Amazon CloudWatch Application SignalsでのSLOモニタリングを試す
こんにちは、NRIデジタルの島です。
昨年開催された『AWS re:Invent 2023』にて、オブザーバビリティ(可観測性)のカテゴリの新機能として「Amazon CloudWatch Application Signals」が発表されました。
Amazon CloudWatch Application Signals (プレビュー版) でアプリケーションをモニタリング
執筆時点ではまだプレビュー版となりますが、今後のクラウドベースのモニタリングにおいて、注目される機能になってくると思いますので、軽く触っていきたいと思います。
Application Signalsとは
概要
Application Signals(以下App Signals)とは、「AWSで稼働するアプリケーションを、面倒な設定作業などをすることなく、自動的に現在のアプリケーションの状態をモニタリングし、最も重要なビジネス目標に照らしてアプリケーションのパフォーマンスを追跡できる新しい機能」です。
公式のユーザガイドなどに細かく書かれていますが、筆者の解釈における本機能のポイントは以下となります。
- カスタムコードやダッシュボードの作成なしで、稼働中のアプリケーションから主要なメトリクスやトレース情報を自動的に収集し、計測することが可能(OpenTelemetryによる自動計装)
- SLI(サービスレベル指標)及びSLO(サービスレベル目標)を定義することができ、ビジネス視点でのアプリケーションのパフォーマンスを可視化可能
