事例に学ぶ EKS on Fargate 運用上の注意
1.はじめに
クラウド各社からマネージドサービスが提供され、広く実用化が進んでいるKubernetes基盤ですが、中にはワーカノードがサーバレス方式で提供されるサービスがでてきています。
サーバレス方式の場合、IaaS型のサービスと比較してワーカノードの細かなチューニングはできないものの、早期に手間をかけずに導入して使い始めることができるため、急速に立ち上げて、試行を積み重ねてゴールを目指していくアジャイル型の開発案件と非常に相性が良いです。
コストに関しても、ワーカノードについてはVMが立ち上がっている時間、ではなく、Podが稼働している時間に対しての課金となるため、試行していない時間帯にかかる維持費も最小限で済み、合理的です。サービスによってはコントロールプレーンの料金が別途発生するものの、ワーカについては不使用時にPod自体を削除しておけば料金は発生しません。
筆者も、実際にアジャイル型の開発案件を担当することになり、そのアプリケーション実行基盤として、サーバレス型のkubernetes基盤であるAWS EKS on Fargateを採用することにしました。
実際のプロジェクトに導入しようとすると、いくつか考慮事項が出てきたため、本稿ではそれらについて紹介します。幾分、プロジェクトの個別事情が関係する部分も含まれますが、類似のケースに出くわした際の参考になれば幸いです。
2.システム構成の概要と導入に際しての考慮点
今回のプロジェクトにおけるシステム構成の概要は下記の通りです。
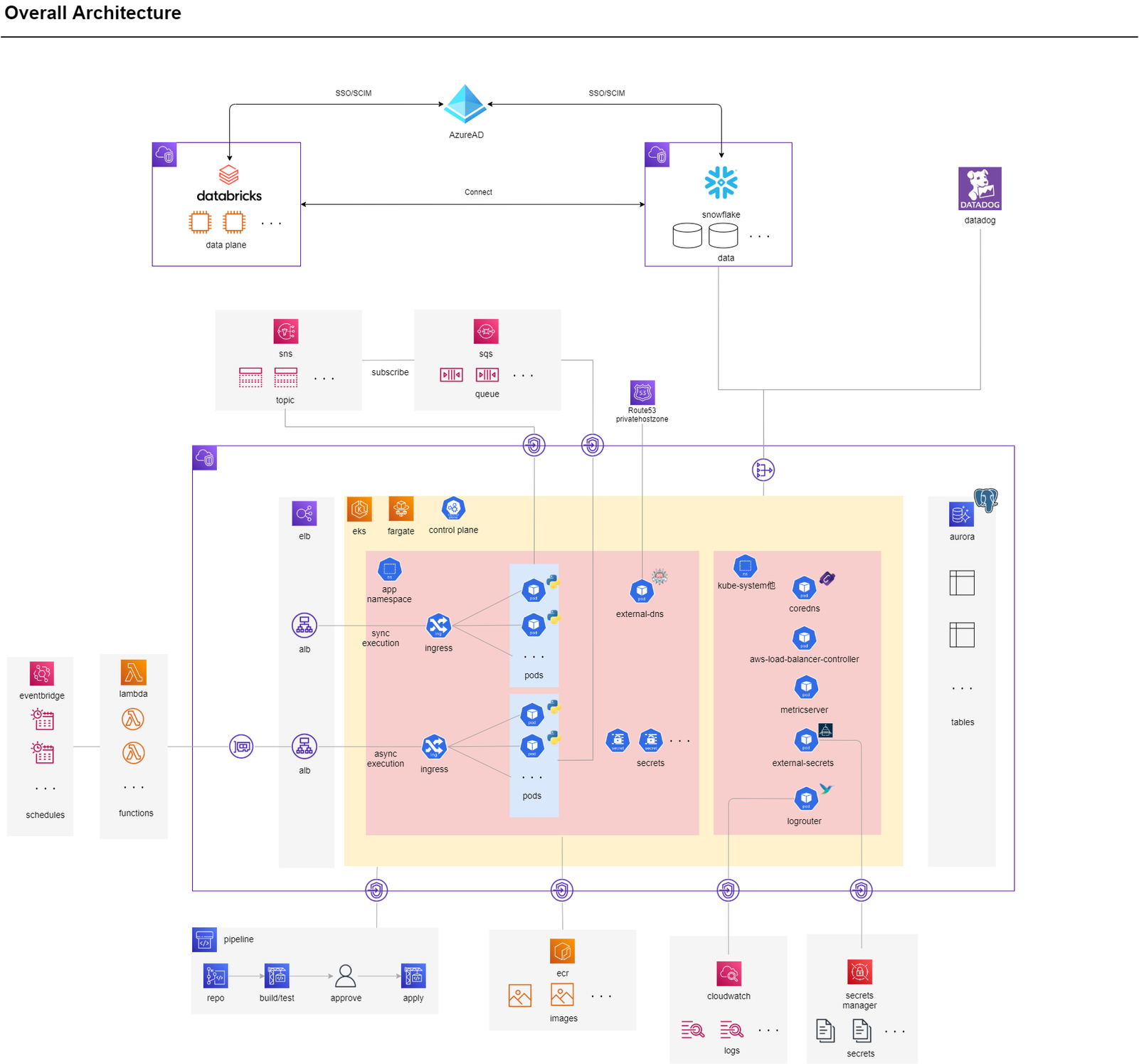
EKSとしては、下記のアドオンを利用した構成を想定します。
上記の構成でプロジェクトに導入を進める中で、出てきた考慮点は下記となります。
- クラスタのバージョンアップはIn-Place型ではなく、Blue/Green型でバージョンアップを行うことが望ましい
- クラスタのバージョンアップ後に現存Podを忘れずに再作成、再起動すること
- 完了後のJobは確実に消すこと
- 関連するサービスが多い場合は、全てを統一の枠組みで扱えるTerraformが便利
- EKSに限った範囲では、繰り返し利用されるIRSAの実装を固めるのが有効
- AppMeshの変更操作は、AppMesh Contoller経由で行うこと
以下で、それぞれについて詳細を記載します。
考慮点1.クラスタバージョンアップ
- クラスタのバージョンアップはIn-Place型ではなく、Blue/Green型でバージョンアップを行うことが望ましい
- クラスタのバージョンアップ後に現存Podを忘れずに再作成、再起動すること
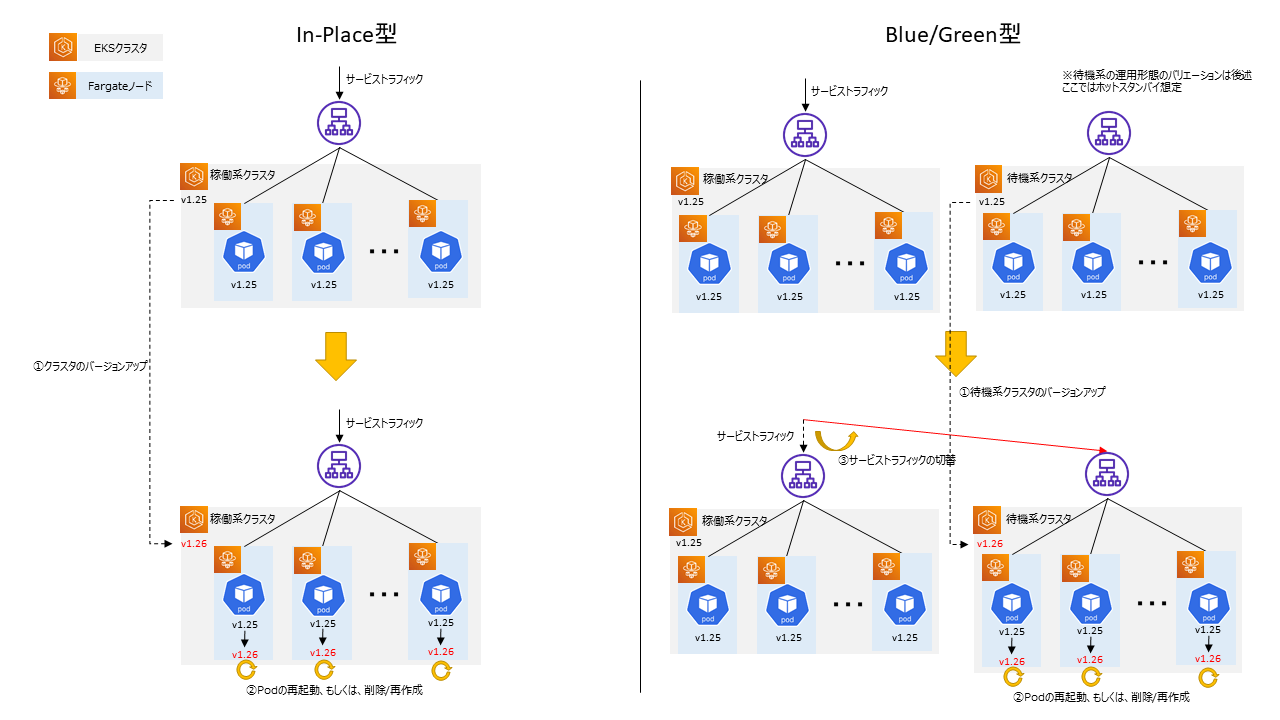
まず、現状EKSクラスタを運用するうえでは避けられないバージョンアップ運用について考えます。
下図に示す通り、大きくIn-Place型、Blue/Green型が考えられますが、実際の案件では「系全体の旧戻し」を確実に担保することが求められることが多いため、「Blue/Green型」、もしくは、「完全に図の通りではなくてもそれに近い」が採用されるケースが望ましいと考えられます。
筆者も以前AKSの実案件を担当していましたが、その時も「系全体の旧戻し」が可能であることが求められたためBlue/Green型を採用しました。
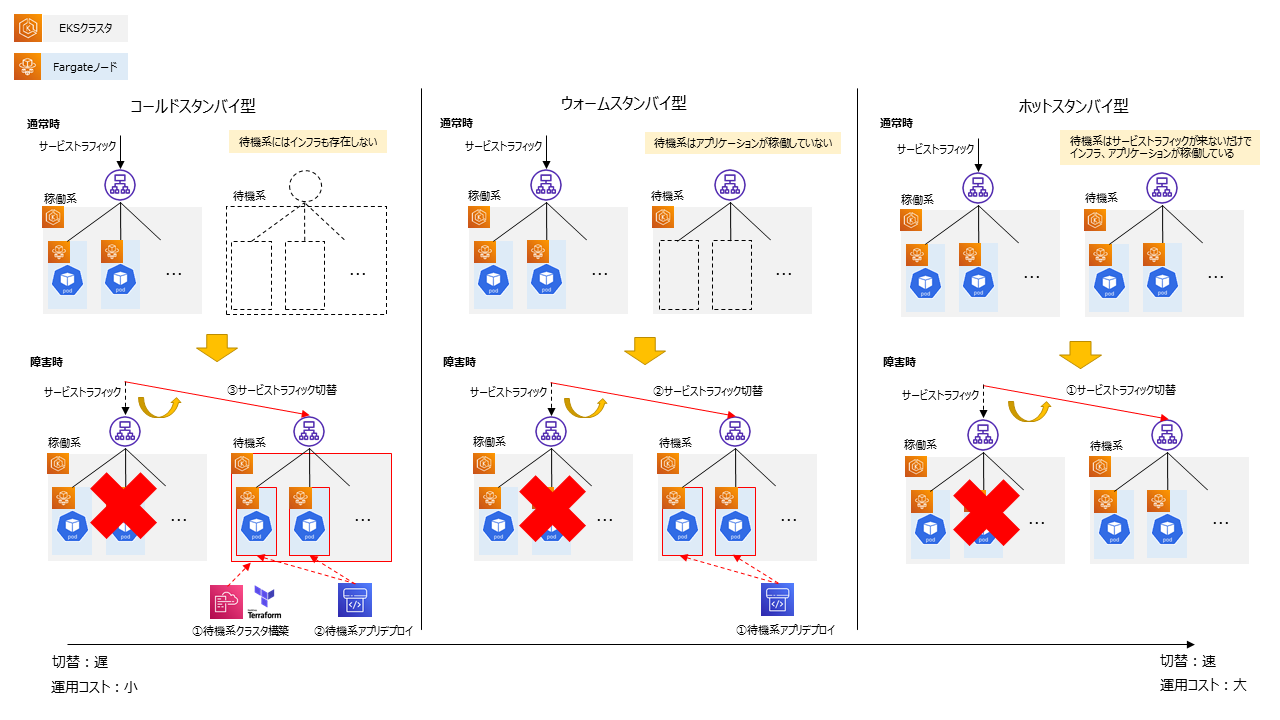
さらに、Blue/Green型の場合でも、通常時の運用としていくつかバリエーションが考えられます。
以下、通常時にサービス提供しているクラスタを稼働系クラスタ、サービス提供していないクラスタを待機系クラスタと称して記載します。
コールドスタンバイ型:
