Snowflake Dynamic Tables による大規模ニアリアルタイム処理に向けた基礎検証
1.はじめに
Snowflake を用いたデータ分析基盤の構築案件が増えており、筆者も参画しています。近年では扱うデータ量として、RAWデータ、および、ETL処理を行うデータに関しては、100TBオーダーからPBオーダーになってきています。担当案件でも、1年間でETL処理のパイプラインを通過するデータの総量は約1PBという目標で進めています。
これだけのデータ量であっても、データの鮮度に関して、数年前から見ると高いレベルが求められている印象を受けます。担当しているプロジェクトでも目標値ではありますが、遅れが5分以内のニアリアルタイムでの鮮度を目指すという話が聞こえ始めました。
一方、SnowflakeのETL処理向けの新機能として、Dynamic Tables という機能がパブリックプレビューとして利用可能になっています。詳細は後続の章に記載しますが、データ変換の結果になる変換後テーブルをDynamic Tablesとして定義すると、ソースデータに更新がかかったときに、その変更を変換後テーブルにSnowflake側で自動で反映してくれる機能になります。従来このような仕組みを構築するには、Snowflakeの複数の機能を組み合わせる、もしくは、履歴テーブルと最新ビューを定義してUNIONする等、工夫が必要でした。
ETL処理の開発生産性、運用効率性を考えると、GA(General Availability、正式公開)後はDynamic Tablesを利用していきたいと考えています。今回の記事では、Snowflake Dynamic Tablesを用いて、仮に1年間1PBのデータ流量、5分以内の遅延を想定した場合に、現実的に実現可能なのか、可能な場合どの程度のリソースを要するのか 、検証していきたいと考えています。検証内容が基礎的な内容になること、および、幾分プロジェクト固有の部分が含まれるかと思いますが、少しでもDynamic Tablesの活用を検討している方の参考になれば幸いです。
2.そもそもPBとは
ここでは、1PBというデータ量について、少し触れておきたく思います。筆者も当初はTBの次の単位、ぐらいの認識でしかなく、具体的にイメージが持てませんでした。下記、通常よくあるケースに1PBという量を当てはめて整理しています。筆者と同じようにイメージ持てない方いらっしゃいましたら、その助けになれば幸いです。
|
ケース |
結果 |
根拠など |
|---|---|---|
|
S3にデータを保存すると |
保管するだけで月額約300万円 |
・S3標準ストレージ、AWS東京リージョン 0.023USD/GB ・為替1ドル135円を想定 |
|
Snowflake(内部テーブル)に保存すると |
保管するだけで月額約600万円 |
・オンデマンドストレージ(AWS、東京リージョン)月額$46/TB ・為替1ドル135円を想定 |
|
S3にデータを転送すると |
約90日かかる。 |
・1Gbps、伝送効率100%を想定 ・1PB=1,000TB=1,000,000GB=8,000,000Gb ・8,000,000Gb/1Gbps/60/60/24≒92.5日 |
|
レコード件数に直すと |
約100億件オーダー |
・1レコード100Bを想定 |
今回はこの量を貯め込んだり、クエリしたり、ということをするわけではありませんが、実際のプロジェクトでも、この量を扱うようになってきている、扱うことを要求されるようになってきている、ということと捉えていただければと思います。
