大規模言語モデルを活用したリコメンデーションシステムの最新動向:
『A Survey on Large Language Models for Recommendation』の紹介
こんにちは、NRIデジタルの侯です。
NRIデジタルのAIビジネスイノベーションチームでは、定期的に論文読み会を開催しています。
今回は『A Survey on Large Language Models for Recommendation』という論文についてご紹介します。この論文では、大規模言語モデルをリコメンドシステムに適用する方法やその適用状況について解説されています。
概要
リコメンドシステムは、ユーザの好みや行動履歴に基づき、商品やサービスを自動リコメンドするシステムです。最近の研究では、大規模言語モデル(LLM)の利用により、リコメンドシステムが強化されています。LLMは、大量のデータを使った自己/半教師あり学習で訓練され、複雑なテキスト特徴の抽出や外部知識の活用が可能です。LLMベースのリコメンドシステムは、コンテキスト理解能力が高く、データが少ない場合でも有効なリコメンドを提供でき、リコメンド結果の解釈可能性が向上できるなどの特徴があります。
モデリングパラダイムと分類
識別的LLM(Discriminative LLMs)と生成的LLM(Generative LLMs)
LLM(大規模言語モデル)には、識別的LLMと生成的LLMの二種類があります。
識別的LLM(Discriminative LLMs)は、入力データから特定の出力を予測することに特化しています。例えば、テキストからカテゴリーを分類するタスクなどが該当します。識別的LLMは自然言語の理解に優れ、入力データの意味や関連性を分析して適切な出力を提供します。代表的なモデルとして、BERTとその派生モデルが挙げられます。