通常時は待機系のクラスタを引き落とし、バージョンアップ時に都度構築するケース。切替の都度クラスタ構築の手間、時間がかかるが、運用費は安くなる。IaCツールが広く浸透した現在となっては十分現実的な選択肢となっている。NW等の制約が多いオンプレとの接続環境においては、NW部分だけ作り置きしておき、待機系を稼働させるときはEKSクラスタやアドオン、その上で稼働するアプリケーションをIaCツール、CICDツールを利用してデプロイする形が想定される。
ウォームスタンバイ型:
待機系のクラスタ自体は稼働させているが、Podを引き落としているケース。切替の都度Podのデプロイが必要となり、運用費は今回の例の中では中間になる。現在では、PodのデプロイはCICDツールで行うため工数・時間はほとんどかからない。また、ワーカのFargateノードも立ち上がっていない状態であるため、待機時の課金も抑えることができ、EKS on Fargateでは有力な選択肢となる。一方、EKS on EC2やAzure AKSなどIaaS型のkubernetesサービスでは、Podが立ち上がっていなくてもVMが起動しているだけで課金が発生する。そのため、VMをシャットダウンしておき、Podのデプロイに先んじて起動させるなどの対応や、効率よく運用するために、これらのCICDツールへの組み込み等が必要になる。
ホットスタンバイ型:
有事の際に稼働系からすぐに切替ができるように、常時待機系のクラスタとPodを稼働させておくケース。切替はサービストラフィックの操作(DNSの切替、もしくは、ALBターゲットの切替)のみとなる。また、運用費は常時稼働した状態を保つため高くなり、切り替え後即サービス運用環境として成立することが望まれるため、監視や構成管理についてもサービス運用環境と同等に行う必要がある。この型は、運用費を差し置いても可用性を高めたい要件がある場合に選択され、筆者の以前担当した案件もこの型を採用している。
ここまで、バージョンアップの方式としては、Blue/Green型が望ましいこと、そのBlue/Green型にはいくつかバリエーションがあることを記載してきましたが、EKS on Fargateにおいてはもう一つ考慮点があるためその内容について記載します。
下記の公式ドキュメントに記載がある通り、バージョンアップ操作で実施されるのは、コントロールプレーンの更新のみで、更新前から存在するFargateノード上のkubeletは更新されないことがわかります。
AWSドキュメント)Amazon EKS クラスターの Kubernetes バージョンの更新 – Amazon EKS
5. クラスターの更新が完了したら、更新したクラスターでの Kubernetes と同じマイナーバージョンに、ノードを更新する必要があります。詳細については、セルフマネージド型ノードの更新 および マネージド型ノードグループの更新 を参照してください。Fargate で起動される新しい Pods であれば、クラスターのバージョンと一致する kubelet バージョンを持っています。それまでに存在していた Fargate Pods は変更されていません。
バージョンアップを行うと、先にコントロールプレーンのバージョンが上がり、これにワーカノードのバージョン(Fargateノードのkubeletのバージョン)を合わせるために、バージョンアップ時点で現存するPodについては再作成、再起動によりFargateノードを再取得する必要があります。
前述のBlue/Green型のバリエーションうち、コールドスタンバイ型、ウォームスタンバイ型では、クラスタのバージョンアップ後にPodを新規デプロイすることになるため、このことは問題になりません。
一方、ホットスタンバイ型の場合は考慮が必要で、待機系のバージョンアップの後、Podの再作成、再起動が必要となります。バージョンアップの手順自体は、統合運用ツールやCICDパイプライン、もしくは、運用管理端末上のシェルスクリプト等で(半)自動化することになると思いますが、Podの再作成、再起動を忘れずに行う必要があります。
