AWS Lambda Powertools 機能検証
こんにちは、NRIデジタルの島です。
AWS Lambda(以下Lambda)を効率的に開発する「Lambda Powertools(以下Powertools)」というツールがあるのをご存知でしょうか。筆者はこれまで触れる機会がありませんでしたが、今後Lambdaを使用したサーバレスアプリケーションの開発プロジェクトに携わることが多くなりそうだったこともあり、このタイミングで一度簡単な検証をしてみました。本記事にてその検証内容を共有していきますので、是非今後のLambda開発の参考にしていただければと思います。
本記事では以下Java版のPowertoolsを使用しますが、本ツールはJava以外にも「Python」「TypeScript」「.NET」で使用可能です。本記事で検証した機能はそれらの言語でも利用可能です。
Homepage – Powertools for AWS Lambda (Java)
Powertoolsとは
Lambdaファンクションを効率的に開発する為のユーティリティライブラリです。Lambdaファンクションの実装・監視などのベストプラクティスをサポートするAWS公式ライブラリ(OSSとして利用可能)で、オブザーバビリティをメインにサポートする「Core Utilities」とその他便利な機能を提供する「Helper Utilities」があります。代表的なユーティリティは以下の通りです。
| ユーティリティ | 機能 | 機能概要 |
|---|---|---|
| Core Utilities | Logger | 構造化されたJSONとしての出力を行う独自のロガーを提供 |
| Metrics | Amazon CloudWatch Embedded Metric Format (EMF) に従ってメトリクスを標準出力に記録することにより、カスタムメトリクスを非同期的に作成 | |
| Tracing | 「AWS X-Ray Java SDK」のThin Wrapperとして、Lambda関数ハンドラのトレースを低いオーバーヘッドで実現 | |
| Helper Utilities | Idempotency | Lambda関数の安全なリトライ実現の為、冪等性機能のシンプルなソリューションを提供 |
| Parameters | パラメータ値をAWS Systems Manager Parameter Store、AWS Secrets Manager、Amazon DynamoDBなどから取得するユーティリティクラスを提供 | |
| Large Message | Amazon SQS, Amazon SNSにおいて、最大許容サイズ (256 KB)より大きなサイズのデータを取り扱う方法を提供(S3オフロード) | |
| Batch Processing | SQS キュー、SQS FIFO キュー、Kinesis Streams、または DynamoDB Streams からのメッセージのバッチを処理するときに部分的なエラーを処理する方法を提供 | |
| Validation | AWS Lambda で使用されるイベントおよびレスポンス内に保持されるペイロードの JSON スキーマバリデーションを提供 | |
| Custom Resources | CloudFormationスタックのイベント(作成、更新、または削除)をトリガーに、Lambda関数がプロビジョニングロジックを実行する方法を提供 | |
| Serialization Utilities | JSONを操作するために Lambda 関数で使用できる一連のユーティリティを提供 |
上表は、Powertools(Java)公式ページの機能説明を、筆者の解釈をもとに表形式でサマリしたものです。
※Powertools(Java)公式ページでは「Core Utilities」以外のユーティリティは「Utilities」と記載されておりますが、「Core Utilities」と区別する為に「Helper Utilities」と記載しています。
Core Utilities
オブザーバビリティの重要性は日々高まっています。オブザーバビリティにおける重要な3要素として、Logging、Metrics、Tracingがありますが、これらに対してLambdaの開発者、運用者から必然的に発生するであろう以下のようなニーズを満たす為、Powertoolsの「Core Utilities」が開発・提供されました。
- すべての関数でフォーマット化されたログを生成して運用時に活用したい。また、「コールドスタート(※)」などのコンテキスト情報も出力したい。
- Lambda関数の実行時に独自のメトリクスを取得して想定通りに関数が実行されていることを数値として確認したい。
- コードを構造化してメソッドを機能単位に分割したので、メソッドごとの実行時間などをトレースしたい。
※ コールドスタートとは
一定の条件、タイミングでLambdaが新しい実行環境で実行されることです。コールドスタートが発生すると、実行環境の初期化処理などにより起動に時間がかかることになりますので、Lambdaを利用する際のパフォーマンス面での課題になることがあります。コールドスタートや実行環境のライフサイクルについては以下のAWSブログがわかりやすいのでご参照ください。
Operating Lambda: パフォーマンスの最適化 – Part 1 | Amazon Web Servicesまた、このコールドスタートの課題解決に向けたアプローチについて、以下ブログを公開しておりますので興味があれば是非ご覧ください。
AWS Lambda SnapStartを利用してJava Lambda関数高速化の可能性を探る | TECH | NRI Digital
これらの機能を独自に実装するのはかなり大変ですが、Powertoolsを使用するとカスタムコードなしで実現することが可能です。具体的には以下のような機能を実現可能です。
Logging
- 構造化されたフォーマット(JSON)にてログを出力可能
- Lambda コンテキスト、コールドスタートの情報をキャプチャ可能
- 構造化されたログに任意のキーを追加可能
- リクエストのパーセンテージでログのサンプリングを DEBUG ログレベルで有効化可能
Metrics
- 埋め込みメトリクスフォーマット Amazon CloudWatch Embedded Metric Format (EMF) に従った標準出力に対するメトリクスでカスタムメトリクスを非同期に作成可能
- メトリクスの一般的な定義間違い(メトリクスユニット、値、最大ディメンジョン、最大メトリクスなど)を検証可能
- 「captureColdStart」オプションを有効化することで、コールドスタート時のメトリクスのキャプチャが可能
Tracing
- サービス単位ではなく、メソッド単位でトレースが可能
- トレースにアノテーションを追加して、主要な情報に基づいてフィルタリングできるようにすることが可能。 e.g. コールドスタートアノテーションにて初期化オーバーヘッドがあったトレースを簡単にグループ化して分析可能
検証アプリ概要
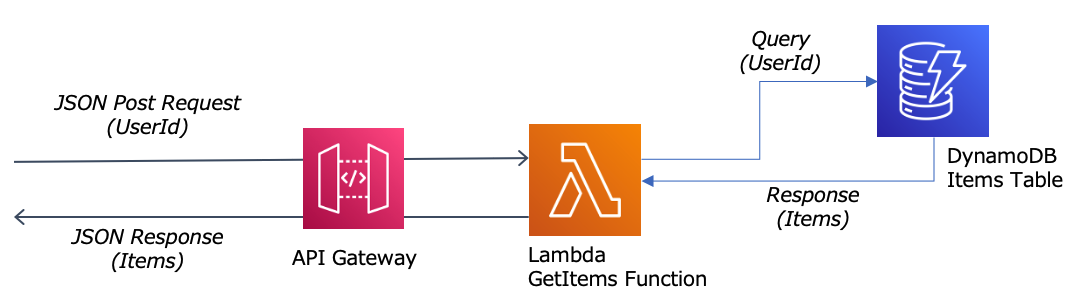
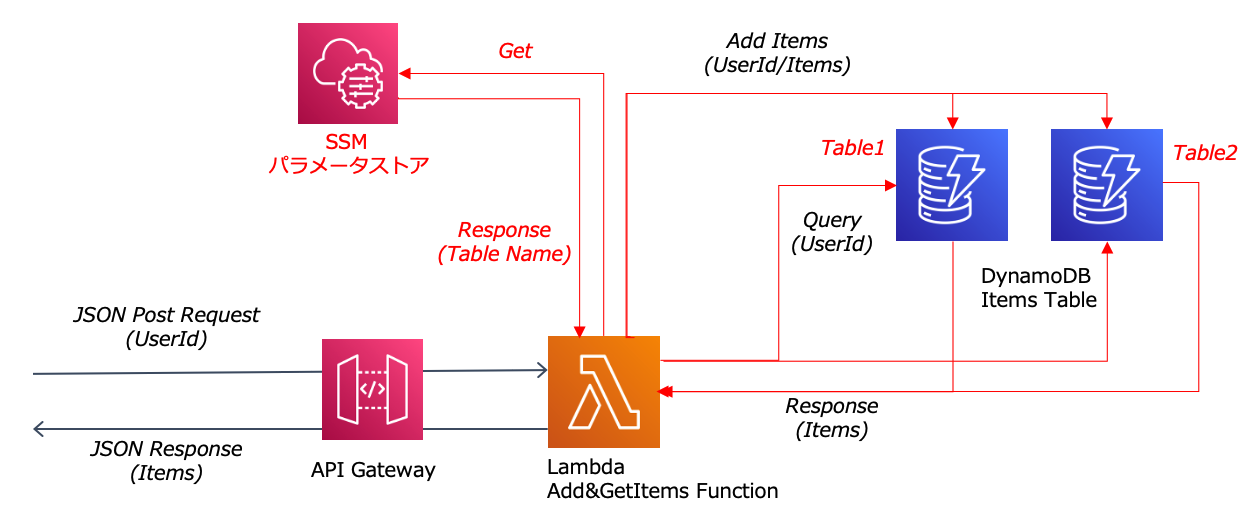
では、実際にそれらの機能を試していきます。本検証で利用するサンプルアプリケーションの構成は以下の通り単純なもので、受け取ったユーザIDに紐づく商品コードの一覧を返却するものです。
初期設定
JavaアプリケーションにてPowertoolsを利用可能にするには、MavenもしくはGradleの設定ファイルにPowertoolsライブラリ群の依存関係などを追加します。本検証ではMavenを使用する為、「pom.xml」に以下設定をしました。
pom.xml
...
<dependencies>
...
<dependency>
<groupId>software.amazon.lambda</groupId>
<artifactId>powertools-tracing</artifactId>
<version>1.17.0</version>
</dependency>
<dependency>
<groupId>software.amazon.lambda</groupId>
<artifactId>powertools-metrics</artifactId>
<version>1.17.0</version>
</dependency>
<dependency>
<groupId>software.amazon.lambda</groupId>
<artifactId>powertools-logging</artifactId>
<version>1.17.0</version>
</dependency>
...
</dependencies>
...
<!-- configure the aspectj-maven-plugin to compile-time weave (CTW) the aws-lambda-powertools-java aspects into your project -->
<build>
<plugins>
...
<plugin>
<groupId>org.codehaus.mojo</groupId>
<artifactId>aspectj-maven-plugin</artifactId>
<version>1.14.0</version>
<configuration>
<source>${maven.compiler.source}</source>
<target>${maven.compiler.target}</target>
<complianceLevel>${maven.compiler.target}</complianceLevel>
<aspectLibraries>
<aspectLibrary>
<groupId>software.amazon.lambda</groupId>
<artifactId>powertools-tracing</artifactId>
</aspectLibrary>
<aspectLibrary>
<groupId>software.amazon.lambda</groupId>
<artifactId>powertools-metrics</artifactId>
</aspectLibrary>
<aspectLibrary>
<groupId>software.amazon.lambda</groupId>
<artifactId>powertools-logging</artifactId>
</aspectLibrary>
</aspectLibraries>
</configuration>
<executions>
<execution>
<goals>
<goal>compile</goal>
</goals>
</execution>
</executions>
</plugin>
...