生成的LLM(Generative LLMs)は、与えられた入力やコンテキストから新しいコンテンツやテキストを生成する能力に焦点を当てています。例えば、翻訳や要約、対話生成など、創造的なテキストや応答を生成するタスクに特化しています。代表的なモデルとして、GPTシリーズが挙げられます。
リコメンドシステムへの適用方法分類
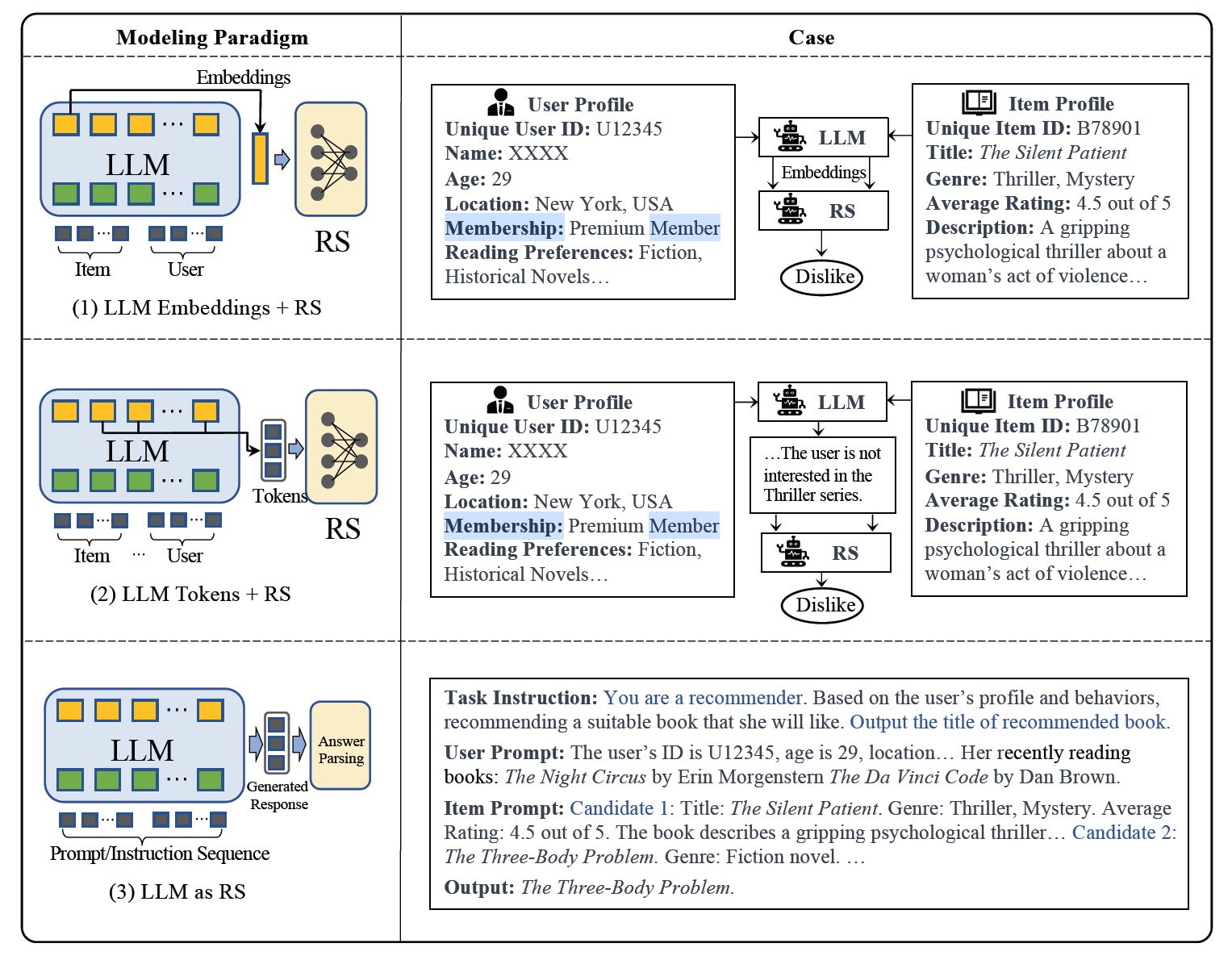
このアプローチでは、LLMは特徴抽出器として機能します。アイテムとユーザの特徴をLLMに入力し、対応する埋め込み(embeddings)を出力します。これらの知識に基づいた埋め込みは、従来のリコメンデーションシステム(RS)モデルによって、さまざまなリコメンドタスクに利用されます。
この方法では、アイテムやユーザの特徴に基づいてトークンを生成します。生成されたトークンは潜在的な好みを捉え、意味解析を通じてこれらをリコメンドシステムの意思決定プロセスに統合します。
このパラダイムでは、トレーニング済みのLLMを直接リコメンドシステムに転用することを目指しています。入力は通常、プロファイルの説明、行動プロンプト、タスク指示などが含まれ、出力は合理的なリコメンド結果を提供することが期待されます。
トレーニング方法の分類
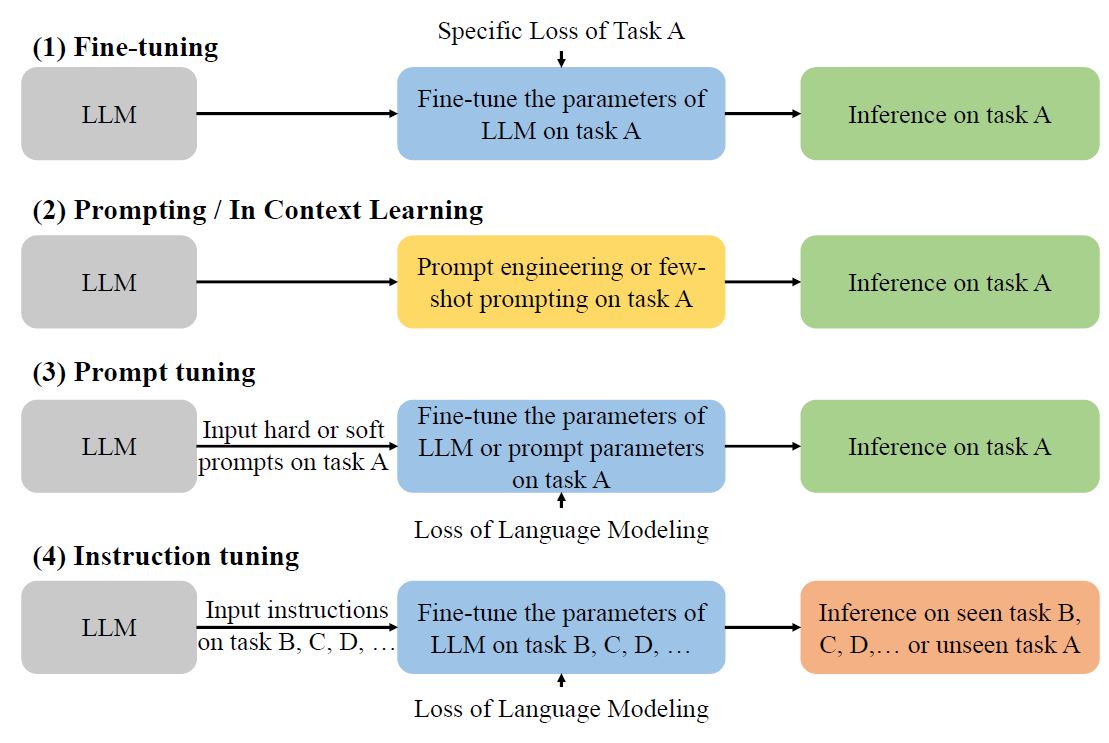
トレーニング方法は、Fine-tuning、Prompting/In Context Learning、Prompt tuning、Instruction tuningに分かれています。それぞれ解説していきます。
事前トレーニング済みのモデル(例: BERT、GPT)を特定タスク用に再トレーニングし、性能を最適化します。これにより、モデルは新しいタスク特有の知識や能力を獲得します。
モデルにプロンプト(指示や質問)を与え、そのコンテキスト内で回答や生成を行わせる方法です。モデルのパラメータは変更されず、与えられたプロンプトのコンテキスト内でのみ学習が行われます。
タスクに最適化されたプロンプトを作成します。主要なモデルのパラメータは固定され、プロンプトの一部がタスク固有の出力を生成するよう調整されます。