- モニタリング対象のアプリケーションのトポロジーと依存関係を可視化可能
- 既存の以下オブザーバビリティ関連サービスと連携可能(※)
Amazon CloudWatch Synthetics Canary
Amazon CloudWatch Evidently
Amazon CloudWatch RUM
以下のように、AWSコンソール上でも、App Signalsカテゴリの中にそれらのサービスが取り込まれているようです。
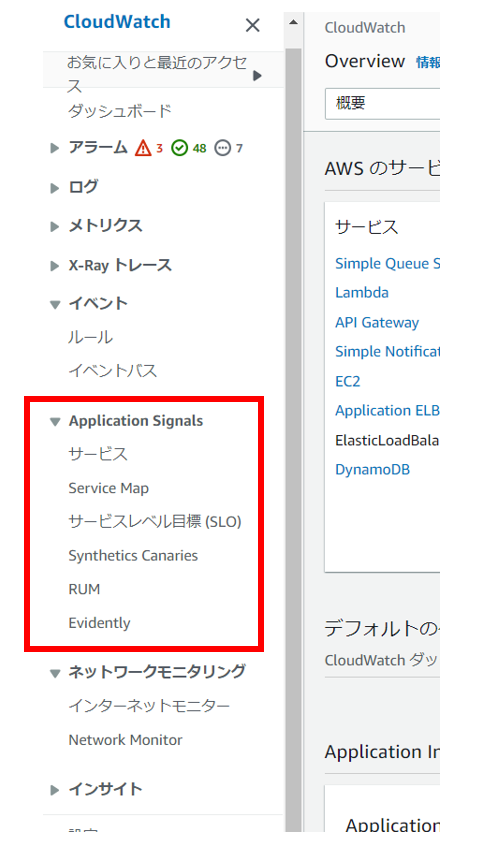
本機能の売りはなんといっても、「SLOを定義、リアルタイムにモニタリングすることで、ビジネス目標に照らしてアプリケーションのパフォーマンスを追跡できる」ことだと筆者は考えています。本記事では以下ワークショップを実行しながら、SLOモニタリング機能を中心に試してみようと思います。
Workshop Studio
なお、前述した通り、執筆時点ではまだプレビュー版であり、利用にあたりまだいろいろと制約がありますのでここに記載しておきます。
対象リソース
対象言語
執筆時点ではJava(8/11/17 LTS)で稼働するアプリケーションのみサポートされています。ただApp SignalsのベースとなるOpenTelemetryはPythonやNode.jsなどもサポートしてますし、SDK自体はそれらの言語でも既に提供されている為、今後Java以外の言語も対象になると思います。
