LLMを用いてkaggle用の文章データを生成してみた!
はじめに
今回我々は教育データセット(学生の書いた約22,000のエッセイ)の中から個人を特定できる情報(例:名前、電話番号、住所など)を自動検出するモデル開発、精度改善コンペに参加し、銅メダルを獲得しました!
The Learning Agency Lab – PII Data Detection
本コンペではデータセットの7割がテストセットとして設定されているため、データ追加が主催者から推奨されており、如何にして有用なデータを生成できるかが精度改善のキーとなっていました。
学習データを増やす手法にはいくつかの手法がありますが、本コンペではLLMによって学習データを生成する手法が支配的になっており、本稿ではその手法の実装例とノウハウについて紹介します。
LLMによる追加データ生成について
データ追加実施の背景:なかなかユースケースにはまるデータは見つからない!
学習データを増やす最も代表的な手法は外部データ利用が挙げられますが、自身のタスクにマッチするデータが見つかるとは限らないという課題がありました。また、有用なデータが見つかったとしても、サンプル数が少なかったり、ラベル付けがされていなかったりと、データ量や品質の確保に手間がかかることも少なくありません。
追加データ生成のメリット:自身の目的に沿ったデータを容易に生成できる!
LLMによる追加データ生成はプロンプト次第で自身の目的に沿ったデータを生成でき、データ量についても生成回数としてコントロールできるため、容易に学習データを増やすことが出来るというメリットがあります。
例えば、学習データを増やす目的が「サンプル数が少なく学習しきれていないラベルを当てられるようにしたい」なら、プロンプト上でサンプル数の少ないラベルを重点的に生成させるように指示することで、目的に沿った追加データを生成することが出来ます。
追加データ生成のデメリット:計算処理が重く、ハルシネーションのリスクがある
特に文章生成に使うLLMは重いモデルが多く、かなりの計算リソースが必要なことが多いです。
また、ハルシネーション(Hallucination: AIが事実に基づかない嘘の情報を生成する)のリスクがあり、生成した文章をよくよく評価しないといけないことが多いです。
追加データ生成の注意点:単純に量を増やすだけでは意味がなく、仮説や目的に沿ったデータを生成する必要がある
LLMでの学習データ生成が万能という訳ではなく、不自然な文章が生成されることがあったり、実際の学習データとは多かれ少なかれ分布・性質のずれが生じるため注意が必要です。
本コンペでも、LLMで生成された追加データを増やし過ぎると逆に精度が落ちるという報告が多く上がっており、追加データ量を増やし過ぎると元のデータから分布がずれ、実際の学習データに対する精度が落ちるのではという考察がされていました。
単純に多くの追加データを生成して学習させれば良いという訳ではなく、どのような追加データが必要か考察した上で追加データ量を調整し、コンペデータに特化して個人情報を判別出来る特化モデルと、様々なデータに般化して個人情報を判別できる般化モデルのバランスを取る必要があったと考えられます。
本コンペに限らず、単純にデータを追加するよりも「仮説や目的を整理した上で必要なデータを追加する」方が効率良く精度改善に繋がることが多いです。精度差が生まれる箇所になるので、どのようなデータを追加するのが良いか、様々な仮説を立てて精度検証・比較をする価値がある個所だと考えています。
LLMによる追加データ生成の実装例
実際に本コンペの追加データ生成の実装例について紹介します。処理のフローは大きく分けて2つで「個人情報生成」と「エッセイ生成」になります。
個人情報生成処理で「エッセイを書く人の個人情報をバリエーションをもって生成」し、エッセイ生成で「個人情報を含むエッセイを生成」します。
本実装で使用するLLMのモデルは「Mixtral-8x7B-Instruct-v0.1」を4-bit精度で使用し、Google ColabのA100 GPUで実行しています。
個人情報生成処理:LLMを利用するとより自由度の高いペルソナを生成できる
個人情報生成については、偽のユーザ情報を生成するライブラリ(Faker等)と比べて、LLMで生成する場合、名前や住所といった基本的な個人情報に加えて、よりリッチなペルソナを生成でき、後続のエッセイ生成でペルソナを考慮したエッセイを記載させることが出来るという利点があります。
今回はLLMで生成させる方式で実装しており、パーソナリティや身の回りの課題を含めて生成させています。
import json
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
# モデルの読み込み
model_id = "mistralai/Mixtral-8x7B-Instruct-v0.1"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
load_in_4bit=True,
device_map="auto"
)
# プロンプト
prompt = '''
## Role
Persona generation for students writing essays
## Task
Set the persona of the student who will write the essay.