</plugins>
</build>
※詳細は公式ページをご参照ください
Logging
まず、Loggingについてです。以下2点について確認していきます。
- 構造化Logging
- DEBUGログサンプリング
構造化Logging
以下の手順を実施することで、構造化されたフォーマット(JSON)にてログを出力可能です。
① JSONフォーマットの設定
② 対象のメソッドへのアノテーション付与とログ出力
① JSONフォーマットの設定
「log4j2.xml」にてJSONフォーマットを設定します。
PowertoolsではベースのLoggingライブラリとして「Log4J2」を使用します
log4j2.xml
<?xml version="1.0" encoding="UTF-8"?>
<Configuration>
<Appenders>
<Console name="JsonAppender" target="SYSTEM_OUT">
<JsonTemplateLayout eventTemplateUri="classpath:LambdaJsonLayout.json" />
</Console>
</Appenders>
<Loggers>
<Logger name="JsonLogger" level="INFO" additivity="false">
<AppenderRef ref="JsonAppender"/>
</Logger>
<Root level="info">
<AppenderRef ref="JsonAppender"/>
</Root>
</Loggers>
</Configuration>
② 対象のメソッドへのアノテーション付与とログ出力
構造化ログを出力したいメソッドに「Logging」アノテーションを付与し、ログ出力します。
public class App implements RequestHandler<APIGatewayProxyRequestEvent, APIGatewayProxyResponseEvent> {
// Loggerの生成
private final Logger log = LogManager.getLogger(App.class);
・・・
// Loggingアノテーション付与
@Logging(logEvent = true)
public APIGatewayProxyResponseEvent handleRequest(final APIGatewayProxyRequestEvent input, final Context context) {
・・・
// ログ出力
log.info("Received input...");
・・・
}
また、以下のように任意のキーをログに追加出力することが可能です。
ログに出力するキーを追加
public class App implements RequestHandler<APIGatewayProxyRequestEvent, APIGatewayProxyResponseEvent> {
// Loggerの生成
private final Logger log = LogManager.getLogger(App.class);
・・・
// Loggingアノテーション付与
@Logging(logEvent = true)
public APIGatewayProxyResponseEvent handleRequest(final APIGatewayProxyRequestEvent input, final Context context) {
・・・
// ログにユーザIDを追加
String userId = this.mapper.readValue(input.getBody(), Request.class).userId();
LoggingUtils.appendKey("user_id", userId);
// ログ出力
log.info("Received input...");
・・・
}
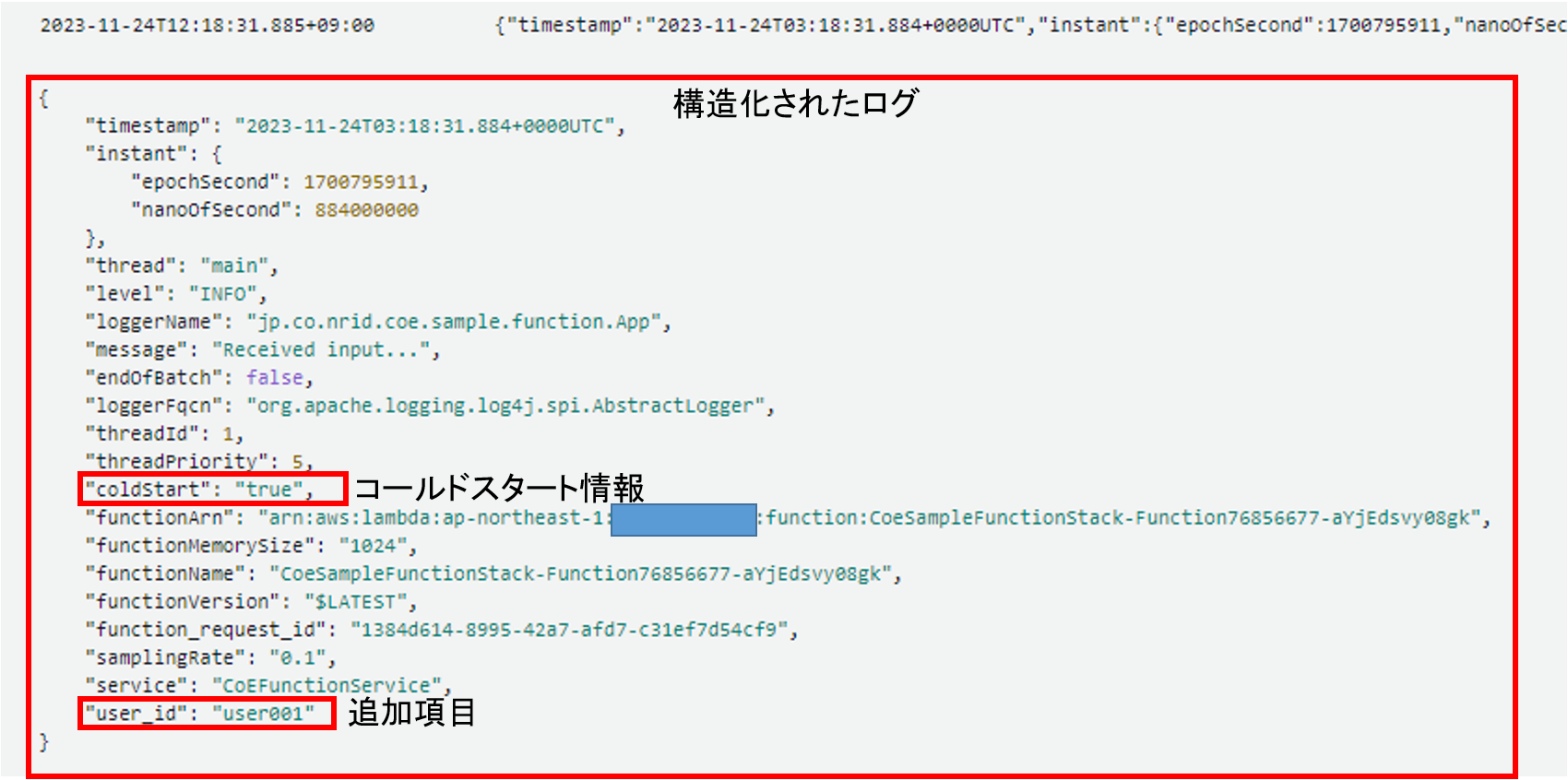
結果、該当メソッド(handleRequest)が実行されると、以下のようにログが構造化された状態で出力できておりました。また、コールドスタートの情報や個別に追加した情報もしっかり出力されておりました。
DEBUGログサンプリング
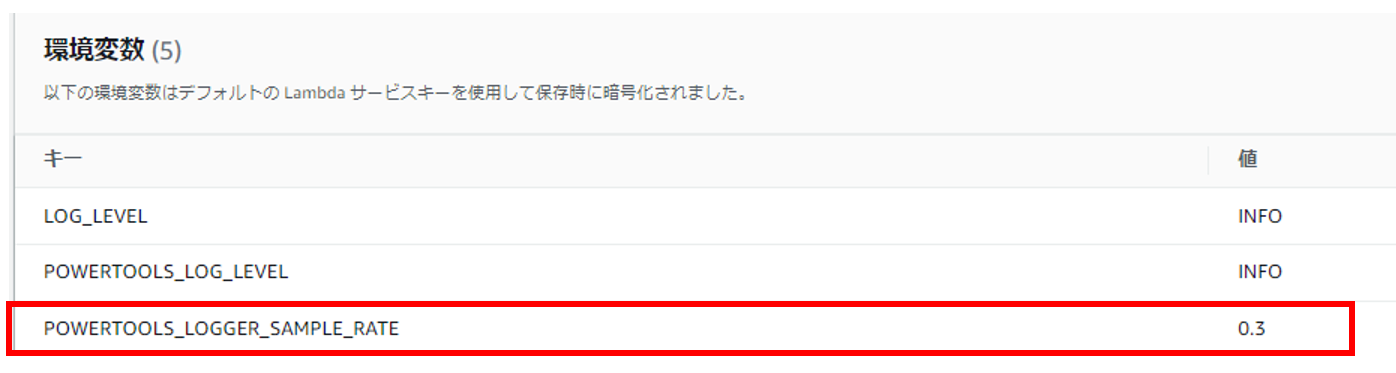
次にDEBUGログのサンプリング機能について試してみます。本番環境で障害調査などをしたい場合、DEBUGログのような詳細なログが出力されるととても便利です。しかしながら、大量のログ出力によるアプリケーション性能への影響やコストなどを懸念し、本番環境ではあまりDEBUGログの出力はしないと思います。本機能は一定の割合でDEBUGログを出力することで、ログ出力を任意の量に抑えながら必要な情報を取得するのに役立ちます。設定方法はLoggingアノテーションの属性「samplingRate」で指定するか、「POWERTOOLS_LOGGER_SAMPLE_RATE」環境変数で指定する方法があります。
アノテーション属性で指定
// 30%の割合で出力
@Logging(samplingRate = 0.3)
public APIGatewayProxyResponseEvent handleRequest(final APIGatewayProxyRequestEvent input, final Context context) {
・・・
環境変数で指定
結果、以下のように指定した割合でのみDEBUGログが出力されるようになりました。
ログ

Metrics
次にMetricsです。本機能を使用すると、独自のカスタムメトリクスを「Amazon CloudWatch(以下CloudWatch)」 へ非同期に送信可能です。また、コールドスタート情報もキャプチャすることができます。使用方法は、対象のメソッドにアノテーションを付与し、カスタムメトリクスを送信します。具体的には、「Metrics」アノテーションを付与し、「MetricsLogger」経由でカスタムメトリクスを送信します。また、コールドスタート情報もキャプチャしたい為、「Metrics」アノテーションの属性に「captureColdStart = true」を設定します。(デフォルトはfalse)
public class App implements RequestHandler<APIGatewayProxyRequestEvent, APIGatewayProxyResponseEvent> {
// MetricsLoggerの生成
private final MetricsLogger metricsLogger = MetricsUtils.metricsLogger();
・・・
@Logging(logEvent = true)
// Metricsアノテーション付与(コールドスタート情報キャプチャの為、「captureColdStart」をTrue
@Metrics(captureColdStart = true)
public APIGatewayProxyResponseEvent handleRequest(final APIGatewayProxyRequestEvent input, final Context context) {
・・・
// カスタムメトリクスの送信