対象サービス
執筆時点では以下サービス上で稼働するアプリケーションが対象となります。
- Amazon EKS
- Amazon ECS
- Amazon EC2
Amazon EKS(以下EKS)のみクラスタのアドオンを入れるだけで自動連携可能ですが、Amazon ECS及びEC2は個別にエージェント(CloudWatch AgentやX-Rayデーモンなど)の導入が必要ですので注意してください。前述した「面倒な設定作業などをすることなく…」に矛盾はしますが、現時点では導入が必要になりますのでご認識いただければと思います。
対象リージョン
執筆時点では東京リージョンを含む以下6リージョンで使用可能となっています。
- US East(N. Virginia)
- US East(Ohio)
- US West(Oregon)
- Asia Pacific(Sydney)
- Asia Pacific(Tokyo)
- Europe(Ireland)
SLOモニタリングを試す
環境構築
では、環境を構築していこうかと思います。環境構築ですが、基本的に以下ワークショップのページの手順通り進めていけば問題ありません。
Workshop Studio
※開発環境などは自身の環境にあわせて読み替えてください
手順実行後、作成される環境は以下のようにEKSベースとなります。
※上記チュートリアルページより引用
Pet Clinic Overview
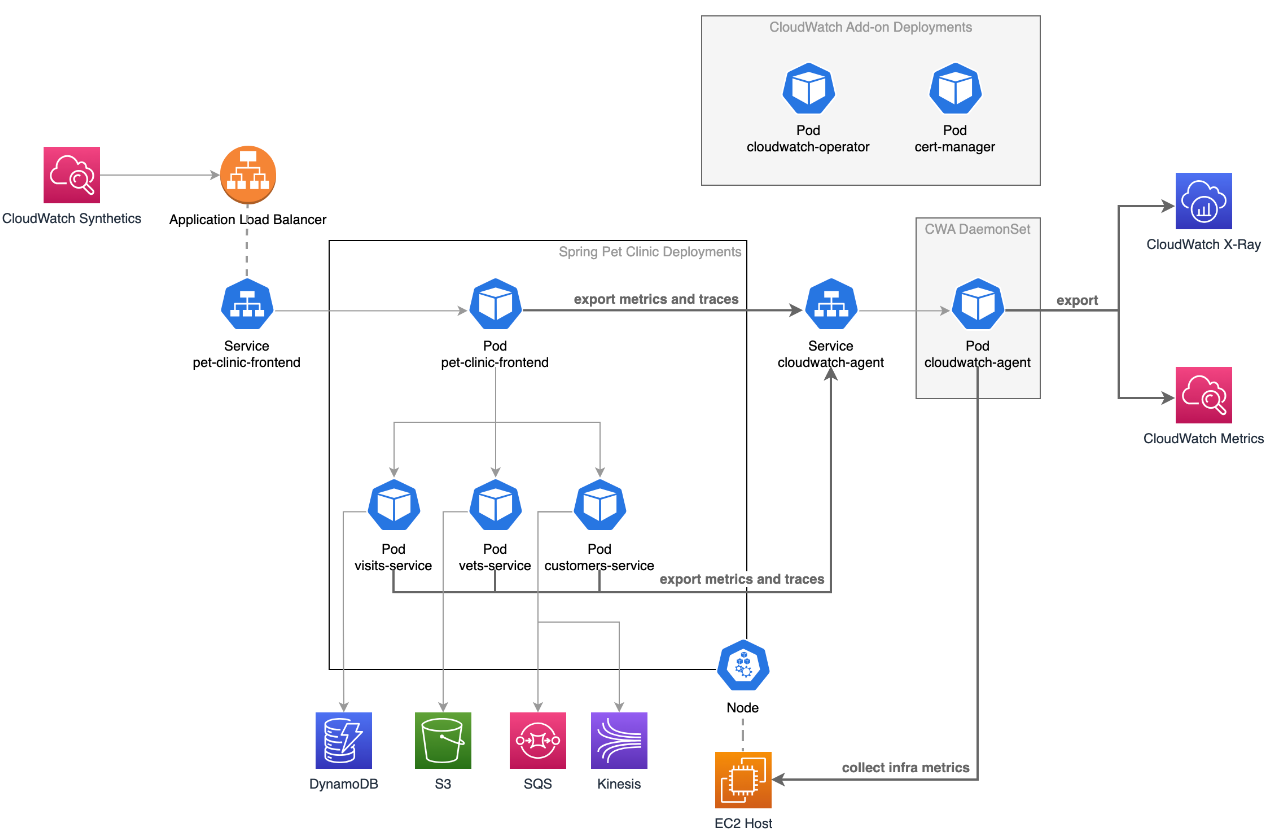
