React Reduxで状態管理の歴史を紐解く
目次
はじめに
こんにちは、NRIデジタルの倉澤です。
Reactで紐解くモダンフロントエンド開発の歴史と進歩の続編として、Reduxを用いた状態管理の歴史を紐解いていきたいと思います。
Reactはユーザーインターフェースを、Reduxは状態管理を担当し、それぞれが進化してきました。ReactとReduxを組み合わせることで、ユーザーインターフェースと状態管理の役割を分離し、関心事を明確にすることができます。見た目の話とデータの話を分けることで開発がしやすくなり、品質も安定します。本稿では、状態管理を中心に解説していきます。
フロントエンドの役割と状態管理という考え方が生まれた背景
フロントエンドは、ユーザーインターフェース(UI)の構築、ユーザーエクスペリエンス(UX)の向上、パフォーマンスの最適化、バックエンドとの連携、セキュリティ対策など多岐にわたります。Webの基本は今も昔もHTML、CSS、JavaScriptです。中でもJavaScriptは動的なユーザーインターフェースの構築、インタラクティブな機能の提供、データの操作と処理、非同期通信(AJAX)など、モダンフロントエンドにおける重要な役割を担っています。本稿ではデータの操作と処理、非同期通信(AJAX)を「状態管理」と呼びます。
Webとスマートフォンの進化に伴い、フロントエンドでは複雑なUI(リアルタイムでのデータ更新やインタラクションなど)のニーズが増加し、複数のデータソース(API、データベース、ローカルストレージなど)を扱うようになりました。Webアプリケーションの大規模化・複雑化が進む中で、「UIの複雑さ」を「マークアップ(見た目)」と「状態管理(データ)」に分離する必要性が出てきました。Webアプリケーション全体でデータを共有しながらデータの一貫性を維持する役割を「状態管理」に機能分離し、マークアップは見た目の領域に集中するように技術が進化していきました。
シングルページアプリケーション(SPA)はこの進化の根幹を成す技術です。以前は、ページごとにサーバーからHTMLを取得してレンダリングするマルチページアプリケーション(MPA)が主流でした。MPAではクライアントサイドでの動的なページ遷移とインタラクションを実現するには課題が多くありました。複雑なUIの要望を実現するために、SPAで動作するReactやVue.jsなどのフレームワークが登場しました。
これらのフレームワークが最初に取り組んだことが「UIの複雑さ」を「マークアップ(見た目)」と「状態管理(データ)」に分離することでした。UIを再利用可能な小さなコンポーネントに分割し、コンポーネント間でのデータの流れを独立して管理することで、フロントエンドのプログラムを構造化することができるようになったのです。
開発者はプログラム上の「見た目」と「データ」の扱いを分けて考えることができるようになり、設計・プログラムがしやすくなるだけでなく、バグの発見や修正が容易になり、開発者間の協力やメンテナンス性が向上しました。
命令的UIから宣言的UIへの進化
「UIの複雑さ」を「マークアップ(見た目)」と「状態管理(データ)」に分離する上で、まずはUIの歴史について触れていきましょう。時は遡り2010年代、Facebook社(現Meta社)のJordan Walke氏がJSConfUS 2013で、FacebookやInstagramで使用していたReactをOSSとして発表しました。この発表で仮想DOMおよび宣言的UIという概念が世に広まりました。
仮想DOMとは、要するに操作に伴うDOMの状態の差分を検出し、その差を埋める同期操作をしてくれるものです。非常に簡単に仮想DOMのアルゴリズムをイメージすると以下のようになります。
操作前の状態 : <div id=’root’>before</div>
操作後の状態 : <div id=’root’>after</div>
差分検出処理 : -before +after
差分同期操作 : document.getElementById(‘root’).textContent = ‘after’;
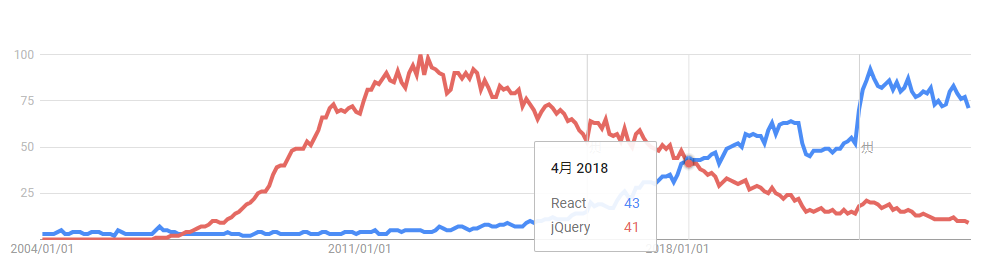
仮想DOMが行っているデータの状態遷移に応じてHTMLを書き換えるという振る舞いは、従来のサーバーサイドで行っていたリクエストに応じてデータの状態を反映し、HTMLを生成することと同じです。しかも、従来のサーバーサイドの仕組みよりもパフォーマンスが高いということで、当時瞬く間に広まりました。2010年代に全盛期だったjQueryは、上記のDOMの操作に伴う差分検出と同期の処理をプログラマーが自ら実装していました。仮想DOMの登場で、この仕事はReactというライブラリが担ってくれることになり、大変ありがたかったことを思い出します。いつしかjQueryや純粋なJavaScriptは命令的UI、ReactをはじめとするモダンJSは宣言的UIと呼ばれるようになりました。
命令的UI : 手順を逐次記述してUIを操作し、状態管理を手動で行う。
宣言的UI : 最終的なUIの状態を記述し、状態変化に応じて自動的にUIを更新する。
では具体的にどのような差があるのか、jQueryとReactを実際のソースコードを元に比較してみたいと思います。外部のAPIにリクエストし、取得したデータを画面に表示するというシンプルなソースコードで説明します。「マークアップ(見た目)」の話と「状態管理(データ)」の話をコメント内に記載しておきますのでご覧ください。
命令的UI
まずは命令的UIを素のJavaScriptで記述します。JavaScriptのfetchを使用して外部APIからデータを取得し、直接DOMを操作してデータをレンダリングする処理を行っています。
<!DOCTYPE html>
<html>
<head>
<title>Fetch API Example</title>
</head>
<body>
<div id="root">Loading...</div> // ★見た目