以下では、実際に実機でバージョンアップ操作を行い、状況を確認したため、その内容を記載します。今回は、1.25から1.26へのバージョンアップを実施しています。
#
# EKSクラスタのバージョンを1.25から1.26へのアップグレードする
#
$ aws eks update-cluster-version --region ap-northeast-1 --name <cluster name> --kubernetes-version 1.26
{
"update": {
"id": "f4b35952-d467-4b57-bf70-8a343bbeac91",
"status": "InProgress",
"type": "VersionUpdate",
"params": [
{
"type": "Version",
"value": "1.26"
},
{
"type": "PlatformVersion",
"value": "eks.2"
}
],
"createdAt": "2023-05-22T05:36:17.033000+00:00",
"errors": []
}
}
#
# 応答で得られた"id"を"update-id"に指定して、状況を確認する。
#
$ aws eks describe-update --region ap-northeast-1 --name <cluster name> --update-id f4b35952-d467-4b57-bf70-8a343bbeac91
{
"update": {
"id": "f4b35952-d467-4b57-bf70-8a343bbeac91",
"status": "InProgress",
"type": "VersionUpdate",
"params": [
{
"type": "Version",
"value": "1.26"
},
{
"type": "PlatformVersion",
"value": "eks.2"
}
],
"createdAt": "2023-05-22T05:36:17.033000+00:00",
"errors": []
}
}
#
# "status": "Successful"になるまでポーリング
#
$ aws eks describe-update --region ap-northeast-1 --name <cluster name> --update-id f4b35952-d467-4b57-bf70-8a343bbeac91
{
"update": {
"id": "f4b35952-d467-4b57-bf70-8a343bbeac91",
"status": "Successful",
"type": "VersionUpdate",
"params": [
{
"type": "Version",
"value": "1.26"
},
{
"type": "PlatformVersion",
"value": "eks.2"
}
],
"createdAt": "2023-05-22T05:36:17.033000+00:00",
"errors": []
}
}
下記に更新後のクラスタの状況をマネジメントコンソールで確認した結果を示します。クラスタのkubernetesバージョンは1.26に上がっていますが、バージョンアップ時にデプロイされていたPodが稼働するFargateノードのkubeletバージョンは1.25のままで上がっていないことが確認できます。
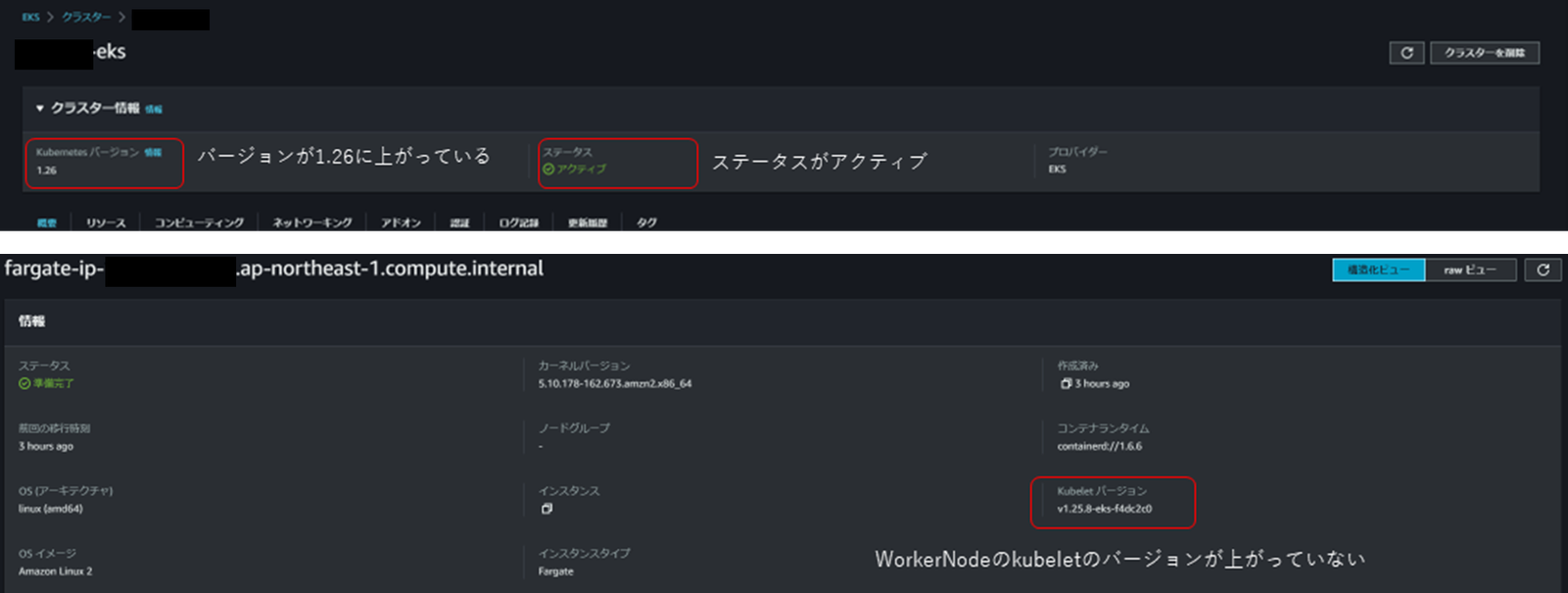
その後、Podを再起動すると、ワーカノードのバージョンも1.26になることを確認できます。