構築されたEKSクラスタのPodを参照すると、概ね上記構成図通りのアプリケーションやエージェントなどがデプロイされていました。
アプリケーションのユースケースは「ペットクリニックのサイト」のようで、以下Ingressリソースのアドレスにアクセスすると画面が表示されました。
※構成図上の「Application Load Balancer」がその実態となります
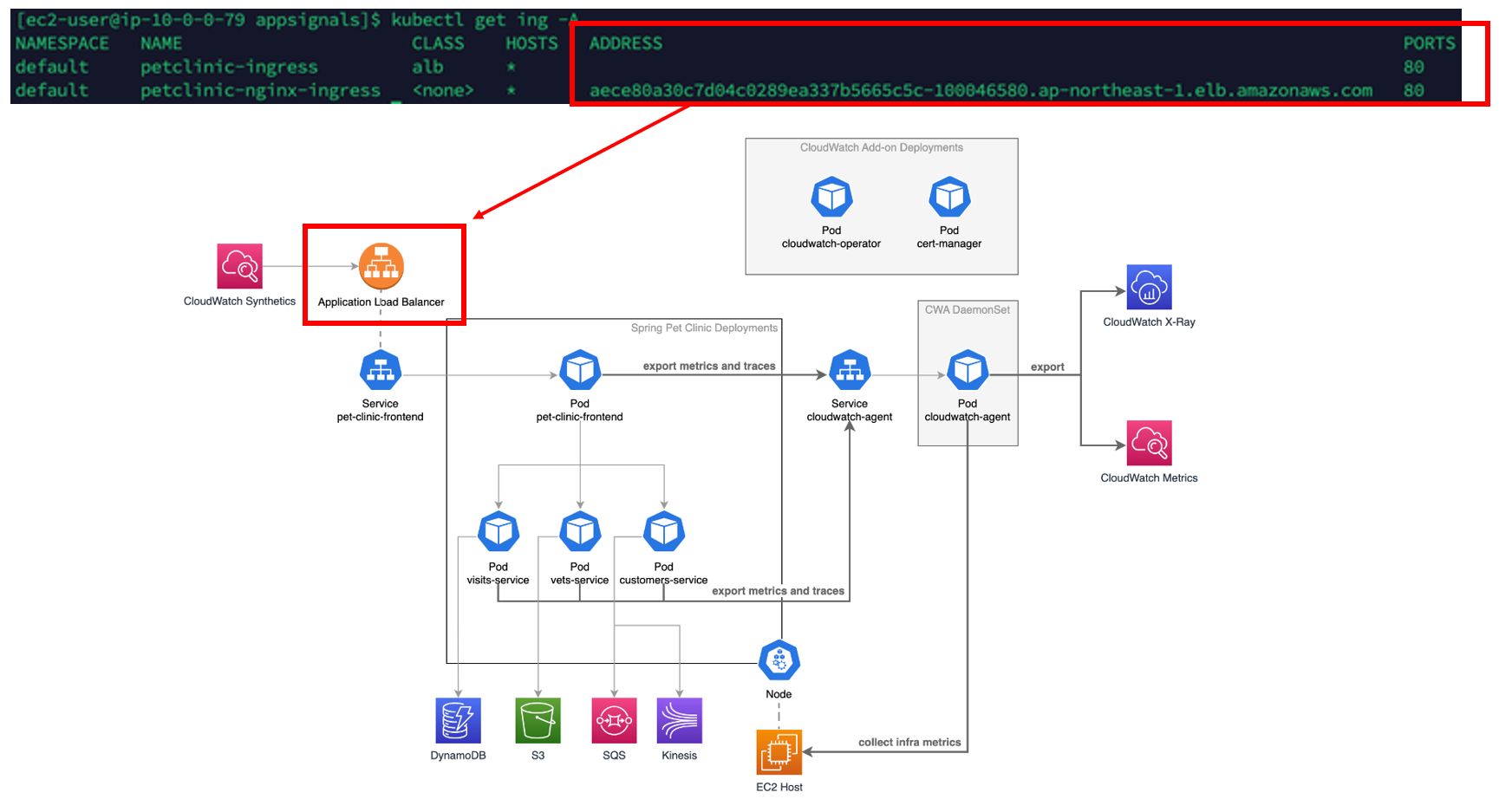
また、「Amazon CloudWatch Synthetics(以下Synthetics)」も作成され、デプロイされたアプリケーションに対して定期的に稼働チェックが実施されています。
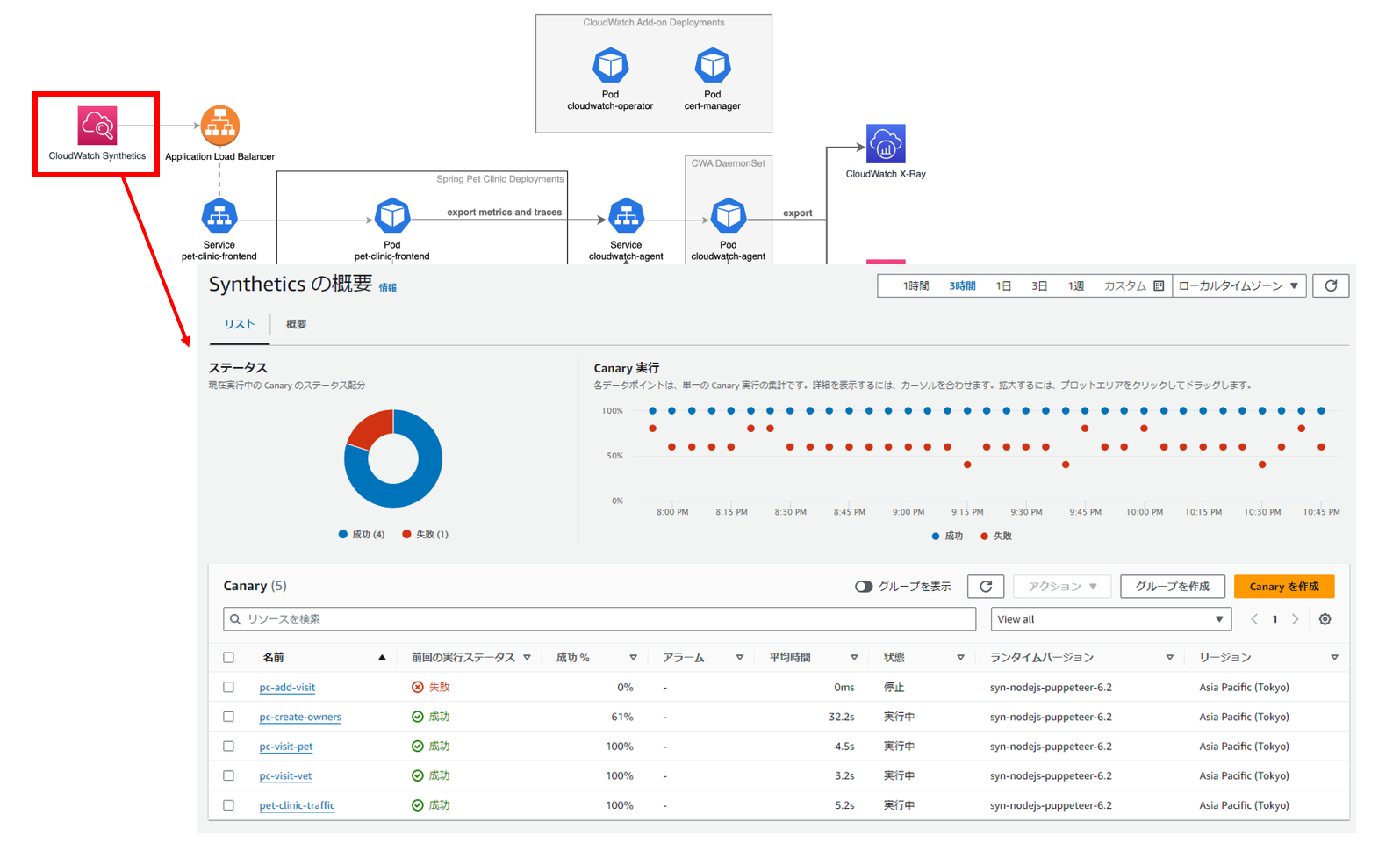
構築が完了して、少し待つと各画面で情報が確認できるようになります。
左メニューから「サービス」を選択すると、監視対象のサービスとそのエラー率などの情報が参照できます。
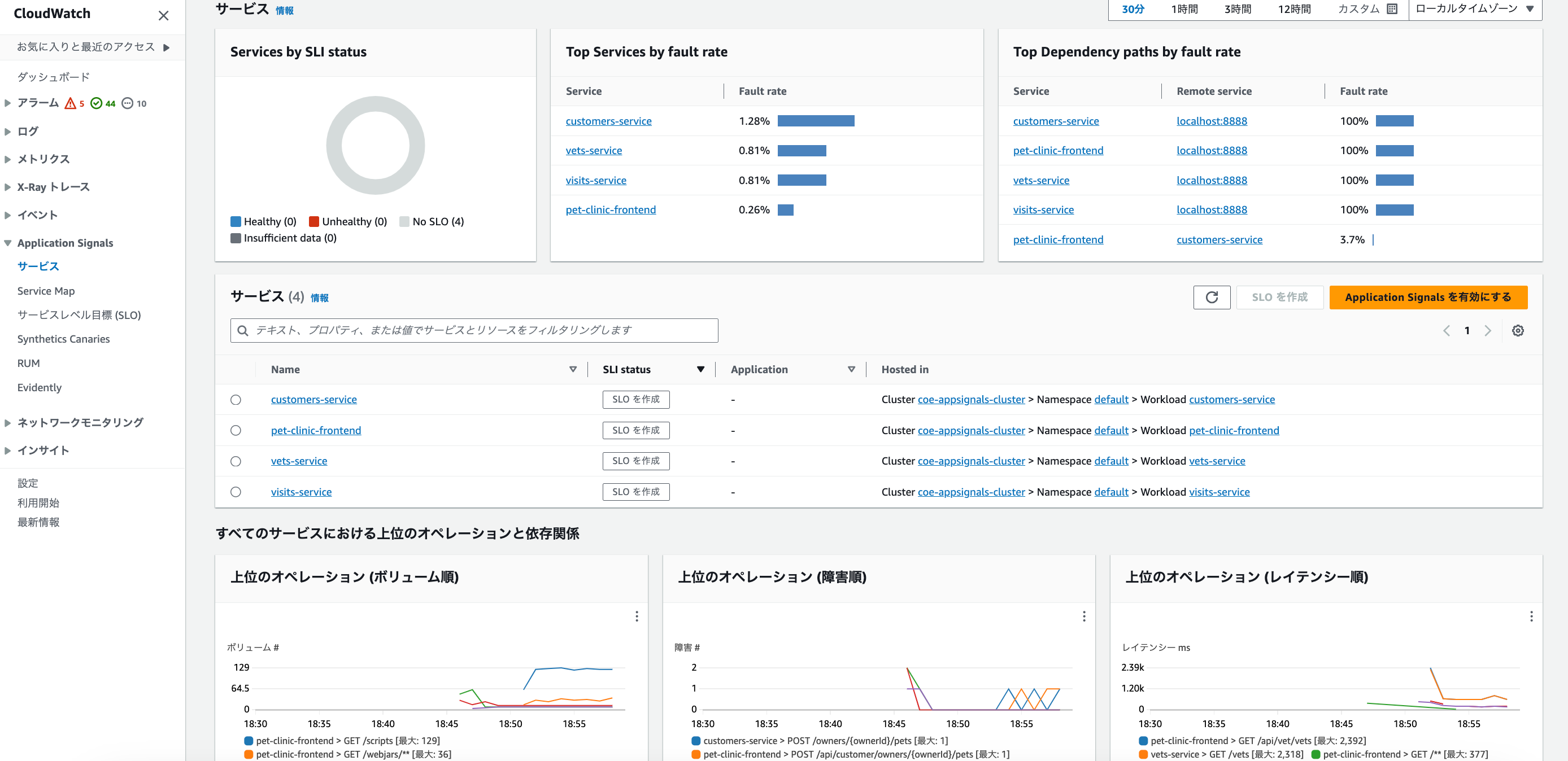
各サービスをクリックすると詳細画面に遷移することができ、ここで各種メトリクスや依存サービスなどを確認することができます。
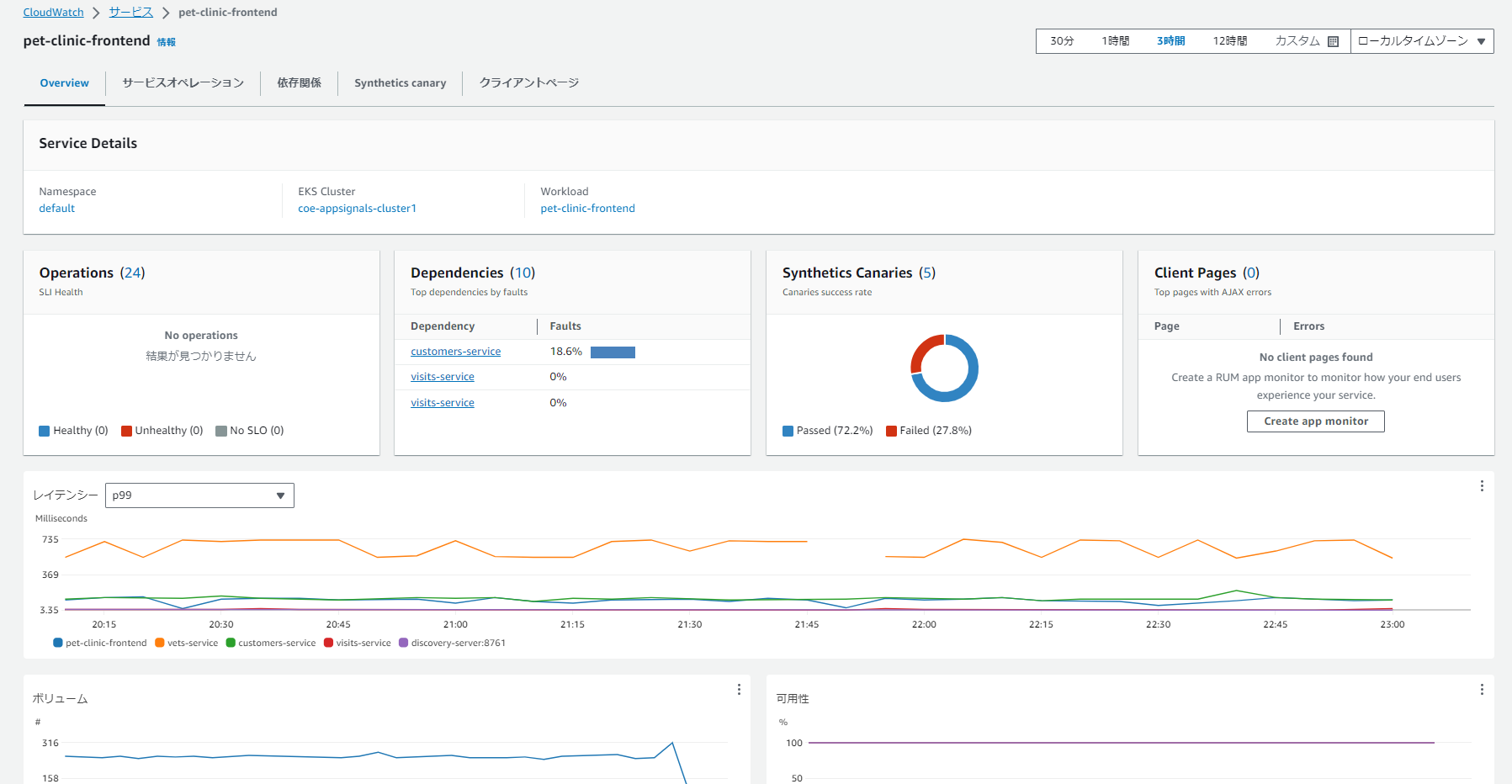
「サービスオペレーション」タブからは各オペレーションごとの情報が参照でき、グラフをクリックすると関連するトレース情報が参照できます。
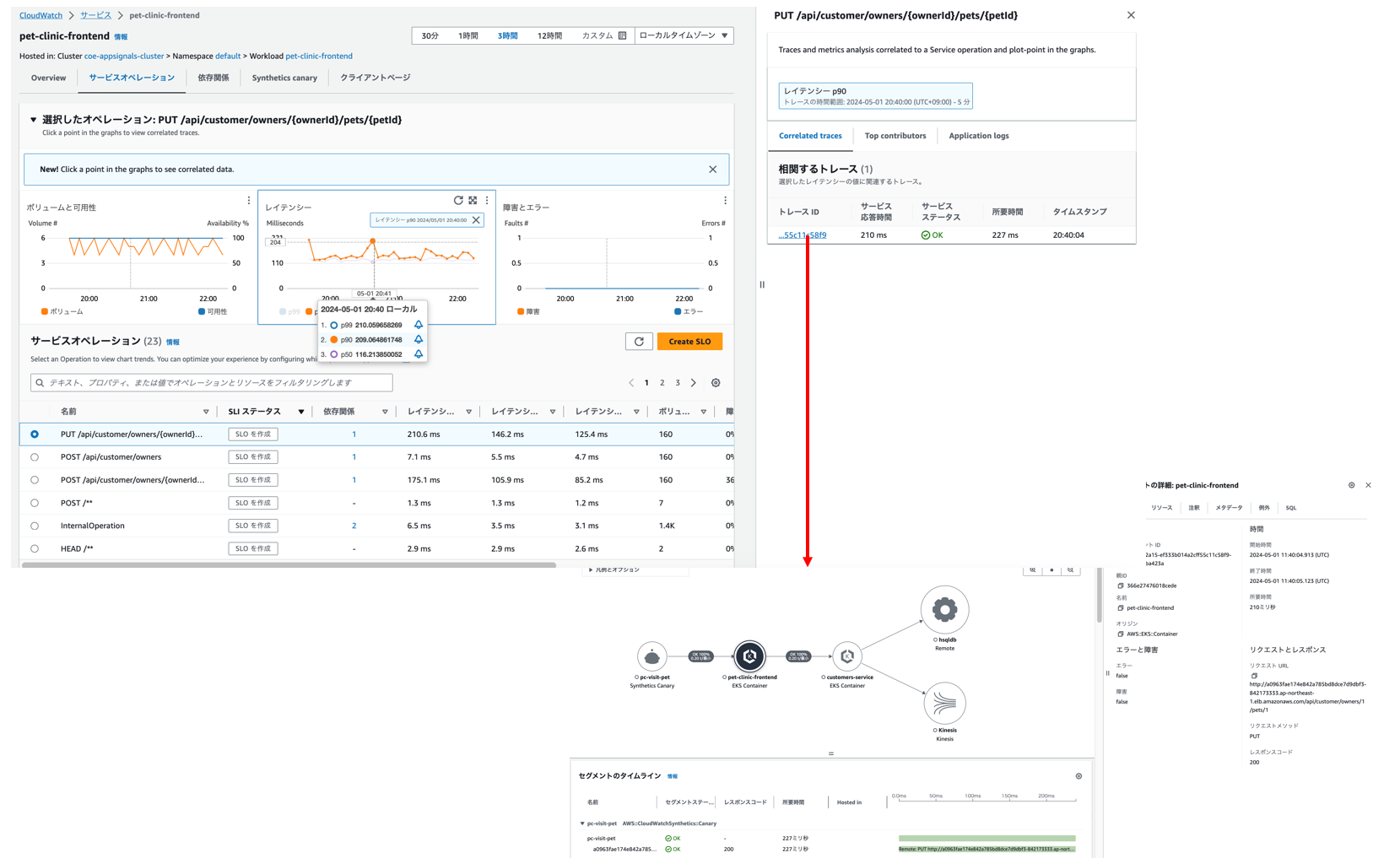