metricsLogger.putMetric("successGetInput", 1, Unit.COUNT);
・・・
}
カスタムメトリクスの送信は非同期で行われる為、メインのアプリケーション処理にオーバヘッドは発生しません。また、以下のようにディメンションを設定することも可能です。
e.g. metricsLogger.putDimensions(DimensionSet.of(“environment”, “prod”));
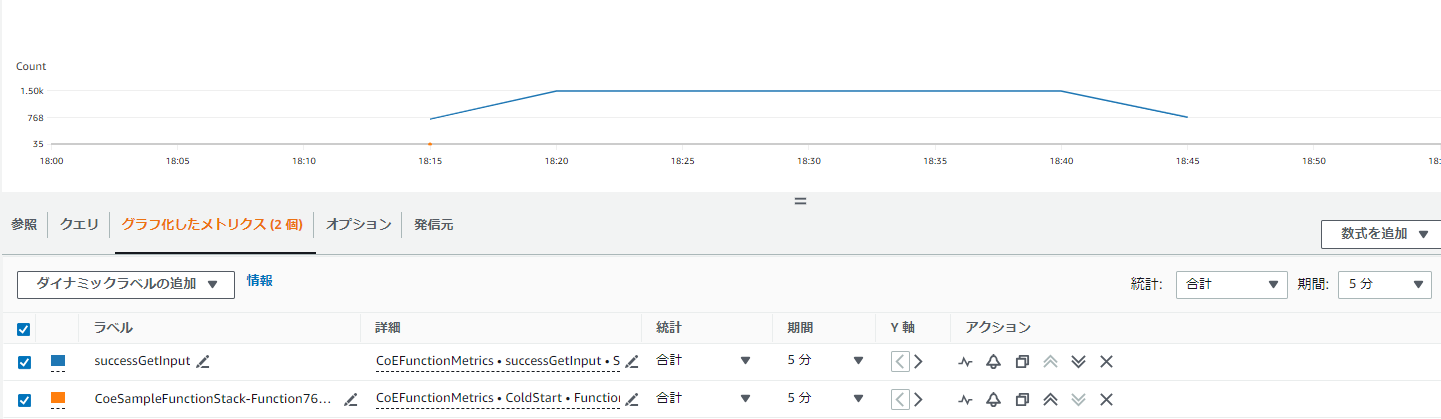
今回は「handleRequest」メソッドが実行されるたびインクリメントされていく「successGetInput」というカスタムメトリクスを独自に定義しました。実行すると「successGetInput」カスタムメトリクスとコールドスタートのメトリクスがCloudWatchにて参照できるようになりました。
Tracing
最後にTracingです。トレース情報を「AWS X-Ray(以下X-Ray)」へ連携することで、X-Rayコンソール上で参照できるようになるのですが、Powertoolsを使用しなくとも、もともとLambdaとX-Rayを連携させる機能は存在しています。具体的には以下のようにLambdaの「モニタリングツール設定」画面にてアクティブトレースを有効化すればトレースは可能です。
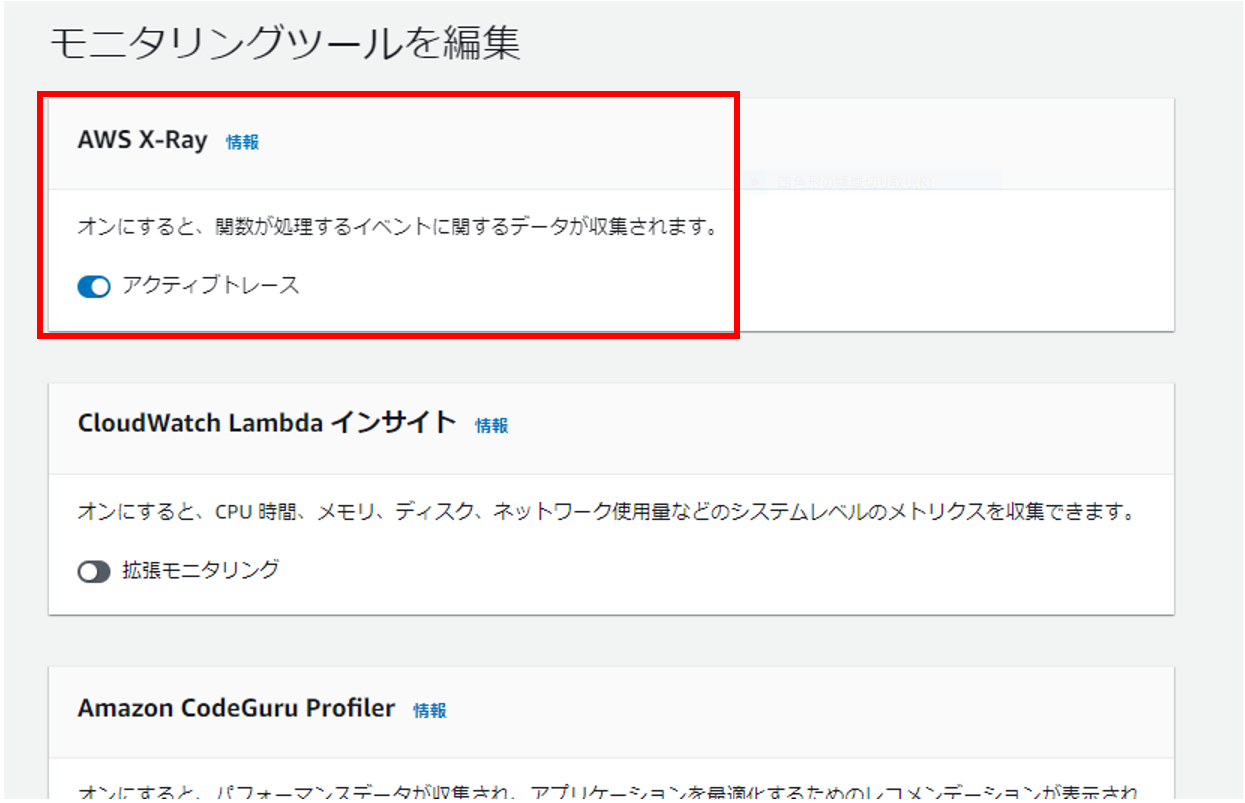
しかしながら、このアクティブトレース機能はあくまでLambdaファンクション単位であり、内部のメソッド単位でのトレースはできず、実現するにはX-Ray SDKを組み込んで個別に実装する必要がありました。Powertoolsを使用すると、SDKの個別組み込みは不要で簡単にメソッド単位でのトレースが可能となります。また、トレース情報にはアノテーションを付与することができ、付与したアノテーションでフィルターすることが可能です。デフォルトではコールドスタートのアノテーションが付与されている為、トレース情報をコールドスタート情報でフィルターして分析することも可能です。
Tracingの使用方法はトレース対象のメソッドに「Tracing」アノテーションを付与し、その属性にセグメント名を設定するだけです。
public class App implements RequestHandler<APIGatewayProxyRequestEvent, APIGatewayProxyResponseEvent> {
private final SampleService service = new SampleService();
・・・
@Logging(logEvent = true)
@Metrics(captureColdStart = true)
// Tracingアノテーション付与(属性にセグメント名を設定する)
@Tracing(segmentName = "main")
public APIGatewayProxyResponseEvent handleRequest(final APIGatewayProxyRequestEvent input, final Context context) {
・・・
this.service.get(userId)
・・・
}
・・・
}
public class SampleService {
@Tracing(segmentName = "Service")
public Response get(String userId) {
・・・
this.dynamoDbClient.query(--略--)
・・・
}
}
実行後、X-Rayコンソールを参照するとメソッド単位でトレース情報が出力されていることが確認できました。
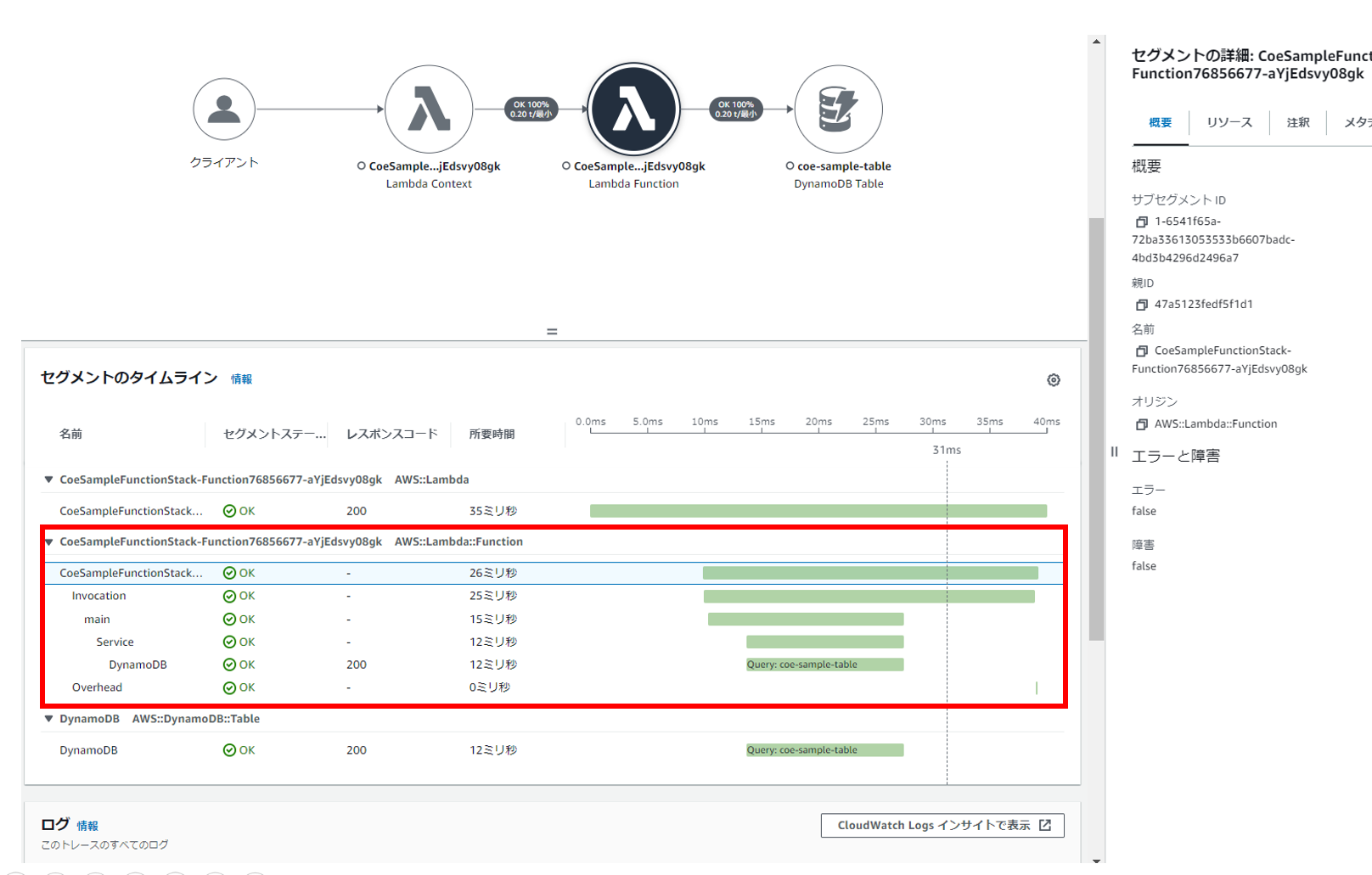
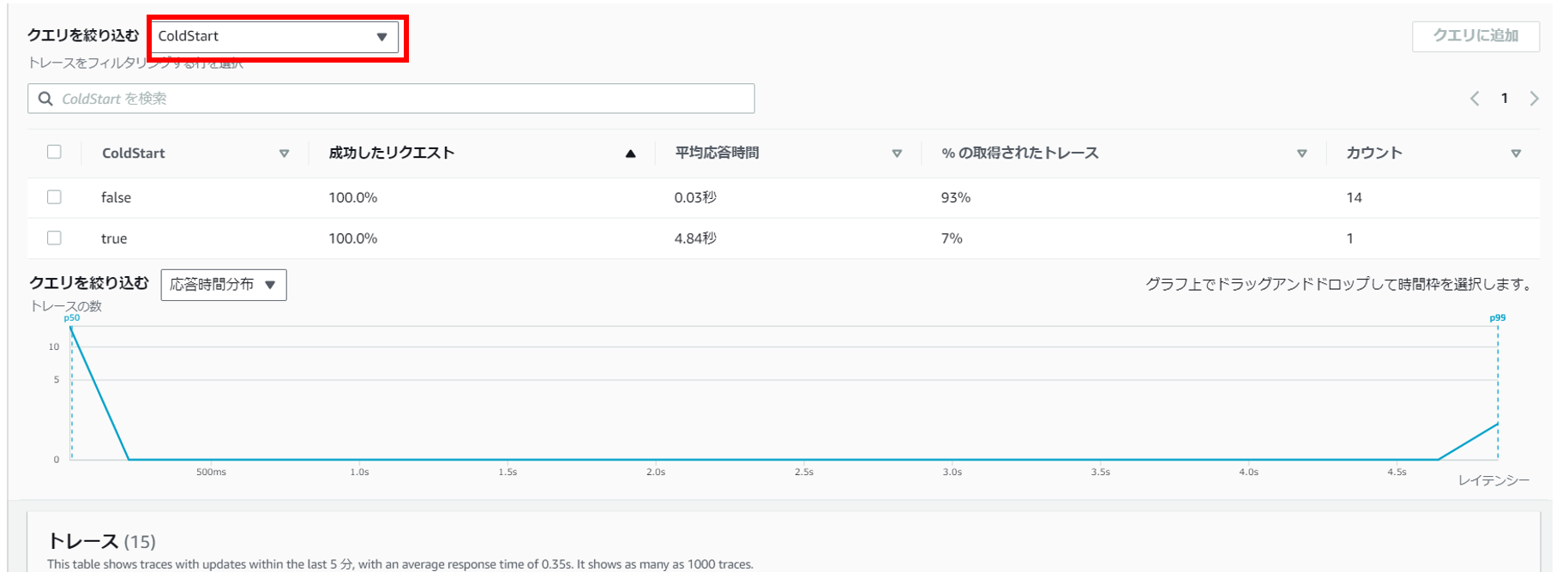
また、コールドスタートでフィルターをかけることで、コールドスタート有無によるトレース情報が確認できました。下図ではコールドスタート時には5秒弱の時間がかかっていることが確認できます。
以上、Core Utilitiesについて、主要機能の検証を実施してみました。既存コードの大幅な変更なく、オブザーバビリティ関連の機能を簡単に追加できるのは非常に便利だと思いました。
Helper Utilities
では、次にHelper Utilitiesについても見ていきたいと思います。Helper Utilitiesには多くの便利機能があります。本検証ではあまり特定のユースケースに依存しない以下赤枠の機能について確認していきます。
(再掲)
| ユーティリティ | 機能 | 機能概要 |
|---|---|---|
| Core Utilities | Logger | 構造化されたJSONとしての出力を行う独自のロガーを提供 |
| Metrics | Amazon CloudWatch Embedded Metric Format (EMF) に従ってメトリクスを標準出力に記録することにより、カスタムメトリクスを非同期的に作成 | |
| Tracing | 「AWS X-Ray Java SDK」のThin Wrapperとして、Lambda関数ハンドラのトレースを低いオーバーヘッドで実現 | |
| Helper Utilities | Idempotency | Lambda関数の安全なリトライ実現の為、冪等性機能のシンプルなソリューションを提供 |
| Parameters | パラメータ値をAWS Systems Manager Parameter Store、AWS Secrets Manager、Amazon DynamoDBなどから取得するユーティリティクラスを提供 | |
| Large Message | Amazon SQS, Amazon SNSにおいて、最大許容サイズ (256 KB)より大きなサイズのデータを取り扱う方法を提供(S3オフロード) | |
| Batch Processing | SQS キュー、SQS FIFO キュー、Kinesis Streams、または DynamoDB Streams からのメッセージのバッチを処理するときに部分的なエラーを処理する方法を提供 | |
| Validation | AWS Lambda で使用されるイベントおよびレスポンス内に保持されるペイロードの JSON スキーマバリデーションを提供 | |
| Custom Resources | CloudFormationスタックのイベント(作成、更新、または削除)をトリガーに、Lambda関数がプロビジョニングロジックを実行する方法を提供 | |
| Serialization Utilities | JSONを操作するために Lambda 関数で使用できる一連のユーティリティを提供 |
なお、Helper Utilitiesの検証では、更新系の確認が必要となってくる為、サンプルアプリケーションに以下のように更新系の処理を追加して実施していきます。
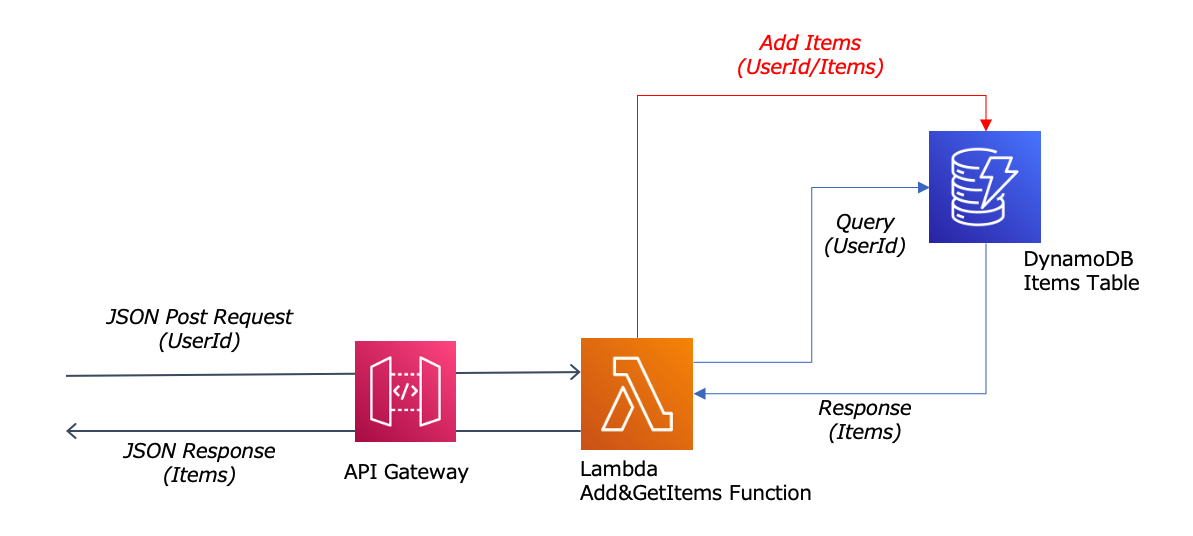
既存の「商品一覧検索」処理の前に「商品コード追加」処理を追加しています。その為、「商品一覧検索」処理では「商品コード追加」処理で追加された商品コードも含めた結果が返却されます。
Idempotency
