ChatGPTが変える未来のかたち
こんにちは。NRIデジタル、データサイエンスの松崎陽子です。今日はみなさんすでにご存じのChatGPTについて、その技術背景と今後の展望についてまとめてみたいと思います。
OpenAIからChatGPTが2022年11月に公開されてはや半年が過ぎようとしています。公開直後からその精度の高さ、柔軟なユースケースが話題になり、一気に大きなトレンドとなりました。ChatGPTの公開後、GoogleやMetaなどもつぎつぎと大規模言語モデル(LLM)を発表しており、2023年の1月から3月は日々刻々と変わっていく情勢に毎日がお祭りのような状況でした。OpenAIと組んだMicrosoftは1月には巨額の投資を発表し、OfficeなどのMicrosoft製品へLLMモデルの対話機能を搭載すると約束しています。またChatGPT自身も2023年3月にはより精度の高いモデル、GPT-4が発表され、さらに5月には有料版機能としてChatGPTとさまざまなシステムを連携するChatGPT Pluginがリリースされています。半年を経てもまだまだChatGPT関連の話題は日々更新されており、この新しいAI技術がどのような未来を与えてくれるのか、まだまだ未知数だと感じています。
ChatGPTができること
ChatGPTは大規模言語モデル(LLM)と呼ばれるとおり、自然言語モデルのなかでそのモデルサイズが大規模である、というカテゴリに属します。ChatGPTはOpenAIが開発したGPT(Generative pre-trained transformers)をもとに開発されており、その名が示す通り文章を生成(Generate)することを目的としたモデルとなっています。
このため、ChatGPTも基本的には「ふさわしい文章を生成する」ことを目的として学習されています。そのため、問いに対してふさわしい答えを生成したり、文章の要約としてふさわしい文を生成したり、英語に対してふさわしい日本語を生成したり、といった、場面に応じた文章の生成を得意としています。
ChatGPTがそれまでのモデルと大きく違うのは、「ふさわしい文章」としてどのような文章を生成すべきかを、より大きな文脈を理解して判断することができる点です。 例えば、ChatGPTでは同じ英語の文章を翻訳する場合でも、どのような文体がふさわしいか、といった文章自体を超えた文脈を与えることで、そのコンテクストに「ふさわしい」翻訳文を生成させることができます(図1~2)。

文章を専門家が読む文章として翻訳するように依頼。硬い文章として翻訳されている。(英文はGPTのWikipedia記事より引用、利用モデルGPT-4ブラウザ版)

図1と同じ文章を中学生がわかるように注釈を補って翻訳するように依頼。平易な単語のみで文章が生成されている。また、機械学習、トランスフォーマー、生成する、などの専門的な言葉に補足説明が追加されている。
ChatGPT以前の言語モデルでも、長い文章の文脈を理解し、適切に文章を分類したり、生成したりするモデルは検討されてきました。しかし、ChatGPTの「文章生成」は、これまでの自然言語モデルが想定してきた文脈の範囲を一挙に広げることで、より自然で、より多様な文章生成を可能にしています。
このようなChatGPTの特性から、ChatGPTの何かを質問する際にはその質問の背景や、求めている回答内容を文脈として指定することで、より「ふさわしい」回答を生成させることができます。このようなChatGPTへの指示方法のノウハウはプロンプトエンジニアリングとよばれ、新しい技術分野として現在さまざまな取り組みがなされています。私たちの部署でも案件ごとにタスクに相応しい、より精度の高いプロンプトが何かを検討する活動が行われています。プロンプトエンジニアリングはこれまでのプログラミングとは違った技術領域になりますが、今後もノウハウを蓄積し、ChatGPTの性能を有効利用したプロダクトを生み出していきたいと思います。
また、プロンプトエンジニアリングは日々の業務において、ChatGPTをユーザーとして使う際にも重要なノウハウとなっています。
すでに皆さんもご承知の通り、ChatGPTは業務上の文章生成(たとえばメールやドキュメント作成の下書き)やコーディング作業の補助、ちょっとした技術知識の問い合わせなど、日常業務においても非常に有用なツールです。(*もちろん、業務上の秘匿すべき情報や、他者・自己の個人情報を入力してはいけません!)