3.Snowflake Dynamic Tablesの概要
Dynamic Tablesは、変換後の状態を定義することで、ソースデータに行われた更新を変換後のテーブルに反映する一連のプロセスをSnowflake側でマネージドしてくれる機能です。例えば、下記のように定義します。
CREATE OR REPLACE DYNAMIC TABLE NEW_SENSOR_DYNAMIC_TABLE TARGET_LAG = '1 minute' WAREHOUSE = WH_XS AS SELECT TIMESTAMP, CAR_NUMBER, LAPS, MODEL, ENGINE_RPM, SPEED, MANUAL, ENGINE_TEMP, FUEL, AMBIENT_TEMP, BAROMETRIC_PRESSURE, MAF, TYPE, INTAKE_TEMP, LONGITUDE, LATITUDE FROM NEW_SENSOR;
実際には、上記のSELECT句の中に変換処理を記載する形になります。上記の例であれば、2行目のTARGET_LAGで指定した時間間隔1分で、ソースデータであるNEW_SENSORテーブルの更新内容を、変換後のテーブルであるNEW_SENSOR_DYNAMIC_TABLEに反映する、といった記述になります。
下記の公式ドキュメントにもある通り、同じことをDynamic Tablesを利用せずに実現しようとすると、STREAMとTASKを定義して、TASKの中でソーステーブルのDMLイベントを検知して、DML種類ごとの処理を実装する、というように複雑な実装が必要になります。大量データを流していくデータパイプラインでは、DML毎に個別の操作が必要となる状況は少ないと考えられるため、得られる生産性向上と運用効率化のメリットのほうが大きいのではないかと考えています。
Dynamic tables | Snowflake Documentation
また、FROM句に先行するDynamic Tablesを指定することで、多段に構成して、ETLパイプラインを構築することができます。Snowflake上では、下記のようにDAGを確認することが可能です。
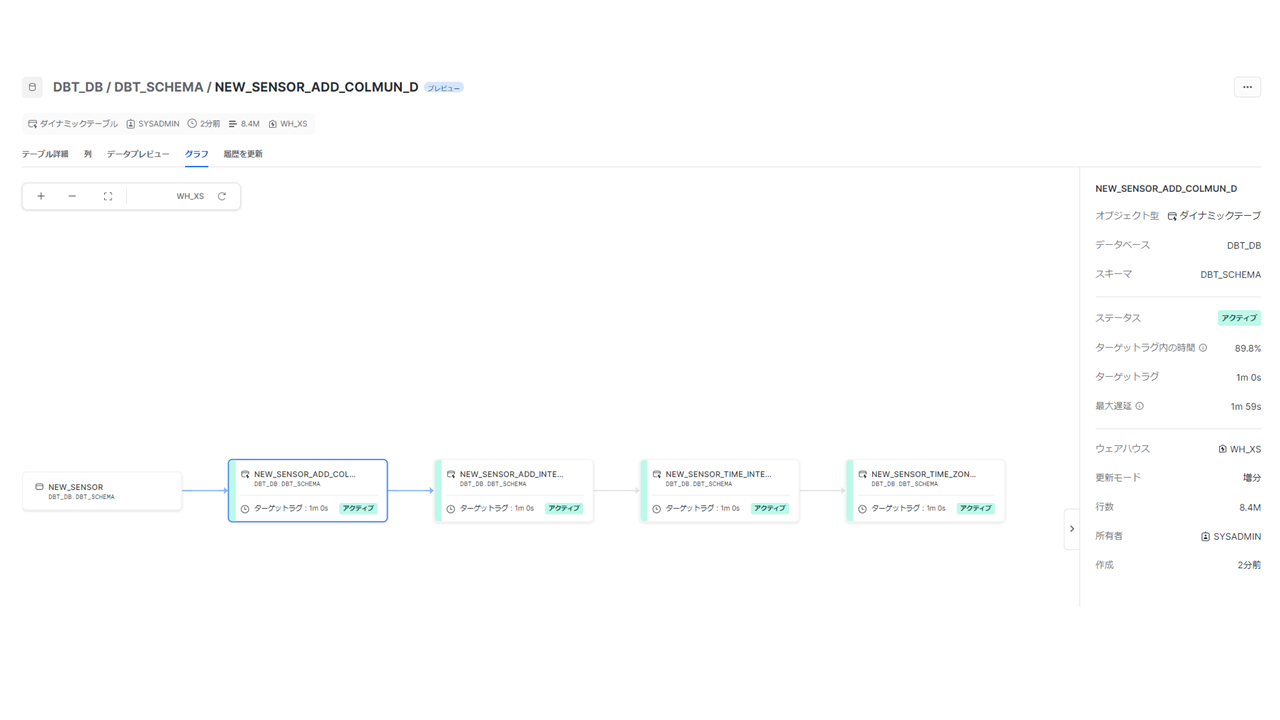
現実には、上記のような多段の構成や、分岐を持つ複雑な構成になりますが、今回は基礎的な検証となるため、検証はソーステーブルから1段のDynamic Tables構成で進めていきます。
4.検証内容
ここでは、検証に用いた環境やデータについて記載しています。
4-1.構成概要
検証に用いた環境構成は、下記の通りです。詳細については、後続の章に記載します。
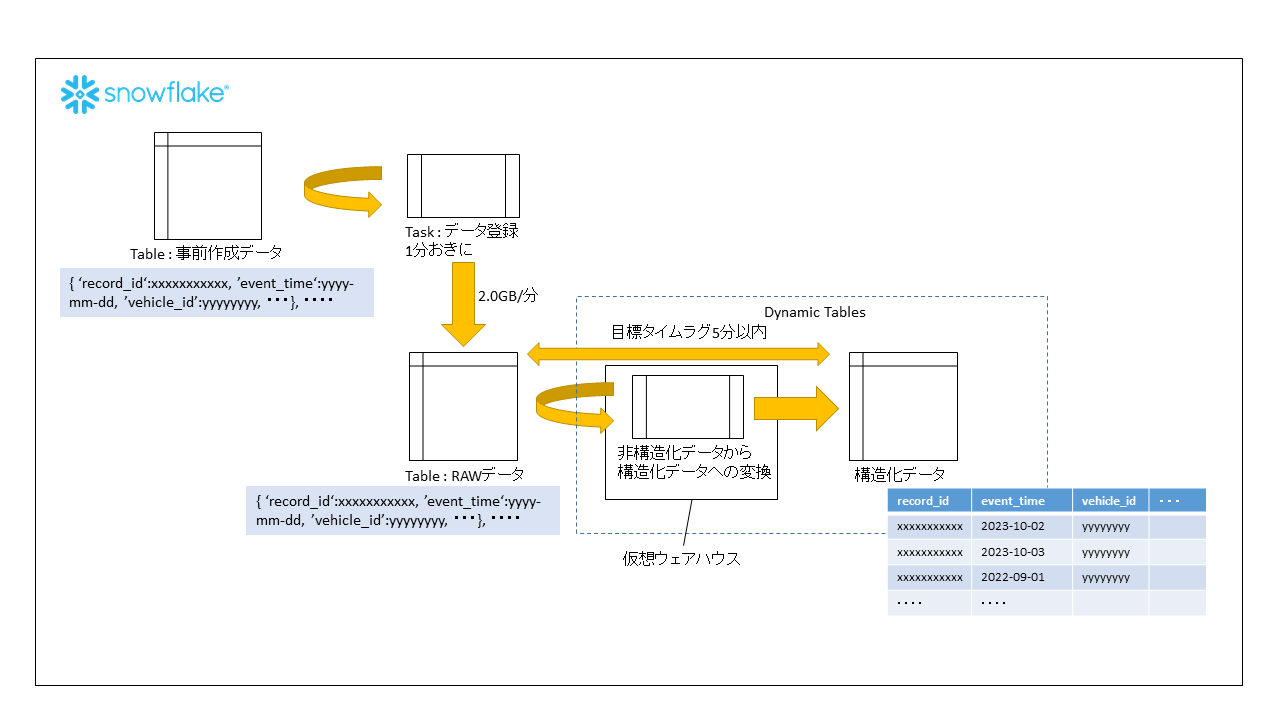
4-2.数値情報の整理
今回データ量としては、1年間で1PBのデータ流入を想定します。これは、1分間約2.0GBのデータが流入することに相当するため(1PB=1,000TB=1,000,000GB, 1,000,000/365/24/60≒1.9GB≒2GB)、今回の検証ではこのレートでRAWデータにデータを流入させていきます。
また、ニアリアルタイムの定義については、現在プロジェクトで目標にしている遅延5分以内、を設定して進めたいと思います。
|
分類 |
数値 |
根拠 |
|---|---|---|
|
パイプラインを通過するデータの総量 |
1PB/年 |
現在のプロジェクト目標 |
|
ニアリアルタイムの基準 |
遅延5分以内 |
現在のプロジェクト目標 |
|
RAWデータの流入レート |
