GKE Autopilot の性能検証
Autopilotモードの概要
Google Kubernetes Engine(GKE)1)https://cloud.google.com/kubernetes-engine?hl=jaは、自動化とスケーラビリティに優れたマネージド Kubernetes プラットフォームです。
GKEでは、Autopilot と Standard の 2 つの運用モードが提供されていますが、公式ドキュメントの比較表2)https://cloud.google.com/kubernetes-engine/docs/concepts/autopilot-overview?hl=jaにあるように、Autopilotモードでは、以下のような利点があります。(一部抜粋)
- アプリケーションに専念する:Google はインフラストラクチャを管理するため、アプリケーションの構築とデプロイに専念可能。
- ノード管理:Google がワーカーノードを管理するため、ワークロードに対応する新しいノードを作成したり、自動アップグレードと修復を構成する必要がない。
- スケーリング:必要に応じて既存のノードのリソースを自動的に拡張する。
Autopilot では、事前構成済みのスケーリング設定によってノードリソースの管理を行います。(公式ドキュメント3)https://cloud.google.com/kubernetes-engine/docs/resources/autopilot-standard-feature-comparison?hl=ja参照)
具体的には標準クラスタの機能にもある、ノードの自動プロビジョニング4)https://cloud.google.com/kubernetes-engine/docs/how-to/node-auto-provisioning?hl=jaや クラスタ オートスケーラー5)https://cloud.google.com/kubernetes-engine/docs/how-to/cluster-autoscaler?hl=jaを使用しています。
ノードの自動プロビジョニング
新しいノードプールがプロビジョニングされる。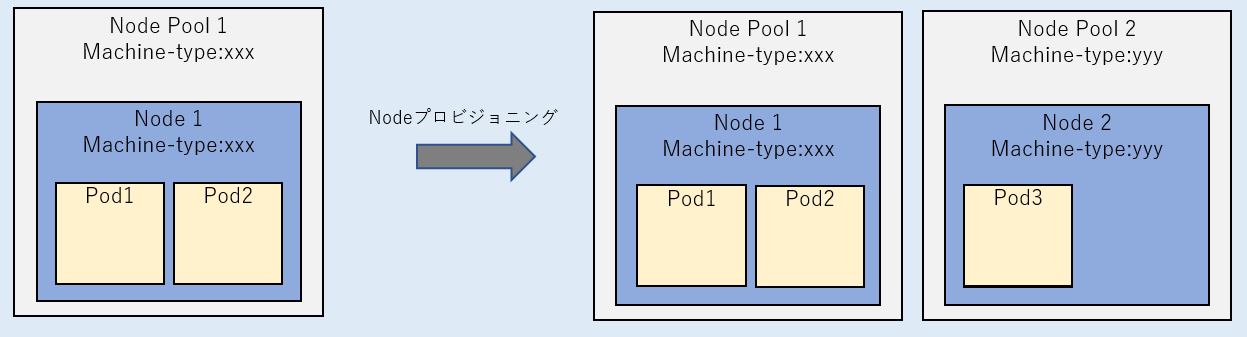
クラスタ オートスケーラー
特定のノードプール内のノード数をスケーリングする。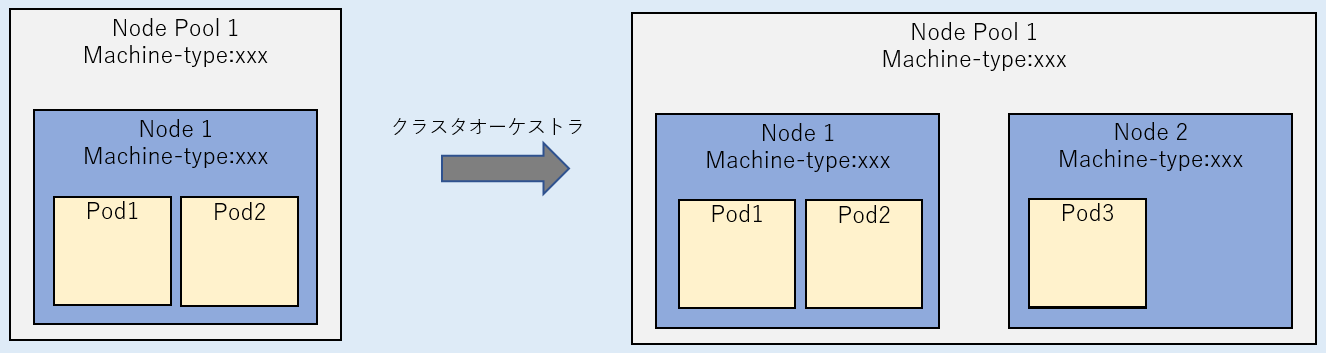