最初に冪等性の保証です。冪等性とは「同じ操作を何度繰り返しても、同じ結果が得られる性質」のことで、同一パラメータにて操作が複数回呼び出された場合でも、操作が追加の副作用を引き起こさないことを保証します。例えば、「同一請求期間に該当顧客を複数回サブスクライブすることによって、誤った料金請求(2重請求)がされないことを保証する(=2重請求という副作用を引き起こすようなデータ生成を防止する)」などです。
冪等性についての詳細はAWSのページにも紹介されておりますので、是非ご参照いただければと思います。
Making retries safe with idempotent APIs
冪等性機能を実現するには以下の手順が必要です。
- Idempotencyライブラリの追加
- 永続ストレージ層の作成(DynamoDBテーブルへの冪等性管理テーブルの作成)
- 冪等性処理動作設定・カスタマイズ
- 冪等性を保証したいメソッドへのアノテーション付与
構成としては、ユーザデータを登録するDynamoDBテーブルと冪等性処理を管理する為のDynamoDBテーブルが存在する形になります。
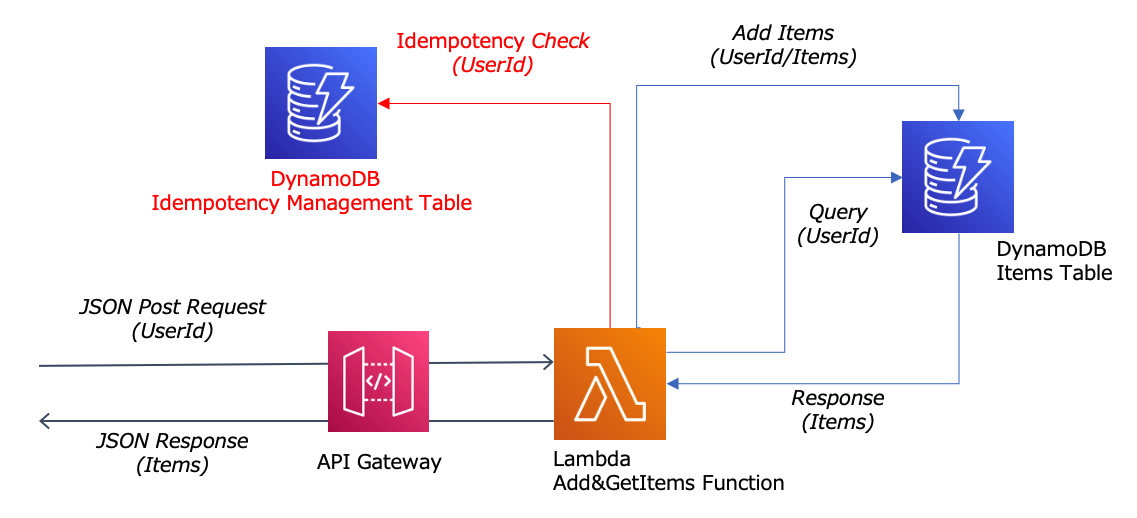
① Idempotencyライブラリの追加
以下のように、pom.xmlに「Idempotencyライブラリ」を追加します。
pom.xml
...
<dependencies>
...
<dependency>
<groupId>software.amazon.lambda</groupId>
<artifactId>powertools-idempotency</artifactId>
<version>1.17.0</version>
</dependency>
...
</dependencies>
...
<!-- configure the aspectj-maven-plugin to compile-time weave (CTW) the aws-lambda-powertools-java aspects into your project -->
<build>
<plugins>
...
<plugin>
<groupId>org.codehaus.mojo</groupId>
<artifactId>aspectj-maven-plugin</artifactId>
<version>1.14.0</version>
<configuration>
<source>${maven.compiler.source}</source>
<target>${maven.compiler.target}</target>
<complianceLevel>${maven.compiler.target}</complianceLevel>
<aspectLibraries>
<aspectLibrary>
<groupId>software.amazon.lambda</groupId>
<artifactId>powertools-tracing</artifactId>
</aspectLibrary>
<aspectLibrary>
<groupId>software.amazon.lambda</groupId>
<artifactId>powertools-metrics</artifactId>
</aspectLibrary>
<aspectLibrary>
<groupId>software.amazon.lambda</groupId>
<artifactId>powertools-logging</artifactId>
</aspectLibrary>
<aspectLibrary>
<groupId>software.amazon.lambda</groupId>
<artifactId>powertools-idempotency</artifactId>
</aspectLibrary>
</aspectLibraries>
</configuration>
<executions>
<execution>
<goals>
<goal>compile</goal>
</goals>
</execution>
</executions>
</plugin>
...
</plugins>
</build>
② 永続ストレージ層の作成(DynamoDBへの冪等性管理テーブルの作成)
冪等判定に使用する管理テーブルを作成します。公式ページに従い、パーティションキーを「id」、TTLを「expiration」という名前で作成します。
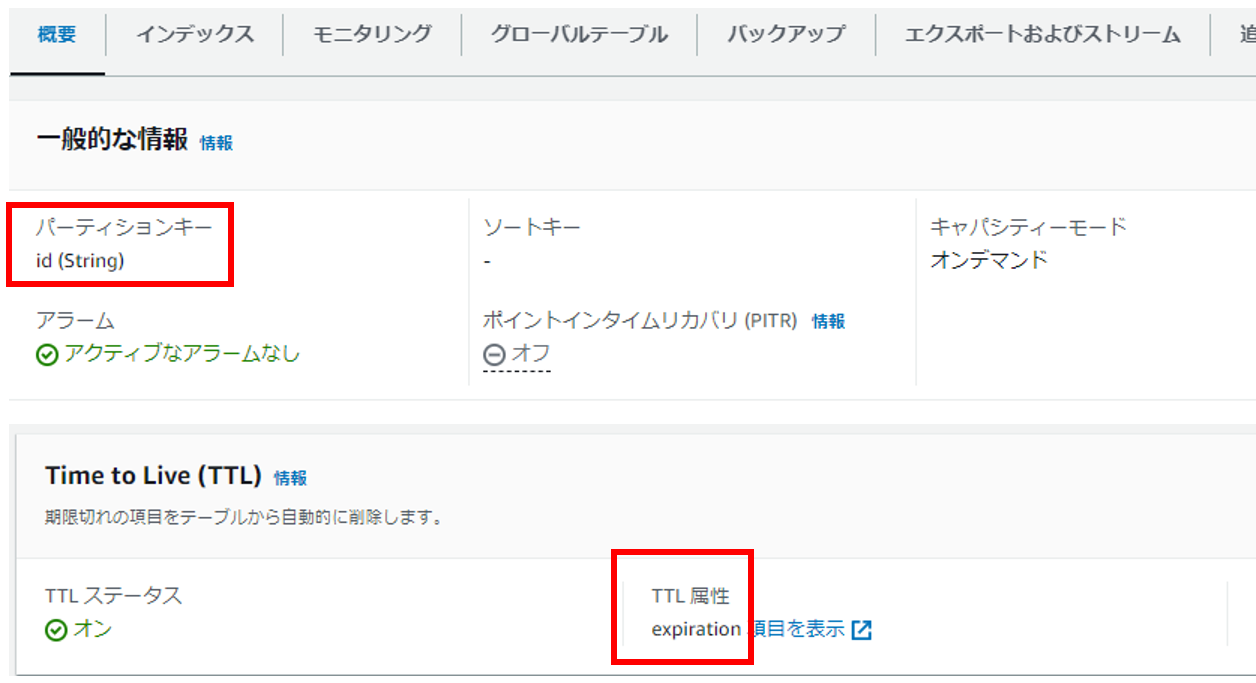
③ 冪等性処理動作設定・カスタマイズ
冪等性処理の動作設定・カスタマイズ処理を実装します。この処理は、ハンドラーメソッドが実行される前に呼び出される必要があるので、今回は対象のアプリケーションクラスのコンストラクタに実装します。デフォルトだとTTL(冪等性を保証する時間)は1時間ですが、変更したい場合は調整可能です。今回は検証しやすいように「1分」に設定します。
// Appクラスのコンストラクタ
public App() {
Idempotency.config()
.withPersistenceStore(DynamoDBPersistenceStore.builder()
.withTableName(System.getenv("IDEMPOTENCY_TABLE_NAME"))
.build())
.withConfig(IdempotencyConfig.builder()
.withExpiration(Duration.of(1, ChronoUnit.MINUTES)) ←TTLを1分に設定
.withUseLocalCache(true)
.build())
.configure();
}
※その他条件も比較的柔軟にカスタマイズも可能ですので、詳細は公式ページをご確認ください。
④ 冪等性を保証したいメソッドへのアノテーション付与
最後に冪等性を保証したいメソッドへ「Idempotent」アノテーションを付与します。また、冪等性制御対象のパラメータは、メソッドへの引数が一つ場合はそれがデフォルトで使用されますが、指定したい場合は「IdempotencyKey」アノテーションで指定可能です。今回は検証しやすいように「ユーザID」のみにします。
・・・
@Idempotent
public String register(@IdempotencyKey String userId, Request request) {
// Key
Map<String,AttributeValue> itemKey = Map.of(
USER_ID, AttributeValue.builder().s(userId).build()
);
// Value
Map<String, AttributeValueUpdate> itemValue = Map.of(
ITEMS, AttributeValueUpdate.builder()
.value(AttributeValue.builder().l(request.getItems()
.stream().map(AttributeValue::fromS).toList())
.build())
.action(AttributeAction.ADD)
.build()
);
this.dynamoDbClient.updateItem(UpdateItemRequest.builder()
.tableName(DynamoConfig.getTableName().isEmpty() ?