2GB/分 |
1PB=1,000TB=1,000,000GB, 1,000,000/365/24/60≒1.9GB≒2GB |
4-3.データの定義
データの定義としては、下記のような車両センサデータを想定します。キーとなるセンサーのイベント時刻、車両のIDや緯度経度などの情報と、100個程度の浮動小数点型の数値情報から構成される想定とします。
|
項目 |
型 |
|---|---|
|
record_id |
string |
|
event_time |
timestam_ltz |
|
car_number |
number |
|
laps |
number |
|
model |
string |
|
engine_rpm |
float |
|
speed |
float |
|
manual |
string |
|
engine_temp |
float |
|
fuel |
float |
|
ambient_temp |
float |
|
barometric_pressure |
float |
|
maf |
float |
|
type |
string |
|
intake_temp |
float |
|
longitude |
float |
|
latitude |
float |
|
_created_at |
timestam_ltz |
|
sensor_value_001 |
float |
|
・・・ |
|
|
sensor_value_100 |
float |
4-4.データの準備
出発地点になるRAWデータは、下記のように準備します。RAWデータの段階では構造は持たないため、半構造化データの形式とします。
create or replace transient table raw_data as
select
object_construct(
'record_id', uuid_string(),
'event_time', dateadd(sec, 0 - abs(random())%1000000, current_timestamp)::timestamp_ltz,
'car_number', abs(random())%10000,
'laps', abs(random())%100,
'model', randstr(5, random()),
'engine_rpm', uniform(0::float, 1::float, random()),
'speed', uniform(0::float, 1::float, random()),
'manual', randstr(5, random()),
'engine_temp', uniform(0::float, 1::float, random()),
'fuel', uniform(0::float, 1::float, random()),
'ambient_temp', uniform(0::float, 1::float, random()),
'barometric_pressure', uniform(0::float, 1::float, random()),
'maf', uniform(0::float, 1::float, random()),
'type', randstr(5, random()),
'intake_temp', uniform(0::float, 1::float, random()),
'longitude', uniform(0::float, 1::float, random()),
