GPTsで手軽にRAGを構築する
こんにちは、NRIデジタルの湯川です。
2023年10月末から11月はAI関連のイベントが多く、重要な発表が多数行われました。
OpenAI DevDay 2023年11月6日
・New models and developer products announced at DevDay
・Introducing GPTs
Microsoft Ignite 2023年11月15から17日
・マイクロソフト Ignite 2023 ニュースブック
イベントのあとで発生したOpenAIのアルトマン氏のCEO退任とCEO復帰が大きな出来事として報じられ、若干霞んでしまったようなところもありますが、OpenAIが発表したGPTs、Assistants API、GPT4-Vなどはいずれも画期的な内容で、MicrosoftのCopilot Studioも企業内での生成AIの活用を加速させるものだったと思います。
今回はGPTsを活用したRAG(Retrieval Augmented Generation)を試してみたので、GPTsを使わない場合との比較をしながら、GPTsがどのように画期的なのかをご紹介したいと思います。
RAG(Retrieval Augmented Generation)とは
RAGはデータベースに保存した一般には公開されていないデータを、生成AIモデルが回答を作る際に参照させて、組織に固有の回答を生成する仕組みです。
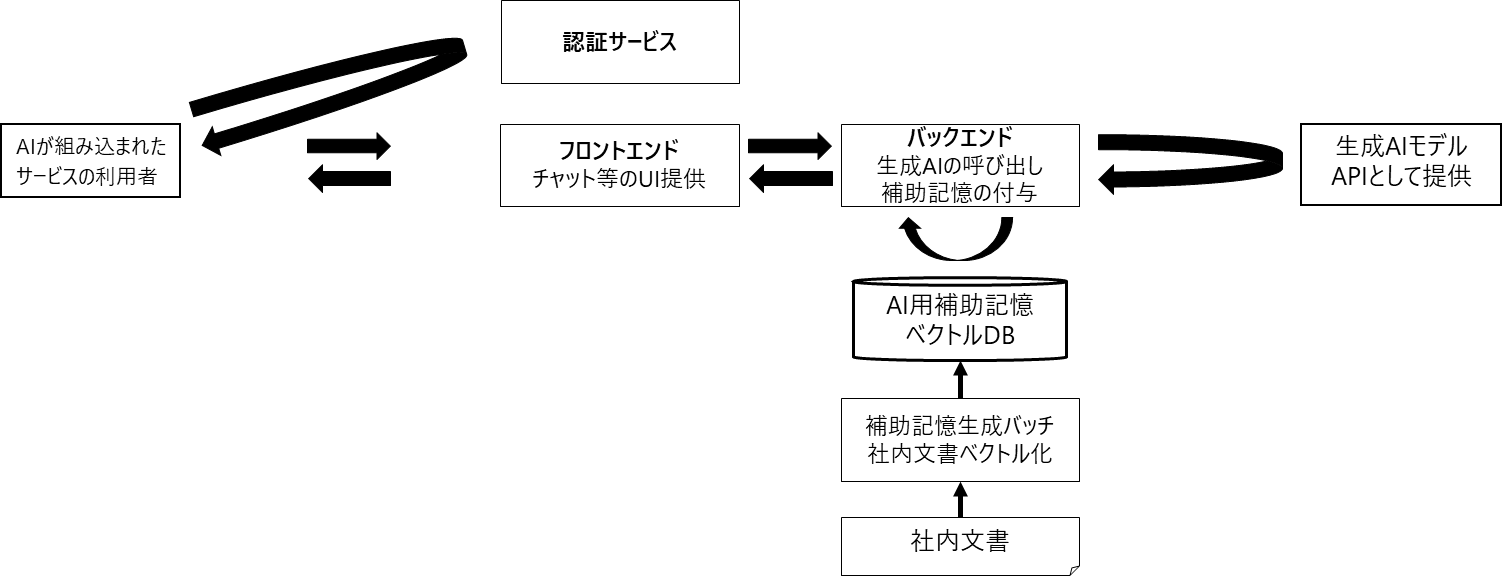
RAGを実装し、専用のAIチャットを作るためには様々なものを作る必要があります。
フロントエンド
一回で完璧な応答が返されるとは限らないため、チャット機能を持ったUIを作ることが多いと思います。
認証サービス
ユーザ名やパスワードの認証をこのシステムのために専用に作りこむよりも、利便性やセキュリティなどの観点からAzure ADなどの認証サービスとの連携することが多いのではないかと思います。
バックエンド
データベースから質問と関連性のあるドキュメントを抽出し、生成AIモデルに抽出したドキュメントを与えて回答を作らせます。
特にGPT-4は応答が遅いので、ストリームで応答を逐次的にフロントに返すことが多いと思います。
AI用補助記憶(データベース)