$ kubectl rollout restart deployment/<deployment name> -n <namespace> deployment.apps/<deployment name> restarted $ kubectl get pods -n <namespace> NAME READY STATUS RESTARTS AGE <deployment name>-6cb4549985-xp52n 1/1 Running 0 5m58s
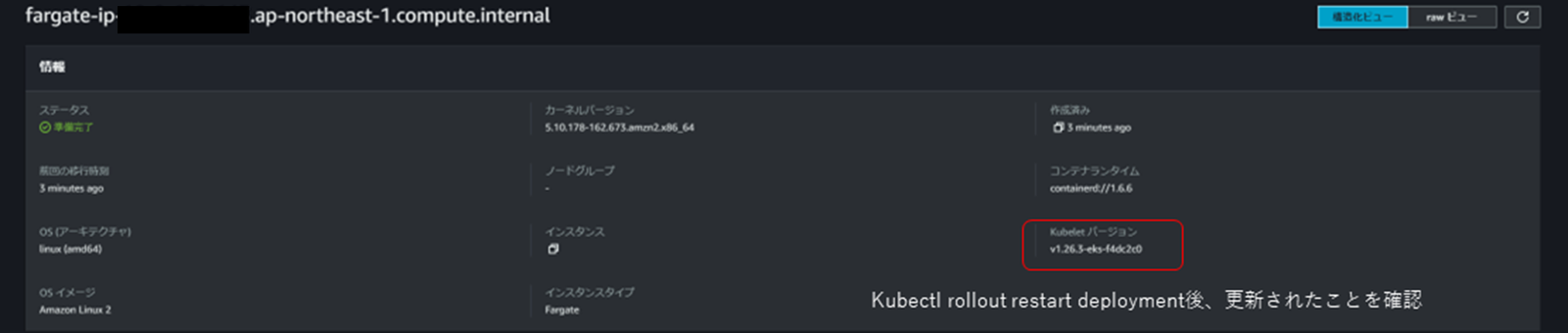
クラスタのバージョンアップ後に現存Podを忘れずに再作成、再起動することが必要です。
考慮点2.Jobリソース運用
完了後のJobは確実に消すこと
Jobリソースに関しては、明示的に消さない限り完了したリソース(Jobで稼働するPod)が残り、Fargateノードが確保されたまま、つまり、使わないIPアドレスが確保されたままになるので注意が必要です。
$ kubectl get pods -n nrivap -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES hoge-4rmrr 0/1 Completed 0 3m39s 10.0.135.94 fargate-ip-10-0-135-94.ap-northeast-1.compute.internal <none> <none> hoge2-dp9lx 0/1 Completed 0 114s 10.0.159.221 fargate-ip-10-0-159-221.ap-northeast-1.compute.internal <none> <none> hoge3-f7czl 0/1 Completed 0 114s 10.0.146.101 fargate-ip-10-0-146-101.ap-northeast-1.compute.internal <none> <none> hoge4-cqnkv 0/1 Completed 0 114s 10.0.140.59 fargate-ip-10-0-140-59.ap-northeast-1.compute.internal <none> <none> hoge5-qngpl 0/1 Completed 0 114s 10.0.148.17 fargate-ip-10-0-148-17.ap-northeast-1.compute.internal <none> <none>
Fargateノードが確保されたままになると、IPアドレスが消費されるため、諸々の事情で狭いアドレス空間内で実装している場合には、アドレスの枯渇に繋がり、必要なPodが立ち上がらなくなる事象に出くわす危険が出てきます。
また、残存しているPodは、人間が利用しているかどうかに関係なく、kube-apiserverの管理対象リソースにもなるため、残存数が多ければ多いほど不要な負荷がかかり、系全体の安定性にも影響が出る可能性もあります。
kubernetesのパラメータでもある程度軽減することはできるため、下記のパラメータの設定と合わせて、完了後のJobリソースを後始末するための仕掛けを導入する必要があります。
プロジェクト内では、まだJobリソースを本格的に利用していないため大きな問題になっていないですが、業務アプリケーションの本体でなくても、運用系のJobなどは今後増えていく可能性があるので、この点に気を付けながらプロジェクトを進めています。
| リソース | 設定項目 | 設定内容 |
|---|---|---|
| job | .spec. ttlSecondsAfterFinished |
Job Podが完了してからクリアされるまでの秒数を指定する。 デフォルトは指定なしであるため、このパラメータを指定するか、完了後のジョブを削除する仕組みを入れる必要がある。 |
| cronjob | .spec.successfulJobsHistoryLimit | 成功したジョブを何件保持しておくか、整数値で指定する。 デフォルト値は「3」で「0」を指定すると何も保持しなくなる。 |