'latitude', uniform(0::float, 1::float, random()),
'_created_at', dateadd(sec, 0 - abs(random())%1000000, current_timestamp)::timestamp_ltz,
'sensor_value_001', uniform(0::float, 1::float, random()),
'sensor_value_002', uniform(0::float, 1::float, random()),
############## 003 - 099 は省略します。##############################
'sensor_value_100', uniform(0::float, 1::float, random())
)::variant as source
from
table(generator(rowcount => 2500000));
4-5.データ流入タスクの準備
今回の検証では、プロジェクト内で扱うデータの特性に合わせて時系列の単純追記型のデータを想定しています。データの流入に関しては、事前に流し込むデータを生成して別テーブルに格納しておき、そのデータをRAWテーブルに流し込む形としました。この形にしたのは、生成しながら流し込むことも何度か試行しましたが、2.0GB/分のレートを満たせなかったためです。また、今回のデータ構造では、250万レコードで約2GBの容量となります。
############## 流入させるデータの事前作成 ##############################
create or replace transient table tran_data as
select
object_construct(
'record_id', uuid_string(),
'event_time', dateadd(sec, 0 - abs(random())%1000000, current_timestamp)::timestamp_ltz,
'car_number', abs(random())%10000,
'laps', abs(random())%100,
'model', randstr(5, random()),
'engine_rpm', uniform(0::float, 1::float, random()),
'speed', uniform(0::float, 1::float, random()),
'manual', randstr(5, random()),
'engine_temp', uniform(0::float, 1::float, random()),
'fuel', uniform(0::float, 1::float, random()),
'ambient_temp', uniform(0::float, 1::float, random()),
'barometric_pressure', uniform(0::float, 1::float, random()),
'maf', uniform(0::float, 1::float, random()),
'type', randstr(5, random()),
'intake_temp', uniform(0::float, 1::float, random()),
'longitude', uniform(0::float, 1::float, random()),