モデルが様々な命令や指示に適切に反応するように調整する方法です。多様なタスクの指示テキストを与え、それに対する反応を学習させることで、特定のタスクに限定されない広範な対応が可能になります。
識別的LLMの活用事例
識別的LLMは、自然言語理解タスクに優れているため、埋め込みのバックボーンとしてよく使用されます。ファインチューニングとプロンプトチューニング手法によりモデルを訓練することができます。
ファインチューニングの場合、BERTなどの学習済み言語モデルをドメイン固有のデータで調整する手法が挙げられます。これにより、多様な言語表現を学んだモデルを特定のタスクやドメインに適応させることができます。ユーザとアイテムの相互作用、アイテムのテキスト説明、ユーザプロファイルなどのデータを利用することができます。
プロンプトチューニングの場合、モデルの内部重みを変更せずに、プロンプト自体が学習されます。つまり、プロンプトに含まれるトークンの表現(Embedding)が更新されることにより、モデルの振る舞いをチューニングする手法です。プロンプトチューニングは、特定のタスクに対してモデルを柔軟に適応させることができ、計算コストも少なくて済みます。
・ファインチューニング事例:BERT4Rec
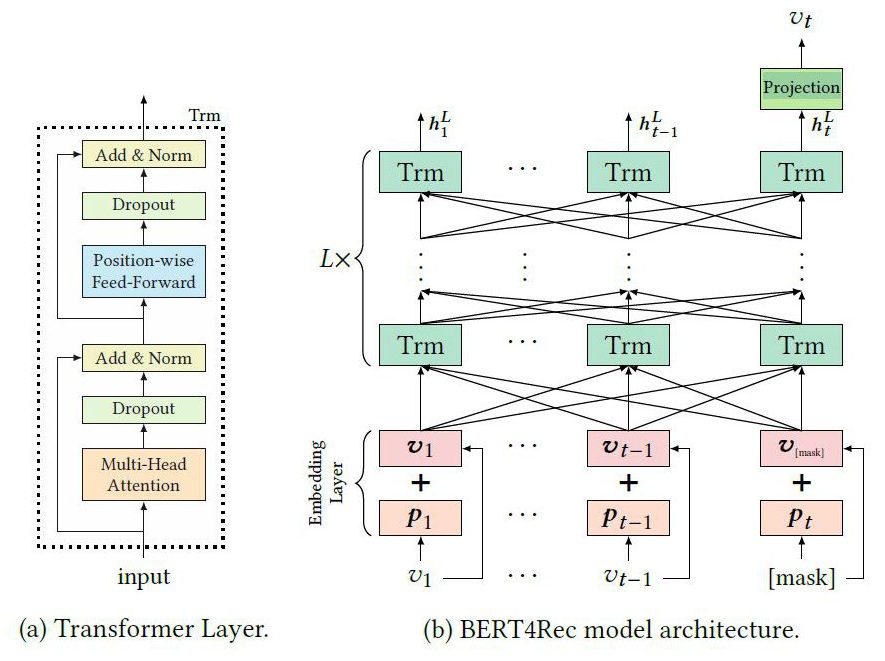
(a)のようなトランスフォーマーブロックからなる(b)のようなBERT構造になります。
pが位置情報Embedding、vがアイテムEmbeddingです。
マスクされたt時点のvを予測することでファインチューニングします。[Fei Sun, 2019]
BERT4Recは、BERTアーキテクチャに基づく双方向トランスフォーマーモデルで、主にユーザの行動履歴をシーケンスデータとして扱い、次の行動を予測します。このモデルは、ユーザの行動を時間的な文脈で分析し、シーケンス内のアイテム間の関連性を捉えることで多様な文脈情報を学習します。また、アイテムとその位置情報をベクトルで表現し、ランダムにマスクされたアイテムを予測させることで双方向の文脈を学習します。これにより、ユーザの好みに合わせたパーソナライズされたリコメンドが可能になります。