NRIグループではすでに社内において生成AI利用ポリシーを定めており、その規範にのっとって日常業務でChatGPTを有効利用し、業務生産性をあげることを推奨しています。個人個人がそれぞれ、自分のタスクにとってどのような指示、プロンプトが有効かを探っていくことが、これから、ChatGPTとともに仕事を進めていくうえで必要な技能かもしれません。
ChatGPTの課題
さて、その有用性が大きく注目されているChatGPTですが、すでにさまざまな課題点が報告されています。しかしながらわずか半年の間に課題の克服方法もすさまじいスピードで検証されています。
最も大きな課題として、ChatGPTをはじめとするLLMモデルによる文章生成には、ハルシネーション(Hallcination、幻覚)とよばれる「うそ」をつく現象が見られることが分かっています。これは、LLMがあくまでも「ふさわしい」文章を生成することを目的としており「正確な」あるいは「正しい」文章を生成するようには訓練されていないことに起因します。ChatGPTやGPT-4ではLLMが「正しさ」を意識するよう、学習後に調整が行われていますが、それでもなお、完全に「うそ」をつくことをやめさせることはできていません。なぜLLMは簡単に「うそ」をついてしまうのか。その原因についてはまだ解明に至ったとは言い難い状況です。
仮説の一つとして、学習データによるバイアスが挙げられます。ChatGPTをはじめとした自然言語モデルは、あくまで学習データに含まれる単語の確率的なつながりに依拠して「それっぽい文章」を学びます。そのため、ある特定の単語、事象に関するデータが不足していたり、不正確であると、その事象や単語に関連した生成文章は不正確にならざるを得ません。ChatGPTの学習には膨大な量のテキストデータ(*GPT-3では45TBものデータをクリーニングし、570GB程度を学習に利用。比較として日本語のWikipediaデータはクリーニング前で3GB程度である)が用いられていますが、そのほとんどが英語であることや、Web上のテキストであることから、日本語の固有名詞や日本固有の概念については正確な学習ができていないと考えられています。そのために「うそ」をつきやすくなっていると考えられます。
ChatGPTなどのLLMを使う際にはこの特性を念頭に置き、つねに回答の裏どりをすることを心がけていただければと思います。このハルシネーションという現象は、LLMを利用する上で解決しなければならない大きな問題であるため、対策の基礎研究も盛んにおこなわれています(図3)。今後の発展を期待したいところです。
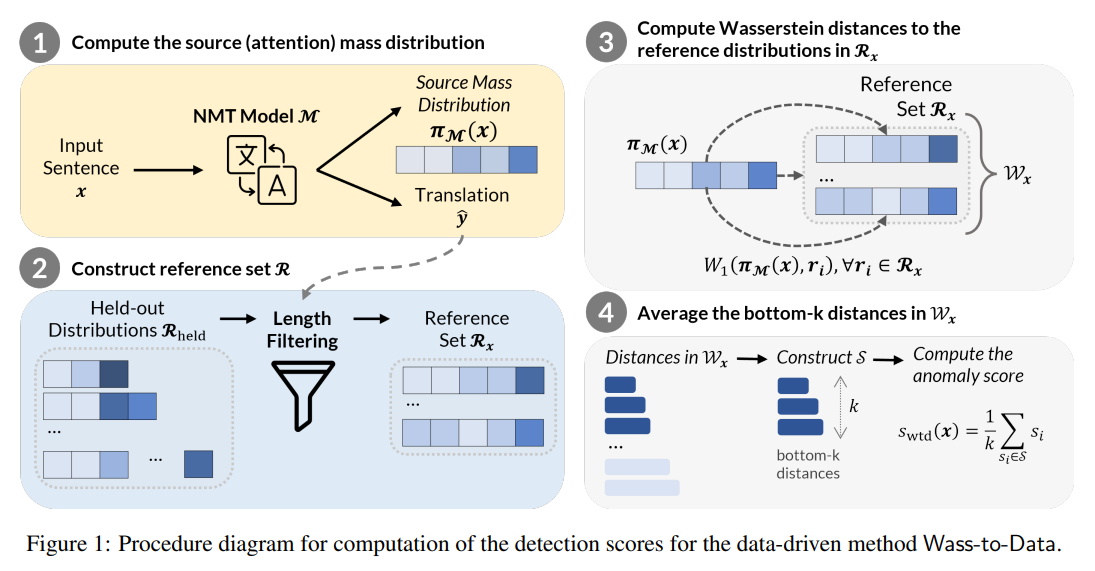
翻訳文と参照文(正解の翻訳例)をベクトル化し、ベクトル間の距離を比較することで意味的に類似しているかどうかを判定し、ハルシネーションが起きているかを評価する。
もう一つの課題として、ChatGPTはそのままでは学習に利用した過去の情報のみしか参照できないことがあげられます。当初から大きな欠点として話題になっていた点ですが、2023年5月にリリースされたChatGPT Pluginではインターネット上の知識を検索し、検索結果の内容を読み込んで回答に利用できるように改良が行われています(図4)。
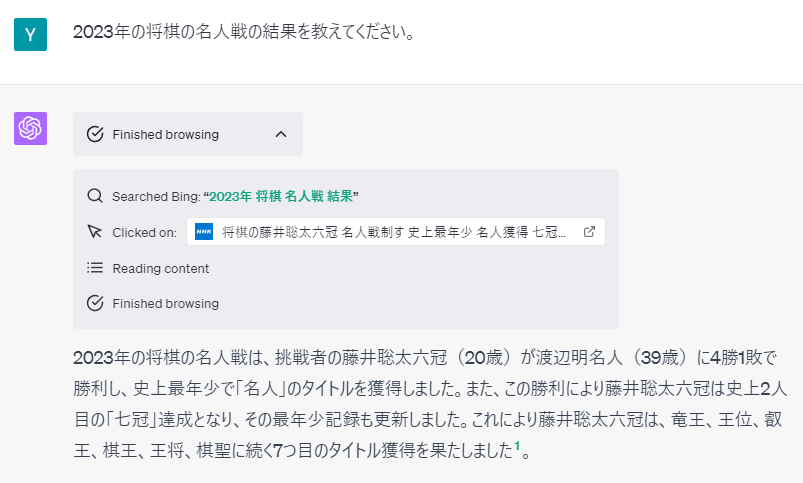