| .spec.failedJobsHistoryLimit | 失敗したジョブを何件保持しておくか、整数値で指定する。 デフォルト値は「3」で「0」を指定すると何も保持しなくなる。 |
考慮点3.Terraform化する際の考慮点
- 関連するサービスが多い場合は、全てを統一の枠組みで扱えるTerraformが便利
- EKSに限った範囲では、繰り返し利用されるIRSAの実装を固めるのが有効
今回のプロジェクトでは、EKS周辺のサービスとして、他のAWSサービスの他、Azure AD、snowflake、Databricksを利用しています。これらサービスの構成管理を、同じ枠組みで扱うため、Terraformを採用しています。Terraformでは、下記に示す通り、AWS、Azureの他、snowflake、Databricks、 kubernetes、 helm(EKSにアドオンを設定する際に利用する)といったプロバイダに対応しています。
参考:Terraform provider)Terraform Registry

構成管理としては、例えばsnowflakeでは、ファンクショナルロールやDBアクセスロールを分割するロールモデルや、DWHを構成するデータベース、スキーマ、テーブル、演算装置となる仮想ウェアハウス等が構成管理対象となります。これらに関しては、Terraformを利用すると、下記の例に示すようにAWSやAzureと同等のコードで実装することができます。
############## ロールモデルの例 #####################
### db access role ###
resource "snowflake_role" "db_access_role" {
name = var.db_access_role.name
comment = var.db_access_role.comment
}
### functional role ###
resource "snowflake_role" "functional_role" {
name = var.functional_role.name
comment = var.functional_role.comment
}
### db access role grants SYSADMIN ###
resource "snowflake_role_grants" "db_access_role_grants" {
role_name = snowflake_role.db_access_role.name
roles = ["SYSADMIN"]
depends_on = [ snowflake_role.db_access_role ]
}
### functional role grants SYSADMIN ###
resource "snowflake_role_grants" "functional_role_grants" {
role_name = snowflake_role.functional_role.name
roles = ["SYSADMIN"]
depends_on = [ snowflake_role.functional_role ]
}
### Access Roleをfunctional Roleに付与する ###
resource "snowflake_role_grants" "db_access_role_to_functional_role_grants" {
role_name = snowflake_role.db_access_role.name
roles = [snowflake_role.functional_role.name]
depends_on = [ snowflake_role.db_access_role, snowflake_role.functional_role, ]
}