DynamoProperties.TABLE_NAME.getName() : DynamoConfig.getTableName())
.key(itemKey)
.attributeUpdates(itemValue)
.build()
);
return userId;
}
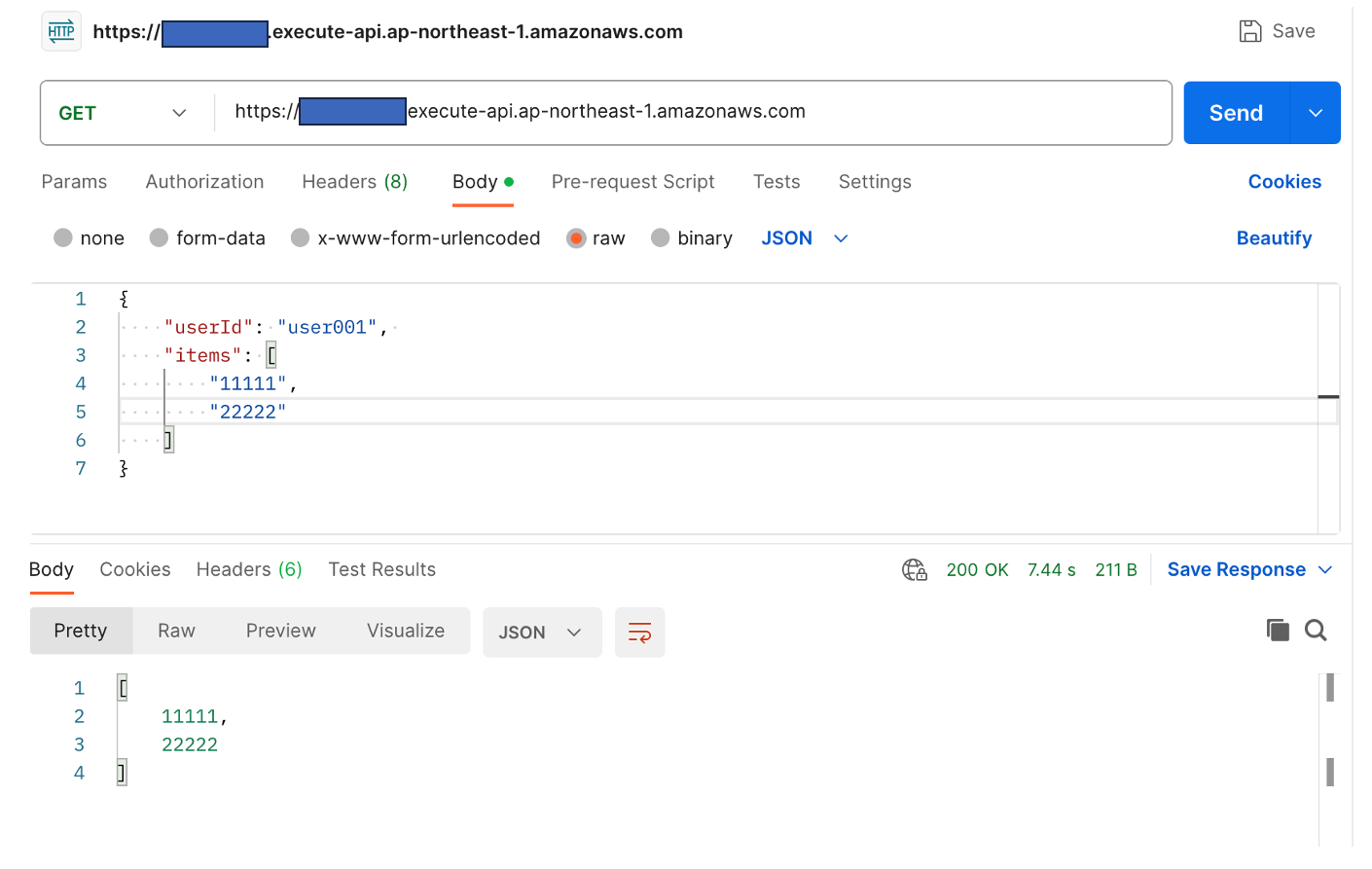
では、以下の通り実行してみます。
リクエスト(postmanで実行)
ユーザ「user001」に商品コード「11111」と「22222」を追加します。
ユーザテーブル
ユーザデータが正常に登録されています。
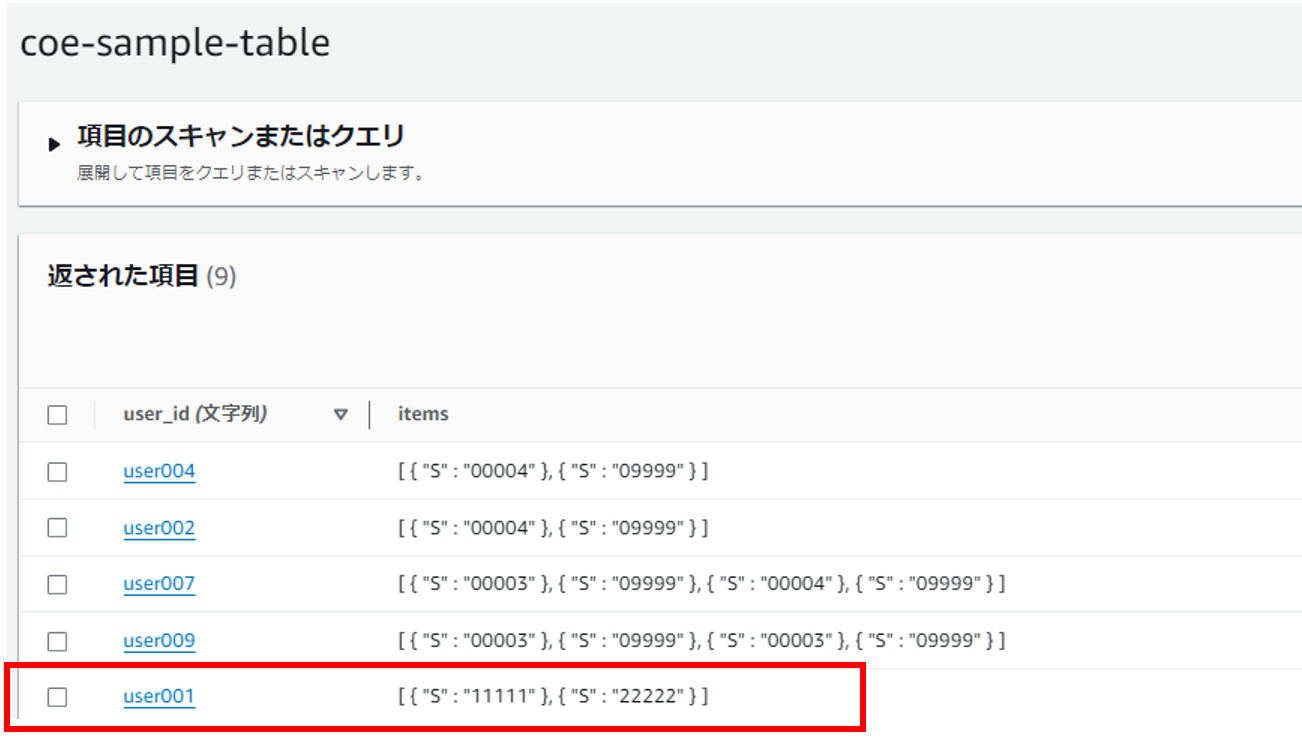
冪等性管理テーブル
同タイミングで冪等性管理テーブルにも情報が登録されました。
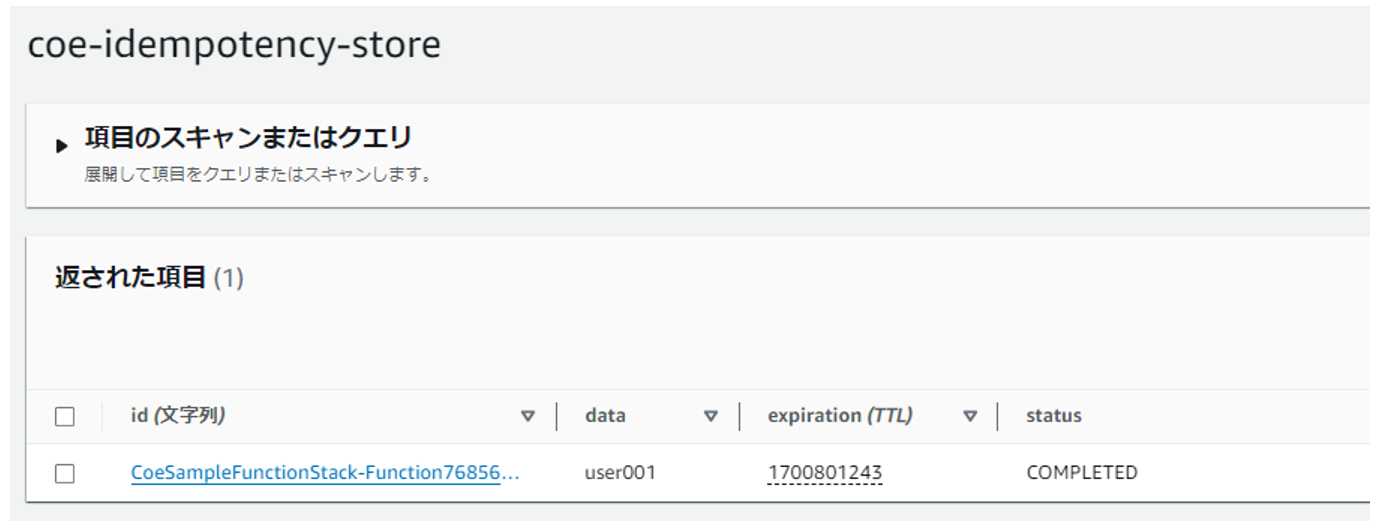
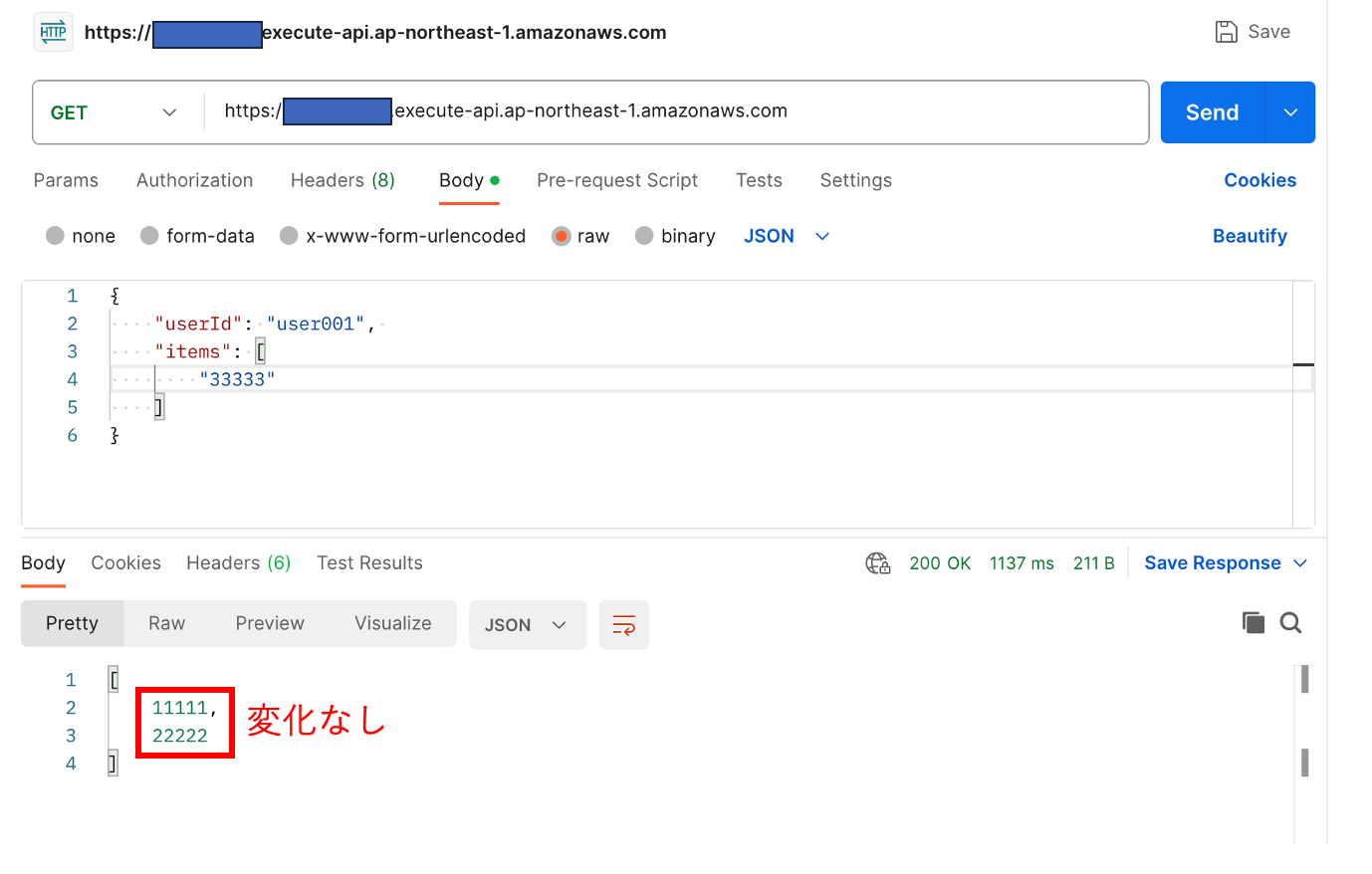
冪等性管理テーブルに登録されたTTLまでの1分間は、同一パラメータ(今回は同一ユーザID)で何度商品コードを追加しにいっても追加されません。
TTLまで(1分間)は追加されない
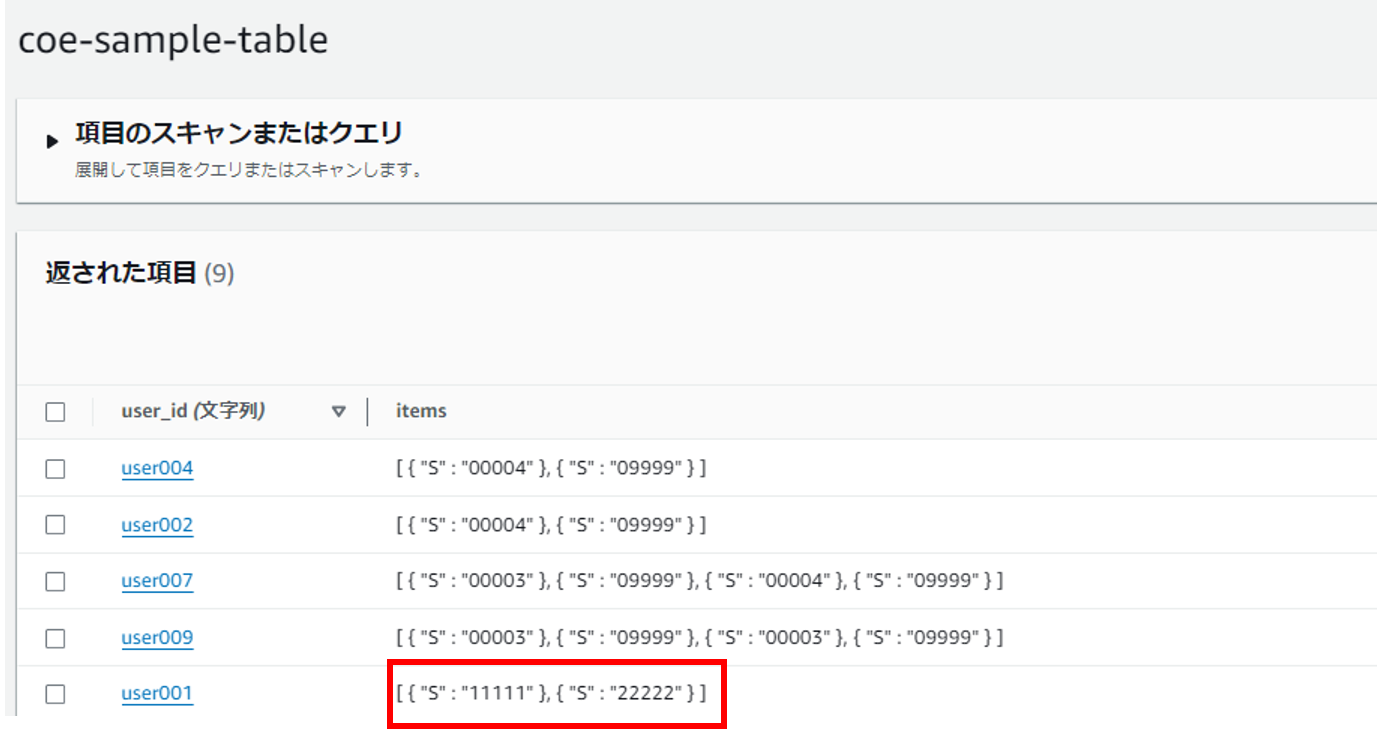
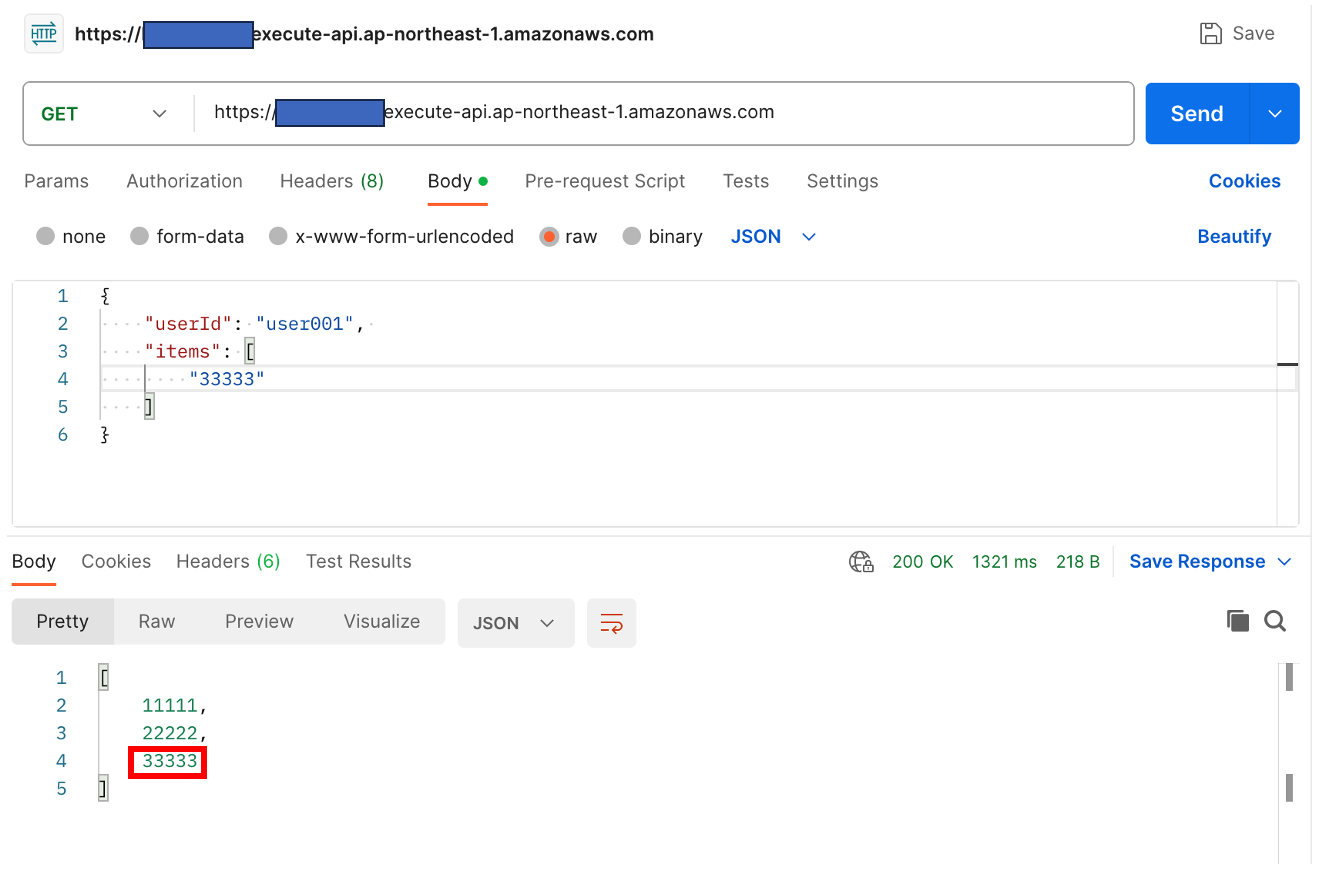
1分経過後は以下の通り正常に追加されました。
TTL(1分間)を超えると追加される
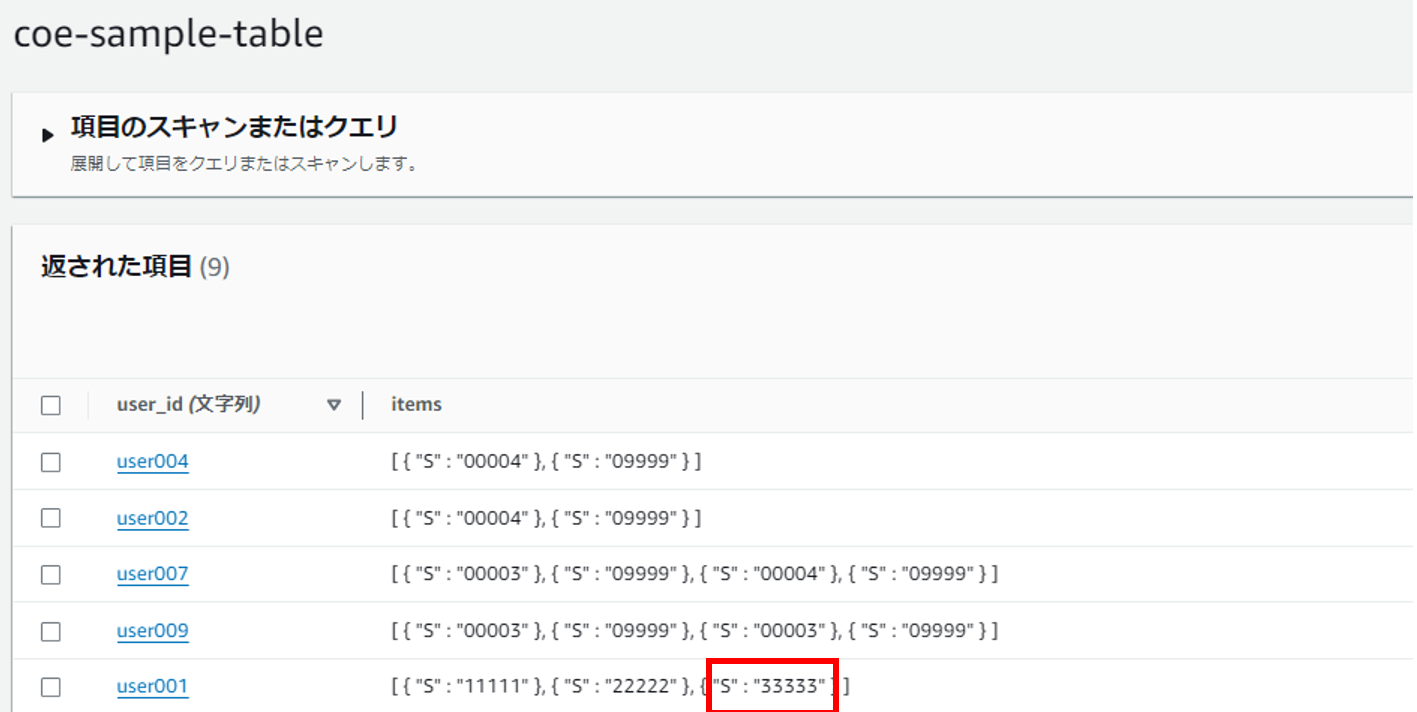