<script>
// 外部APIのURL
const apiUrl = 'https://api.example.com/data';
// データを取得し、画面に表示する関数
function fetchData() {
// データを取得する処理 ★データ
fetch(apiUrl)
// API 正常応答 ★データ
.then(data => {
// 画面に正常データを表示する処理 ★見た目
const root = document.getElementById('root');
root.textContent = `Title: ${data.title}, Body: ${data.body}`;
})
// API 異常応答 ★データ
.catch(error => {
console.error('Error fetching data:', error);
// 画面にエラーデータを表示する処理 ★見た目
const root = document.getElementById('root');
root.textContent = 'Error fetching data';
});
}
// データを取得する ★データ
fetchData();
</script>
</body>
</html>
宣言的UI
次に宣言的UIです。JavaScriptのfetchを使用して外部APIからデータを取得し、仮想DOMがレンダリングしてデータをコンポーネント内に表示します。
import React, { useState, useEffect } from 'react';
import ReactDOM from 'react-dom';
// APIからデータを取得して表示するコンポーネント
function App() {
// ★データ
const [data, setData] = useState(null);
const [loading, setLoading] = useState(true);
const [error, setError] = useState(null);
useEffect(() => {
// 外部APIのURL
const apiUrl = 'https://api.example.com/data';
// データを取得する ★データ
fetch(apiUrl)
.then(response => response.json())
.then(data => {
setData(data);
setLoading(false);
})
.catch(error => {
setError(error);
setLoading(false);
});
}, []);
// ローディング中の表示 ★見た目
if (loading) {
return <div>Loading...</div>;
}
// エラーが発生した場合の表示 ★見た目
if (error) {
return <div>Error fetching data</div>;
}
// データの表示 ★見た目
return (
<div>
<h1>Title: {data.title}</h1>
<p>Body: {data.body}</p>
</div>
);
}
// Reactアプリをレンダリング
ReactDOM.render(<App />, document.getElementById('root'));
いかがでしょうか。宣言的UIの方が、データを処理するプログラム(状態管理)とデータを表示するプログラム(マークアップ)が分かれており、直感的ではないでしょうか。命令的UIから宣言的UIへの進化により、開発者はマークアップ(見た目)と状態管理(データ)を分離することに成功し、描画のためだけのデータ処理から解放され、本質的なビジネス価値につながる領域のデータ処理(状態管理)や、大規模で複雑なWebアプリケーションの開発に取り組めるようになったのです。
命令的UI : 手順を逐次記述してUIを操作し、状態管理を手動で行う。
宣言的UI : 最終的なUIの状態を記述し、状態変化に応じて自動的にUIを更新する。
状態管理ライブラリの進化
Reactでの状態管理ライブラリReduxの登場
さて、主題の状態管理に話を戻します。「状態管理」の役割は、データの操作と処理、非同期通信(AJAX)です。2024年現在では、Redux、Redux Toolkit、RTK Queryの利用が主流になっています。これらの説明に入る前に、Reduxの歴史を振り返りたいと思います。
Reactは、Fluxというデータ管理の考え方を元に作られています。Fluxの中心的な概念は「一方向データフロー」です。データの流れが特定のルールに従うため、予期せぬ状態変更のリスクが減り、データの整合性を保つのが容易になります。データの流れが一方向であるため、データがどこから来てどこに行くのかが明確です。リアクティブ性(データの変更を検知して、そのデータを利用している関数を自動的に再計算すること)が向上し、ユーザー体験が改善されます。
このシンプルなデータフローにより、コードの理解が容易になり、新しい開発者がプロジェクトに参加する際の学習曲線が低くなります。大規模なWebアプリケーションを複数の開発者が同時に異なる部分を開発しても、データの衝突や競合が発生しにくくなります。詳細は、React で紐解くモダンフロントエンド開発の歴史と進歩の Flux という設計思想の章をご覧ください。
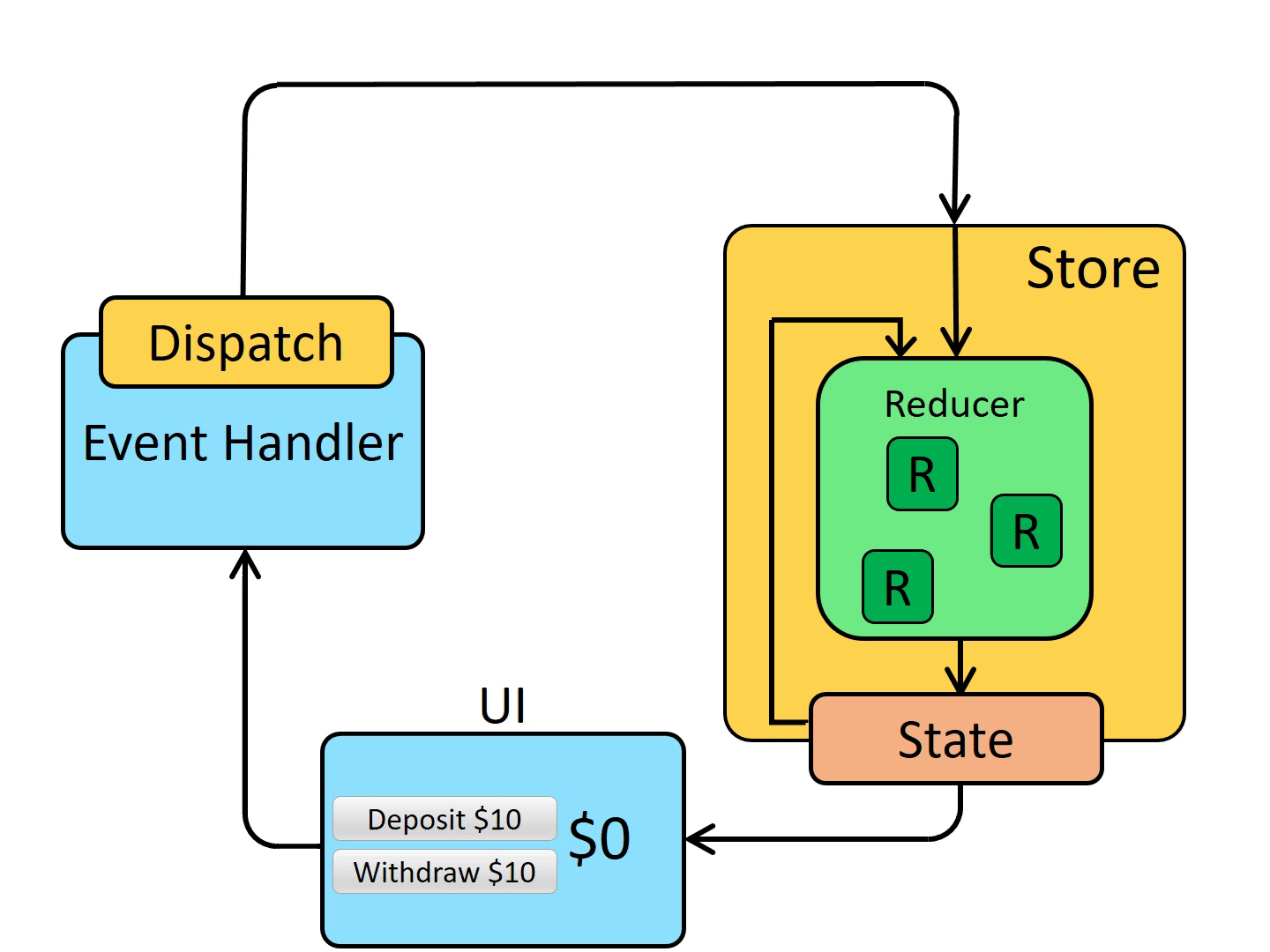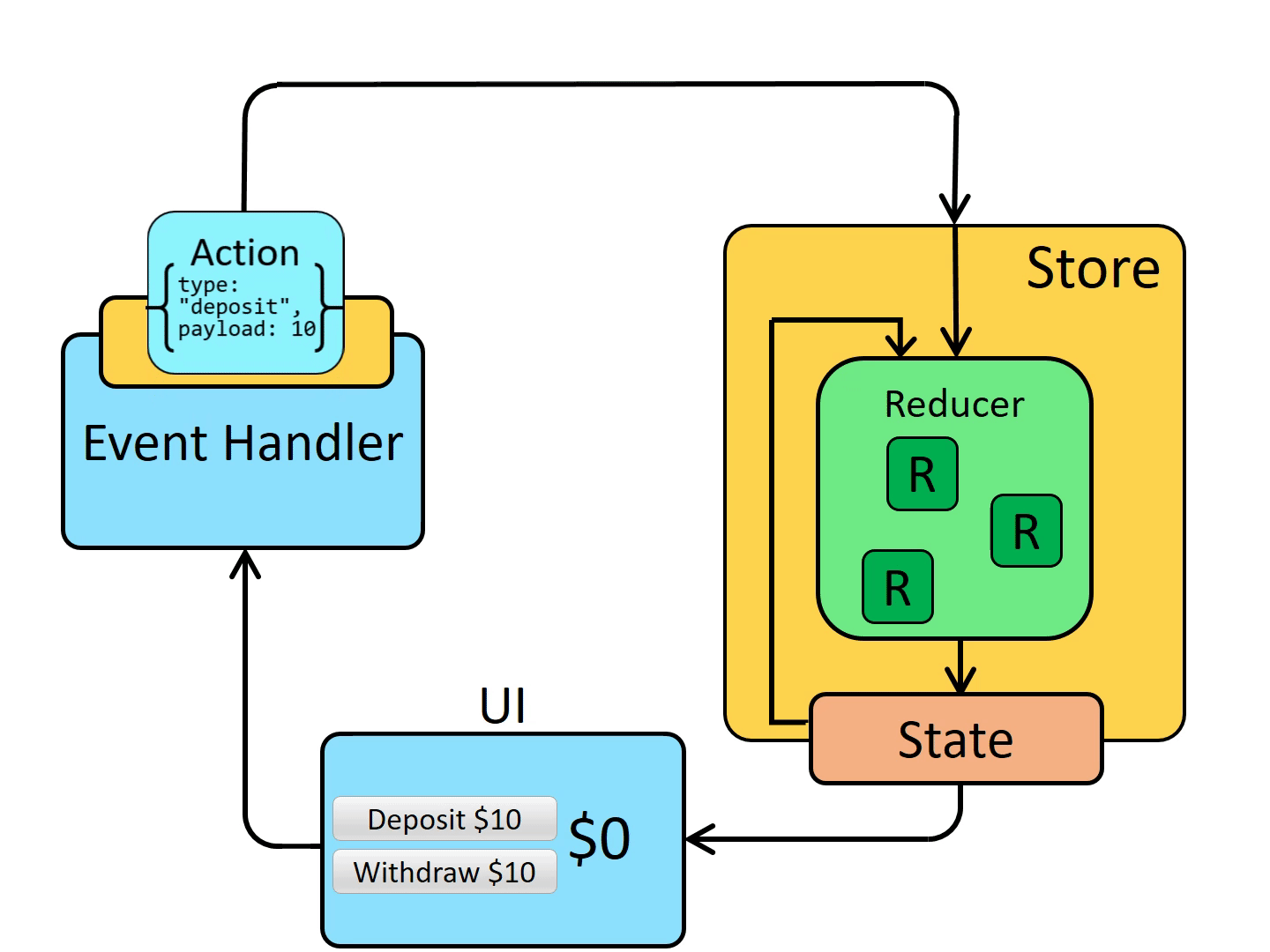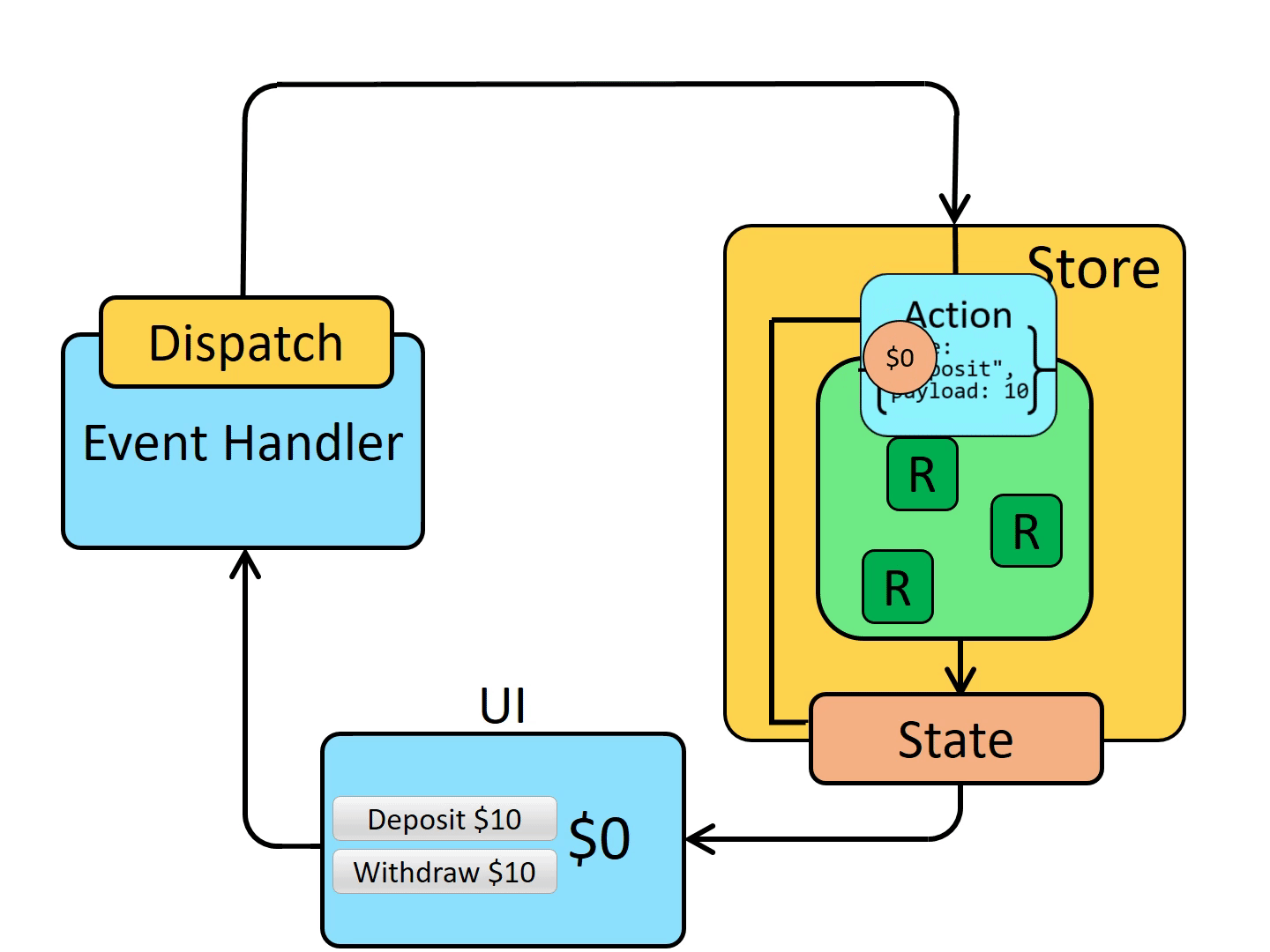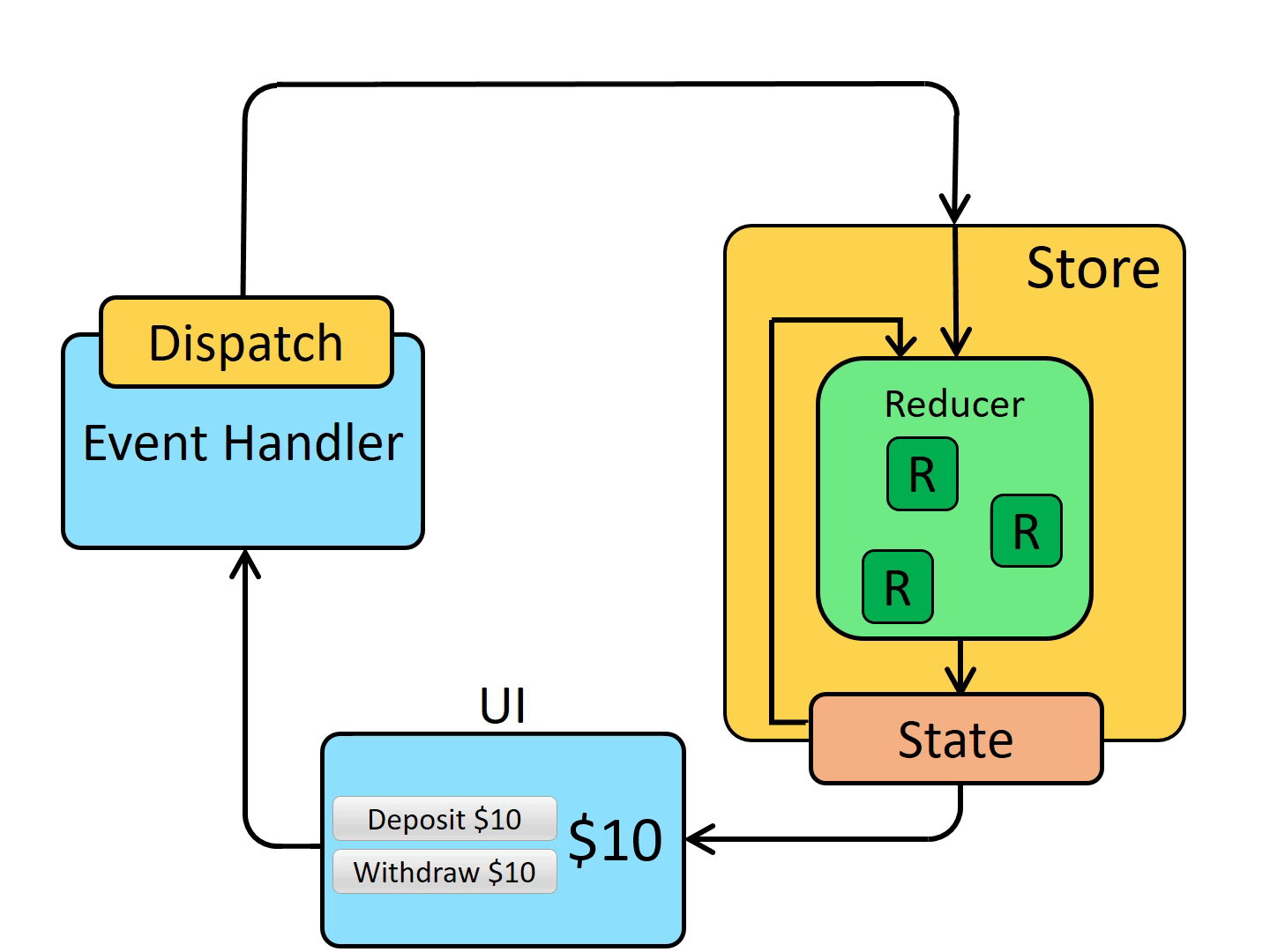
そして、Fluxの考え方を元にReduxという状態管理ライブラリが生まれました。
基本となる考え方は以下の通りです。