最新のニュースに関した質問にも回答できるようになった(利用モデル GPT-4, plugin Browse with Bing)。仕組みとしては、質問文から検索すべきキーワードを抽出し(画像内の“2023年 将棋 名人戦 結果”が抽出された検索キーワード)、キーワードを検索エンジンに入力して検索結果を受け取ります。そして受け取ったURLをクリックして内容を読み込み、読み込んだテキスト情報から回答の文章を生成します。
このような、ChatGPTがそのままではもっていない知識を外部から与え、回答に利用するように指示する方法は、プロンプトエンジニアリングによっても実現することができます(図5~7)。この事例では、最近更新されたWebページの情報を読み込み、OpenAI APIを利用してChatGPTに入力し、該当ページの情報を抽出した要約文を作成します。その後、作成した要約文を用いて次の質問に答えるように指示を出しています。これにより、ChatGPTそのもの、ChatGPT Pluginでも正しく回答できなかった質問に対して、正確な情報をこたえることができています。

文化庁HP2) https://www.bunka.go.jp/shinsei_boshu/kobo/93894401.htmlより6/7日付発表の公募内容をWebスクレイピングによって入手し、ChatGPTに要約させ参照用のテキストデータを作成した。次に作成した要約テキストの内容を用いて質問に答えるように指示することで、本来持っていない外部データを正確に回答することができている。(利用モデル、OpenAI API, gpt-3.5-turbo)
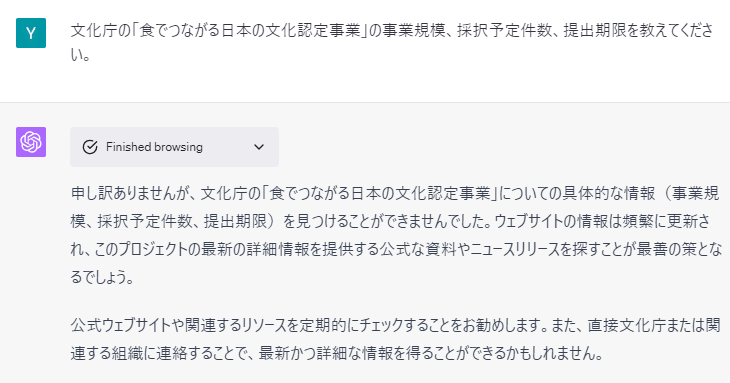
図5とおなじ課題をGPT-4 plugin, Browse with Bing (Beta)で実施したもの。ウェブページの検索に失敗してしまい、情報を得ることができなかった。先の将棋の例では十分なWebリソースがあることで検索の実施と回答が実施できていたが、ニッチな情報に対してはまだ改善の余地があるようだ。
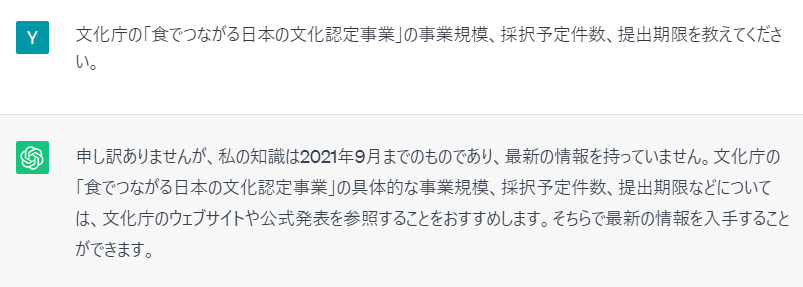
図5とおなじ課題をGPT-3.5(ブラウザ版)にて実施した結果。最新の情報は参照できない、と回答する。
このような仕組みを用いれば、ChatGPTが保有していない、特定の業務知識に基づいた回答を作成させることが可能になることが分かってきています。また、外部知識の連携を実現するためのツールとして、LangChainやLlamaIndexなどのライブラリも発展してきており、さまざまな試みが気軽に試せるようになってきました。私たちはより効率の良い外部知識の連携方法や、システムとしての構成方法を検討し、どうすればサービスとして提供できるかを検証しています。
最後の課題として、ChatGPTはOpenAIの独占モデルである、という点が挙げられます。ChatGPTの利用には情報漏洩のリスクや、APIの利用に伴うコストの増大など、利用場面が増えるほど問題視されるリスクがあります。これらの解決方法として、ChatGPTに頼らない、独自のLLMモデルを開発し利用するという方策があります。ChatGPTやGPT-4などと同等の巨大モデルは、開発するのにも、運用するのにも莫大なコストがかかり、実現することは非現実的です。今後は、より小さい、軽いLLMモデルによって、ChatGPTなどの超巨大モデルの性能にせまることはできるのかどうか、が焦点になってくるでしょう。