SLOの設定
各種情報が参照できることが確認できましたので、SLOを作成していきます。実際のワークショップの流れでは、SLO作成もスクリプトで一括で作成することになりますが、今回は手動で作成していこうと思います。今回は「customers_service」サービスに対してSLOを設定していきます。
SLOは、自動的に収集される各サービスオペレーションの主要なメトリクス(レイテンシーや可用性など)をもとに以下のような観点で設定していくことができます。
SLI(サービスレベル指標)
各メトリクスに対するしきい値を指定(e.g. レイテンシー「200ms」以下)達成度目標
指定したSLIのしきい値を満たすことが求められる期間や達成度(パーセンテージ)を指定
(e.g. 目標「1分 99%」で「1日」間隔で指定→「1分間でのSLI達成率が99%以上」を毎日達成しているかを評価)詳細は公式ドキュメントにて解説されていますのでご参照ください。
SLO concepts※SLI(サービスレベル指標)やSLO(サービスレベル目標)自体の説明は割愛しますが、以下ワークショップのページにも記載されていますので、こちらもあわせてご参照いただければと思います。
Workshop Studio
SLOの作成は「サービス」「Service Map」「サービスレベル目標(SLO)」それぞれの画面から実施可能です。以下のように、SLIの定義、SLOの定義、その他設定と進んでいきます。
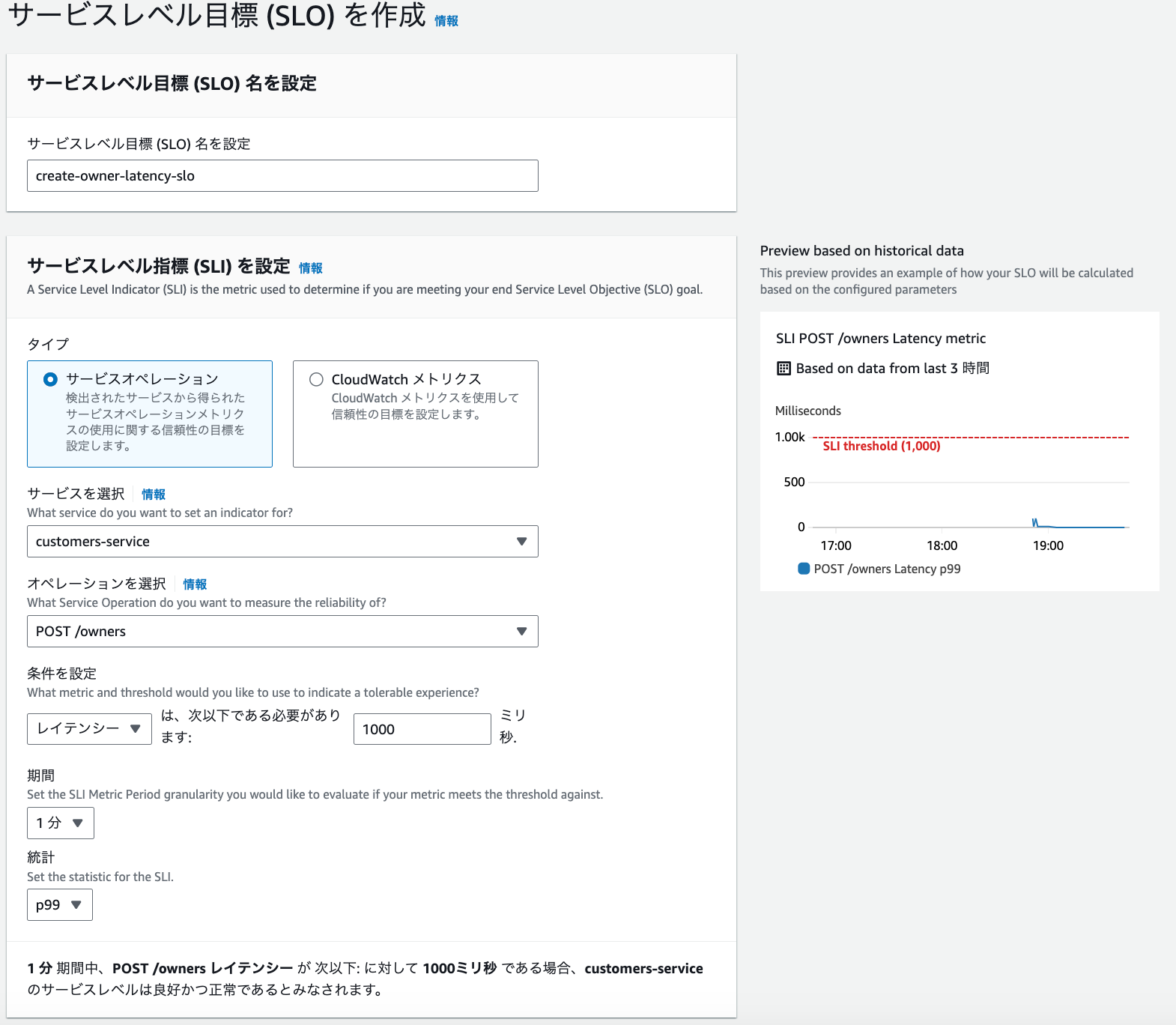