'latitude', uniform(0::float, 1::float, random()),
'_created_at', dateadd(sec, 0 - abs(random())%1000000, current_timestamp)::timestamp_ltz,
'sensor_value_001', uniform(0::float, 1::float, random()),
'sensor_value_002', uniform(0::float, 1::float, random()),
############## 003 - 099 は省略します。##############################
'sensor_value_100', uniform(0::float, 1::float, random())
)::variant as source
from
table(generator(rowcount => 2500000));
2.0GB/分のレートでのデータ流し込みは、Taskで実装しています。また、検証の際には、このタスクの完了時間が1分を超えず、2.0GB/分のレートで流入できていることを合わせて確認します。
create task tran_to_raw warehouse = WH_XS schedule = '1 minute' as insert into raw_data select * from tran_data;
4-6.Dynamic Tables作成
RAWデータに対してDynamic Tablesを作成します。下記のSQLで作成しています。target_lagでDynamic Tablesの更新間隔、warehouseで更新に使用する仮想ウェアハウスのサイズを指定しています。また、今回はRAWデータの半構造化データを解いて、構造化データに変換する処理をSELECT句で指定する形としています。
create or replace dynamic table test_dynamic_table
target_lag = '5 minute'
warehouse = WH_XS
as
select
source:record_id::string as record_id,
source:event_time::timestamp as event_time,
source:car_number::number as car_number,
source:laps::number as laps,
source:model::string as model,
source:engine_rpm::float as engine_rpm,
source:speed::float as speed,
source:manual::string as manual,
source:engine_temp::float as engine_temp,
source:fuel::float as fuel,
source:ambient_temp::float as ambient_temp,
source:barometric_pressure::float as barometric_pressure,
source:maf::float as maf,
source:type::string as type,
source:intake_temp::float as intake_temp,
source:longitude::float as longitude,
source:latitude::float as latitude,