たとえば特定の話題にしぼった対話、特定の課題に絞った指示理解など、ChatGPTとは違った戦略を取ることで有用なモデルが実現できるかもしれません。このような独自LLM技術に関してはまだまだ基礎研究の段階ですが、多くの技術がそうであったように、いつの日かブレイクスルーが起きると思われます。そしてそれは、そう遠くはないでしょう。というのも、ちょうど昨年、ChatGPTに先んじて生成AIブームの先駆けとなった画像生成の分野では、当初挙げられていた課題(たとえば構図の指定ができない、指などの複雑な部位の表現がうまくできない、など)から、商業利用することは難しいとの見方がありました。しかしながら、1年もたたない間に課題を解消する技術が発展し、この3月には商用サービスとしてAdobe Fireflyが発表されています。
このような急速な発展の背景には、画像生成AIに多くの関心が寄せられ、企業や研究機関にとどまらず、さまざまなユーザーによる検証が進められたことが挙げられます。画像生成AIと同様に、ChatGPTやより小規模なLLMモデルについても現在、多くの企業、研究機関、一般ユーザーが課題の解消に強い興味を持っており、日々新しい知見を公表しています。まだまだどのような方法が技術革新を進めるかは未知の領域ですが、私たちは日々最新の知見にキャッチアップしながら、独自モデルを扱う技術についても検証を進めています。
おわりに
冒頭でも触れましたが、ChatGPTなどのLLM技術はこれからOfficeをはじめ、さまざまなシステムに当たり前のように組み込まれていくと考えられます。自然言語、つまり言葉は誰もが使えるインターフェースであり、もっとも容易な意思伝達の手段です。もし同僚にSlackで仕事を依頼するように、ソフトウェアにチャットでタスクを依頼できるようになったら。そうなれば、もはや誰がそれぞれのソフトのUIを覚え、コマンドを覚え、必要な設定事項を選んでタスクを実行するでしょうか。
もちろん、テキストで指示するよりUIを操作するほうが簡単だ、という声もあるでしょう。しかし私たちはまだ、言葉を利用することのメリットを正確に計ることができていません。ちょうどインターネットが発達し、Google検索が現れたとき、私たちは最初「検索」の力を知りませんでした。しかし、今となっては「検索」がない世界は想像がつかない状況になっています。同じように、LLMがどのような力を持つか、私たちはまだ誰も正確には知りません。けれど、この技術はきっと、私たちの未来において「なくてはならない」ものの一つになると、そう期待させてくれます。
もちろん、そのような未来はまだ少し先です。しかしその未来は、待っているだけでは訪れません。私たちはこれからも最新の技術を追いかけ、ノウハウを蓄積し、よりよい未来を実現するために、日々研鑽を積んでいきたいと思います。
References
| 1. | ↑ | Guerreiro et. al., 2022, https://arxiv.org/abs/2212.09631v2 |
| 2. | ↑ | https://www.bunka.go.jp/shinsei_boshu/kobo/93894401.html |