管理用テーブルの準備など、若干事前準備に手間がかかりますが、自作するともっと手間がかかり、品質的なリスクも発生する為、フレームワーク側に処理を委譲できることは大きなメリットだと感じました。
Parameters
次にパラメータ機能について確認します。本機能は、「AWS Systems Manager(以下SSM)」のパラメータストアや「AWS Secrets Manager」などのコンフィグサーバに設定したコンフィグ値の取得をサポートします。本機能のポイントは、設定したTTLの間値をキャッシュできることです。これにより、コンフィグサーバへの通信オーバヘッドを抑えながら動的なコンフィグ値取得を実現します。検証方法は、サンプルアプリケーションがアクセスするDyanamoDBのテーブル名をコンフィグ値として持たせ、そのテーブル名を変更することで、アクセス先が想定の時間で切り替わるかで確認します。
※本検証ではSSMのパラメータストアをコンフィグサーバとして使用します
以下の手順で実施しました。
① Parametersライブラリの追加
② SSMパラメータストアの作成
③ コンフィグ取得処理の実装
① Parametersライブラリの追加
以下のように「Parametersライブラリ」を依存関係に追加します。
...
<dependencies>
...
<dependency>
<groupId>software.amazon.lambda</groupId>
<artifactId>powertools-parameters</artifactId>
<version>1.17.0</version>
</dependency>
...
</dependencies>
...