Autopilotでは、開発者が上記のようなスケーリング設定をせずに、スケーラブルなアプリケーション環境を構築できるという利点がある反面、ノードの拡張が発生するタイミングを制御できないため、ワークロードの予期せぬ中断やノードの立ち上がりによる起動遅延が懸念されます。
本ブログで調査すること
上記のGKE Autopilotモードにおけるスケーリング時の影響を調査する目的で、本ブログでは以下3点を検証しました。
- Pod作成時に発生する、追加されるノードのマシーンタイプの決まり方
どのような条件で、どのようなノードが拡張されるか - Javaアプリケーションをデプロイした場合に、プロセスが起動されるまでの時間
ノードの拡張有無で、どれくらいプロセス起動に差があるか - チューニング方法
アプリケーション起動までの時間を短縮させるためのチューニング要素があるか
留意事項
以降の検証では基本機能を軸に検証を進めているため、Pod のノード アフィニティやラベルセレクタ6)https://kubernetes.io/docs/concepts/configuration/assign-pod-node/、Node Taints7)https://cloud.google.com/kubernetes-engine/docs/how-to/node-taintsなどのPodのスケジューリング機能は使用しない状態で検証しています。
検証条件
本項における実機検証は、以下の条件で検証を実施しました。
- GKE Autopilot
- バージョン:1.22.12-gke.2300
- リージョン:asia-northeast1
- Java (Spring Boot)アプリケーション
- パラメータ
- deployment.yaml のCPUや、Pod数をパラメータとして検証
1. Pod作成時に発生する、追加されるノードのマシーンタイプの決まり方
検証の結果、Podが作成(Penging状態)になってから、PodがSuccess状態になるまでのフローは以下のようです。
- Podが作成されて、Pending 状態となる。
- Podを配置可能なノードを探す。
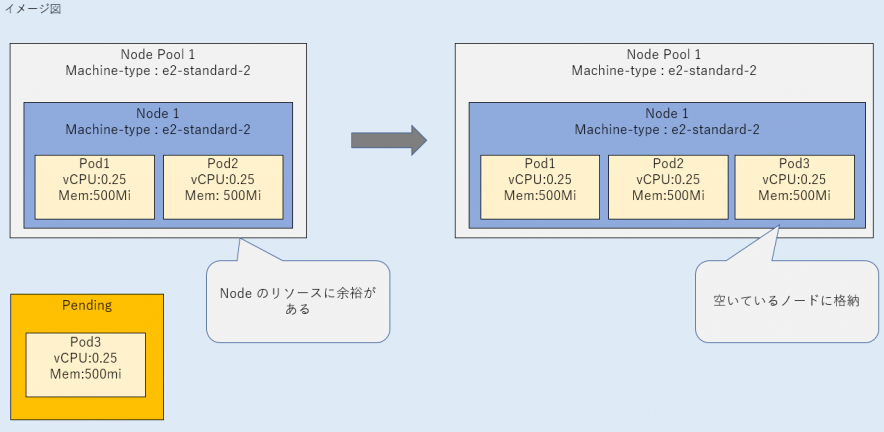
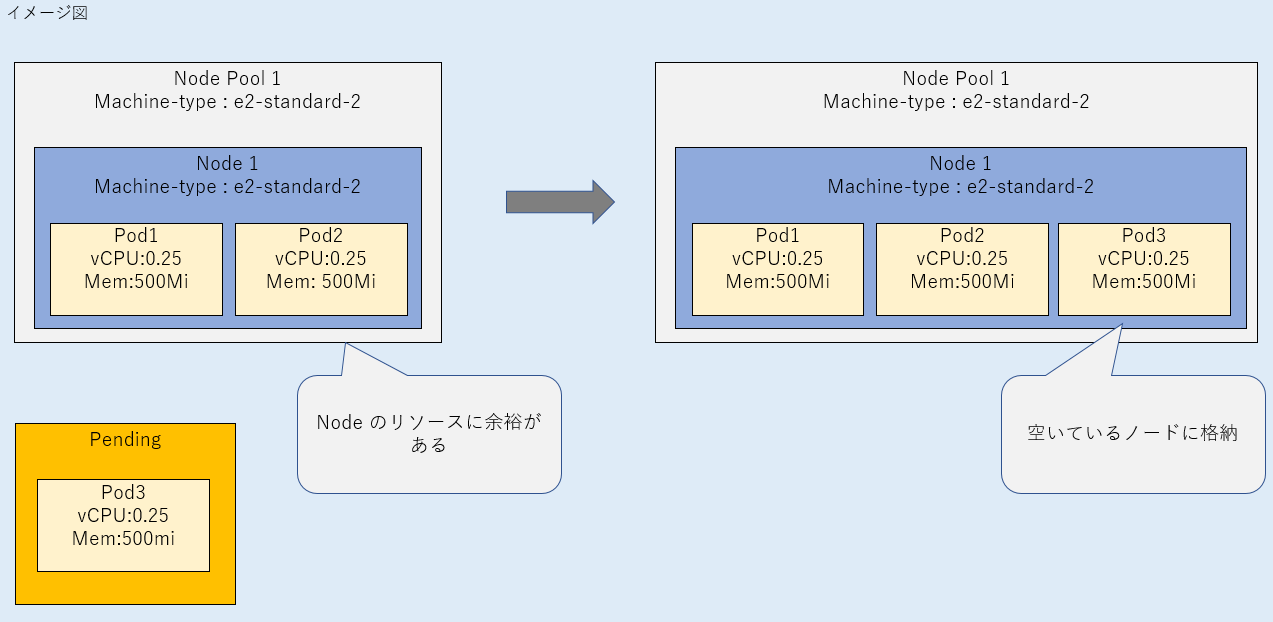
a. Podに必要なリソースを確保可能なノードがある場合、空いているノードにPodが配置され、PodがSuccess 状態となる。