### functional RoleをUserに付与する ###
resource "snowflake_role_grants" "functional_role_to_users_grants" {
role_name = snowflake_role.functional_role.name
users = [
snowflake_user.user001.name
]
depends_on = [ snowflake_role.functional_role, snowflake_user.user001 ]
}
############## DWH関連リソースの例 #####################
# データベースの作成
resource "snowflake_database" "db" {
name = var.db.name
comment = var.db.comment
data_retention_time_in_days = var.db.data_retention_time_in_days
}
# データベースへのグラント
resource "snowflake_database_grant" "db_grant" {
database_name = snowflake_database.db.name
privilege = var.db.privilege
roles = [snowflake_role.db_access_role.name]
depends_on = [snowflake_database.db, snowflake_role.db_access_role]
}
# スキーマの作成
resource "snowflake_schema" "schema" {
database = snowflake_database.db.name
name = var.schema.name
comment = var.schema.comment
is_transient = var.schema.is_transient
is_managed = var.schema.is_managed
data_retention_days = var.schema.data_retention_days
depends_on = [snowflake_database.db]
}
# スキーマへのグラント
resource "snowflake_schema_grant" "schema_grant" {
database_name = snowflake_database.db.name
schema_name = snowflake_schema.schema.name
privilege = var.matsu_schema.privilege
roles = [snowflake_role.db_access_role.name]
depends_on = [snowflake_database.db, snowflake_role.db_access_role]
}
# テーブルの作成
resource "snowflake_table" "table" {
database = snowflake_schema.schema.database
schema = snowflake_schema.schema.name
name = var.table.name
comment = var.table.comment
column {
name = "TIMESTAMP"
type = "TIMESTAMP_LTZ"
}
# つづく
またEKSでは、クラスタ上で稼働するPodに対してIAMロールを割り当てる仕組みとしてIRSA(IAM Roles for Service Accounts)という仕組みを利用しますが、種々のアドオンのインストールやサードパーティサービスを利用する上で至るところで登場します。そのため、このIRSAの実装コードをパッケージングして、生産性の向上に役立てています。以下に、内部コードのサンプルを示します。