② SSMパラメータストアの作成
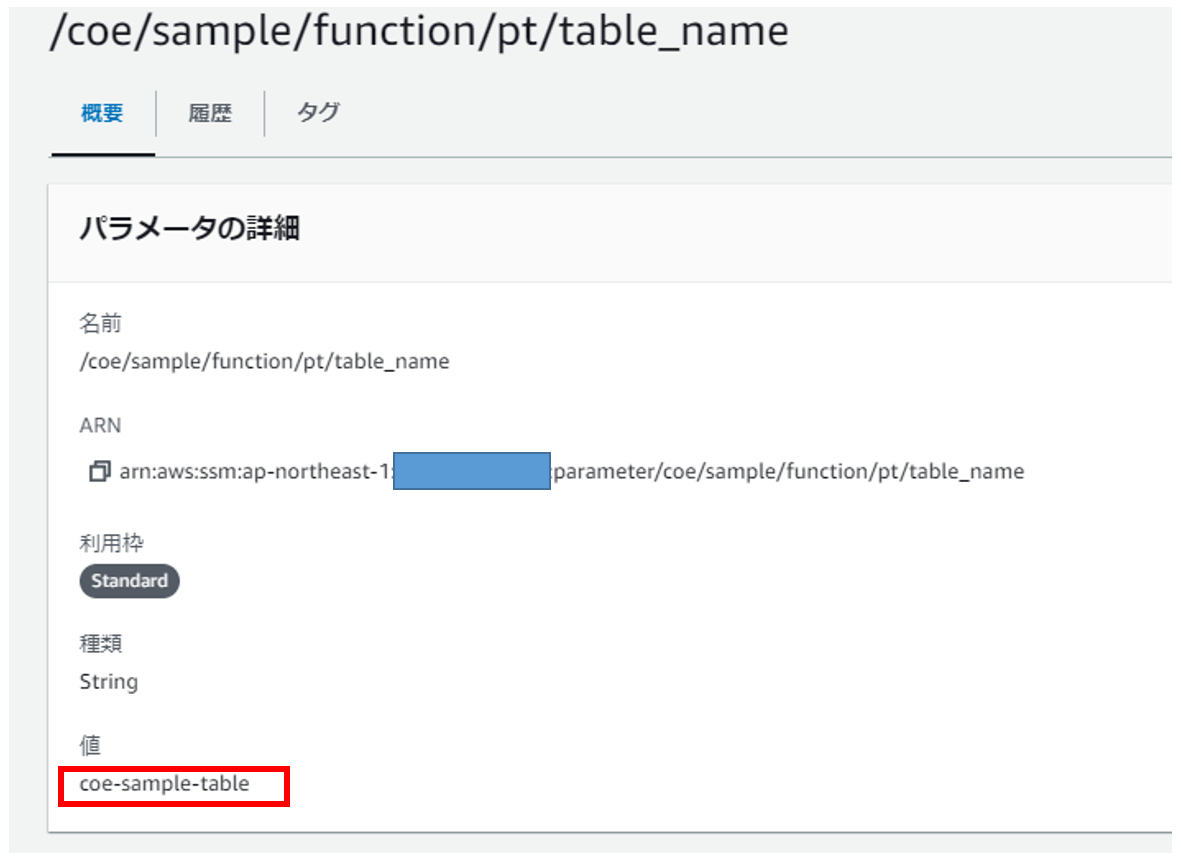
正規のテーブル名でSSMパラメータストアを作成しておきます。
③ コンフィグ取得処理の実装
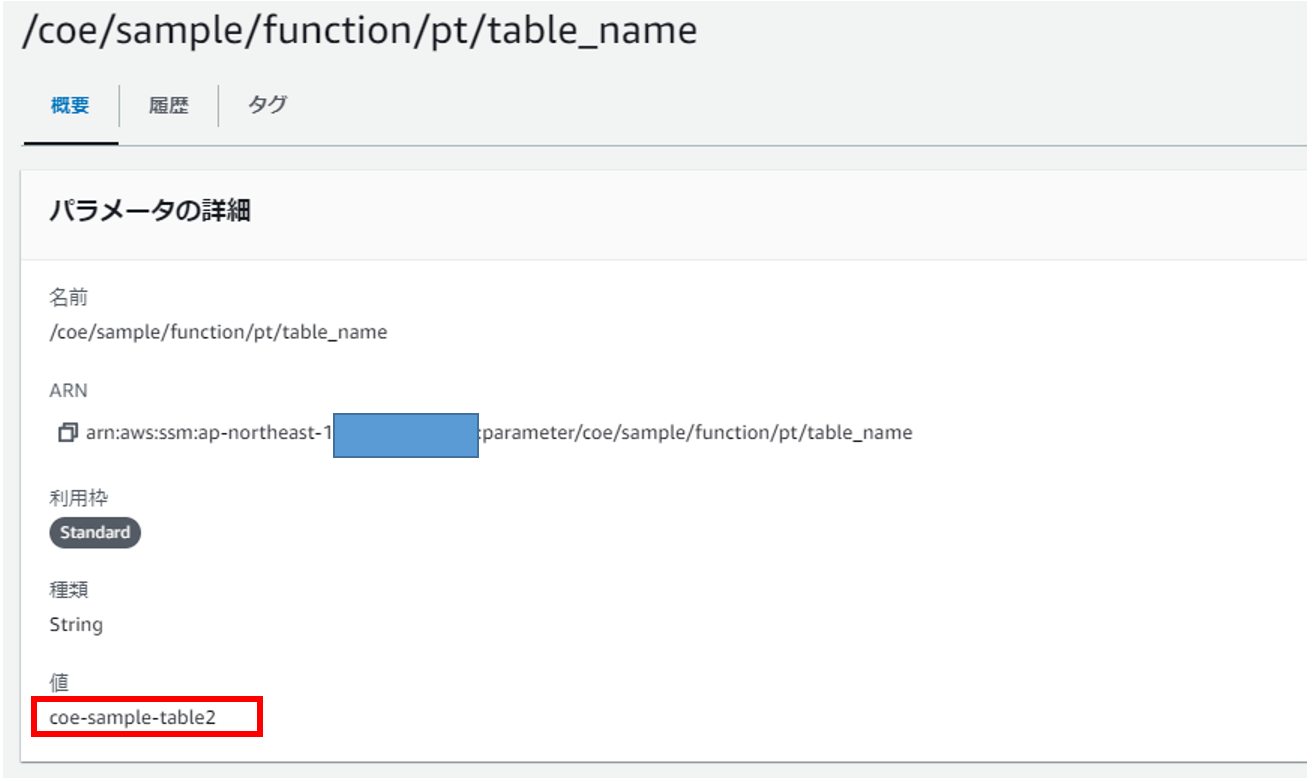
SSMパラメータストアからテーブル名を取得する処理を実装します。検証しやすいように、TTLは「1分」に設定します。
public class DynamoConfig {
private static final SSMProvider ssmProvider = ParamManager.getSsmProvider();
private static final Logger log = LogManager.getLogger(DynamoConfig.class);
public static String getTableName() {
String tableName = null;
try {
tableName = ssmProvider
.withMaxAge(1, ChronoUnit.MINUTES)
.get("/coe/sample/function/pt/table_name");
log.info("table_name->" + tableName);
} catch(Throwable t) {
t.printStackTrace();
}
return tableName;
}
}
実行すると、SSMパラメータストアに設定したテーブルのデータが更新されます。
リクエスト
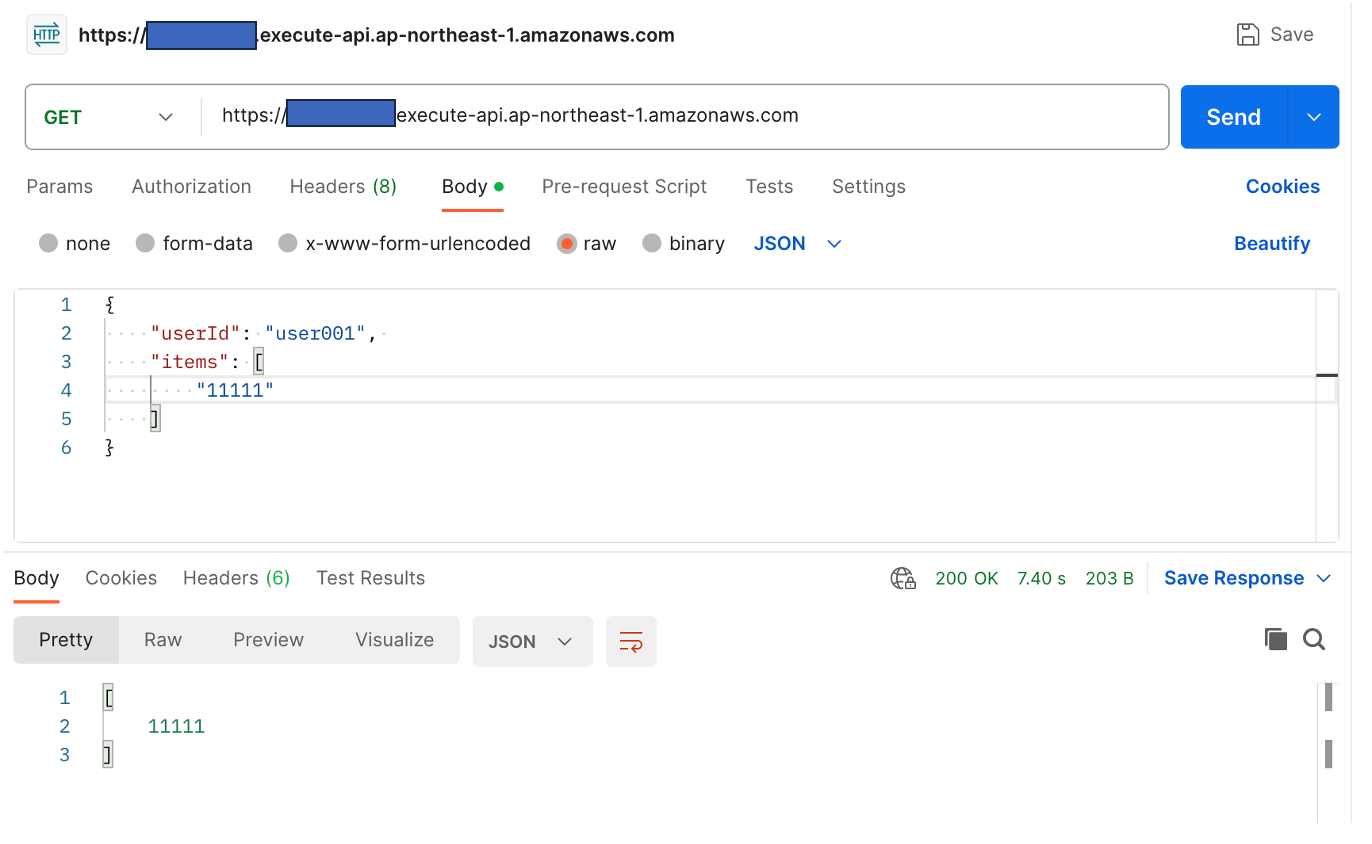
現行テーブル
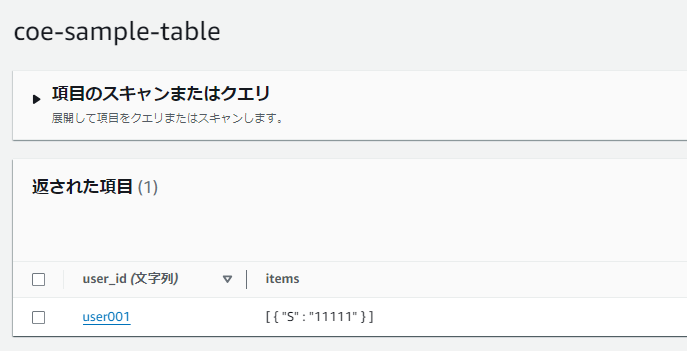
次にSSMパラメータストアのテーブル名を変更します。
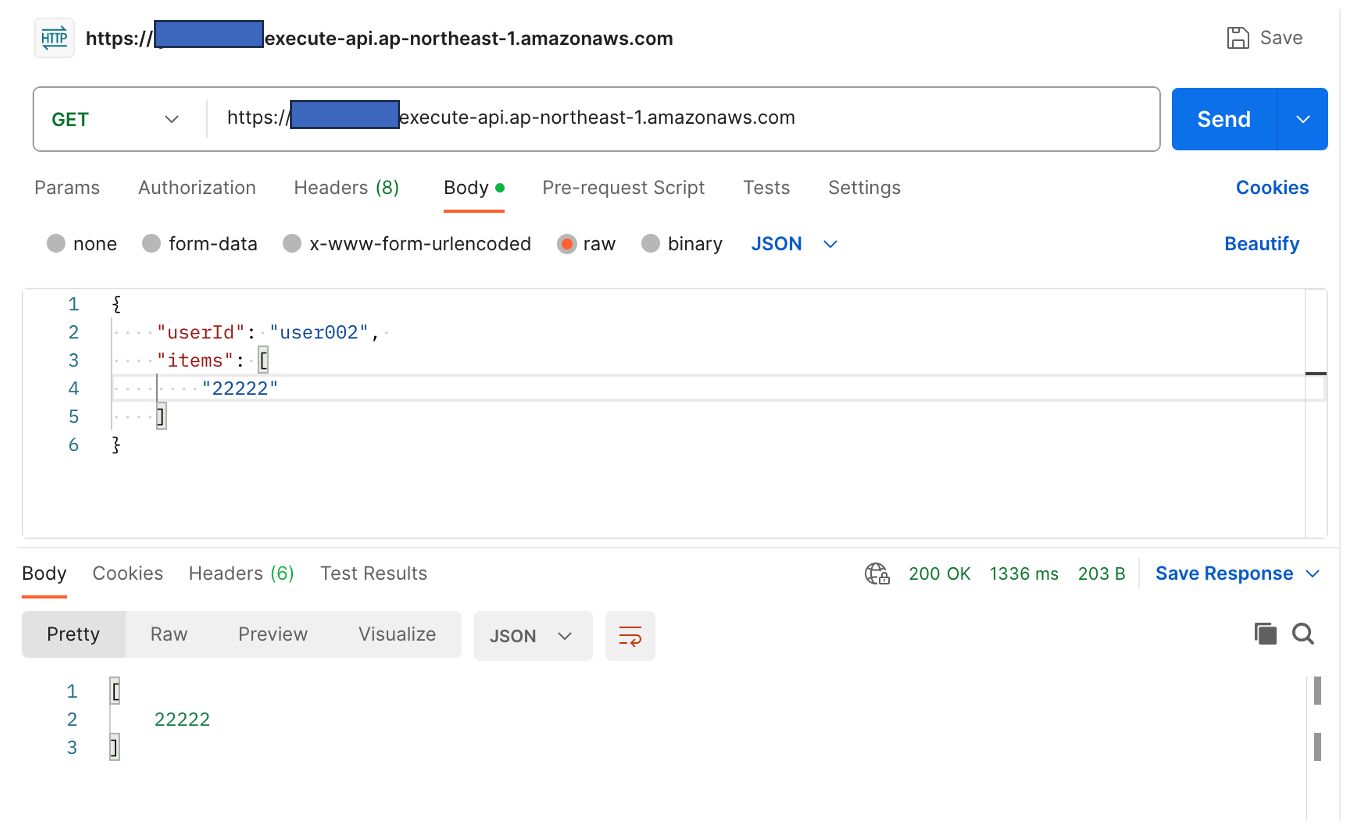
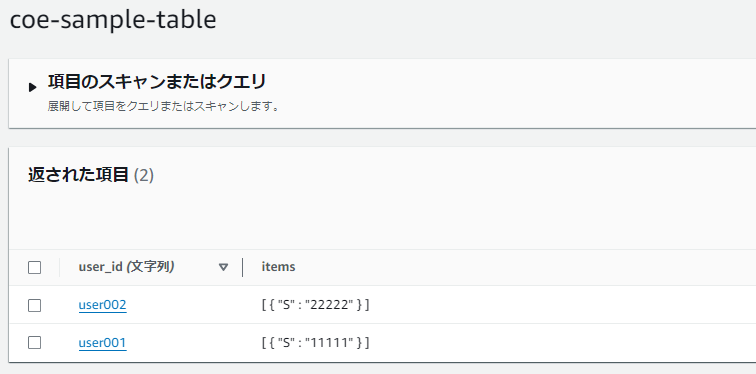
設定変更後、1分間はまだ変更前のテーブルのデータが更新されます。
リクエスト
現行テーブル
変更先テーブル
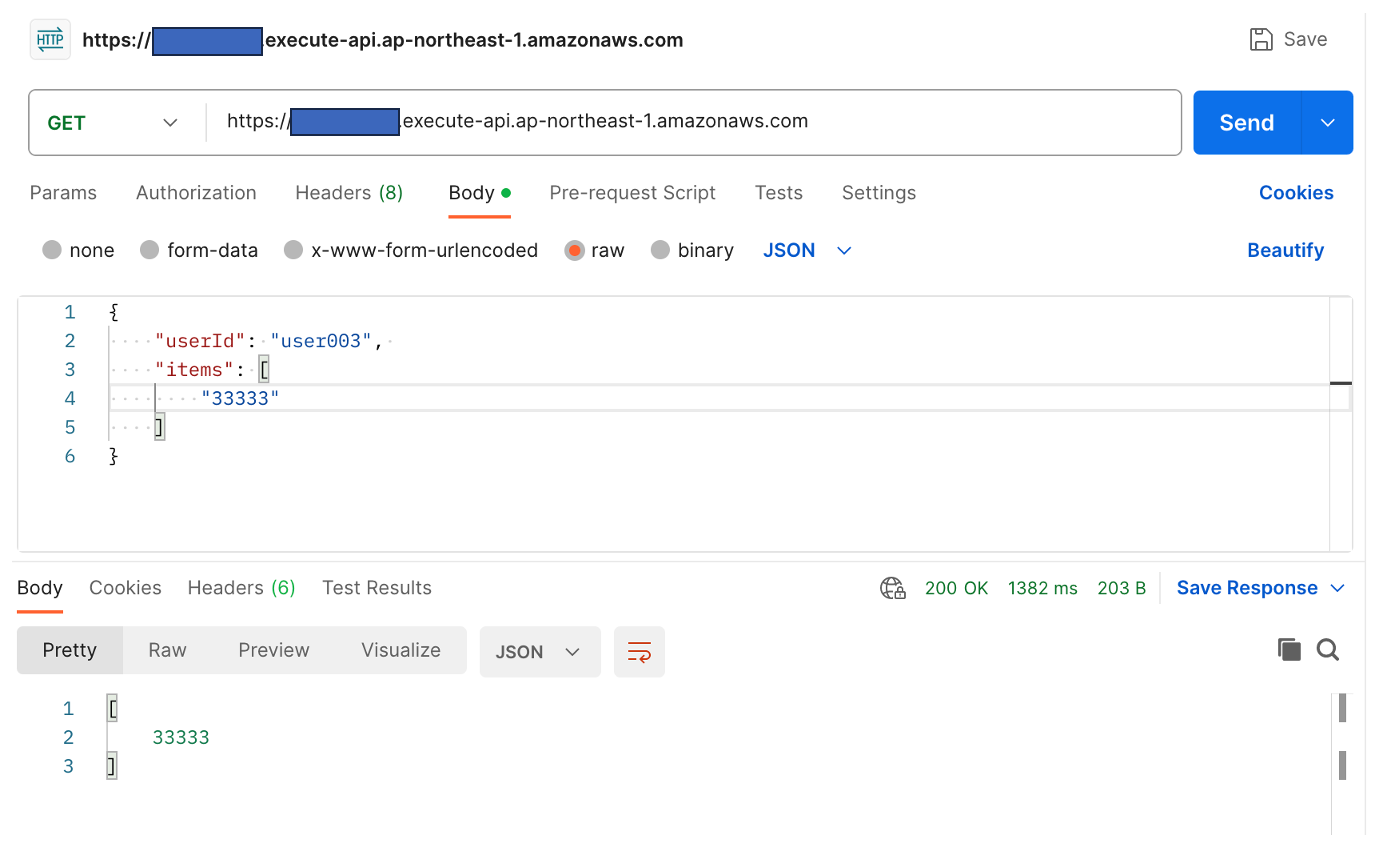
1分経過後に実行すると、変更後のテーブルのデータが更新されることが確認できました。
リクエスト
現行テーブル
変更後テーブル
パラメータ値は実行されているLambdaインスタンスのメモリ上にキャッシュされます。TTLはインスタンス単位での設定の為、タイミングによってはインスタンス毎にパラメータ値が相違する可能性がありますので注意してください。一時的にも値が異なることが許容されない場合はTTL関連値を「0」に設定してください(※)。
(参考)Caching
Parameters – Powertools for AWS Lambda (Java)※ 執筆時点のJava版においてはキャッシュ自体の無効化ができません。 多言語(Python/TypeScript/.Net)においては、キャッシュを使用せずに最新値を取得するパラメータ(forceFetch)が用意されています。
Validation
次にバリデーション機能です。この機能は、Lambdaへのインバウンド及びアウトバウンドのJSONスキーマの妥当性検証をサポートします。手順は以下の通りです。
- Validationライブラリの追加
- 検証用のJSONスキーマファイルを作成
- ハンドラーメソッドへ「Validation」アノテーションの付与
※検証するスキーマ(インバウンド/アウトバンド)とそれに対応するJSONスキーマファイルの場所を属性で指定
① Validationライブラリの追加
以下のように「Validationライブラリ」を追加します。
pom.xml
...
<dependencies>
...
<dependency>
<groupId>software.amazon.lambda</groupId>
<artifactId>powertools-validation</artifactId>
<version>1.17.0</version>
</dependency>
...
</dependencies>
...
<!-- configure the aspectj-maven-plugin to compile-time weave (CTW) the aws-lambda-powertools-java aspects into your project -->
<build>
<plugins>
...
<plugin>
<groupId>org.codehaus.mojo</groupId>
<artifactId>aspectj-maven-plugin</artifactId>
<version>1.14.0</version>
<configuration>
<source>${maven.compiler.source}</source>
<target>${maven.compiler.target}</target>
<complianceLevel>${maven.compiler.target}</complianceLevel>
<aspectLibraries>
<aspectLibrary>
<groupId>software.amazon.lambda</groupId>
<artifactId>powertools-tracing</artifactId>
</aspectLibrary>
<aspectLibrary>
<groupId>software.amazon.lambda</groupId>
<artifactId>powertools-metrics</artifactId>
</aspectLibrary>
<aspectLibrary>
<groupId>software.amazon.lambda</groupId>
<artifactId>powertools-logging</artifactId>
</aspectLibrary>
<aspectLibrary>
<groupId>software.amazon.lambda</groupId>
<artifactId>powertools-idempotency</artifactId>
</aspectLibrary>
<aspectLibrary>
<groupId>software.amazon.lambda</groupId>
<artifactId>powertools-validation</artifactId>
</aspectLibrary>
</aspectLibraries>
</configuration>
<executions>
<execution>