source:_created_at::timestamp as created_at,
source:sensor_value_001::float as sensor_value_001,
source:sensor_value_002::float as sensor_value_002,
############## 003 - 099 は省略します。##############################
source:sensor_value_100::float as sensor_value_100
from
raw_data;
ここまでの準備により、下記のようなDAGが構成されます。今回はこの環境で検証を進めます。
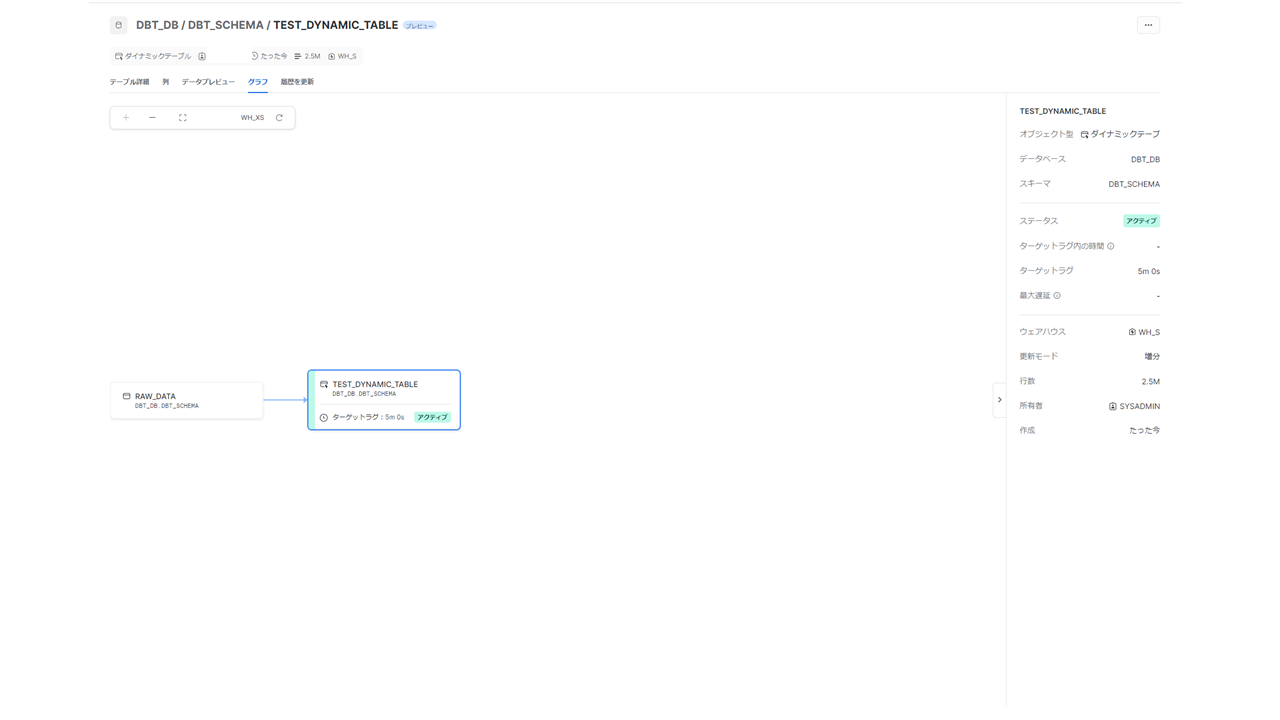
4-7.検証方法と評価方法
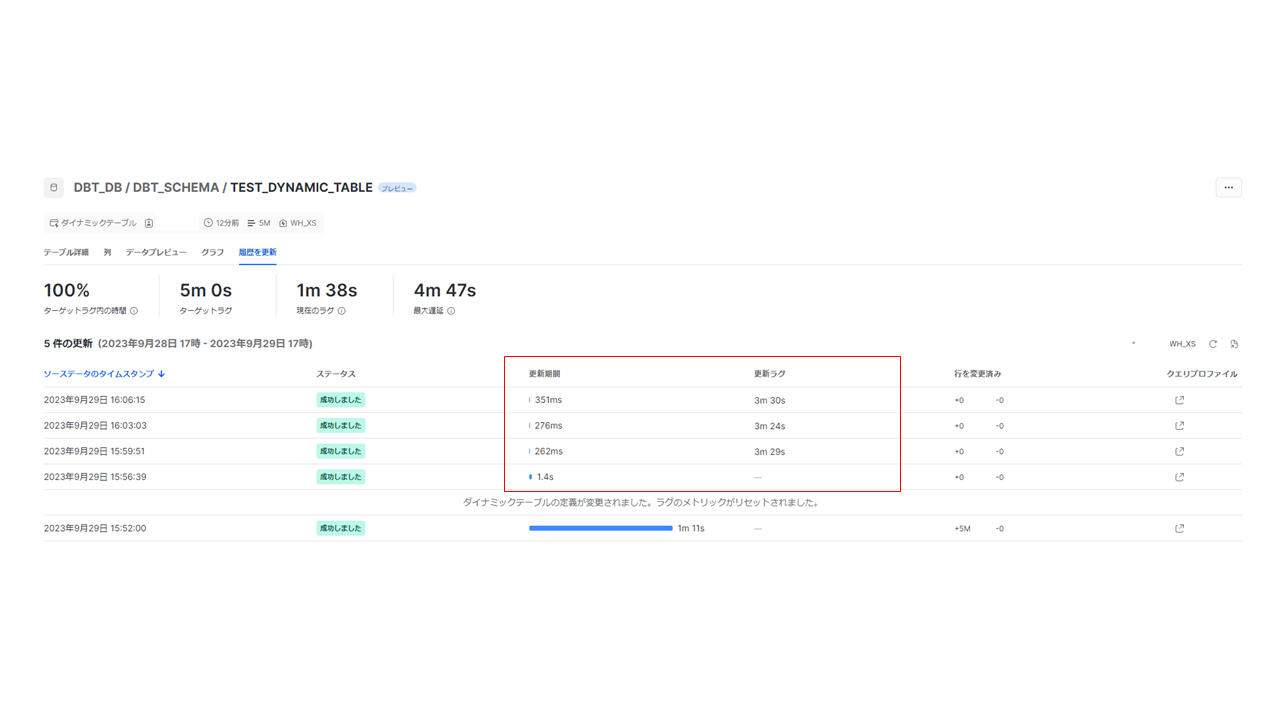
検証方法としては、先のタスクを実行した状態で、合計5回の連続したDynamic Tablesの更新状況を取得します。取得できる項目としては、更新期間(1回の更新に要した時間)と更新ラグ(データの遅延)がありますので、こちらを評価していきます。実機で確認したところ、ターゲットラグを5分とした場合、Dynamic Tablesは約3分30秒おきに、更新がかかっている状況でしたので、更新期間(1回の更新に要した時間)については、1分30秒を評価の基準として設定していきます。更新ラグは、ターゲットラグとして設定した5分を超過するかどうか、で評価します。
仮想ウェアハウスのサイズは、XSから最大で6XLまであります。今回の検証では、XSから順に上げていき、2サイズ区分連続で更新遅延5分以内を満たせたところで、それ以上のサイズでも実現できるとみなして、検証をストップします。
参考)ウェアハウスの概要 | Snowflake Documentation
5.検証結果
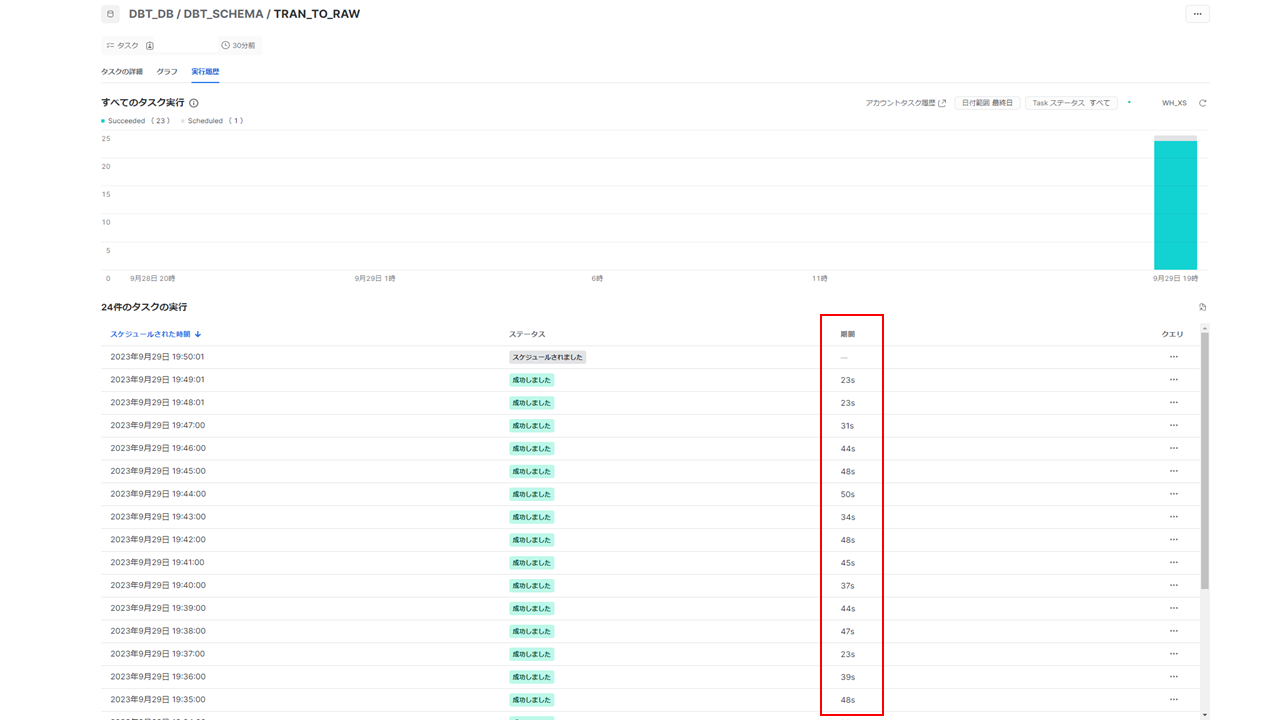
以後で検証結果を記載しますが、それらの前提として、データが想定のレートで流入できていることを確認します。データを流入させるタスクが1分以内に完了していることを、具体的には、下記画面の期間列の値が60s以内に収まっていることを確認しています。
検証の結果は、下記のようになります。計測値は「分 : 秒」としています。
|
仮想ウェアハウスサイズ |
||||
|
XS |
S |
M |
||
|
更新期間 |
1回目 |
2:56 |
1:07 |
0:48 |
|
2回目 |
2:42 |
1:08 |
0:34 |
|
|
3回目 |
3:05 |
1:06 |
0:34 |
|
|
4回目 |
3:02 |
1:06 |
0:32 |
|
|
5回目 |
3:58 |
1:07 |
0:36 |
|
|
平均 |
3:09 |
1:07 |
0:37 |
|
|
最大 |
3:58 |
1:08 |
0:48 |
|
|
最小 |
2:42 |
1:06 |
0:32 |
|
|
更新ラグ |
1回目 |
6:18 |
4:38 |
4:12 |
|
2回目 |
6:04 |
4:36 |
3:55 |
|
|
3回目 |
6:25 |
4:32 |
4:02 |
|
|
4回目 |
6:29 |
4:30 |
3:59 |
|
|
5回目 |
7:24 |
4:39 |
4:04 |
|
|
平均 |
6:32 |
4:35 |
4:02 |
|
|
最大 |
7:24 |
4:39 |
4:12 |
|