① SLIの定義
SLIを「/ownersエンドポイントに対するPOSTリクエスト」に対して「1分間の99パーセンタイルのレイテンシが1000ms以下」で設定
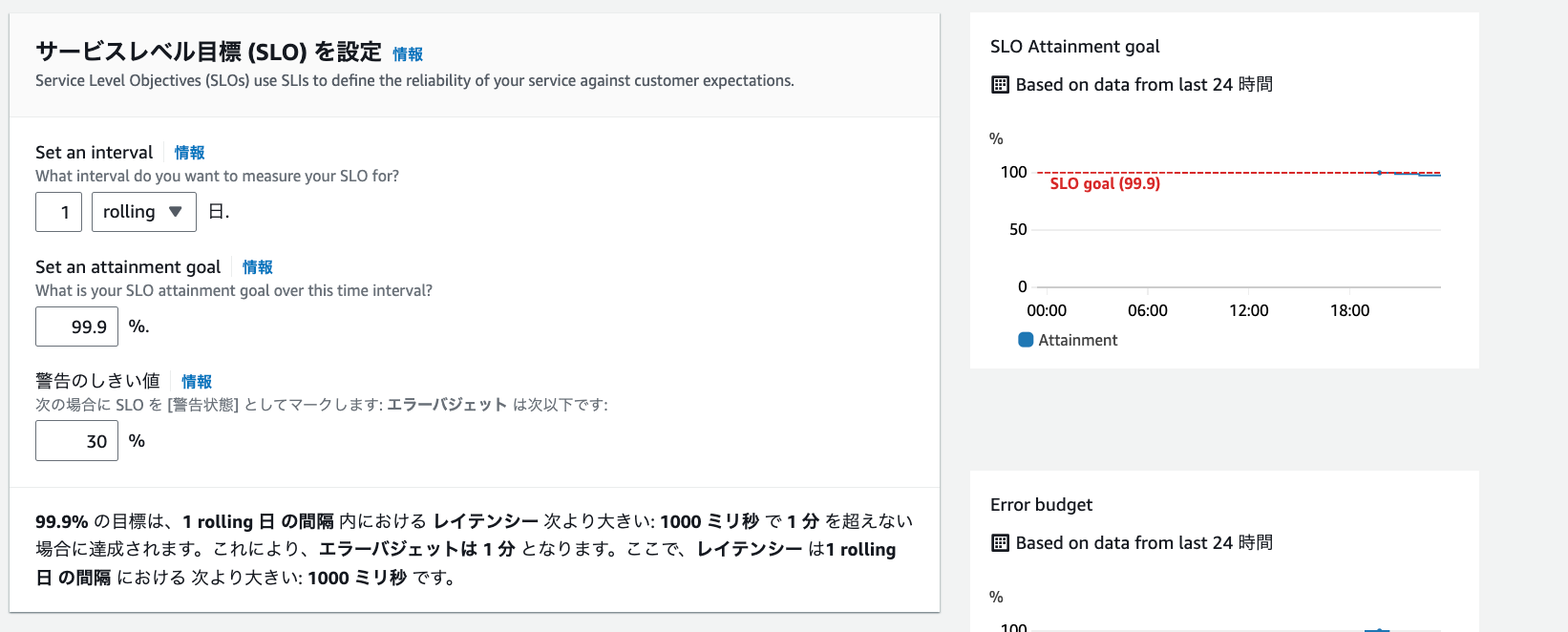
② SLOの定義
SLOをインターバル「1日」、達成度「99.9%」で設定
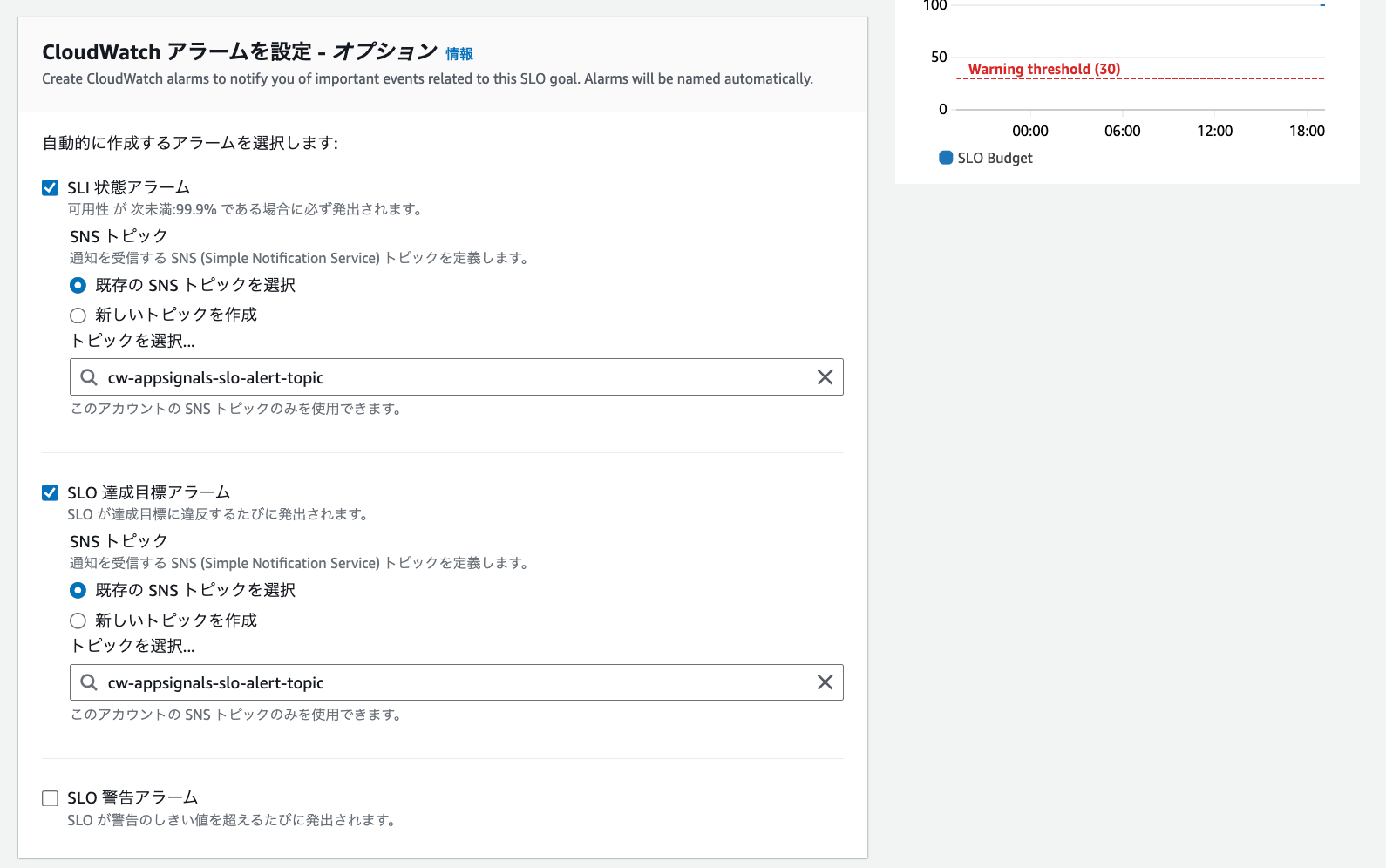
③ その他設定
各種アラームに通知先などを設定
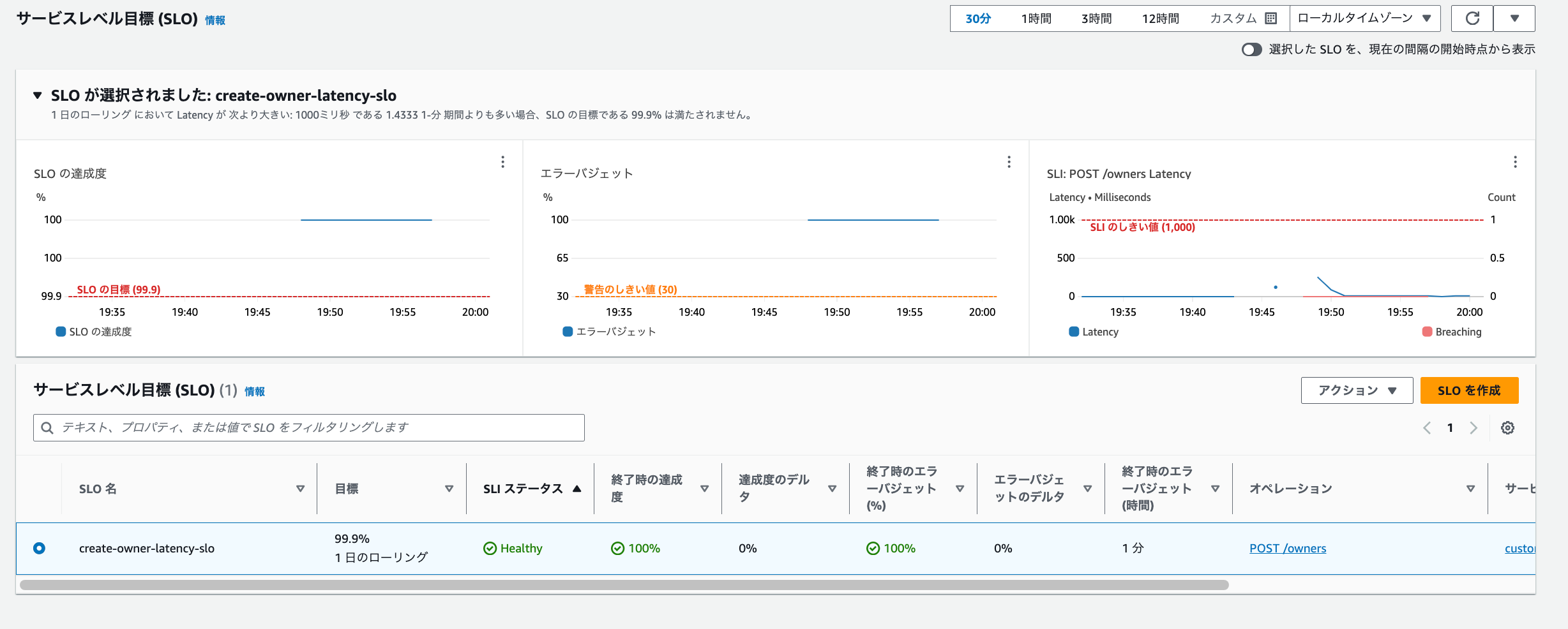
設定してしばらくすると、実ワークロードのメトリクスによりSLOが評価されます。以下の通り「SLI ステータス」も「healthy」であり、特に問題なく稼働している状態となっています。
実際に送信されるメトリクスは以下に記載されています。
Workshop Studio
ここで、SLO評価対象の「customers_service」サービスの該当コードを変更し、一定の確率でレイテンシを悪化させるようにしてみます。
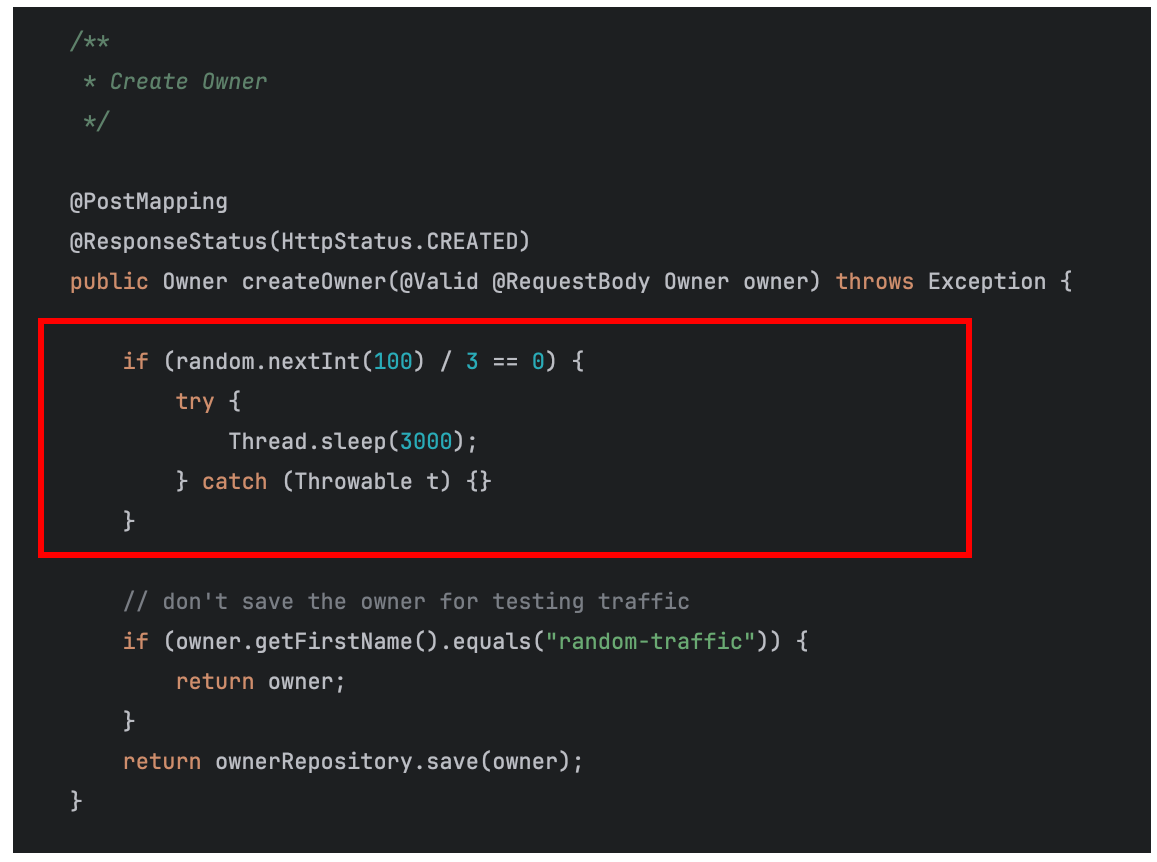
ワークショップで使用されているアプリケーションのコードは以下Githubリポジトリです。
GitHub – aws-observability/application-signals-demo
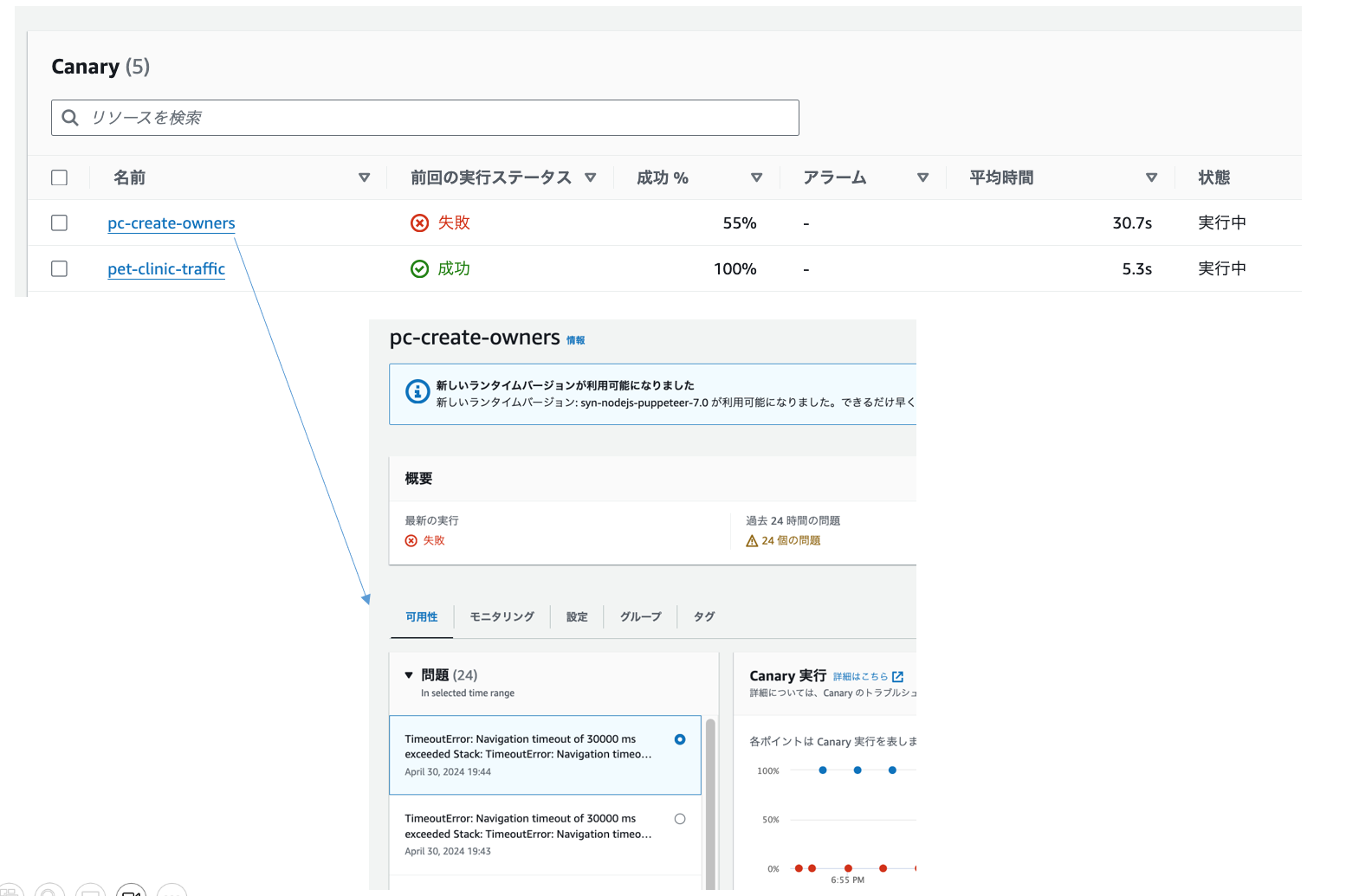
