運用観点から見るDynamoDB – OpenSearch のZero-ETL統合
目次
DynamoDBとOpenSearchの統合によるフルテキスト検索
DynamoDBはシンプルなキー・バリューストアとして優れていますが、複雑なクエリやフルテキスト検索には限界があります。実際の運用においても、テーブル設計段階で想定していなかった条件での検索のニーズが発生したり、フルテキスト検索が必要になるケースがあります。
そうしたDynamoDB単体では実現が難しい検索要件に対応する方法として、検索サービスとの組み合わせが有効です。AWSでは、DynamoDBと組み合わせて利用できる検索サービスとして、OpenSearchが提供されています。OpenSearchは高度な検索機能とリアルタイム分析を提供し、高いスループットと低レイテンシーでデータを迅速に保存・取得できるDynamoDBとの相性が非常に良いです。
一方で、OpenSearchとDynamoDBを組み合わせてシステムを運用する際には、データ保護、エラーハンドリング、再実行、監査ログなどの観点からシステム全体の設計と管理を行うことが求められます。
OpenSearchとDynamoDBを組み合わせる方法として、従来はDynamoDB StreamとLambdaを利用したETL統合が活用されてきましたが、2023年12月に行われたre:InventにてDynamoDBとOpenSearchのZero-ETL統合が発表されました。Zero-ETL統合は、アプリケーションが一度データをDynamoDBに書き込むだけで、OpenSearchに自動的に同期され、フルテキスト検索や高度な分析が即時に行えるようになるもので、ETL統合で抱えていた運用課題解消へ向けたアプローチとなりうるものです。Zero-ETL統合が発表されてから1年近くがたち運用ナレッジも溜まってきた昨今、本記事ではDynamoDBとOpenSearchを組み合わせたZero-ETLの仕組みについて、従来のETL統合との比較を通して、実運用視点で深掘りしていきます。システムの複雑さを抑えつつ、迅速で効率的な検索環境をどのように実現するか、具体的な手法と考慮すべき点について実際の運用観点から説明します。
まず、DynamoDBとOpenSearchを連携させる基本的な設定として、DynamoDBからOpenSearchへデータを転送する際に使用するAWSサービスやその構成例について触れます。次に、Zero-ETLアプローチの概念と利点について、既存のETL処理との違いを比較しながら、実際の運用で直面する問題点やその解決方法を明らかにしていきます。
従来のDynamoDBとOpenSearchの連携方法
~DynamoDB StreamとLambdaを用いたETL構成~
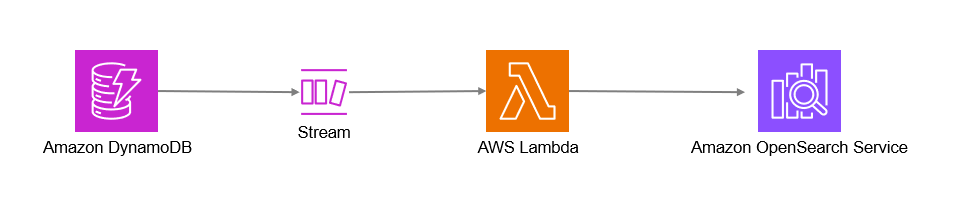
DynamoDBに格納されたデータを効率的にOpenSearchに同期するため、DynamoDB StreamsとAWS Lambdaを活用したETL構成は従来広く活用されてきました。この方法を用いることで、DynamoDBのデータ変更が自動的にOpenSearchに反映され、リアルタイムで高度な検索が可能になります。具体的な構成は公式ドキュメントを参考いただくこととし、ここでは概要と運用上の課題点だけ触れます。
Amazon DynamoDB テーブルからストリーミングデータをロードする – Amazon OpenSearch Service
DynamoDB StreamとLambdaを用いたETLの概要
DynamoDBとOpenSearchを組み合わせて利用する際には、そのデータ構造の違いを理解する必要があります。DynamoDBはキーバリューストア型のNoSQLデータベースであるのに対し、OpenSearchはドキュメント指向型のデータストアでありデータはJSON形式のドキュメントして保存されることになります。こういったデータ構造の差異を吸収する方法として従来利用されてきたのがDynamoDB StreamとLambdaを用いたETL構成になります。DynamoDB StreamsとAWS Lambdaを組み合わせ、DynamoDBの変更データをOpenSearchにリアルタイムで転送する構成を使用することで、迅速かつ柔軟な検索環境を構築することができます。