# IRSA(IAM Roles for Service Accounts)の有効化
# Open ID Connect Provider
# TLS証明書の取得
data "tls_certificate" "tls-certificate-eks" {
url = aws_eks_cluster.eks.identity[0].oidc[0].issuer
depends_on = [
aws_eks_cluster.eks
]
}
# Open ID Connect Provider を作成する
resource "aws_iam_openid_connect_provider" "oidc-provider-eks" {
client_id_list = ["sts.amazonaws.com"]
thumbprint_list = [data.tls_certificate.tls-certificate-eks.certificates[0].sha1_fingerprint]
url = aws_eks_cluster.eks.identity[0].oidc[0].issuer
depends_on = [
data.tls_certificate.tls-certificate-eks
]
}
# Preparation Pod IRSA
# create assume policy doc for Pod IRSA
# Pod IRSA用の信頼ポリシーの作成
data "aws_iam_policy_document" "policydoc-assume-eks-pod" {
statement {
actions = ["sts:AssumeRoleWithWebIdentity"]
effect = "Allow"
condition {
test = "StringEquals"
variable = "${replace(aws_iam_openid_connect_provider.oidc-provider-eks.url, "https://", "")}:aud"
values = ["sts.amazonaws.com"]
}
condition {
test = "StringEquals"
variable = "${replace(aws_iam_openid_connect_provider.oidc-provider-eks.url, "https://", "")}:sub"
values = [var.eks.pod_assume_policy_value]
}
principals {
identifiers = [aws_iam_openid_connect_provider.oidc-provider-eks.arn]
type = "Federated"
}
}
depends_on = [
aws_iam_openid_connect_provider.oidc-provider-eks
]
}
# create iam role for Pod IRSA
# Pod IRSA用の信頼ポリシーをアタッチしてロールを作成
resource "aws_iam_role" "role-eks-pod" {
# Assume ポリシー
assume_role_policy = data.aws_iam_policy_document.policydoc-assume-eks-pod.json
# 名称
name = format( "%s-%s", var.project_name, var.eks.pod_role_name )
depends_on = [
data.aws_iam_policy_document.policydoc-assume-eks-pod
]
tags = {
"Name" = format( "%s-%s", var.project_name, var.eks.pod_role_name )