RAG用のデータベースには文脈的な一致による検索ができるものが望ましいため、ベクトル検索(言葉をベクトル化し距離が近いものを抽出することで意味的に近いものを検索する技術)ができるものが広く用いられています。
生成AIモデル
GPT-3.5やGPT-4などの生成AIモデルはAPIとして提供されていますが、これらはステートレスなものとして提供されています。
会話の履歴も保持してくれないので、毎回バックエンドから渡す必要があります。
※先日のOpenAIのイベントで発表されたAssistants APIでは会話の履歴を保持させることができます。
(これまで)RAG環境を作る方法
RAGの環境を作るのはすごく難しいわけではありません。
GithubにはMicrosoftから簡単にRAG環境を立ち上げるためのコードが提供されていて、READMEに書かれている手順に従えば環境を構築することができます。私が特に参考にさせていただいているのが以下の2つのです。
Azure-Samplesのazure-search-openai-demoは日本のMicrosoftの方々が派生版を作って公開されているものもあります。
以下の図はMicrosoftの阿佐さんのリポジトリからの引用ですが、この図のような環境は簡単に構築できます。
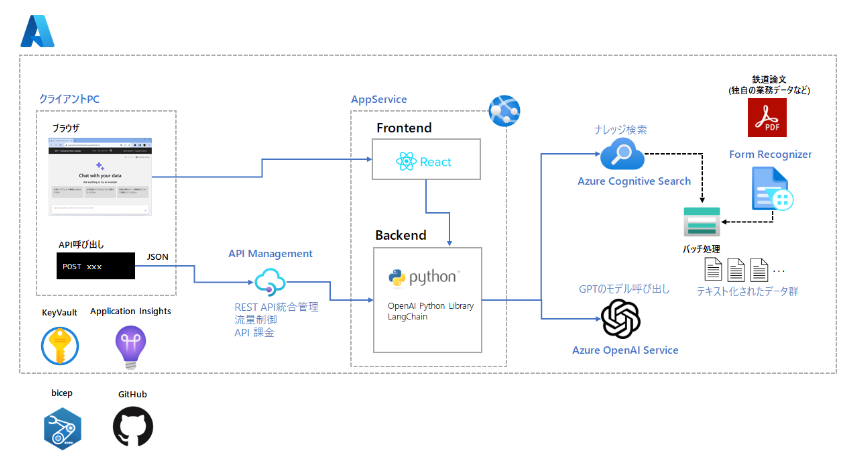
とりあえず試せる環境はMicrosoftから提供されているコードを使うことですぐに構築できます。かかっても数時間程度の作業で、慣れていれば1時間もかかりません。
ただ、簡単なのは何も改変しようと思わない場合の話です。中身を改変しようとすると急にハードルが高くなります。
- フロントをいじろうとするとReactの知識が必要です。
- バックエンドをいじろうとするとPythonの知識が必要です。
- AppServiceではなくStatic Web AppsとContainerAppsの組み合わせに変更したければAzureの知識とbicepの知識が必要です。
RAG環境は様々な技術要素の組み合わせでできたそれなりにちゃんとした仕組みでできているので当たり前といえば当たり前なのですが、ちゃんと作るのはそれなりに大変です。
(これから)GPTsを使ってRAG環境を作る方法
GPTsを使う場合はRAG環境を作る手間は大幅に削減されます。