BERT4Recは、従来の単方向のリコメンドシステムとは異なり、ユーザの行動シーケンス全体にわたる多様な文脈情報を活用することで、発表時点で、BPR-MF(行列分解)、GRU4REC(GRUモデルベース)などの手法より高い精度のリコメンドを実現することができています。 [Fei Sun, 2019]
・プロンプトチューニング事例:Prompt4NR
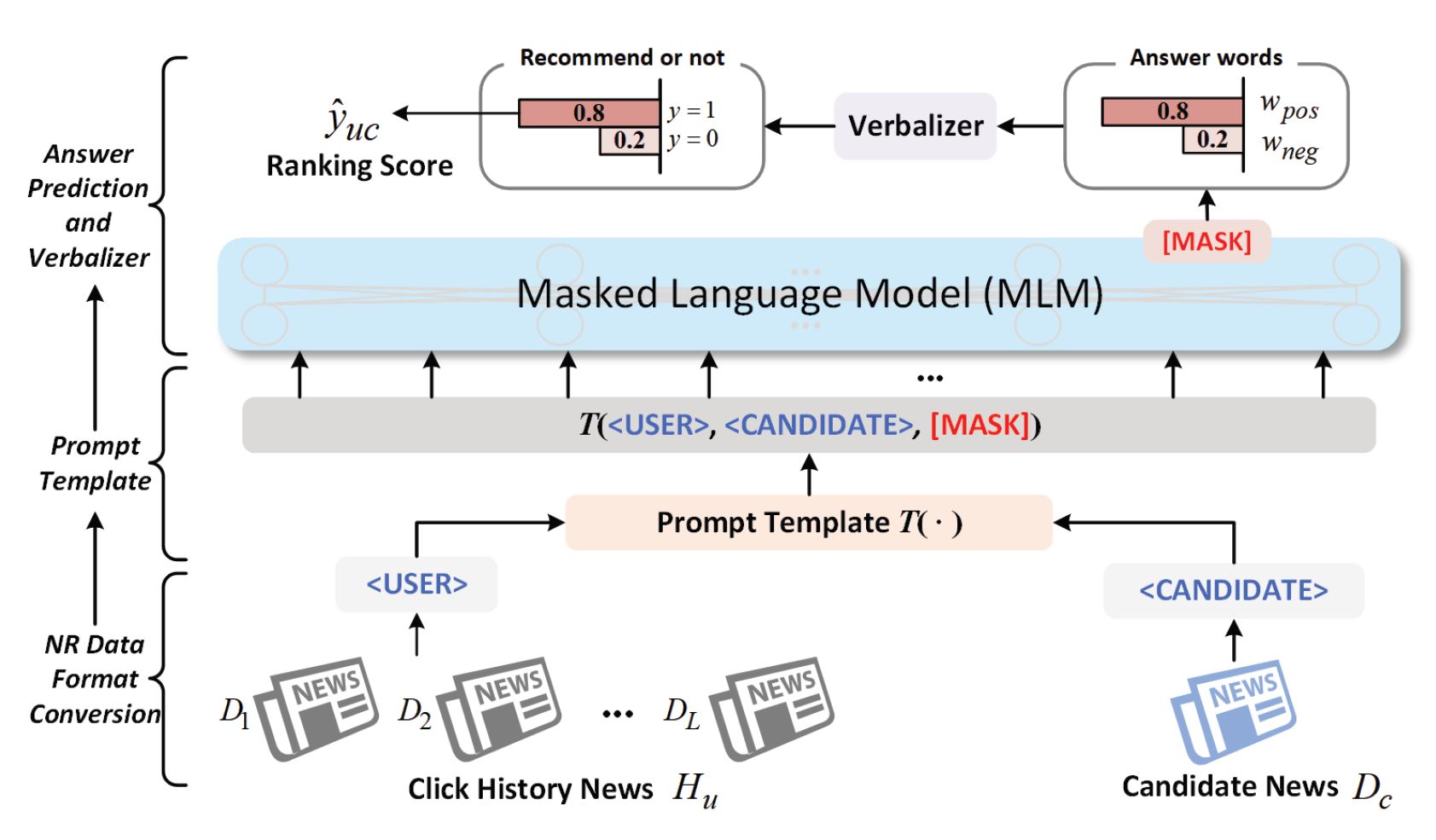
ユーザ(<USER>)が過去クリックしたニュースD1..DLと、候補(<CANDIDATE>)となるDcが
プロンプトテンプレートに入力し、ユーザが候補に対して興味有無(<MASK>)を予測します。 [Wang., 2023]

離散型、連続型、ハイブリッド型のプロンプトテンプレートが設計されています。 [Wang., 2023]
Prompt4NRモデルは、ニュースリコメンド(News Recommendation, NR)のためのフレームワークです。従来のモデルとは異なり、Prompt4NRはプロンプト学習と呼ばれる手法を採用しており、ニュース閲覧履歴(USER)、候補ニュース(CANDIDATE)をプロンプトテンプレートに入力し、ユーザが候補ニュースに対する興味有無(MASK)を推論します。
具体的には、様々な形式のプロンプトテンプレートが設計され、複数のプロンプトテンプレートの予測結果を統合するためのアンサンブル手法を使用しています。この方式はMINDデータセット1)MINDは、ニュースリコメンドベンチマークデータセットとして使われている、マイクロソフトニュースプラットフォームから収集されたユーザ行動ログのデータセットです。特定の時間にユーザに表示・クリックされたニュースとクリックされなかったニュース、およびそのインプレッション前のユーザのニュースクリック行動履歴を記録しています。を用いた検証で有効性が示されています。 [Wang., 2023]