しばらくすると、先に設定したアラートが通知され、Synthetics Canaryによる稼働チェックも失敗し始めました。
※以下「pc-create-owners」が「/owners」エンドポイントへのPOSTリクエストです
サービスマップ上で「cusotmer_service」に異常が発生していることがわかります。
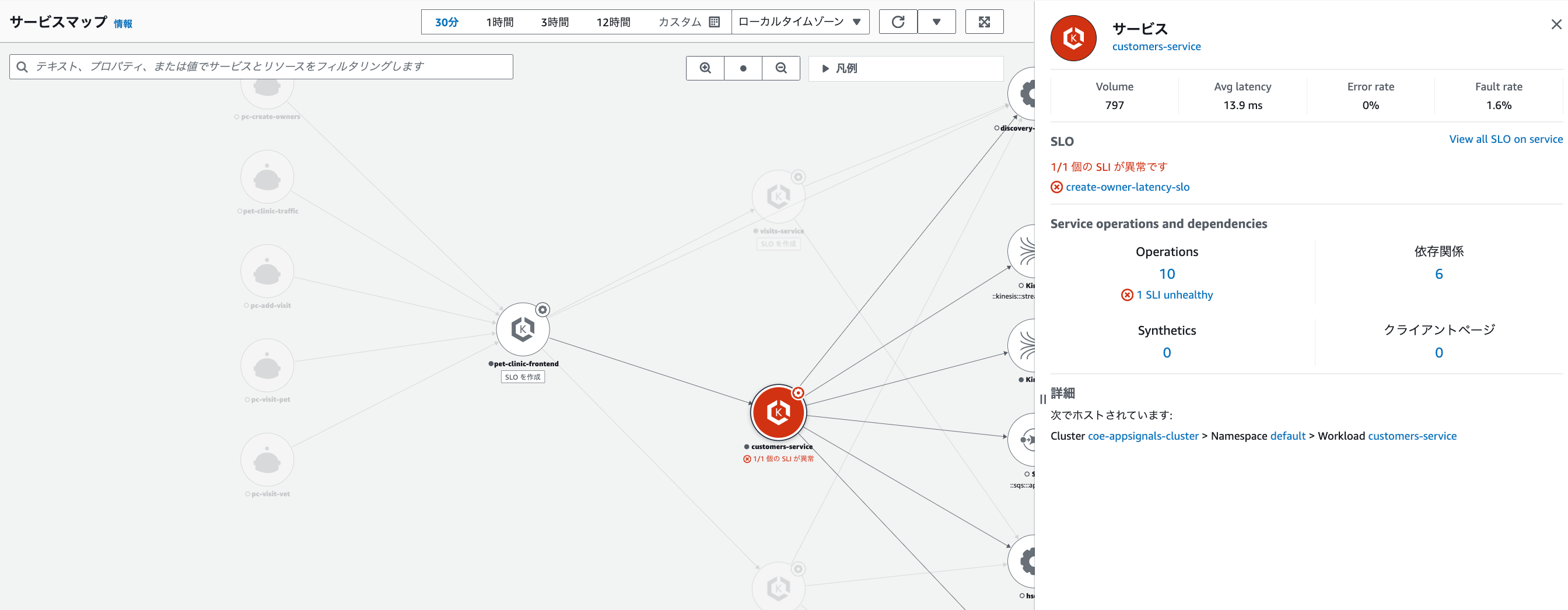
SLO画面上も以下のように「unhealthy」となり、異常な状態になりました。
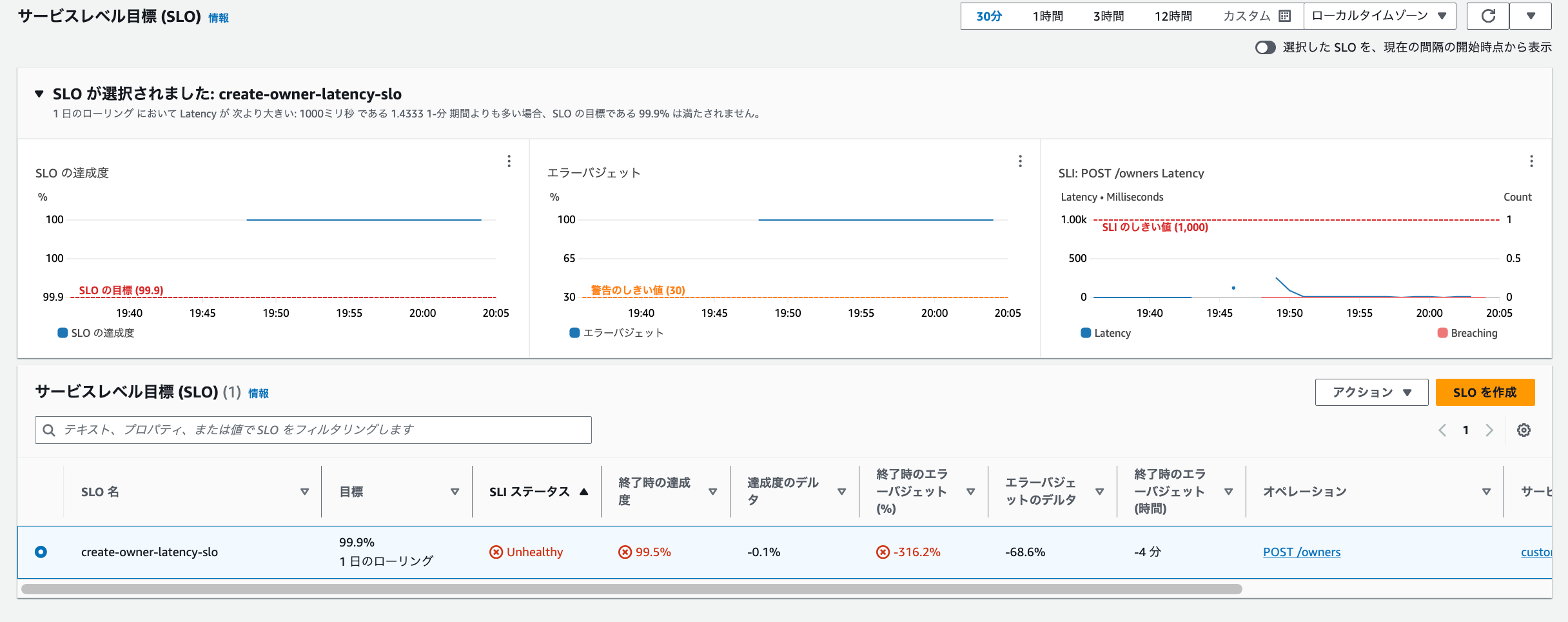
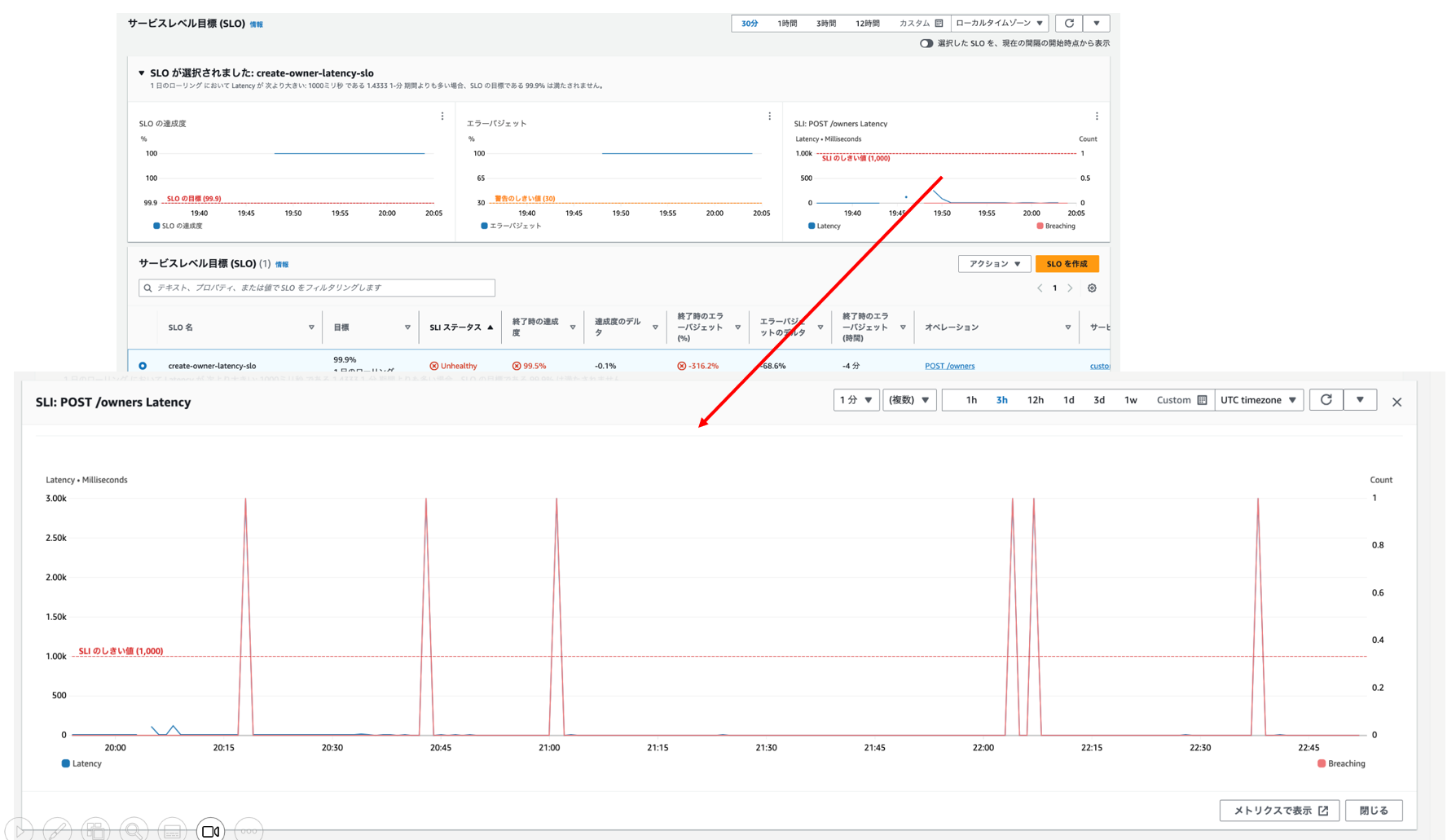
SLOでの指標となる「レイテンシ」は閾値(1000ms)を何度か超過しています。
レイテンシ
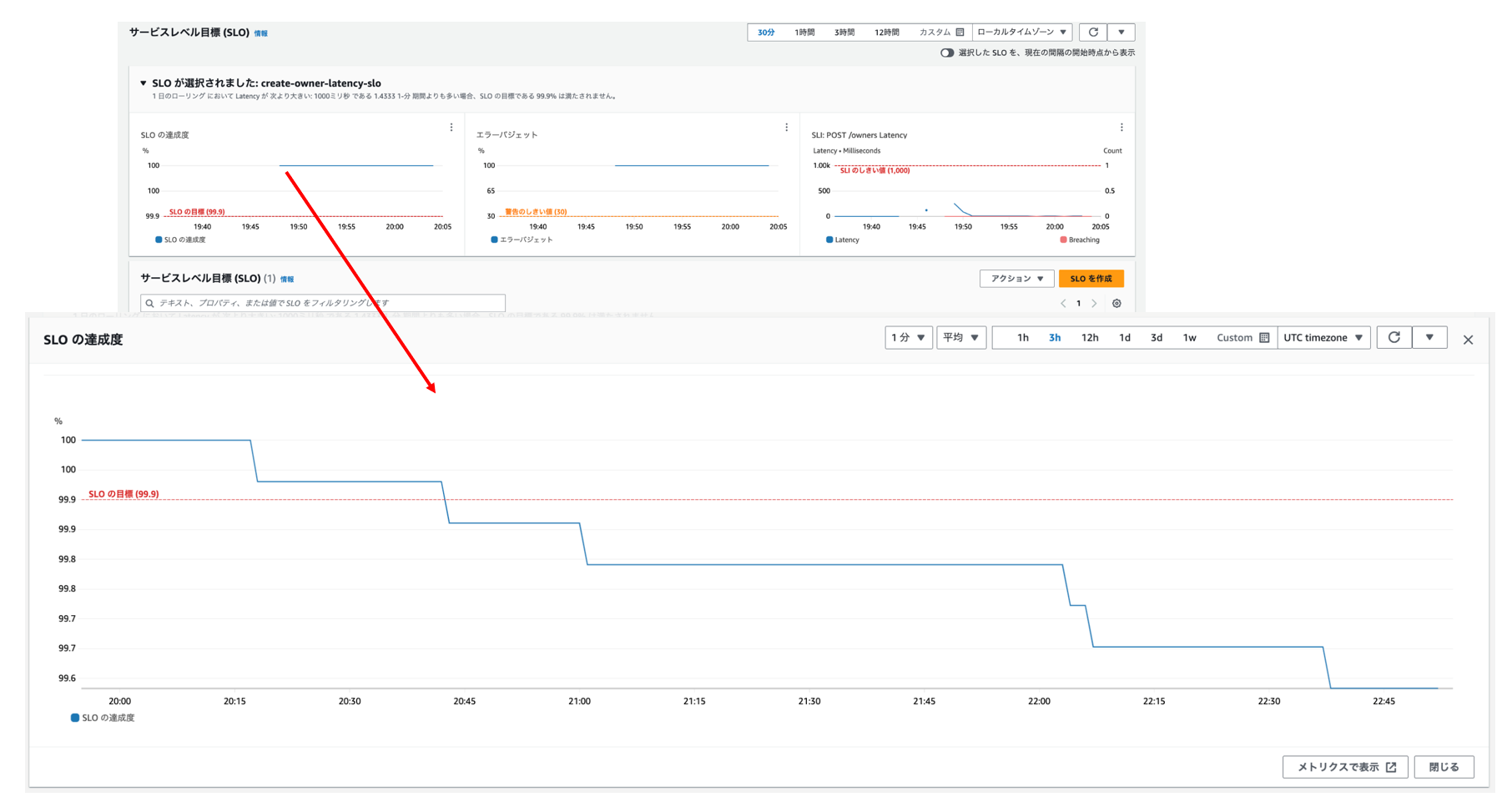
「SLO達成度」や「エラーバジェット」を参照すると以下の通り低下しています。
SLO達成度
エラーバジェット
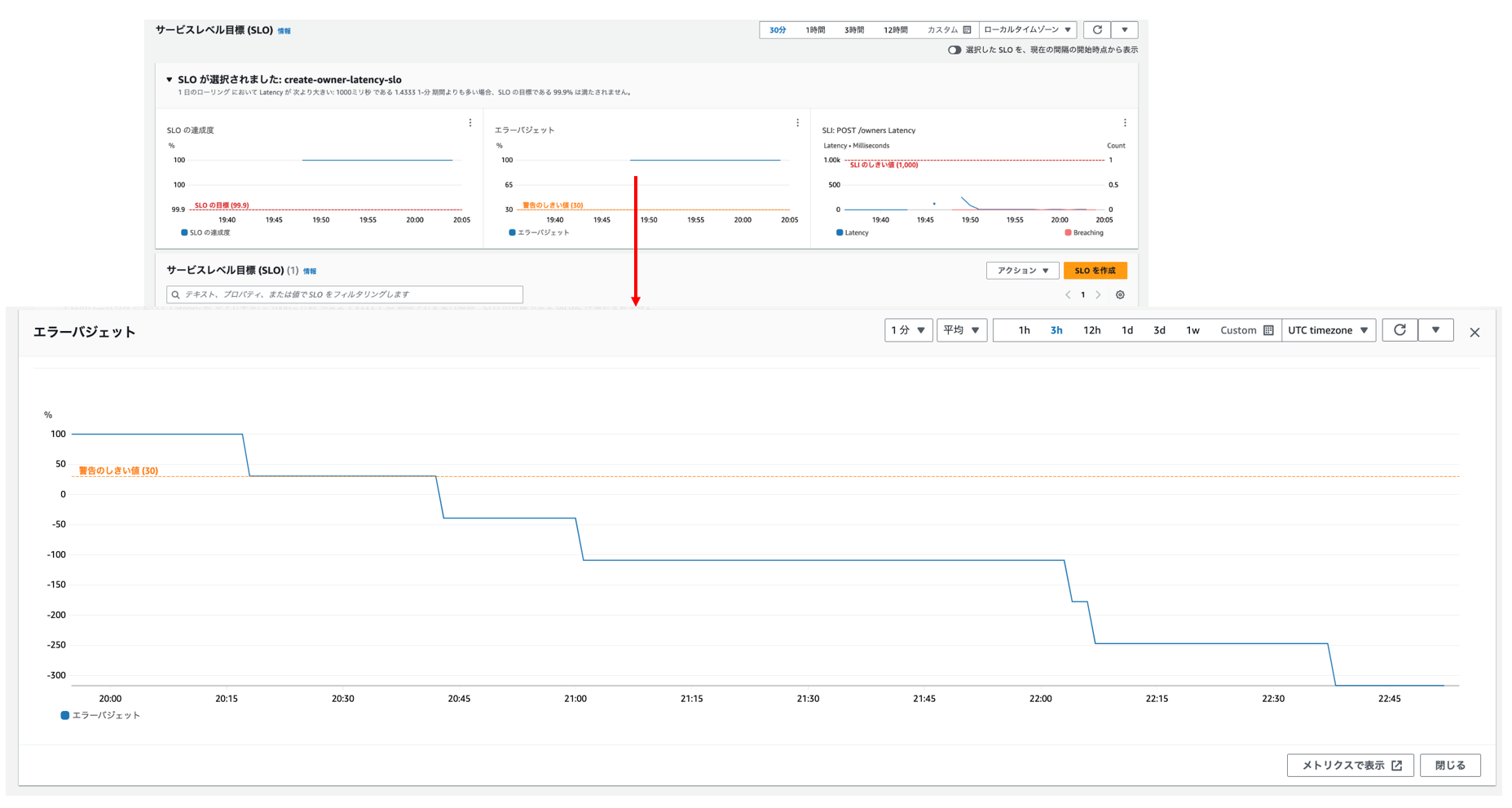
エラーバジェットとは、システムの利用ユーザーが許容できる累積エラー量です。このエラーバジェットを超えるエラーが発生した場合、利用ユーザは該当システムの対して不満を感じるようになります。主に可用性やレイテンシなどのディメンションで評価されます。
App Signalsにおける「エラーバジェット」や先の「SLO達成度」の計算については、以下公式ページに説明がありますのでご確認ください。