GPTsからAPIを呼び出すことができるので、この必要な独自ナレッジの検索用APIさえ作れば、フロントエンドやバックエンドなどはサービスとして提供されているものを使うことができます。独自の挙動をさせたい部分のみを作れば良いということなので非常にお手軽です。
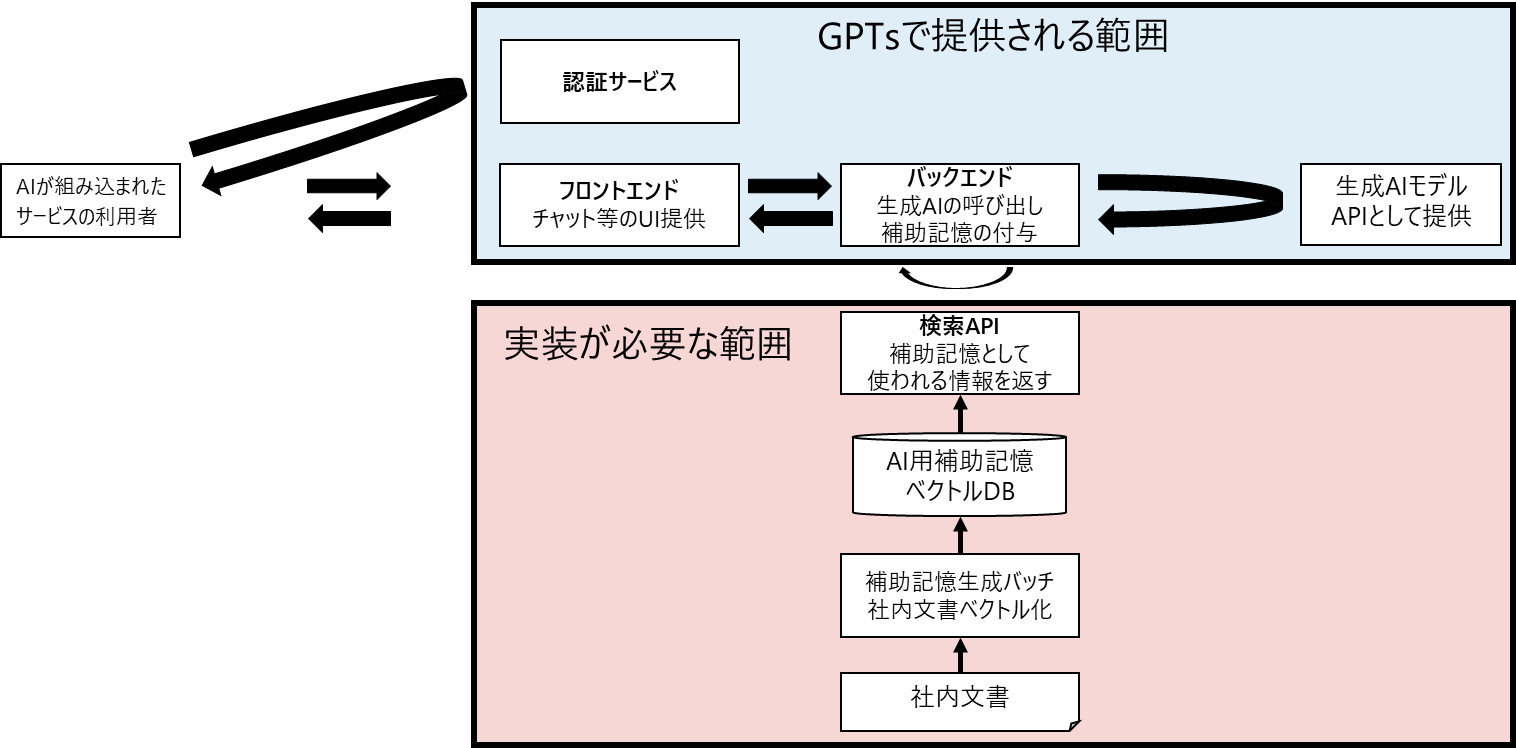
GPTsを使ったRAGを作ってみる
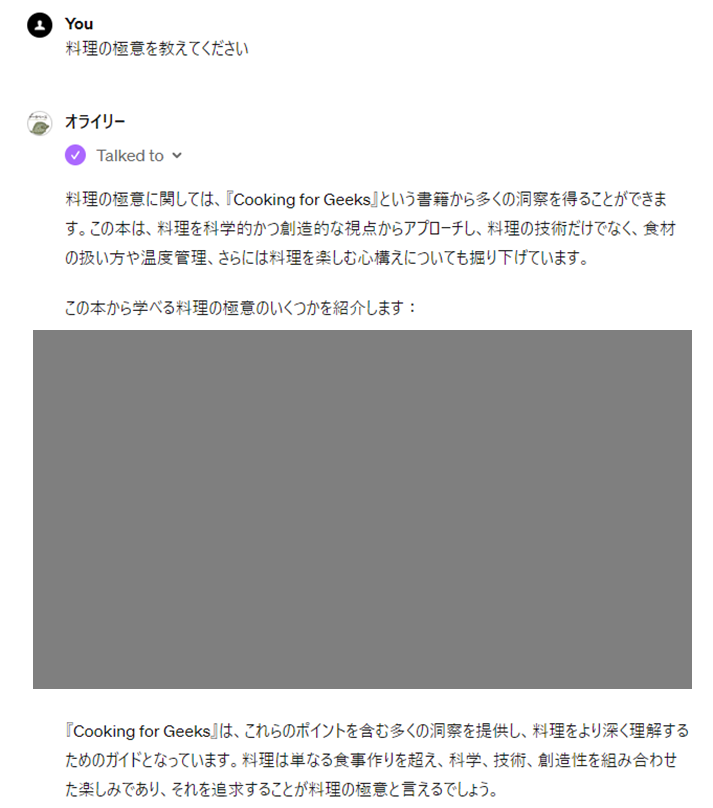
GPTsは公開しない自分専用のものを作ることができるので、今回は個人的に持っていたオライリーの電子書籍40冊をベクトル化し、これを与えたRAGを作ってみました。完成後のAIとのやりとりは以下のような感じです。著作権があるので書籍の内容は伏せました。
ChatGPT側の準備
ChatGPT Plusのサブスクリプションが必要なのでまず課金します。
ブラウザからChatGPTを開くと左メニューにExplorerというのが追加されていると思います。
これをクリックすると以下のような画面が出てきます。
![]()
+ボタンをクリックし、表示された画面でConfigureを選ぶとAIの振る舞いをカスタマイズする画面が出てきます。

オライリーRAGの場合は以下のように設定しました。
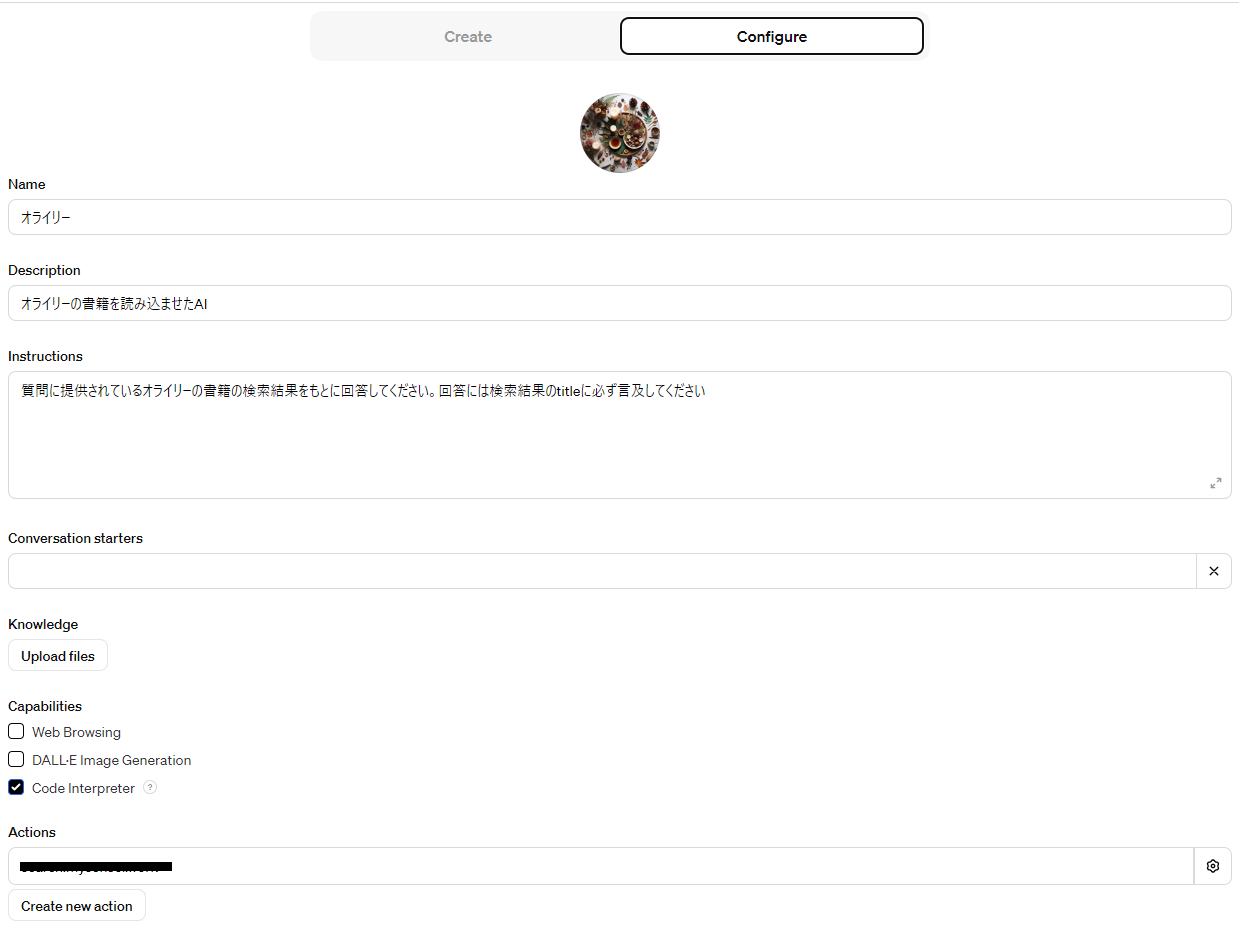
API呼び出しができるようにActionsの設定をします。記載する必要があるのはSchemaとAuthenticationだけです。
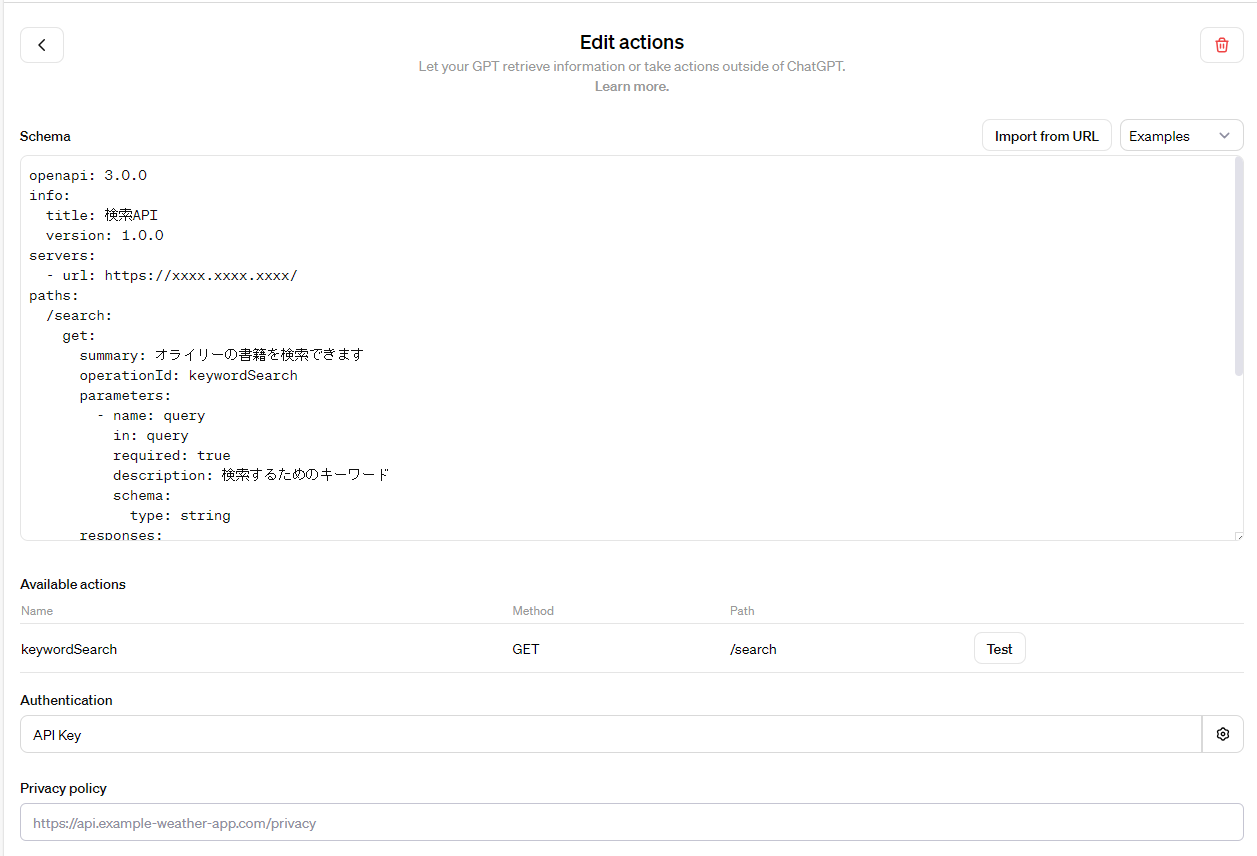
Schemaには以下のように記載しました。
openapi: 3.0.0
info:
title: 検索API
version: 1.0.0
servers:
- url: https://xxxx.xxxx.xxxx/
paths:
/search:
get:
summary: オライリーの書籍を検索できます
operationId: keywordSearch
parameters:
- name: query
in: query
required: true
description: 検索するためのキーワード
schema:
type: string
responses:
'200':
description: 検索結果
content:
application/json:
schema:
type: object
properties:
title:
type: string
description: ドキュメントのタイトル
page_content:
type: string
description: ドキュメントの本文
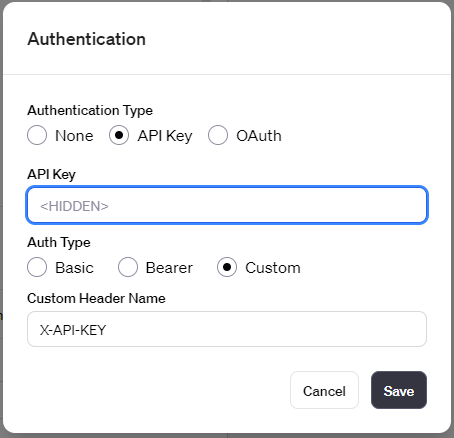
AuthenticationにはAPI Keyを選択し、ヘッダ名とKeyの値を入れました。
Available actionsのTestを押してみましょう。

AIが適当な質問を自分で作ってAPIのテスト呼び出しを試みてくれます。
いまはまだ呼び出す対象のAPIがないので、エラーになるはずです。
ベクトル検索用のDBを用意する
今回はベクトル検索用のDBにpostgresqlにpgvectorを入れたものを使うことにします。
FROM postgres:15.3
RUN apt-get update && \
apt-get install -y --no-install-recommends \
build-essential \
curl \
postgresql-server-dev-all && \
localedef -i en_US -c -f UTF-8 -A /usr/share/locale/locale.alias en_US.UTF-8
RUN apt install -y postgresql-15-pgvector
試しに作成したものなので、APIもDBもお手軽にdocker composeを使って構築しましたが、先日のIgniteでpgvector 0.5.1のFlexible Serverでのサポートが発表されました。本格的に利用する場合はこちらを利用するか、Azure AI Search(旧:Azure Cognitive Search)を用いることになると思います。
書籍をベクトル化する
テキストのベクトル化にはOpenAIのtext-embedding-ada-002を用います。
unstructuredはpdfにも対応しているのですが、フォーマットエラーになってしまったので、pdfminerを使っています。
import os