|
最小 |
6:04 |
4:30 |
3:55 |
|
1年間1PBに相当する2GB/分の流入データに対して、仮想ウェアハウスのサイズがXSの場合は、5分以上の遅延が発生していますが、S以上の仮想ウェアハウスサイズにすると、5分以内に収まっていることがわかります。仮想ウェアハウスの実行時間は、そのまま課金対象となるため、少しでも小さいサイズで運用したいところですが、下から2番目の比較的小さなサイズで捌くことができるのは、うれしい限りです。
この検証結果を受けて、逆にXSの仮想ウェアハウスでどれだけの流量を捌くことができるのか、という指標も、今後進めていくサイジングの中でも重要な指標と考えられます。そこで、追加でXSの仮想ウェアハウスでは、どの程度の流量まで捌くことができるのか、追加検証を行いました。
6.追加検証とその結果
追加検証として、XSの仮想ウェアハウスでは、どれぐらいのデータ流量であれば、更新遅延5分以内の条件を満たすことができるか、を検証します。検証に用いるデータやタスクは先の検証と同一で、流量データとして生成するデータを変化させて、Dynamic Tablesの更新期間と更新ラグを計測していきます。生成するデータ量は、1年間1PBに相当する2GB/分を上限に、0.4GB/分単位に5区分で変化させて計測しています。
追加検証の結果は、以下になります。計測値は「分 : 秒」としています。
|
データ流入量 |
||||||
|
0.4GB/分 |
0.8GB/分 |
1.2GB/分 |
1.6GB/分 |
2.0GB/分 |
||
|
0.2PB/年 |
0.4PB/年 |
0.6PB/年 |
0.8PB/年 |
1.0PB/年 |
||
|
更新期間 |
1回目 |
0:25 |
0:56 |
1:38 |
2:34 |
2:56 |
|
2回目 |
0:21 |
0:46 |
1:48 |
2:27 |
2:42 |
|
|
3回目 |
0:34 |
0:55 |
1:35 |
2:13 |
3:05 |
|
|
4回目 |
0:22 |
1:13 |
1:30 |
3:06 |
3:02 |
|
|
5回目 |
0:25 |
0:55 |
2:03 |
2:24 |
3:58 |
|
|
平均 |
0:25 |
0:57 |
1:43 |
2:33 |
3:09 |
|
|
最大 |
0:34 |
1:13 |
2:03 |
3:06 |
3:58 |
|
|
最小 |
0:21 |
0:46 |
1:30 |
2:13 |
2:42 |
|
|
更新ラグ |
1回目 |
3:49 |
4:20 |
4:56 |
6:02 |
6:18 |
|
2回目 |
3:43 |
4:17 |
5:15 |
5:51 |
6:04 |
|
|
3回目 |
3:54 |
4:24 |
4:57 |
5:43 |
6:25 |
|
|
4回目 |
3:49 |
4:41 |
5:00 |
6:35 |
6:29 |
|
|
5回目 |
3:41 |
4:21 |
5:24 |
5:52 |
7:24 |
|
|
平均 |
3:47 |
4:25 |
5:06 |
6:01 |
6:32 |
|
|
最大 |
3:54 |
4:41 |
5:24 |
6:35 |
7:24 |
|
|
最小 |
3:41 |
4:17 |
4:56 |
5:43 |
6:04 |
|
仮想ウェアハウスのサイズXSの場合、1.2GB/分(0.6年/PB相当)あたりが、更新遅延5分以内を満たせるかどうかのボーダーラインであることがわかります。今回ターゲットとした、2.0GB/分には及びませんが、中小規模のデータパイプラインであれば、XSでも十分な性能なのではないかと考えています。
