自体は正しいはずなのに、特定の条件を備えたドキュメントをより優先的に上位へ表示したい」というケースでは、別のチューニング手法が必要になります。
ここでは、検索スコアを「制御」するための3つのアプローチを解説します。
①スコアリングプロファイル
スコアリングプロファイルは、一致したドキュメントの検索スコア(@search.score)に対して、フィールドの重み付けや、数値・日付・位置情報などの関数を用いてブースト(加点)または抑制を行う仕組みです。
具体的には、以下の要素を組み合わせて独自のランキングロジックを構成できます。
| 要素 | 説明 |
|---|---|
| 特定フィールドの重み付け | 特定のフィールドにヒットした際の重要度を高めます。 (例:「商品名」でのマッチを他フィールドより4倍重視する) |
| 数値・日付・位置情報の関数 | データの鮮度や評価数などのメタデータをスコアに反映させます。 (例:新しい記事ほど加点、レビュー数が多いほど加点) |
| タグに対するブースト | ユーザーの嗜好性タグとドキュメントの属性が一致した場合にスコアを底上げします。 |
スコアリングプロファイルは、クエリ実行時にscoringProfileパラメータで指定して適用します。そのため、「検索画面では通常ランキングを用い、特集ページやレコメンド枠では特定のプロファイルを適用する」といった、コンテキストに応じた使い分けが可能です。
{
"scoringProfiles": [
{
"name": "sample-scoring-profile",
"text": {
"weights": {
"product_name": 4
}
},
"functions": [
{
"type": "magnitude",
"fieldName": "reviewCount",
"boost": 2,
"interpolation": "linear",
"magnitude": {
"boostingRangeStart": 0,
"boostingRangeEnd": 500,
"constantBoostBeyondRange": true
}
}
],
"functionAggregation": "sum"
}
]
}
②用語ブースト
「特定のキーワードが入っているドキュメントを、局所的に最上位へ引き上げたい」という場合には、クエリ側での「用語ブースト」が効果的です。たとえば、特定のキャンペーン対象商品を優先表示したいケースなどが該当します。スコアリングプロファイルが「インデックス全体の構造的な重み付け」であるのに対し、用語ブーストは「その時の検索クエリに応じたピンポイントな制御」に向いています。
queryTypeでfullを指定している場合、キャレット記号^を使うことで、特定の語句やフレーズの重みを指定できます。
冷蔵庫 AND 〇〇キャンペーン^3
③BM25のパラメータ調整
スコアリングプロファイルやクエリ側のブーストを駆使しても、検索エンジン全体の”癖”が理想と合わない場合の最終手段として、BM25自体のパラメータ調整が考えられます。
Azure AI Search の BM25 では、以下の2つのパラメータをインデックス単位で設定・変更できます。
| パラメータ | 説明 |
|---|---|
| k1 | 単語の出現頻度(TF)がスコアに与える影響の「飽和スピード」を制御します。この値を小さくすると、同じ単語が何度も出現することによる加点効果が早めに頭打ちになります。 |
| b | 文書の長さによるスコアの減衰(長さの正規化)を制御します。この値を大きくすると、短い文書に単語が含まれていることをより高く評価するようになります。 |
なお、これらはインデックス全体の挙動に根本的な影響を与えるため、十分な検証を行った上で慎重に調整すべき項目と言えるでしょう。
課題3:表記ゆれ・略語などに対応したい
「スマホ/スマートフォン」「PC/パソコン」「冷蔵庫/れいぞうこ」など、ユーザー入力の揺れは避けられません。ここをアナライザーだけで吸収しようとすると限界があるため、明示的にシノニムマップ(類語辞書)に持つのが定石です。シノニムマップは、同義語の対応関係を定義してクエリを拡張・置換する機能で、ユーザーが別表記で検索しても同じ結果に到達できるようにします。
Solr 形式のルールとして、次の2種類を定義できます。
- 同義性規則:列挙した語句を相互に同等として扱う
例:スマホ, スマートフォン, 携帯電話(どれで検索しても相互に拡張される) - 明示的マッピング:片方向に置換する(逆方向はしない)
例:ノートパソコン, デスクトップ => PC(PC関連のキーワードをすべて「PC」に寄せたい場合など)
シノニムマップ自体はいつでも作成・割り当てでき、インデックス作成やクエリを止めずに適用できるため、「全部入りの辞書」を最初から作ることを目指すのではなく、検索ログの「0件ヒット」や「表記ゆれ」から追加していく方が、ノイズを増やさず効果的です。
5. おわりに
ここまで、Azure AI Search のフルテキスト検索機能に焦点を当て、検索品質を意図通りにコントロールするための設計と改善の勘所を解説してきました。
とはいえ、初期実装で検索が動き始めた瞬間は、スタートラインに過ぎません。実際の運用が始まれば、コンテンツの増加やユーザー行動の変化に伴い、「期待した結果が出ない」「ノイズが混ざる」といった課題が必ず顕在化します。検索は、一度作って終わりの機能ではなく、常に磨き続ける必要がある領域なのです。
運用フェーズにおいて重要なのは、感覚的な調整に頼らず、検索ログから抽出した定量的なデータに基づいて対策を講じることです。特に、次の2つの指標に注視してみてください。
| 指標 | 説明 |
|---|---|
| 0件ヒット (ゼロマッチ) |
ユーザーの目的達成を完全に阻害している、最も優先度の高い課題です。トークンの不一致(アナライザー設定)、検索対象フィールドの不足、あるいは類義語(シノニム)の欠落など、どこに課題があるかを特定し、着実に解消する必要があります。 |
| クリック率(CTR) | 検索結果は出ているものの、順位や精度に満足していないサインです。filterの見直し、searchModeによる適合率の調整、スコアリングプロファイルによる重み付けなど、全体への影響を考慮しながら「上位表示の納得感」を高める施策を打つ必要があります。 |
ここで大切なのは、一度に大規模な変更を加えないことです。「小さく直し、検証する」というサイクルを愚直に回し続けることで、検索品質は着実に積み上がっていきます。
昨今のAI技術の進化は目覚ましいものがありますが、フルテキスト検索の最大の強みは、ブラックボックスではない「高い再現性」と「説明可能な制御性」にあります。「なぜこの結果が上に来るのか」を開発者が制御できる安心感は、そのままユーザー体験の信頼性へと直結します。
本記事が、みなさんのプロダクトにおける検索機能を、「単に動くもの」から、ビジネス要件に沿って意図通りにコントロールできる「使えるもの」へと引き上げるための一助となれば幸いです。