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores.pgvector import PGVector
from langchain.text_splitter import CharacterTextSplitter
from pdfminer.high_level import extract_text
from unstructured.partition.auto import partition
embeddings = OpenAIEmbeddings(
openai_organization=os.environ["OPENAI_ORGANIZATION"],
openai_api_key=os.environ["OPENAI_API_KEY"],
model="text-embedding-ada-002")
DATABASE_URL = os.environ["PGVECTOR_DATABASE_URL"]
store = PGVector(connection_string=DATABASE_URL,
collection_name=os.environ["PGVECTOR_DATASETNAME"],
embedding_function=embeddings)
text_splitter = CharacterTextSplitter(separator="\n\n", chunk_overlap=128)
books = [
{
"title": "書籍名",
"path": "ファイル名"
},
]
for book in books:
# 拡張子がepubの場合
if book["path"].endswith(".epub"):
path = os.path.join("./epub", book["path"])
results = [str(result) for result in partition(path)]
# 拡張子がpdfの場合
elif book["path"].endswith(".pdf"):
path = os.path.join("./pdf", book["path"])
results = extract_text(path).split("\n")
else:
pass
# 200文字以下の場合は前の文と結合する
buffers = []
buf = ""
for s in results:
if len(buf) + len(s) < 198:
buf = ". ".join([buf, s])
else:
buffers.append(buf)
buf = s
# 最後に残ったものを追加
buffers.append(buf)
# 改行区切りで連結
text = "\n".join(buffers)
# 最終的なチャンク処理はオーバーラップをさせたいのでCharacterTextSplitterに任せる
docs = text_splitter.split_text(text)
print(book["title"], len(docs))
store.add_texts(docs,
metadatas=[{
"title": book["title"]
} for _ in range(len(docs))])
検索APIを作る
ベクトル化したデータを検索できるWebのAPIを作ります。
import logging
import os
from quart import (
Blueprint,
Quart,
abort,
jsonify,
request,
)
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores.pgvector import PGVector
embeddings = OpenAIEmbeddings(
openai_organization=os.environ["OPENAI_ORGANIZATION"],
openai_api_key=os.environ["OPENAI_API_KEY"],
model="text-embedding-ada-002")
DATABASE_URL = os.environ["PGVECTOR_DATABASE_URL"]
store = PGVector(connection_string=DATABASE_URL,
collection_name=os.environ["PGVECTOR_DATASETNAME"],
embedding_function=embeddings)