サービスレベル目標 (SLO)
異常な状態に陥ることで、「SLO達成度」や「エラーバジェット」が低下していくことを確認することができました。
App Signalsを試してみて
以上、簡単なユースケースで確認しましたが、数個の設定のみでSLOを簡単にモニタリングできることが確認できました。機能的には単純なものに見えますが、もし、App Signalsがない場合、既存のCloudWatchのダッシュボードでこのような仕組みを自作しなければなりません。必要なメトリクスの送受信、エラーバジェットの計算、ダッシュボードのUIなどなど、相当な専門家がいないと実現は難しいように思います。
App Signalsを利用すれば、事前に必要なセットが揃っていますので、時間や手間をあまりかけずに実現が可能となります。
ただ、異常検知後の切り分けや原因特定までを考えた場合、被疑箇所を如何に迅速に特定するかが重要になってくるように思います。AWSには「Amazon CodeGuru Profiler(以下 Guru Profiler)」というサービスがあり、過日検証記事も執筆していますが、こちらのサービスを使用すると、JVMのプロファイリングが可能です。
App SignalsとGuru Profilerを連携させ、異常発生の検知のみならず、被疑箇所へリンクし、JVMプロセスの中身まで追えたりできるような仕組みができれば、更に有用なサービスになるように思います。
まだGA前のサービスでもありますので、今後の拡張に期待していきたいと思います。