生成的LLMの活用
生成的言語モデルは、特にリコメンドシステムにおいて、その自然言語生成能力を活かした革新的なアプローチを提供します。識別的モデルと比較して、これらのモデルはリコメンドタスクを自然言語タスクとして扱い、直接リコメンド結果を生成することができます。
大規模言語モデル(LLM)利用して、特定のタスクやデータセットに対してファインチューニングを行わない方法があります。このアプローチでは、モデルの既存の能力を活用して、タスク固有の学習を行わずにリコメンドします。
また、特定のリコメンドタスクに特化するために、プロンプトチューニングや命令チューニングなどの手法を適用する方法もあります。これにより、LLMは特定のタスクやドメインに適した形でチューニングされ、より精度の高い推薦結果を出力するように訓練されます。
・プロンプティング事例 -Is ChatGPT a Good Recommender? A Preliminary Study

ChatGPTをリコメンドタスクに適用させる研究にはさまざまな事例があります。
この事例(図6)ではモデルをトレーニングせずに、プロンプトのみを使用して自然言語タスクに変換するアプローチを採用しています。「Sequential Recommendation」「Direct Recommendation」ようにユーザの過去の行動やインタラクションの履歴をプロンプトに組み込み、次にユーザが興味を持ちそうなアイテムを推論し、リコメンド結果の評価を行っています。
ChatGPTは「アイテムに対するコメントから評価点数を予測するタスク」においては良好なパフォーマンスを発揮しました。しかし、一般的にいう「ユーザが興味のあるアイテムを推論する」タスク(連続リコメンド(Sequential Recommendation)や直接リコメンド(Direct Recommendation))のタスクではそれほど良いパフォーマンスを上げませんでした。[Junling Liu, 2023]