公式ドキュメントでも挙げられているDynamoDB StreamsとAWS Lambdaの組み合わせは、データのリアルタイム同期を行うための基本構成となります。この構成では、DynamoDBテーブルで発生した変更を即座にOpenSearchへ転送することができ、効率的な検索や分析が可能です。以下では、本構成におけるDynamoDB StreamとLambdaの役割について簡単に説明します。
DynamoDB Streams
DynamoDB Streamsは、DynamoDBテーブルの変更履歴をキャプチャして、テーブルに対する変更イベント(挿入、更新、削除)をストリームとして記録する機能です。このストリームを利用することで、テーブル内で発生した最新の変更を外部のサービスやアプリケーションに通知することができます。
AWS Lambda
AWS Lambdaは、DynamoDB Streamsに新しいイベントが発生した際に自動的に起動する構成を取ることが可能です。Lambda関数はイベントデータを受け取り、必要な処理を実行して結果を他のサービスに送信できます。DynamoDBの変更データをOpenSearchに送るための中間処理を行うのが一般的です。
処理のおおまかな流れは以下になります。
- DynamoDBテーブルで発生した変更はDynamoDB Streamsに記録される
- DynamoDB StreamsをトリガーとしてAWS Lambda関数が起動し、変更イベントを取得する
- Lambda関数内で取得したデータを加工・変換し、OpenSearchのエンドポイントに転送する
- OpenSearchは受け取ったデータをインデックスに格納し、検索に利用
DynamoDB StreamとLambdaを用いたETL構成の運用上の課題点
DynamoDB StreamsとLambdaのETLですが、運用を行っていくうえではいくつか難しいポイントがあります。主な運用課題を大きく分類すると、次のような観点が挙げられます。
1.データ変換と保護の複雑性データをDynamoDBからOpenSearchに転送する際、データの変換やマスキング処理を実装しようと思うとLambda関数内で実装することが一般的かと思いますが、自分で変換・マスキング処理を実装するのは手間も掛かりますし、データの構成が変わった際の変更取り込みの運用負荷も高くなります。特に、データの構造が変わった際や新たなデータパターンが追加された際には、都度Lambda関数のコード変更・テストが必要になります。またデータとして機密情報を扱う場合、特に複数のフィールドやデータ型が混在するケースなどではLambdaでの処理が複雑化しがちです。このため、データ変換の正確性やマスキング処理をLambdaで個別実装する必要があるのは課題の一つとなっています。
2.エラー発生時のハンドリング処理と再実行DynamoDB Streamsを通じて送信されたイベントをLambdaで処理する際、エラーが発生する可能性があります。エラーが発生した場合、処理の再試行やエラーイベントの管理が必要になります。エラーハンドリングが適切に行われないと、データの一貫性が失われたり、同期が中断されるリスクがあり、運用負荷が大きくなる可能性があります。また、Lambdaのスロットリングやリトライポリシー等のパラメータチューニングも必要であり、設計の難易度も高くなります。このため、DynamoDBとLambdaの組み合わせではエラーハンドリングや設計の複雑性が運用上の課題となっています。
3.監査ログとモニタリングの複雑性データ同期の過程において、各ステップでの状態を追跡し、異常発生時の原因を特定するためのログ管理が求められます。DynamoDB StreamsとLambdaを組み合わせた構成では、OpenSearchとLambdaの双方のログを確認したうえで異常個所を特定する必要があります。調査のためにはより詳細なログを出力する必要がありますが、ログを出せばログごとに機密情報が出力されていないかなどの配慮が必要になり、そういった意味でも運用負荷が大きくなります。
以上のようなDynamoDB StreamsとLambdaを用いた構成における課題を踏まえて、これらの運用負担や複雑性を軽減するための新たなアプローチとして、Zero-ETLの導入が注目されています。次章ではDynamoDBとOpenSearchのZero-ETLの仕組みについて詳しく見ていきます。
DynamoDBとOpenSearchのZero-ETL統合