- アプリケーションの状態(State)を一箇所(Store)に集約管理
- 状態(State)は純粋な関数(Reducer)を通じてのみ変更可能
- 状態(State)は直接変更できず、UI上の特定のイベントや操作に応じてアクション(Action)を作成し、ストアに送信(Dispatch)して状態を変更する
2010年代のJavaScriptにおける非同期通信(AJAX)の急速な進化は目を見張るものでした。現在では、ECMAScriptの標準化によってPromiseやasync/awaitといった非同期処理をシンプルに扱うための機能が追加され、非同期通信の実装が簡単になりました。当時はコールバック関数の多重ネスト、エラーハンドリングの複雑さ、状態管理の困難さ、同期と非同期の混在、古いブラウザのサポートなど、多くの考慮事項があり、フロントエンドエンジニアは大変苦労しました。Reactと共に進化したReduxは、状態を一元管理することで、非同期通信によって変更される状態も一貫して管理できるようになりました。
そして、Reduxは、非同期通信を含む非同期処理の標準的な方法・ミドルウェアを提供しました。 例えば、API通信でデータを取得して画面に表示し、その後、画面操作によってデータを書き換えた結果を即時に画面に反映する処理などです。こういった処理を実装しようとすると、同期と非同期が混在した実装になります。標準化されたミドルウェアを利用しないと、かなり複雑になります。それがRedux ThunkとRedux Sagaです。シンプルな非同期処理にはRedux Thunkが適しており、複雑な非同期ロジックにはRedux Sagaが適しています。
Redux Thunkは、Reduxのミドルウェアであり、非同期処理(例えば、API呼び出し)を行うために使われます。通常のアクションはプレーンなJavaScriptオブジェクトですが、Redux Thunkを使うことで、アクションとして関数をディスパッチできるようになります。この関数は、dispatch関数とgetState関数を受け取ることができます。
Redux Sagaは、Reduxアプリケーションで副作用(例えば、データの取得やブラウザキャッシュへのアクセス)を処理するためのミドルウェアです。ジェネレータ関数を使い、非同期処理をより宣言的に管理できます。
先ほどまでとの比較のために、外部のAPIをリクエストし、取得したデータを画面に表示するReactコンポーネント(component.js)とRedux状態管理(store.js)のサンプルコードを示します。Redux Thunkを用いてボイラープレートを記載します。「UIの複雑さ」を「マークアップ(見た目)」と「状態管理(データ)」に分離できるようになっていることをご確認ください。
store.js ★データ
import { createStore, applyMiddleware } from 'redux';
import thunk from 'redux-thunk';
// 初期状態 ★データ
const initialState = {
data: [],
loading: false,
error: null
};
// アクションタイプ ★データ
const FETCH_DATA_REQUEST = 'FETCH_DATA_REQUEST';
const FETCH_DATA_SUCCESS = 'FETCH_DATA_SUCCESS';
const FETCH_DATA_FAILURE = 'FETCH_DATA_FAILURE';
// アクションクリエーター ★データ
const fetchDataRequest = () => ({ type: FETCH_DATA_REQUEST });
const fetchDataSuccess = data => ({ type: FETCH_DATA_SUCCESS, payload: data });
const fetchDataFailure = error => ({ type: FETCH_DATA_FAILURE, payload: error });
// 非同期アクション ★データ
export const fetchData = () => async dispatch => {
dispatch(fetchDataRequest());
try {
const response = await fetch('https://api.example.com/data');
const data = await response.json();
dispatch(fetchDataSuccess(data));
} catch (error) {
dispatch(fetchDataFailure(error.message));
}
};
// リデューサー ★データ
const reducer = (state = initialState, action) => {
switch (action.type) {
case FETCH_DATA_REQUEST:
return { ...state, loading: true, error: null };
case FETCH_DATA_SUCCESS:
return { ...state, loading: false, data: action.payload };
case FETCH_DATA_FAILURE:
return { ...state, loading: false, error: action.payload };
default:
return state;
}
};
// ストアの作成 ★データ
const store = createStore(reducer, applyMiddleware(thunk));
export default store;
import React, { useEffect } from 'react';
import { useSelector, useDispatch } from 'react-redux';