・生成的LLMファインチューニング事例-TALLRec
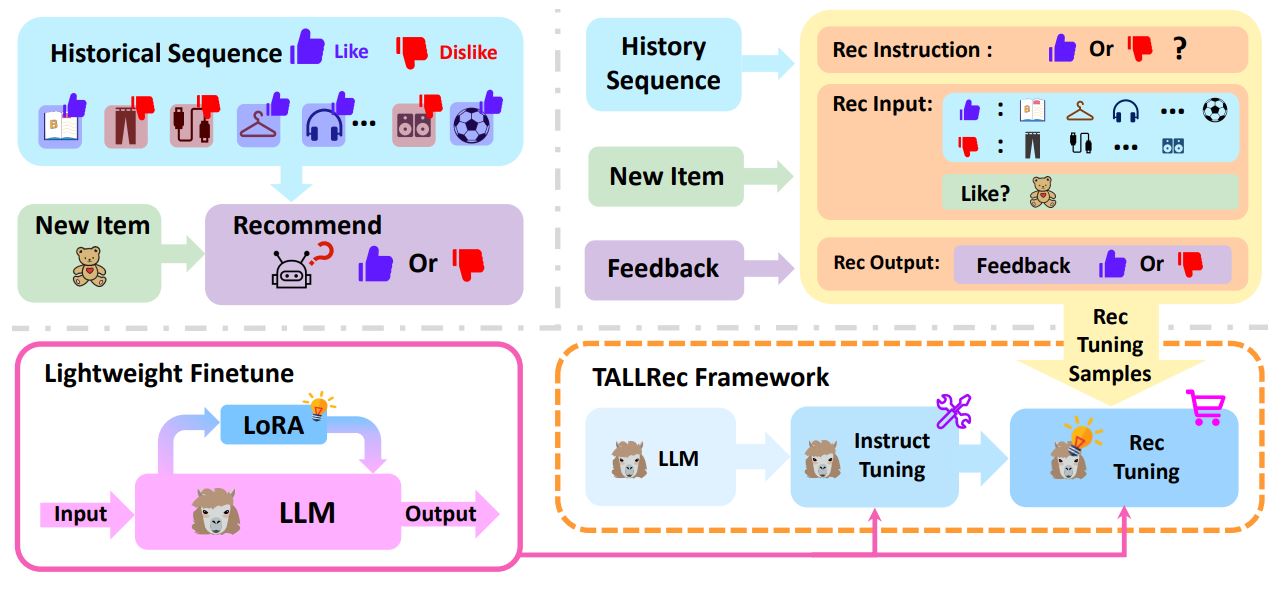
TALLRecは、LLaMAモデルをベースにしており、LoRA(Low-Rank Adaptation)アーキテクチャを利用して効率的なチューニングを行っています。主に、2つのチューニングプロセス、Instruct TuningとRec Tuningを組み合わせています。
このステップでは、LLMを多様なタスクや指示に対応できるように一般化します。これにより、モデルは広範なシナリオや要求に適応する能力を身につけます。
ここでは、リコメンデーション特有のデータを使用してモデルをファインチューニングします。
これにより、モデルはユーザの好みやニーズに基づいてより精度の高いリコメンデーションを生成できるようになります。 [Keqin Bao, 2023]
・命令チューニング事例-P5
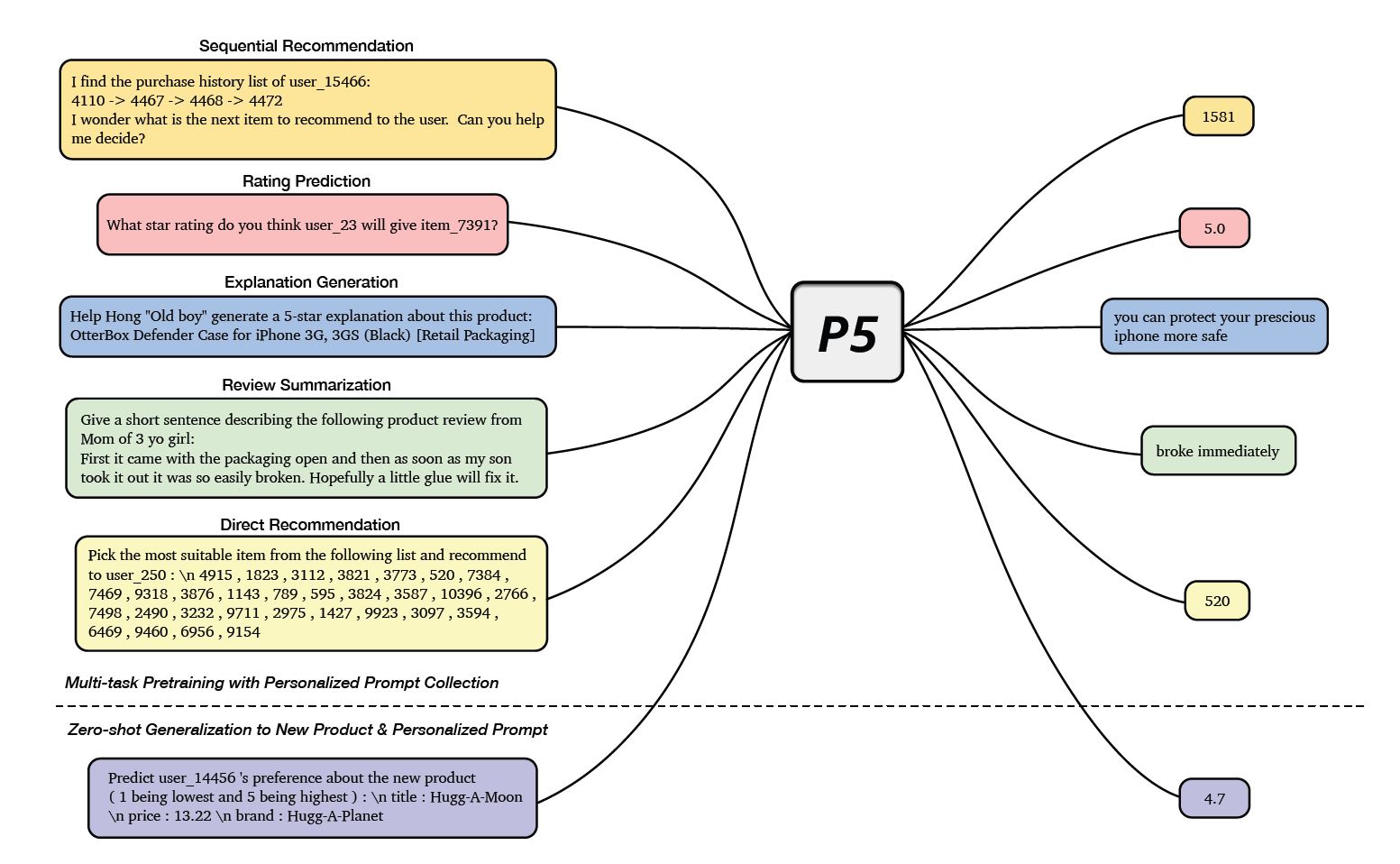
リコメンデーションに関わるSequential RecommendationやRating Predictionなど
複数のタスクおよびその答えをP5モデルに入力して学習させる。
リコメンデーションタスクの新しいプロンプトが入力されるときに適切に結果を推論できます。
[Shijie Geng, 2022]
P5モデルは、T5モデルをベースにして、複数のタイプの命令でファインチューニングされたリコメンデーションシステムです。このモデルでは、自然言語処理を応用して、ユーザの行動や好みをより深く理解し、個別化されたリコメンドを行います。P5は、異なるデータソース(ユーザとアイテムの相互作用、メタデータ、レビューなど)を統一的に扱い、言語モデルを通じてこれらの情報を理解します。