DynamoDBとOpenSearchのZero-ETL統合は、昨年のAWS re:Inventで発表された比較的新しいサービスであり、データ連携の効率化を実現しうるアプローチとして注目されています。上述の通り、従来はDynamoDBとOpenSearchを連携する際には、DynamoDB StreamsとAWS Lambdaを用いたリアルタイムデータ同期が一般的でしたが、運用負荷は低くはありませんでした。
Zero-ETLの登場により、データの同期や変換をよりシンプルで効率的に行うことが可能になりました。Zero-ETLは従来のETLプロセスにおける手動作業や中間処理を省略し、DynamoDBのデータが変更されるたびにOpenSearchに自動で同期される仕組みを提供するものです。このZero-ETLにより、従来の運用課題がどのように解消されるのか、以下で具体的に見ていきます。
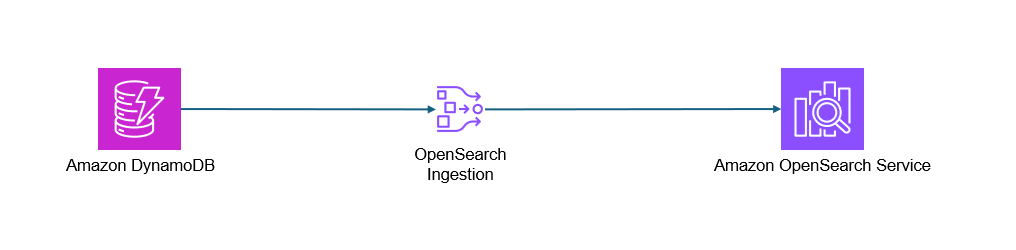
パイプラインを活用したZero-ETLの仕組み
Zero-ETL構成の中核を担うのが「Amazon OpenSearch Ingestion パイプライン」です。パイプラインは、データの変更が発生すると自動でDynamoDBからOpenSearchへデータを転送し、リアルタイムで同期する役割を果たします。これにより、AWS Lambdaによる中間処理が不要となり、運用負荷が軽減されます。パイプラインは設定がシンプルで、AWSの提供する自動化されたデータ転送の仕組みとして、迅速な導入と柔軟なデータ連携を実現します。
Amazon OpenSearch Ingestion パイプラインはData Prepperというデータコレクターを基盤技術として採用し、AWSのマネージドサービスとして提供されています。Amazon OpenSearch Ingestion パイプラインでは、「ソース」、「プロセッサ」、「シンク」のサブセットをサポートしています。 「ソース」はその名の通りデータの連携元となるデータソースで、今回はDynamoDBとOpenSearchを繋げるのでDynamoDBになります。
「プロセッサ」はデータ連携の過程で加えるデータ加工処理になります。OpenSearchが対応しているプロセッサは以下にあります。ETL構成でLambdaが担当していたデータ加工処理はこのプロセッサで実施することができます。
Processors
「シンク」はデータの連携先です。複数指定でき、今回はDynamoDBとOpenSearchを繋げるのでOpenSearchを設定しています。その他、後述しますがデータ連携失敗時にDLQとしてS3を設定することもでき、その場合もこのシンクで指定します。
具体的なパイプライン設定の例と以下になります。設定の際の注意点をコメントとして追記しています。
version: "2"
dynamodb-pipeline:
source:
dynamodb:
acknowledgments: true
tables:
# 連携元のDynamoDBテーブルのArn
- table_arn: "arn:aws:dynamodb:ap-northeast-1:999999999999:table/table-name"
# ストリーミングで他を読み取るための設定。start_positionは読み取り開始箇所を示しており、LATESTは新しく入ったストリーミングデータを読み込む設定。
# 現在のDynamoDB - OpenSearchの連携では現状LATEST以外指定不可。DynamoDBのフルロードオプションは現状としてない。(他のサービスとのインテグレーションだとありそうだったので、今後追加される可能性あり)
stream:
start_position: "LATEST"
# ストリーミング以外のデータを読み込む(フルロードする)際にはS3にエクスポートしてそれを読み込むという挙動をする。
# ここでエクスポート先のS3を指定すると初回パイプライン接続時にエクスポートが行われてOpenSearchに連携される。
export:
# バケット名。Arnではなくバケット名である点に注意
s3_bucket: "bucket-name"
s3_region: "ap-northeast-1"
# バケット内で任意のディレクトリにエクスポート可能。このオプションで指定する。
s3_prefix: "ddb-to-opensearch-export/"