import { fetchData } from './store';
// APIからデータを取得して表示するコンポーネント
const App = () => {
// Reduxのdispatch関数を取得 ★データ
const dispatch = useDispatch();
// Reduxストアから状態を取得 ★データ
const { data, loading, error } = useSelector(state => state);
// コンポーネントがマウントされたときにデータをフェッチする ★データ
useEffect(() => {
dispatch(fetchData());
}, [dispatch]);
// データをロード中の表示 ★見た目
if (loading) return <div>Loading...</div>;
// エラーが発生した場合の表示 ★見た目
if (error) return <div>Error: {error}</div>;
// データの表示 ★見た目
return (
<div>
<h1>Title: {data.title}</h1>
<p>Body: {data.body}</p>
</div>
);
};
export default DataComponent;
Reduxの使用を簡単にするRedux Toolkitの登場
Redux Thunkでは、アクションとリデューサーを標準化しましたが、同じ内容のボイラープレートを何度も書くことになりました。上記のRedux Thunkのstore.jsで書いている内容は、API一本の非同期アクションの状態管理のためのものです。APIの本数が増えるたびにこのボイラープレートを量産する必要があり、開発者を苦しめました。
Redux Toolkitは、Reduxの使用を簡単にし、ベストプラクティスに従いやすくするための公式ツールセットです。開発者は煩雑な設定や冗長なコードから解放され、より生産的な開発が可能になります。
ボイラープレート部分をRedux Toolkitでは、createSlice、createAsyncThunk、extraReducersの関数を用いて簡潔に書くことができます。createSliceは、アクションタイプ、アクションクリエーター、リデューサーを一つのスライスとしてまとめて定義します。createAsyncThunkは非同期アクションを定義し、extraReducersでリデューサーが非同期アクションの各状態(pending、fulfilled、rejected)をハンドリングします。
store.js ★データ
import { configureStore, createSlice, createAsyncThunk } from '@reduxjs/toolkit';
// 非同期アクション ★データ
export const fetchData = createAsyncThunk('data/fetchData', async () => {
const response = await fetch('https://api.example.com/data');
const data = await response.json();
return data;
});
// スライスの作成 ★データ
const dataSlice = createSlice({
name: 'data',
initialState: {
data: [],
loading: false,
error: null
},
reducers: {},
extraReducers: (builder) => {
builder
.addCase(fetchData.pending, (state) => {
state.loading = true;
state.error = null;
})
.addCase(fetchData.fulfilled, (state, action) => {
state.loading = false;
state.data = action.payload;
})
.addCase(fetchData.rejected, (state, action) => {
state.loading = false;
state.error = action.error.message;
});
}
});
// ストアの作成 ★データ
const store = configureStore({
reducer: {
data: dataSlice.reducer
}
});
export default store;
import React, { useEffect } from 'react';
import { useSelector, useDispatch } from 'react-redux';
import { fetchData } from './store';
// APIからデータを取得して表示するコンポーネント
const App = () => {
// ★データ
const dispatch = useDispatch(); // Reduxのdispatch関数を取得
const { data, loading, error } = useSelector(state => state.data); // Reduxストアからデータ、ローディング状態、エラーを取得
// コンポーネントがマウントされたときにfetchDataアクションをディスパッチ ★データ
useEffect(() => {
dispatch(fetchData());
}, [dispatch]);
// ローディング状態のときの表示 ★見た目
if (loading) return <div>Loading...</div>;
// エラーが発生したときの表示 ★見た目
if (error) return <div>Error: {error}</div>;