<goals>
<goal>compile</goal>
</goals>
</execution>
</executions>
</plugin>
...
</plugins>
</build>
② 検証用のJSONスキーマファイルを作成
クラスパス上にJSONスキーマファイルを作成します。
(今回の検証は、インバウンドのみの検証とします)
resources/request_schema.json
{
"$schema": "https://json-schema.org/draft/2019-09/schema",
"$id": "http://example.com/example.json",
"type": "object",
"default": {},
"title": "Root Schema",
"required": [
"userId"
],
"properties": {
"userId": {
"type": "string",
"default": "",
"title": "The userId Schema",
"examples": [
"user003"
]
},
"items": {
"type": "array",
"default": [],
"title": "The items Schema",
"items": {
"type": "string",
"title": "A Schema",
"examples": [
"00001",
"00002",
"00003"
]
},
"examples": [
["00001",
"00002",
"00003"
]
]
}
},
"examples": [{
"userId": "user003",
"items": [
"00001",
"00002",
"00003"
]
}]
}
③ ハンドラーメソッドへ「Validation」アノテーションの付与
ハンドラーメソッドへ「Validation」アノテーションを付与し、その属性でインバウンドのJSONスキーマファイルの場所を設定します。
・・・
@Validation(inboundSchema = "classpath:/request_schema.json")
public APIGatewayProxyResponseEvent handleRequest(final APIGatewayProxyRequestEvent input, final Context context) {
・・・
}
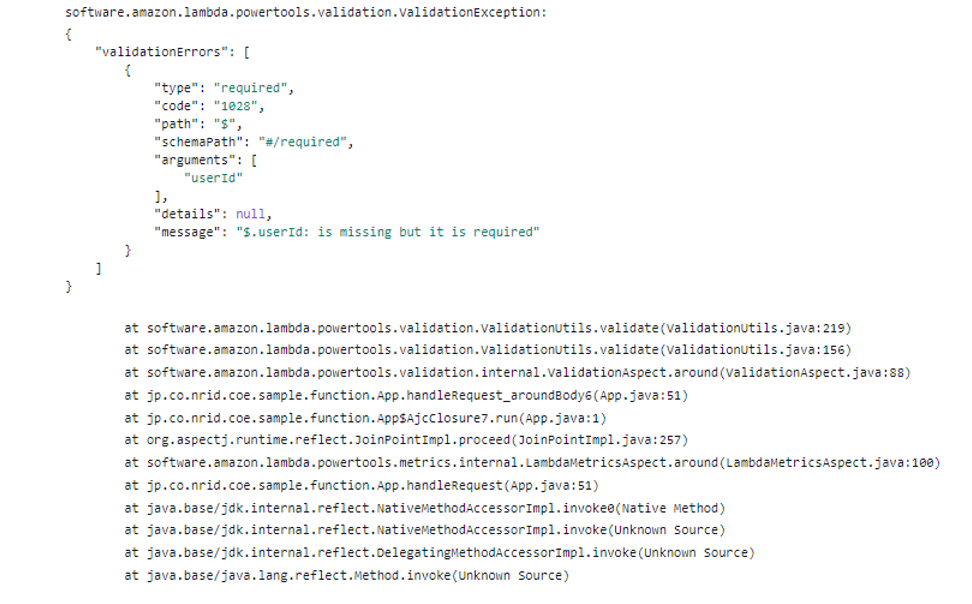
実行時、JSONスキーマ上必須となっている「ユーザID(userId)」を未設定にすると以下のように検証エラーとなることが確認できました。
Serialization Utilities
最後にシリアライズユーティリティです。これはLambdaの主要イベントコンテンツ(API Gatewayイベントなど)を簡単にオブジェクトへ簡単にデシリアライズすることができます。手順は以下です。
- Serializationライブラリの追加
- デシリアライズ実装
① Serializationライブラリの追加
以下のように「Serializationライブラリ」を依存関係に追加します。
...
<dependencies>
...
<dependency>
<groupId>software.amazon.lambda</groupId>
<artifactId>powertools-serialization</artifactId>
<version>1.17.0</version>
</dependency>
...
</dependencies>
...
② デシリアライズ実装
以下のようにインバウンドのAWS Gatewayイベントからオブジェクトへデシリアライズするコードを実装します。
・・・
import static software.amazon.lambda.powertools.utilities.EventDeserializer.extractDataFrom;
public class App implements RequestHandler<APIGatewayProxyRequestEvent, APIGatewayProxyResponseEvent> {
・・・
public APIGatewayProxyResponseEvent handleRequest(final APIGatewayProxyRequestEvent input, final Context context) {
・・・
Request request = extractDataFrom(input).as(Request.class);
・・・
}
}
※Requestクラス
public class Request implements Serializable {
private String userId;
private List<String> items;
public String getUserId() {
return userId;
}
public void setUserId(String userId) {
this.userId = userId;
}
public List<String> getItems() {
return items;
}
public void setItems(List<String> items) {
this.items = items;
}
}
以下のような入力で実行すると、Requestオブジェクトへ正常にデシリアライズされることが確認できました。
{
"userId": "user001",
"items": [
"11111",
"22222"
]
}
このようなシリアライズユーティリティは3rd Partyのライブラリなど含め多数存在します。ただ、本機能の意義は、上記コードのように、Lambdaのイベントコンテンツをユーティリティメソッドへ渡すだけで所望の情報でデシリアライズできることだと思います(内部構造を理解してブレイクダウンするなどの必要はありません)。
さいごに
Powertoolsの「Core Utilities」及び「Helper Utilities」の主要機能について簡単に検証してみました。両ユーティティともにサーバレスを本番環境で稼働させる為に必要な機能が備わっていると思いました。また、使用方法もそれほど難しくない為、既存機能への影響も少なく組み込み可能と思います。アプリケーション開発者はメインとなる業務機能の開発に専念し、それ以外のサポート機能をユーティリティフレームワークに寄せられることは非常にメリットがあることだと感じました。Powertoolsの利用自体は無償の為、是非一度お試しいただければと思います。
以上