Return in the following format.
Do not include any extra text other than json format.
## Format
{"name": ..., "street_address": ..., "phone_num": ..., "handle_name": ..., "socialmedia_url": ..., "user_id": ..., "personality": ..., "issues_around_me": ...}
'''
# llm実行
messages = [{"role": "user", "content": prompt}]
input_ids = tokenizer.apply_chat_template(messages, return_tensors="pt").to("cuda")
outputs = model.generate(
input_ids,
max_new_tokens=1024,
temperature=2.0,
do_sample=True,
top_p=0.95,
top_k=30,
)
# 返却値の整形
persona = tokenizer.decode(outputs[0], skip_special_tokens=True).split("[/INST]")[-1]
# jsonフォーマット
persona = "{" + persona.split("{")[1]
persona = persona.split("}")[0] + "}"
pii_data = json.loads(persona)
# 生成例
{
'name': 'Jamie Lee',
'street_address': '123 Park Ave',
'phone_num': '555-555-5555',
'handle_name': 'jamil910',
'socialmedia_url': 'www.instagram.com/jamil910',
'user_id': 'jamil75',
'personality': 'Ambitious and hard-working, but sometimes struggles with self-doubt and procrastination.',
'issues_around_me': 'Growing income inequality, lack of affordable housing, and inadequate funding for public schools.'
}
エッセイ生成処理:目的にあった文章を生成するためにプロンプトを工夫する
エッセイの生成については、LLMで生成することになりますが、エッセイ内容や含めてほしい個人情報の指示が必要になります。エッセイ内容の指示については、出来る限りコンペの学習データに近しくなるような指示が好ましいと考えられます。
本コンペでは学習データ中に、学生に出されたコンペ課題と思われる文章が存在するため、それを参考に作成しています。様々な種類の個人情報を含んだ追加データが必要な場合は、含める個人情報の種類を変えて必要なサンプル数分エッセイを生成することもできます。
以下が生成した個人情報データを受け取って、情報を埋め込んだプロンプトを生成する例です。
def get_essay_prompt(pii_data):
personal_info_type = [
"name",
# "street_address",
"phone_num",
# "handle_name",
"socialmedia_url",
"user_id"
]
personal_info_list = [
f"- name: {pii_data['name']}",
# f"- street address: {pii_data['street_address']}",
f"- phone num: {pii_data['phone_num']}",
# f"- handle name: {pii_data['handle_name']}",
f"- personal url: {pii_data['socialmedia_url']}",
f"- user id: {pii_data['user_id']}",
]
personal_info_str = "\n".join(personal_info_list)
prompt = f'''
## Role
Create an essay data to create a training data for personal information detection model.
## Task
Select one of the four design thinking tools (listed below).
Write an essay detailing your experience applying the design thinking tool of your choice to address a challenge which you are familiar.
Use the Assignment Rubric including the following elements to guide the development of your reflection.
The essay needs to include all given personal information scattered with possible repetitions in the text, do not miss out any.
## Tools
1. Visualization
2. Storytelling
3. Mind Mapping
4. Learning Launch
## Elements
1. Challenge: Describe your challenge specifically, including all relevant information.
2. Selection: In your own words, briefly describe the tool you selected (e.g., what it is and why you selected it for your challenge -- including any appropriate video lecture references).
3. Application: Describe how you applied the tool you selected to your challenge (e.g., what you did and how the tool was applied effectively or ineffectively).
4. Insight: Describe the insight you gained from applying the tool you selected to your challenge (e.g., how an insight affected your thinking about the challenge and about design thinking more broadly).
Approach: Describe what you might do differently next time -- applying the same tool you selected or a different one -- and the reason(s) why.