}
}
# create pod policy doc
# アプリケーション特性に合わせてメンテナンスしていくことになる
data "aws_iam_policy_document" "policydoc-eks-pod" {
statement {
effect = "Allow"
actions = [
## 用途に合わせて個別調整 ##
]
resources = [
## 用途に合わせて個別調整 ##
]
}
}
# create pod policy
resource "aws_iam_policy" "policy-eks-pod" {
# 名称
name = format( "%s-%s", var.project_name, var.eks.pod_policy_name )
# 説明
description = var.eks.pod_policy_description
# ポリシー
policy = data.aws_iam_policy_document.policydoc-eks-pod.json
depends_on = [
data.aws_iam_policy_document.policydoc-eks-pod
]
tags = {
"Name" = format( "%s-%s", var.project_name, var.eks.pod_policy_name )
}
}
# policy attach to iam role for Pod IRSA
resource "aws_iam_role_policy_attachment" "rpa-eks-pod" {
# ロール
role = aws_iam_role.role-eks-pod.name
# ポリシー
policy_arn = aws_iam_policy.policy-eks-pod.arn
}
考慮点4.AppMeshの利用
- AppMeshの変更操作は、AppMesh Contoller経由で行うこと
今回の案件では、AppMeshについても導入を検証しています。ただし、試行錯誤の途中でマネジメントコンソールで実行した変更が数時間後に元に戻る事象に遭遇しました。
AppMeshを介してDatadogへの接続を試行する際に、一時的にAppMeshの「Egress フィルター」を「外部トラフィックを拒否する」から「外部トラフィックを許可する」に変更したい状況になったため、マネジメントコンソールからこの変更を行いました。
その後動作確認などを行い、その日はそのまま終業して翌朝マネジメントコンソールを確認すると、AppMeshの「Egress フィルター」が「外部トラフィックを拒否する」に戻されていたという状況です。
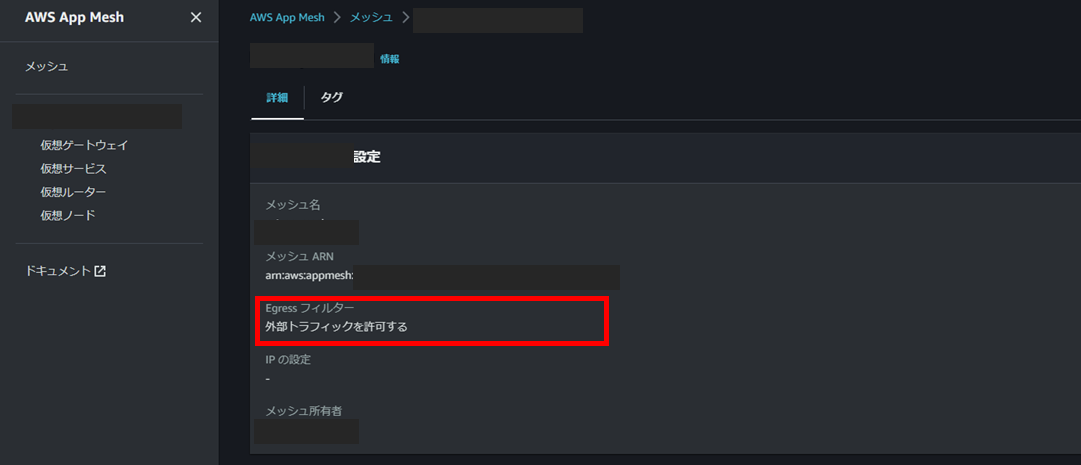
AWSサポートにも確認したところ、kubernetes上のAppMesh Controllerにより設定が更新されている、ということで、AppMeshをインストールした場合は、AppMesh Controller経由で変更操作を行ったほうが良いとのことでした。
これはインストールの手順等も影響している可能性もあり、執筆段階では調査中の部分もあるが、プロジェクトでは、AppMeshに対する変更操作はAppMesh Controller経由で行うこととし、マネジメントコンソールは参照用として利用するルールで運用を行っています。
おわりに
本稿では、EKS on Fargateの導入に際しての考慮事項について記載しました。考慮事項と言ってもノックアウトファクターになるようなものはなく、今後のアップデートで解消していく可能性があると考えています。
また、実プロジェクトでは、EKS on Fargateがアジャイル開発の土台として十分にその効果を発揮しており、特性がマッチするケースではどんどん活用していくべきだと考えています。