このアプローチにより、P5はゼロショットやフューショット学習に対応し、広範囲なファインチューニングなしで多様なリコメンデーションタスクに適応できる柔軟性を持ちます。また、プロンプトベースの指示を通じて、より個人に合わせたリコメンドを提供することが可能です。 [Shijie Geng, 2022]
LLM利用したリコメンドシステムの課題
リコメンデーションシステムとバイアスの問題
- 位置バイアス:LLMベースのモデルでは、リストの上位にあるアイテムが優先される傾向があります。ランダムサンプリングやブートストラッピングが提案されていますが、完全な解決には至っていません。
- 人気バイアス:人気のあるアイテムが高いランキングを得やすい傾向があります。
- 公平性バイアス:性別や人種によるバイアスが現れることがあります。公正で偏りのないリコメンデーションを保証するためには、この問題に取り組むことが重要です。
リコメンデーションプロンプトの設計課題
- ユーザ/アイテム表現:ユーザの異種な行動シーケンスを自然言語に変換する際に工夫が必要です。
- コンテキストの長さの制限:LLMのコンテキストの長さに制限があり、最適なパフォーマンスを得るのが困難な場合があります。
- ゼロショット/フューショットの能力:限られたデータでのリコメンデーションが期待されますが、さらなる研究が必要です。
- 説明可能な能力:ChatGPTなどのモデルにより、リコメンド結果に対する優れた解釈性が示されています。
- Fei SunLiu, Jian Wu, Changhua Pei, Xiao Lin, Wenwu Ou, and Peng Jiang.Jun. (2019). Bert4rec: Sequential recommendation with bidirectional encoder representations from transformer. CIKM, pages 1441–1450.