// データが正常に取得できたときの表示 ★見た目
return (
<div>
<h1>Title: {data.title}</h1>
<p>Body: {data.body}</p>
</div>
);
};
export default App;
いかがでしょうか。Redux Toolkitを使うことで、かなりスッキリしたと思いませんか。それでもまだ、store.jsには工夫の余地があります。それはデータのフェッチおよびキャッシュの部分です。
API非同期通信の状態管理に特化したRTK Queryの登場
RTK Queryは、Redux Toolkitに含まれるデータフェッチおよびキャッシングのためのツールです。要するに、API通信の非同期処理に特化した状態管理ツールです。主な特徴と役割は以下の通りです。
データフェッチの簡素化 : API呼び出しのロジックを簡単に記述できるようになる
自動キャッシング : フェッチされたデータを自動的にキャッシュし、再利用可能
キャッシュの無効化とリフェッチ : データの更新やキャッシュの無効化
統合された状態管理 : APIのデータフェッチと状態管理を統合
RTK Queryを使用することで、createAsyncThunkやextraReducersを手動で設定する必要がなくなります。APIエンドポイントの定義とデータフェッチのロジックが一箇所に集約され、コードの見通しが良くなります。また、非同期アクションの状態(loading、success、error)を自動で管理し、フックを通じて利用できます。キャッシュやリフェッチもRTK Queryが自動的に処理します。
これもサンプルコードで比べてみましょう。
store.js ★データ
import { configureStore, createSlice } from '@reduxjs/toolkit';
import { createApi, fetchBaseQuery } from '@reduxjs/toolkit/query/react';
// 非同期アクション ★データ
const api = createApi({
reducerPath: 'api',
baseQuery: fetchBaseQuery({ baseUrl: 'https://api.example.com/' }), // fetchBaseQueryを使用してベースURLを設定
endpoints: (builder) => ({
fetchData: builder.query({
query: () => 'data' // データを取得するエンドポイントを定義
})
})
});
// ストアの作成 ★データ
const store = configureStore({
reducer: {
[api.reducerPath]: api.reducer // APIリデューサーをストアに追加
},
middleware: (getDefaultMiddleware) =>
getDefaultMiddleware().concat(api.middleware) // APIミドルウェアをストアに追加
});
export const { useFetchDataQuery } = api; // フックをエクスポート
export default store; // ストアをエクスポート
import React from 'react';
import { useFetchDataQuery } from './store';
// APIからデータを取得して表示するコンポーネント
const App = () => {
// フックを使用して、データ、エラー、ローディング状態を取得 ★データ
const { data, error, isLoading } = useFetchDataQuery();
// ローディング状態のときの表示 ★見た目
if (isLoading) return <div>Loading...</div>;
// エラーが発生したときの表示 ★見た目
if (error) return <div>Error: {error.message}</div>;
// データが正常に取得できたときの表示 ★見た目
return (
<div>
<h1>Title: {data.title}</h1>
<p>Body: {data.body}</p>
</div>
);
};
export default App;
いかがでしょうか。Redux ThunkからRedux Toolkit、そしてRTK Queryへと進化することで、ソースコードの印象が大きく変わりますよね。2010年代に登場したReduxも、時代を経て進化してきたことを実感します。
状態管理ライブラリReduxのまとめ
これまでの説明をまとめると、Reduxが解決した状態管理の課題は以下のようになります。
グローバルな状態管理 : Reactのコンポーネント間での状態共有の複雑さを解決
予測可能な状態変遷 : 純粋なリデューサーを使った予測可能な状態変遷
非同期処理と副作用の管理 : Redux ThunkやRedux Sagaなどを使った非同期処理の管理
データの一元管理とキャッシング : RTK Queryによるデータフェッチとキャッシング
当然ですが、他にも状態管理の課題を解決する手法は登場してきましたし、これからも登場することでしょう。例えば、Context API + useReducer、React Query / SWR、Zustand / Jotai などです。
Reduxは歴史も長く、エコシステムも強力です。ご自身のプロジェクトの状況に合わせて、最適なツールを選択することをおすすめします。
データのチェック処理はどうすべきか
システムを開発する上で避けては通れないのがデータのチェック処理です。Redux自体は状態管理を行っていますが、データが正しいかどうかまではチェックしていません。チェック処理は大きく、単項目チェックと相関チェックに分けられます。