7.結果と考察
仮に1年間1PBのデータ流量、5分以内の遅延を想定した場合に、現実的に実現可能なのか、可能な場合どの程度のリソースを要するのか 、をテーマに検証を行ってきました。
結果、今回の想定であれば、Sサイズ以上の仮想ウェアハウスで、更新ラグ5分以内を達成できることがわかりました。また、XSの仮想ウェアハウスでは、1.2GB/分あたりまでのデータ流入を更新ラグ5分以内に実現できることがわかりました。今回の設定した問題の範囲ではありますが、下から2番目のサイズの仮想ウェアハウスでクリアできることを確認しました。 もちろんプロジェクトで導入するためには、まだまだ取り組まないといけない課題はたくさんあり、例えば、機能面では、データ変換処理を実処理にする、DAGを多分岐/多段にする等、非機能面では、流入レートを現実のものにして、ピーク性やバラツキを表現する等、運用面では、パイプライン処理状況の監視、異常の検知、復旧等です。これらについても、引き続き追加の検証、新情報のキャッチアップを続けていきたいと考えていますが、PBデータを現実的な範囲で扱うことができる時代になってきている のだと感じました。
最後に、処理できるのは良いとして、コストはどうなるのか、という視点で考察を記載したいと思います。まず、今回ターゲットとした1PBというデータを仮にSnowflakeの内部テーブルに保管すると、1カ月で約600万円のコストが発生します(オンデマンドストレージ、AWS、東京リージョンを想定)。このコストが、仮想ウェアハウスをどれだけ稼働させた場合のコストに相当するのかを見ていきます。仮想ウェアハウスのサイズと1か月稼働させた場合コストは下記のようになります。
なお、クレジット単価はビジネスクリティカルサポートの単価($5.7/クレジット)を想定します。
|
仮想ウェアハウスのサイズ |
XS |
S |
M |
|---|---|---|---|
|
1か月稼働させた際に発生するクレジット |
720 |
1440 |
2880 |
|
1か月稼働させた際に発生するコスト ・為替1ドル135円を想定 |
約60万円 ($4,104) |
約110万円 ($8,208) |
約170万円 ($12,312) |
|
1PBのデータ保管料と同額になる場合の常時稼働台数 |
約10台 |
約5.5台 |
約3.5台 |
上記の通り、最小サイズであるXSの仮想ウェアハウスであれば約10台を常時稼働させると、1PBを貯めておくコストと同額になることがわかります。いくつかの大規模プロジェクトでクラウド環境を運用してきた筆者の経験から見ても、思いのほか低いところに敷居がある、現実的に到達しうるレベルだという印象を受けています。
今回のようにニアリアルタイムを実現しようとすると、仮想ウェアハウスを高い稼働率で稼働させることになるため、発生するコストも十分に考慮する必要があります。ニアリアルタイムを実現すること自体は可能 なのですが、それにより得られる利活用効果を見極めた上で 、ニアリアルタイムを実現するのか、更新頻度を落とすのか、更新せずに貯め込んでスタティックな分析とするのか、といった選択肢の中から最適なアーキテクチャを採用する必要がある 、と考えています。
8.おわりに
本稿では、Snowflake Dynamic Tables による大規模ニアリアルタイム処理に向けた基礎検証を行いました。SnowflakeのDynamic Tables導入を検討している方々にとって、少しでも参考になれば幸いです。