aws:
# 利用するロール。OpenSearchとDynamoDBとS3の権限が必要
sts_role_arn: "arn:aws:iam::999999999999:role/Excute_OpenSearchPipiline"
region: "ap-northeast-1"
processor:
#プロセッサ。詳細は後述。以下はdateを変換する例
- date:
match:
- key: date
patterns: ["yyyyMMdd"]
destination: "@timestamp"
output_format: "yyyy-MM-dd"
sink:
- opensearch:
# 連携先のOpenSearchのドメインを指定する
hosts: [ "https://search-table-name-xxxxxxx.aos.ap-northeast-1.on.aws" ]
# データを格納するOpenSearchのインデックス名を指定する。
index: "table-index"
index_type: custom
# document_id 値には primary_key メタデータ値を使用というZero-ETL統合におけるベストプラクティスに従ったもの。デフォルトで以下の設定
# ベストプラクティス:https://docs.aws.amazon.com/ja_jp/amazondynamodb/latest/developerguide/bp-ingestion-opensearch.html
document_id: "${getMetadata(\"primary_key\")}"
# action 設定には opensearch_action メタデータ値を使用するというZero-ETL統合におけるベストプラクティスに従ったもの。デフォルトで以下の設定
action: "${getMetadata(\"opensearch_action\")}"
# OpenSearch ドキュメントの _version として使うフォーマット文字列。
# https://opensearch.org/docs/latest/data-prepper/pipelines/configuration/sinks/opensearch/ 参照
document_version: "${getMetadata(\"document_version\")}"
document_version_type: "external"
aws:
# 利用するロール。osis-pipelines.amazonaws.comを信頼されたエンティティに指定する必要がある。上記で指定しているロールと同じものを指定する必要がある。
sts_role_arn: "arn:aws:iam::999999999999:role/Excute_OpenSearchPipiline"
region: "ap-northeast-1"
serverless: false
Zero-ETLを用いたときの従来の運用課題へのアプローチ
1.データ変換と保護の複雑性
DynamoDBとOpenSearchを連携する際、特に注意が必要なのがデータ保護の観点です。 DynamoDBに格納されるデータには個人情報や機密情報が含まれることも多いため、データ変換・マスキング処理を行わずそのままOpenSearchに転送するのはデータ保護の観点から懸念点として挙げられます。これを防ぐために、DynamoDBのデータをOpenSearchに転送する手順で適切な変換やマスキングを施し、情報漏洩のリスクを軽減することが必要です。
例えば、個人を特定する情報についてはハッシュ化することで匿名性を高めたり、データの一部だけをマスクして検索に必要な情報のみを保持したりといった対策が考えられます。
これらは従来のETLでも実装は可能でしたが、ETLプロセスではデータの抽出後、複製データが各段階で保持されるため、データが保管される箇所が増え、保護の手間やリスクも増加するという課題がありました。また、そもそものデータベースとしてのデータ構造の違いもLambdaで吸収することが必要でした。
一方でZero-ETL構成ではOpenSearch ingestionパイプラインを利用しているので、データの移動中に変換処理を挟むことが可能になります。