単項目チェック
本稿では、システム開発においてデータの型や桁が正しいかを検証することを「単項目チェック」と呼びます。単項目チェックは、プログラミングにおける検証手法の一つであり、データ品質を保証するために行います。
TypeScriptには型定義があります。しかし、TypeScriptは静的型チェックであるため、コンパイル時には型チェックを行いますが、実行時には渡された値が正しい型であるかをチェックすることはありません。
例えば、電子メールアドレスが有効な形式(例:user@example.com)であることを実行時に確認するチェック処理を実装すると、以下のようになります。
function isValidEmail(email: string): boolean {
const re = /^(([^<>()[\]\\.,;:\s@"]+(\.[^<>()[\]\\.,;:\s@"]+)*)|(".+"))@((\[[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\])|(([a-zA-Z\-0-9]+\.)+[a-zA-Z]{2,}))$/;
return re.test(String(email).toLowerCase());
}
一つや二つの型チェックであれば実装してもいいかもしれませんが、大変ですよね。私が取り組んだプロジェクトでは、外部のAPIの本数もかなり多く、渡される項目数も相当数ありました。そこで、OSSライブラリを活用し、実行時の型チェックができないかと考えました。
前述の通り、API通信で外部から取得したデータの実行時チェックは、TypeScriptの型定義だけでは確認できません。一つ一つの項目に型桁チェックを実装するのは現実的ではないので、Zodというバリデーションライブラリの利用をおすすめします。Zodはスキーマ定義をすることで実行時のバリデーション設定を行うことができます。一般的にはフォームなどの入力値でバリデーションを行いますが、筆者はRTK Queryの戻り値に対してZodでバリデーションをかけました。
さらに、接続先システムがOpenAPIの仕様に準じてAPIインターフェース定義を行っていたため、OpenAPIのSwaggerファイルからZodのスキーマ定義を自動生成し、実行時バリデーションチェックを行うことにしました。
OpenAPIの仕様から単項目チェックバリデーションを自動生成する仕組みを作ったことで、フロントのReactシステムで扱うデータはすべて検証された状態を実現し、品質がかなり向上しました。皆さんにもぜひおすすめします。この着想を得たのは、NRI OpenStandia Advent Calendar 2023(Qiita)の記事です。お時間があればぜひご一読ください。
では、実際にどのような実装となるのかをご紹介していきます。
Zodは、TypeScriptに特化したバリデーションライブラリです。シンプルなAPIと型推論があり、スキーマ検証とデータチェックを行います。TypeScriptプログラム上のエラー処理とバリデーションに貢献します。
name(氏名)は文字列であり、age(年齢)は0歳以上の数値であるというスキーマ定義を行い、parse()メソッドでデータのチェックを行います。
import { z } from 'zod'
const PersonSchema = z.object({
name: z.string(),
age: z.number().min(0),
})
// 実行時の単項目チェックは正常
PersonSchema.parse({
name: "野村太郎",
age: 30,
})
// 実行時の単項目チェックでエラー
PersonSchema.parse({
name: "野村太郎",
age: -5, // 年齢は0歳以上
})
Swagger(現OpenAPI)は、REST APIの設計情報を記述するための標準仕様です。ドキュメントの自動生成やモックサーバー、テストの実行などに利用できます。弊社が提供している企業のWeb APIサービス構築を支援する「API Atelier」でも、OpenAPIを利用しています。
Swagger Editorのサンプルを元に解説します。APIの設計情報をJSON形式のSwaggerファイル(左)に記述することで、マシンが理解しやすく、人が読みやすいドキュメント(右)が出来上がります。開発者は、APIの設計、開発、テスト、管理を一元化することができます。
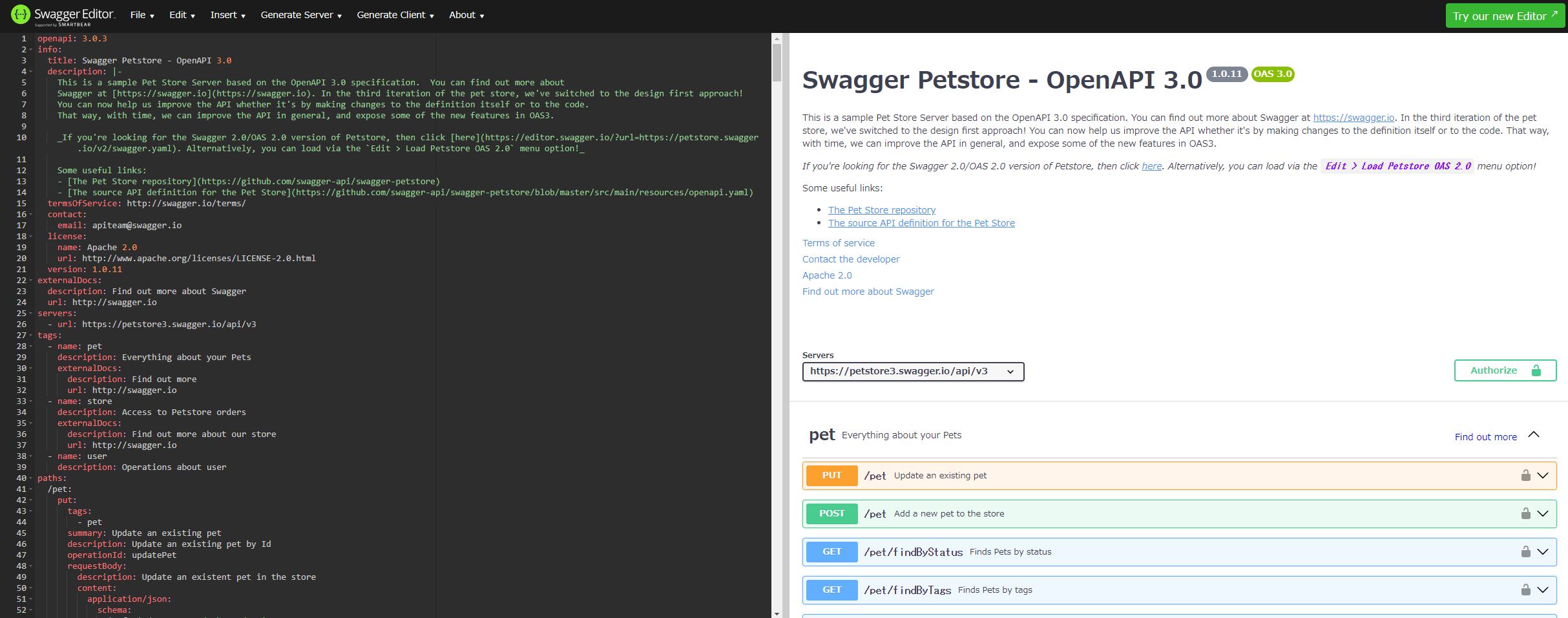
Swaggerファイルをイメージしていただくために抜粋して説明します。infoはAPI全体の説明、pathsはAPIのエンドポイントを示します。/pet/{petId}はAPIのパスでgetはHTTPメソッドのGetを指定しています。parametersはリクエストパラメータ、responseはHTTPステータスコードに応じたレスポンスが記述されています。詳しくはSwagger Editorをご確認ください。
openapi: 3.0.3
info:
title: Swagger Petstore - OpenAPI 3.0
paths:
/pet/{petId}:
get:
tags:
- pet
summary: Find pet by ID
description: Returns a single pet
operationId: getPetById
parameters:
- name: petId
in: path
description: ID of pet to return
required: true
schema:
type: integer
format: int64
responses:
'200':
description: successful operation
content:
application/json:
schema:
$ref: '#/components/schemas/Pet'