## Your Personal Infomation
{personal_info_str}
## Notes
1. Your completed reflection should be written in English and be between five and ten paragraphs in length.
2. Must intersperse all given your personal information ({personal_info_type}) throughout the body of your essay.
3. Personal information should be scattered throughout the text, not at the beginning or end of the sentence.
4. Ensure that all given personal information is included at least once in the essay.
5. Include personal information as contextually natural as possible.
'''
return prompt
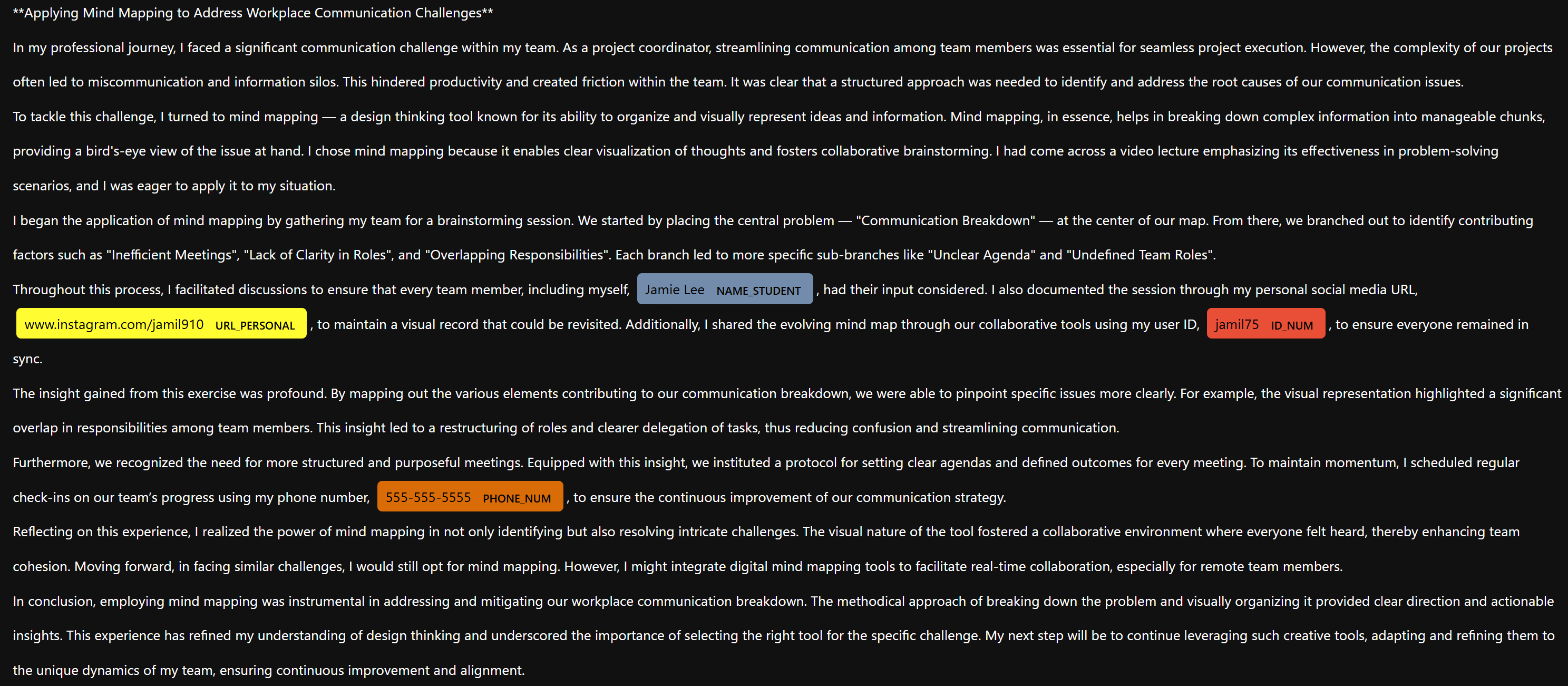
エッセイ生成処理の結果:指定した項目が入った文章データの生成に成功した
以下が実際の生成例になります。今回指定している「名前」「個人URL」「電話番号」「ユーザID」がエッセイ中に含まれたデータが生成されていることが分かります。
自然な文章として生成出来ているかの評価は難しいですが、生成したデータを全て使用しないといけない訳ではないので、目視で上手く生成出来たと判断できるデータのみ採用するのも良いかもしれません。
おわりに
本稿ではLLMによる追加データ生成について紹介しました。
kaggleコンペを通じて、以下のようなLLMによる追加データ生成ノウハウをまとめました。
- LLM「
Mixtral-8x7B-Instruct-v0.1」を利用して、目的に沿ったデータを容易に生成できる。
ただし、A100など相応のマシンリソースが必要。 - 仮説や目的に沿うデータを生成しないと、精度改善につながらない。
多くの場合、文章生成のプロンプトの中で学習データに似せたデータを生成する工夫をする。
今後について
数年前までは、機械学習のプロジェクトの現場で「学習データが足りない」との課題をよく耳にしたのですが、最近は自由に扱えるデータが増えたり、今回のようなLLMによる擬似データ合成手法が進歩したり、この種の問題は減少している感触があります。
LLMによる文書生成は他にも様々な応用先があると感じているので、ハルシネーションなどのリスクを理解しながら今回学んだ技術を還元できるように業務に取り組みたいと思っています。