bp = Blueprint("routes", __name__, static_folder='static')
@bp.route("/search", methods=["GET"])
async def search():
headers = request.headers
if "X-API-KEY" not in headers:
abort(401)
api_key = headers["X-API-KEY"]
if api_key != os.environ["API_KEY"]:
abort(401)
if "query" not in request.args:
abort(400)
query = request.args.get("query")
try:
result = store.similarity_search_with_score(query, k=2)
return jsonify([{
"title": doc.metadata["title"],
"page_content": doc.page_content
} for (doc, _) in result]), 200
except Exception as e:
logging.exception("Exception in /search")
return jsonify({"error": str(e)}), 500
def create_app():
app = Quart(__name__)
app.register_blueprint(bp)
return app
これだけです!
GPTsから検索APIを呼び出す
GPTsから検索APIを呼び出してみましょう。以下のような応答が返るはずです。

最後に
今回ご紹介したようにGPTsを使えばUIや認証はChatGPTのものを流用することができるので、これまでよりもかなり少ない労力でRAGを実現することができます。
UIや認証をカスタマイズしたいけどベクトル検索の部分を省力化したい場合はどうしたらよいのでしょう。その場合はAssistants APIを使うことができそうです。Assistants APIはこれまでと異なりAPI側で状態を持つことができ、会話の履歴や補助記憶用のデータを持たせることができます。
生成AI関連は進歩が非常にはやいので引き続きウォッチしていきたいと思います。