例えば、パイプラインのプロセッサで以下のように記載することで、dateフォーマットの変換を行うことなどが可能です。以下の例ではyyyyMMdd形式で書かれた日付をyyyy-MM-ddの形式に変更して@timestampのディメンションにマッピングしています。
processor:
- date:
match:
- key: date
patterns: ["yyyyMMdd"]
destination: "@timestamp"
output_format: "yyyy-MM-dd"
単に数字8桁として表示されてしまっていたdateの値を日付として検索しやすくすることなどが可能です。

データの変換のほか、一部データの削除やマスキングなども可能です。利用できる処理パターンはOpenSearchの公式ドキュメントをご参考ください。Processors
例えば、エンティティを完全に削除するのであれば以下のように記載することができます。以下の例ではemailというキーに該当するデータを削除します。
processor:
- delete_entries:
with_keys: ["email"]
あるいは、項目にマスクを実施することも可能です。以下の例ではemailというキーに該当するデータの頭三文字以外を”****”という文字列に置き換えています(例えば、email:example@example.com というデータを入れた場合、exa****という形に置換されます)。
processor:
- substitute_string:
entries:
- source: "email"
from: "^(...).*"
to: "$1****"
上のドキュメント内にもあるように、プロセッサではLambdaを利用することも可能です。ingestionパイプライン単体では対応していない種類の変換を行いたい場合などにも、Lambda関数を挟むことで、より柔軟なデータ変換を行うことができます。
まとめです。
- DynamoDBとOpenSearchのデータスキーマの違いもOpenSearch ingestion パイプラインのプロセッサを利用することである程度吸収することができる
- OpenSearch ingestion パイプラインのプロセッサを利用することで柔軟なデータ保護(データの変換とマスキング)を手軽に実装することが可能
2.エラー発生時のハンドリング処理と再実行
DynamoDBとOpenSearchを連携させたシステムに関して、エラーハンドリングの仕組みは重要な要素になります。データ転送時に、ネットワークエラーや一時的なサービスエラーが発生する可能性があり、これを放置するとデータの不整合が発生する可能性があります。DynamoDBからOpenSearchへのデータ同期は通常非同期で行われるため、エラー発生時の再実行は考慮が必要です。
Lambdaを利用したETLでは当然再処理の仕組みを自分で組まなければなりませんでしたが、Zero-ETLでは異なります。Zero-ETLではエラーの発生箇所がDynamoDB、ingestionパイプライン、OpenSearchのいずれの場合であっても中断したところからユーザーが何か操作をすることなく再開する事が可能になります。24時間以上中断が続いてしまうと中断した箇所からの自動再開はできない点には注意が必要ですが、逆に言うと24時間以内に収束するサービス障害などについては自動でリカバリーが可能です。また、データ構成の変更などによりデータ変換部分に不整合が発生し連携に失敗してしまうケースなども考えられますが、Zero-ETLを利用していれば同様に24時間以内に復旧することができれば自動で再処理を行うことが可能です。しかし、現実問題として24時間以内にデータ不整合の問題を解消することは困難ですし、サービス障害による中断が24時間以内に収束しないケースも想定し得ます。そういったケースを考慮し、DLQを設定することも可能です。
以下のようにOpenSearchのingestionのsinkにDLQオプションを設定することで、連携に失敗したデータをS3に退避することもできます。万が一自動で連携ができなくなってしまう状況に陥っても、中断期間中のデータをS3に保存してそれを再度OpenSearchに連携するなどといった手動リカバリーを実施することが可能です。
sink:
- opensearch:
# ---OpenSearchの設定は略---
# DLQオプション: S3を利用したDLQの設定。連携失敗したデータの送信先になる。
dlq:
s3:
bucket: "dlq-bucket-name"
key_path_prefix: "dynamodb-pipeline/dlq"
region: "ap-northeast-1"
sts_role_arn: "arn:aws:iam::999999999999:role/Excute_OpenSearchPipiline"
まとめです。
- DynamoDBとOpenSearchのZero-ETLでは24時間以内の一時的連携失敗はユーザーの手なしに自動リトライが可能
- 24時間以上の継続的な連携失敗にもDLQを使用して手動リカバリー運用を組むことで対応可能
3.監査ログとモニタリングの複雑性
システム運用において、ログはトラブルシューティングやシステム監視のために欠かせない要素になります。しかし、ログを「何でもかんでも出力すれば良い」というわけではありません。むしろ、適切な箇所で必要なログだけを出力することが、運用効率とセキュリティの両面で非常に重要です。 また、システムのパフォーマンスを定期的に監視し、レイテンシーやスループット、リソースの使用状況を把握することも安定した運用を実現するうえでは重要な要素となります。
こういった監査ログとモニタリングの観点からDynamoDBとOpenSearchのZero-ETLを見てみます。
従来のETLでLambdaで連携データを処理しようと思うと、その処理が失敗した理由を調べるためにLambda自身のログを出力・調査することが必要になります。そうなると、どの処理の部分で何をした際にエラーが発生したのかを特定するために処理対象のデータもログに出力する必要が出てくるため、ログの扱いが難しくなります。
対して、Zero-ETL統合の場合はデータ連携はOpenSearch ingestion パイプラインが担うため連携部分をマネージドに寄せる事ができます。OpenSearch ingestion パイプラインにはパイプラインを検証する機能があり、DynamoDB – ingestion パイプラインの連携を検証することができます。フィールド不足や型の不一致、構造エラーなどは検証機能で検知することが可能です。Ingestionパイプライン – OpenSearchに連携する部分でOpenSearchまで到達した後失敗していればOpenSearch側のログで失敗原因まで調査することが可能です。一方で、パイプラインでの失敗をログという形で残したい場合やIngestionパイプラインからOpenSearchに到達する前に失敗してしまった場合などは、OpenSearch ingestionパイプラインで設定できるログ(audit-logs)には失敗レコードや失敗原因までは出力されないため、ingestionパイプライン側で明示的にハンドリングすることが必要になります。詳細は以下の公式ドキュメントをご参考頂ければと思います。
Handling pipeline failures
まとめです。
- OpenSearchのZero-ETL統合ではデータ連携部分をマネージドサービスに寄せることができるため処理途中のログ出力を抑止することが可能
- Ingestionパイプラインのデータ検証機能で、LambdaでのETLの場合にはログ調査が必要だった一部検証を行える一方、OpenSearchまで到達できなかった場合などのログまでハンドリングするためには明示的な構成を組む必要がある。
総括:DynamoDBとOpenSearchのZero-ETL統合は従来の運用課題だった点をマネージドサービスに寄せることで解消
DynamoDBとOpenSearchの従来のETL構成ではLambdaを使った手動構築部分がデータ保護・エラーハンドリング・監査の点でネックになってしまっていましたが、OpenSearch ingestionパイプラインを利用したDynamoDBとOpenSearchのZero-ETL 統合によってそれをマネージドに置き換えることが可能になり、課題を大きく緩和する事ができると言えます。DynamoDB単体でのデータ探索に課題を感じOpenSearchとの組み合わせを考えている方は是非活用検討を進めていただくとよいのではないでしょうか。
※Amazon Web Services、AWS、Powered by AWS のロゴは、Amazon.com. Spend less. Smile more. , Inc.またはその関係会社の商標です。