application/xml:
schema:
$ref: '#/components/schemas/Pet'
'400':
description: Invalid ID supplied
'404':
description: Pet not found
security:
- api_key: []
- petstore_auth:
- write:pets
- read:pets
ここまではAPIの提供側の話をしていましたがAPIの利用側の目線でOpenAPI(Swagger)を見ていきます。フロントエンドからfetch関数でAPI通信を行います。以下のリクエストを行う際にはpetIdは数値であるというI/F仕様になっています。またAPIからのレスポンスのデータを使って画面に表示する上でペットの名前nameは必須値であるべきです。
GET https://petstore3.swagger.io/api/v3/pet/{petId}
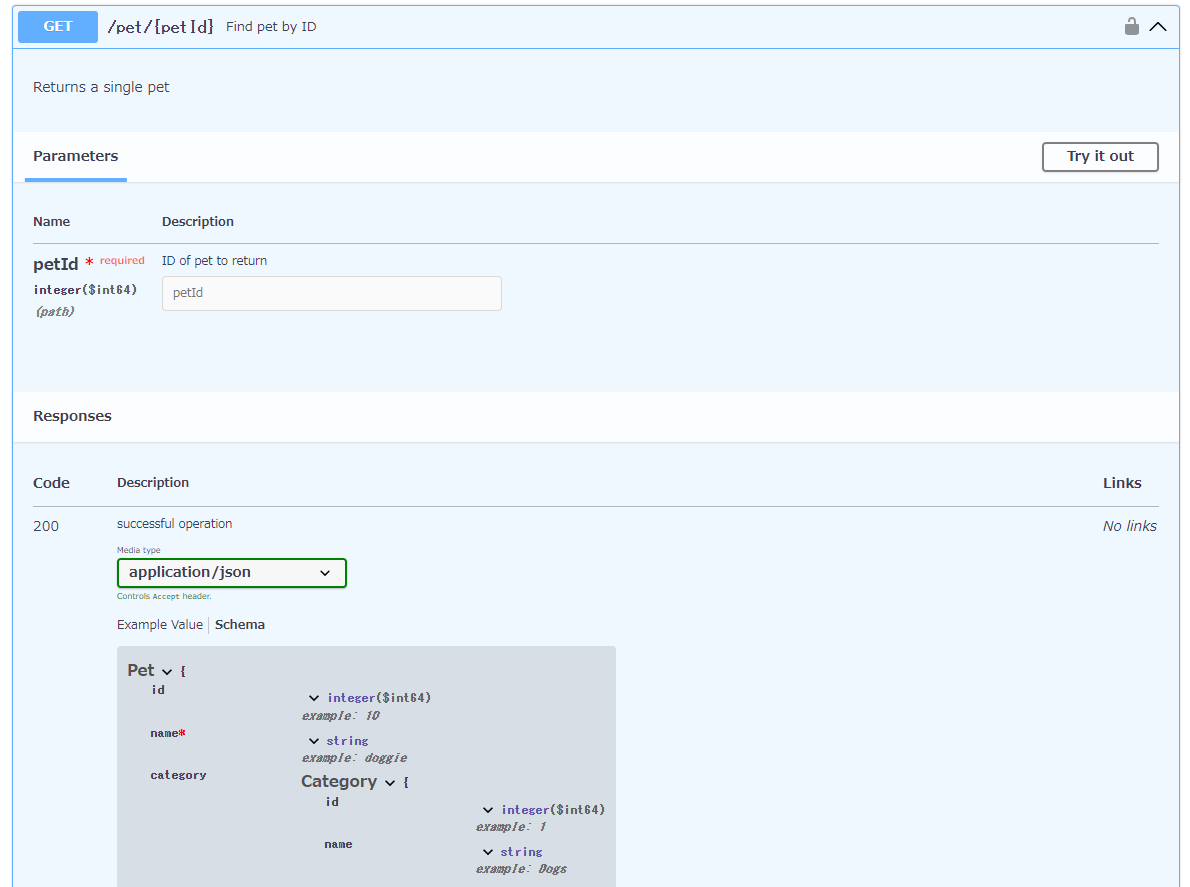
API通信の実装イメージです。petIdのリクエスト値やnameのレスポンス値の単項目チェックの実装が冗長な印象ですよね。
interface Pet {
id: number;
name: string;
// ...他のプロパティ
}
async function getPetById(petId: any): Promise<Pet> {
// リクエストの petId が数値であることを単項目チェックする
if (typeof petId !== 'number') {
throw new Error('Expected petId to be a number');
}
const response = await fetch(`https://petstore3.swagger.io/api/v3/pet/${petId}`);
if (!response.ok) {
throw new Error('Network response was not ok');
}
const petData = await response.json();
// レスポンスの name は必須値であることを単項目チェックする
if (!('name' in petData)) {
throw new Error('Expected property "name" is missing in the returned data');
}
return petData as Pet;
}
API通信を行う上で、リクエストやレスポンスの単項目チェックを一つ一つ実装していくのはかなりの手間です。そこでバリデーションチェックはZodに寄せてOpenAPIの仕様からZodの型定義を自動生成するopenapi-zod-clientを導入することにしました。以下のコマンドを実行すると、画像のようにOpenAPI(Swagger)からZodの型定義が自動生成されます。
pnpx openapi-zod-client “./input/file.yaml” -o “./output/client.ts”
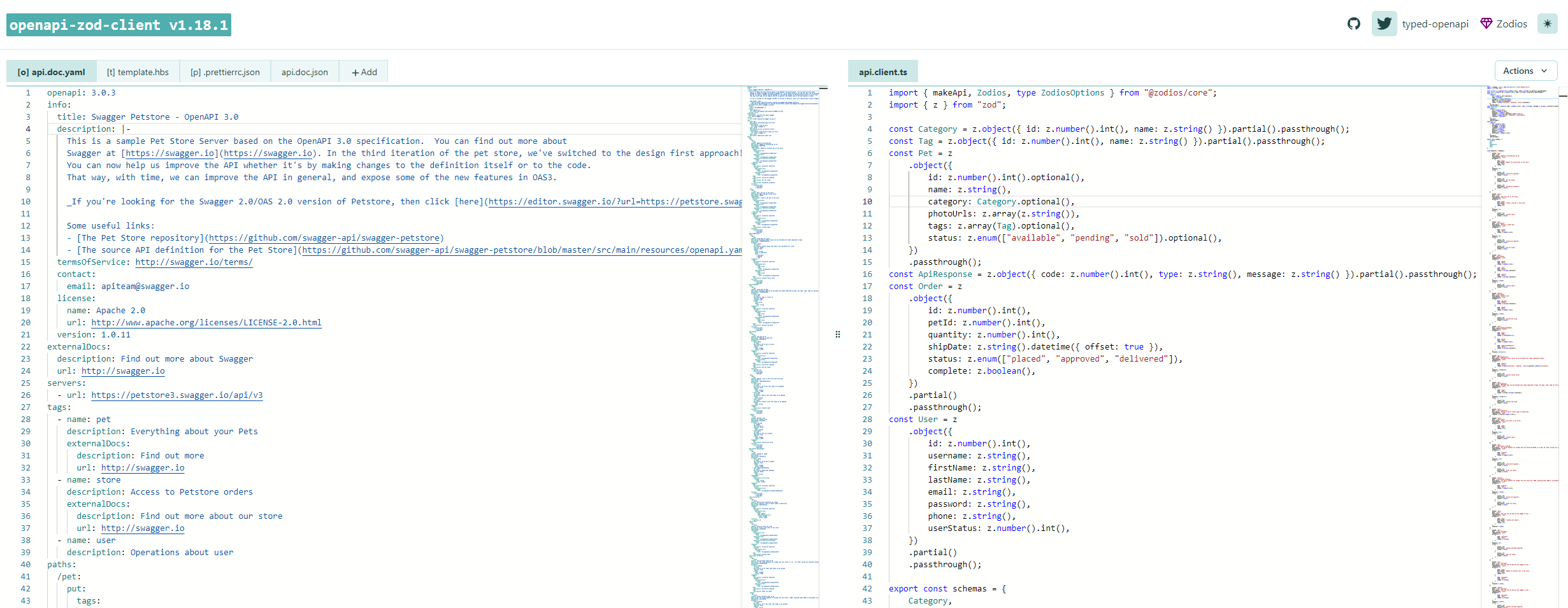
自動生成したZodの型定義は以下のようになっています。
schema.ts
import { z } from "zod";
export const Pet = z
.object({
id: z.number().int().optional(),
name: z.string(),
category: Category.optional(),
photoUrls: z.array(z.string()),
tags: z.array(Tag).optional(),
status: z.enum(["available", "pending", "sold"]).optional(),
})
.passthrough();
- id : idは整数のオプションであり、存在しなくても良いと定義されています。
- name : nameは文字列であり、必須です。
- category : categoryはCategory型であり、存在しなくても良いと定義されています。
- photoUrls : photoUrlsは文字列の配列です。
- tags : tagsはTag型のアイテムを持つ配列で、存在しなくてもよいと定義されています。
- status : statusはenum(列挙型)であり、”available”、”pending”、”sold”の3つの値を持つことができます。これも存在しなくてもよいと定義されています。
最後に、.passthrough()メソッドは、未知のプロパティを許可します。このメソッドを使用すると、スキーマに定義されていない追加のフィールドがあった場合でもエラーにならず、そのまま通過させることができます。つまり、このPetスキーマはid, name, category, photoUrls, tags, status以外のフィールドも受け入れます。
それでは、自動生成したZodの型定義を使ってRTK QueryのAPIリクエストとレスポンスのデータに対してを単項目チェック処理を追加してみましょう。queryでリクエストパラメータ、transformResponseでレスポンスデータをチェックすることが出来ます。
ただ、リクエスト・レスポンスのデータの型が異なっていた場合にシステムエラーにしてしまうと、実運用では困ることもあるのではないでしょうか。ZodライブラリにはparseとsafeParse があります。parseはスキーマと一致しないと直接例外を投げますが、safeParseは細かくハンドリングすることができます。そのため、システムエラーにするほどではない型の違いは適切に処理するとよいかと思います。
store.ts
import { Pet } from './schema';