- Junling LiuLiu, Renjie Lv, Kang Zhou, and Yan ZhangChao. (2023). Is chatgpt a good recommender? A preliminary study. CoRR, abs/2304.10149.
- Keqin BaoZhang, Yang Zhang, Wenjie Wang, Fuli Feng, and Xiangnan He.Jizhi. (2023). Tallrec: An effective and efficient tuning framework to align large language model with recommendation. CoRR, abs/2305.00447.
- Likang WuZheng, Zhaopeng Qiu, Hao Wang, Hongchao Gu, Tingjia Shen, Chuan Qin, Chen Zhu, Hengshu Zhu, Qi Liu, Hui Xiong, Enhong ChenZhi. (2023). A Survey on Large Language Models for Recommendation. arXiv:2305.19860.
- Shijie GengLiu, Zuohui Fu, Yingqiang Ge, and Yongfeng Zhang.Shuchang. (2022). Recommendation as language processing (RLP): A unified pretrain, personalized prompt & predict paradigm (P5). RecSys, pages 299–315.
- Wang.Zhang and BangZizhuo. (2023). Prompt learning for news recommendation. . arXiv:2304.05263.
有望な能力
評価の問題とデータセットの選択
評価問題:
評価するためにLLMに対して出力を制御する必要があります。LLMのリコメンデーション能力を評価するための基準は、現在未解決の問題です。
データセット:
実際の産業データセットと比べて、小規模なベンチマークデータセットではLLMの能力が完全に反映されないことがあります。
大規模言語モデルの限界と課題
知識の忘却:
特定のタスクのためにモデルをトレーニングすると、知識の忘却が起こる可能性があります。
大規模なモデルの使用は、過度な計算コストを要求する可能性があります。
結論
この論文では、リコメンデーションシステムにおける大規模言語モデル(LLM)の利用方法についての研究事例を広く概観しています。既存の研究を識別的モデルと生成的モデルに分類し、リコメンドシステムへの適用方法や、その特徴について比較を行っています。 この分野の研究はまだ発展途上にあり、LLMを活用したリコメンデーションシステムは、将来的により精度の高い、高品質のリコメンドができるよう発展することが期待されます。
筆者の感想
この研究はLLM(特に生成AI)をリコメンドシステムに応用することの可能性を示しています。LLMによるリコメンドは従来の方法と比較して、より多くの外部知識が捉えられ、学習データが少ない(またはない)ときも合理的なリコメンドを実現可能です。一方、データセットによって傾向が違い、モデルをより各データセットに適合させるには、モデル学習・ファインチューニングという従来の手法のほうがオーソドックスと言えるでしょう。LLMと従来のリコメンド手法をうまく融合すれば、お互いのメリットを生かすことができ、高品質なリコメンドが実現できるでしょう。
参考文献
References
| 1. | ↑ | MINDは、ニュースリコメンドベンチマークデータセットとして使われている、マイクロソフトニュースプラットフォームから収集されたユーザ行動ログのデータセットです。特定の時間にユーザに表示・クリックされたニュースとクリックされなかったニュース、およびそのインプレッション前のユーザのニュースクリック行動履歴を記録しています。 |