export const petstoreApi = createApi({
reducerPath: 'petstoreApi',
baseQuery: fetchBaseQuery({ baseUrl: 'https://petstore3.swagger.io/api/v3/' }), // APIのベースURL
endpoints: (builder) => ({
// ペットのID(number)をリクエストパラメータで受け取り、レスポンスは Pet 型のデータを返す
getPetById: builder.query<Pet, number>({
// クエリ関数はリクエストする具体的なAPIエンドポイントとそのパラメータを定義する
query: (params) => {
// リクエストパラメータを Pet.id の Zod 型定義に従って単項目チェック
const parsedParams = Pet.id.parse(params.petId);
if(parsedParams instanceof Error) {
throw parsedParams;
}
return `pet/${params.petId}`; // API エンドポイント
},
// レスポンスデータを Pet の Zod 型定義に従って単項目チェック
transformResponse: (response: any) => {
const parsedResponse = Pet.parse(response);
if(parsedResponse instanceof Error) {
throw parsedResponse;
}
return parsedResponse;
},
}),
}),
});
export const { useGetPetByIdQuery } = petstoreApi;
import React from 'react';
import { useGetPetByIdQuery } from './petstoreApi';
const PetDetails = ({ petId }: { petId: number }) => {
const { data: pet, isError, isLoading } = useGetPetByIdQuery(petId);
if (isLoading) {
return <div>Loading...</div>;
}
if (isError || !pet) {
return <div>Error occurred or pet not found</div>;
}
return (
<div>
<h2>{pet.name}</h2>
{/* Other pet details... */}
</div>
);
};
export default PetDetails;
相関チェック
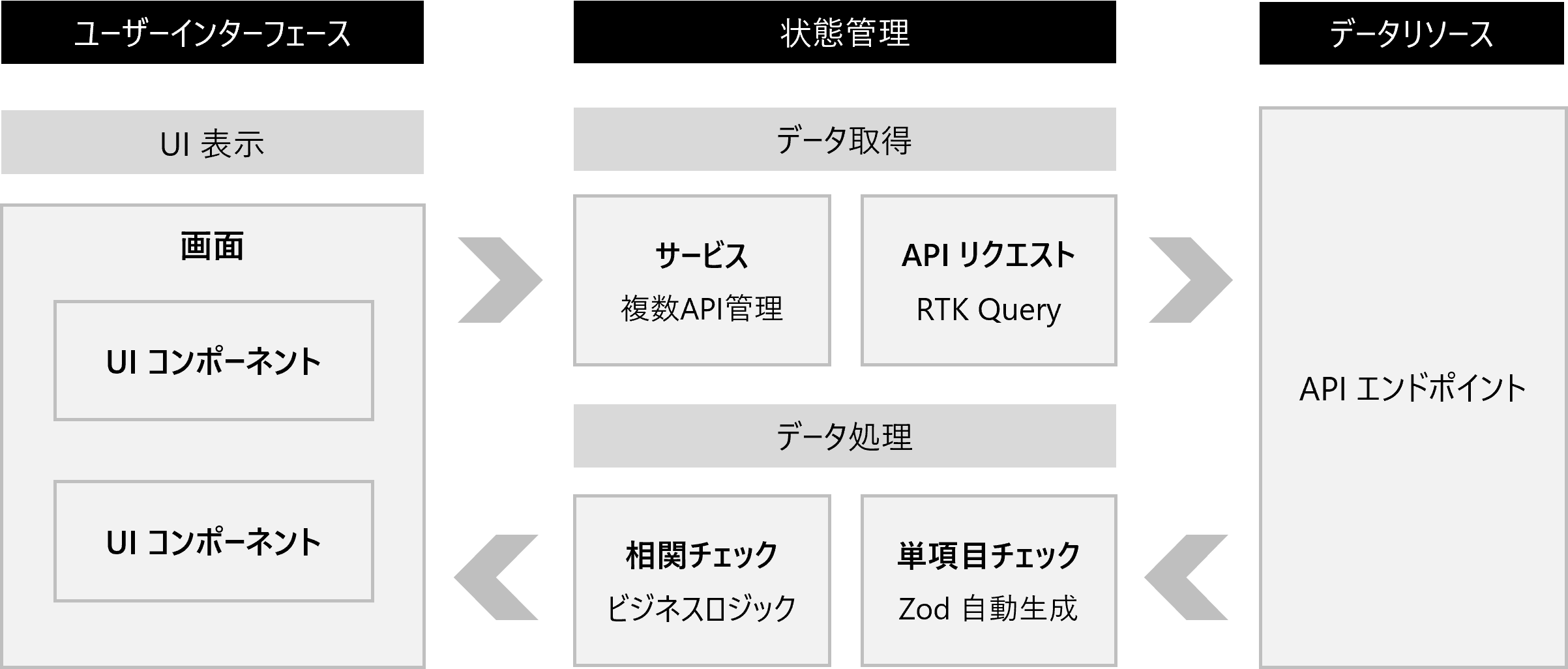
本稿では、相関チェックとはデータとデータの組み合わせで意味をなすもののデータ処理のことを指します。例えば、都道府県と市区町村のデータにおいて「東京都」と「千代田区」の組み合わせは正しいですが、「東京都」と「横浜市」の組み合わせは間違っています。私が取り組んだプロジェクトでは、このようなビジネス上の意味があるデータの組み合わせをチェックする処理を、相関チェック(サービス層・ビジネスロジック層)として定義しました。
前述までの話はあくまでAPI1本に対するデータ処理です。実際のシステム開発においては、1つの画面で複数のAPIを利用することが多いです。RTK Queryが提供してくれる機能はあくまでAPI1本に対するものであるため、複数のAPIデータを扱うための標準化を行いました。RTK Queryのクエリを束ねる関数の役割をサービス層、複数のデータの相関チェックを行う役割をビジネスロジック層と呼ぶことにします。
1画面から複数のAPIを呼び出してデータの整合性を取って表示するのは思いのほか難しいです。なぜならば、一つ一つのAPIは独立して通信をしているため、非同期の順序性や複数呼び出しているうちのいずれかのAPIでエラーが発生した場合などのケースを考慮しながら、画面の描画を考えなければいけないからです。そこで、私のプロジェクトでは「1画面⇔1サービス⇔複数のAPI」という階層構造になるように標準化しました。
サービスの中では複数のAPI、つまりRTK Queryのクエリを呼び出すことに集中し、複数のAPIから受け取ったデータをビジネスロジック層で相関チェックを行います。画面はサービスが返却したデータが整合性の取れたものであるという前提で、画面の描画に集中できるように役割を分けました。
- API呼び出しに必要なリクエストパラメータをチェックする
- データ取得(複数のAPIを呼び出す)
- API1本ずつレスポンスデータを単項目チェック
- 複数のAPIのレスポンスデータを相関チェック
- 整合性の取れたデータを画面に返却する
意識していただきたいのは引数や戻り値の標準化です。RTK Queryはdata, isSuccess, isLoading, isErrorなどの戻り値で標準化されています。これを踏襲するように実装することで、画面(ユーザーインターフェース)から見るとRTK Queryを呼び出すのかサービスを呼び出すのかは関係無く、データ処理(状態管理)は統一した実装に出来ます。
おわりに
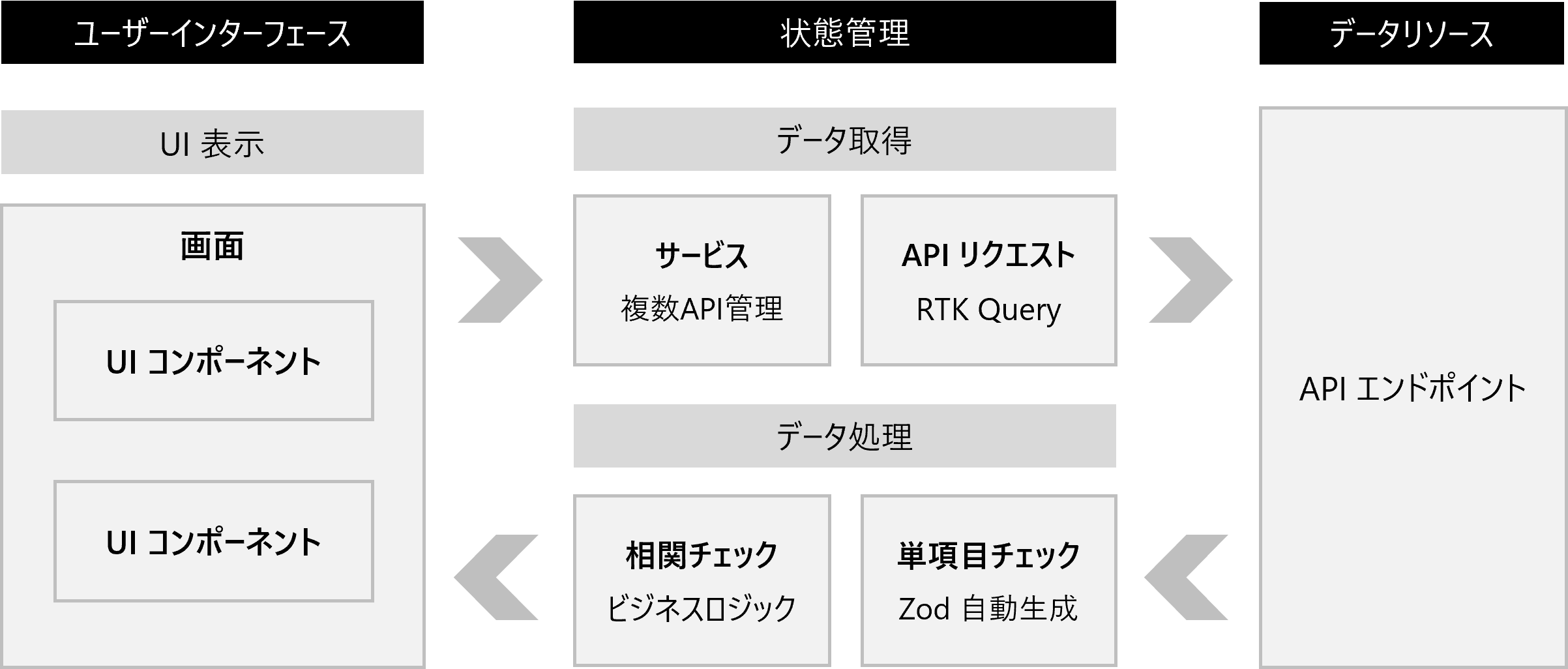
このように、ユーザーインターフェースと状態管理は役割が違います。ReactとReduxを使い、関心事を分離することで開発がしやすくなり、品質も安定します。ReactとRedux以外にも様々なオープンソースライブラリとの組み合わせがありますが、Reactはユーザーインターフェース、Reduxは状態管理という明確な役割分担があったからこそ、互いに進化してきたのだと思います。
フロントエンド開発で状態管理の標準化に悩まれている方の一助になれば幸いです。