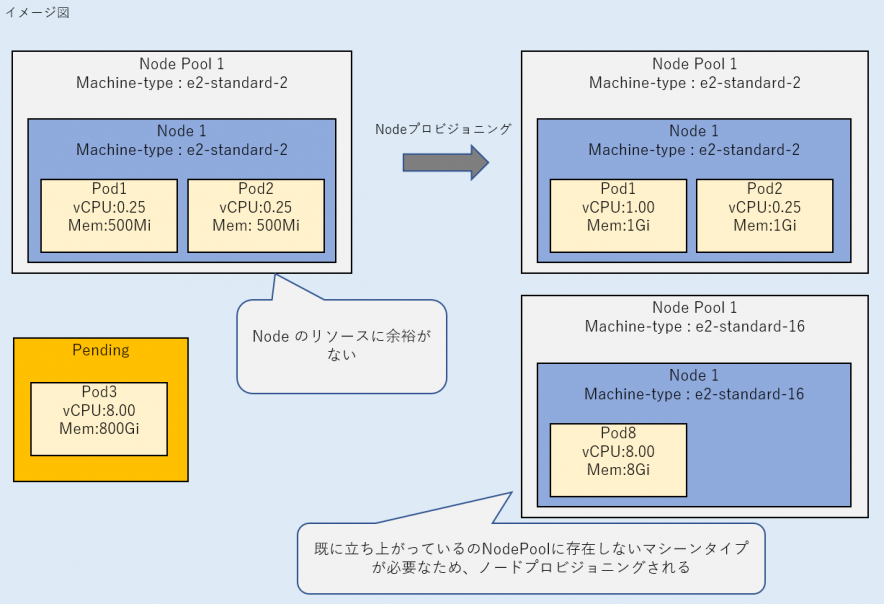
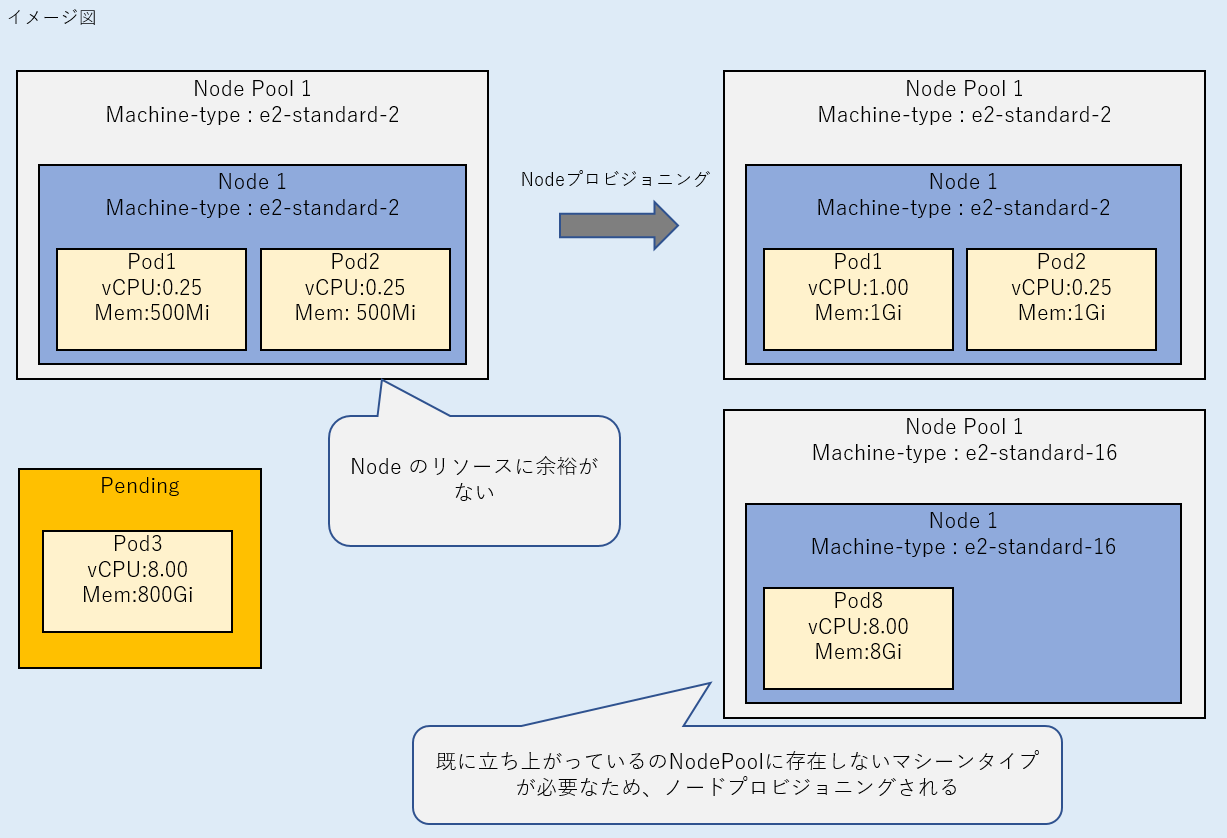
b. Podに必要なリソースを確保可能なノードがない場合、不足リソースに必要十分なマシーンタイプを持つノードが作成された後に、Podが配置されてSuccess 状態となる。
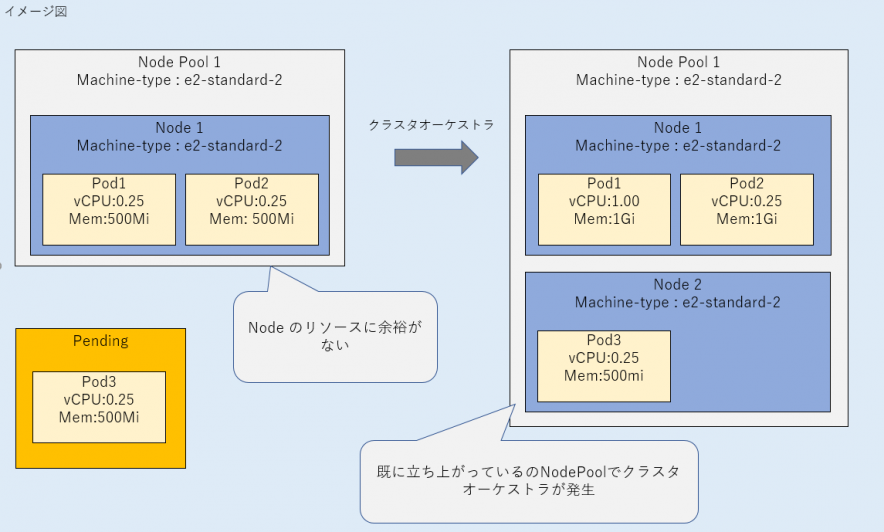
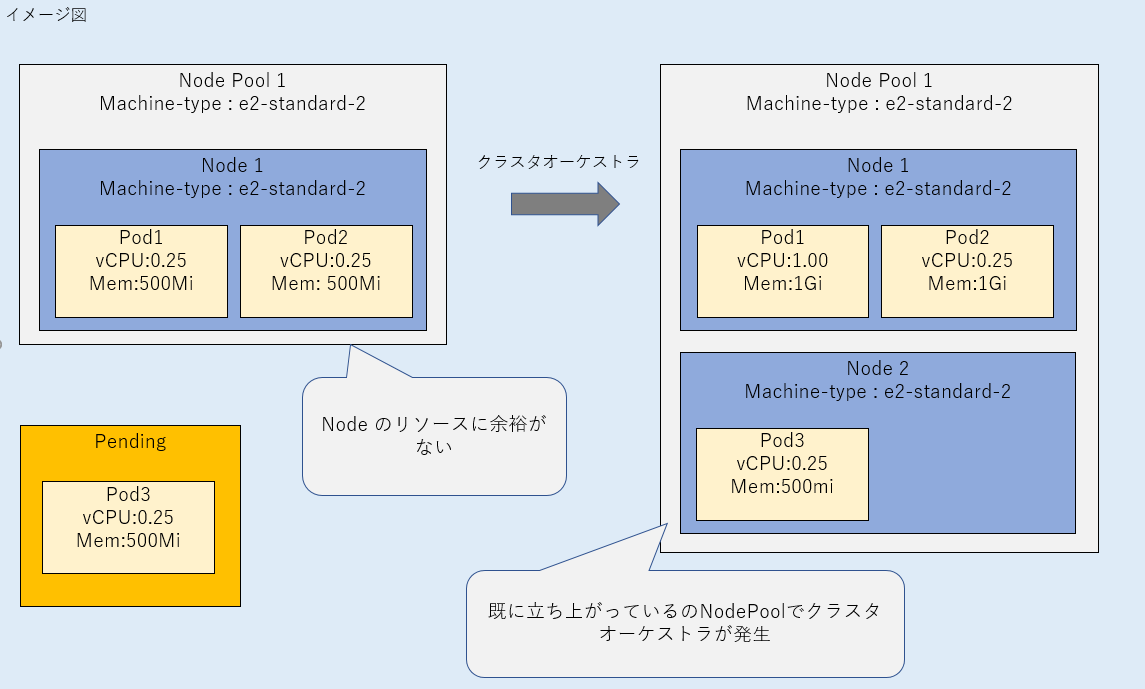
i. 不足リソースに必要十分なマシーンタイプと一致するノードが既に存在する場合、クラスタオーケストラが発生する。
ii. 不足リソースに必要十分なマシーンタイプと一致するノードが既に存在しない場合、ノードの自動プロビジョニングが発生する。
以下に検証結果を記載します。
a. Podに必要なリソースを確保可能なノードがある場合
Podをデプロイした場合、配置可能なノードがある場合は、空いているノードにPodが配置されます。
例)Podが1つ立ち上がっており、250mcpuのPodを配置するだけの空がある場合
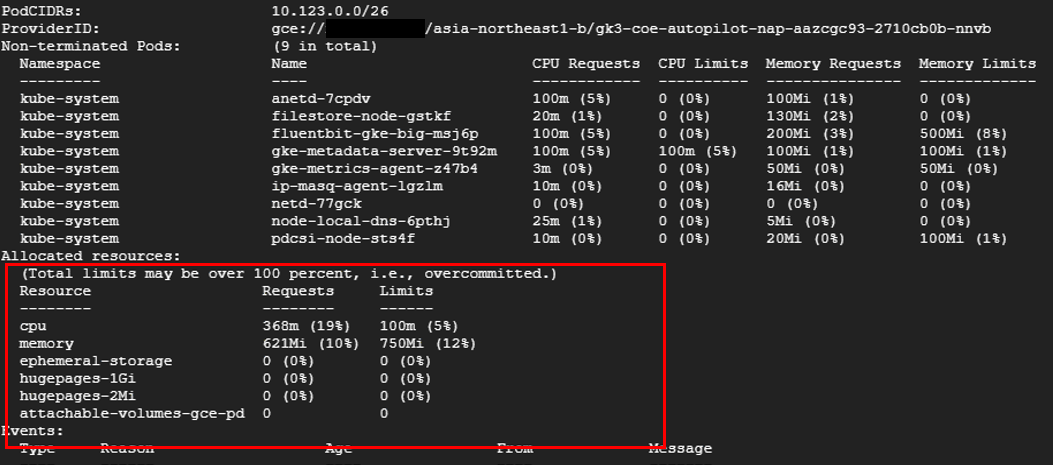

b. Podに必要なリソースを確保可能なノードがない場合
作成されるノードは、すでに立ち上がっているノードによらず、ユーザがデプロイしたPodの要求リソースとノードを作成したときに自動作成されるkube-systemのPodの要求リソースを満たすマシーンタイプが選択される傾向がありました。
検証の結果、8CPUを要求したPodをデプロイした場合は、16CPUのマシーンタイプが選定されます。
| deploymentで定義した Pod CPU |
deploymentで定義した Pod Memory |
選択されたマシーンタイプ |
|---|---|---|
| 8CPU | 1000Mi | e2-highcpu-16 (16vCPUs, 8GiB) |
| 8CPU | 20000Mi | e2-standard-16 (16vCPUs, 32GiB) |
| 8CPU | 40000Mi | e2-highmem-16 (16vCPUs, 64GiB) |
i. 不足リソースに必要十分なマシーンタイプと一致するノードが既に存在する場合
追加されたPodに必要十分なノードのマシーンタイプが、既に存在しているノードのマシーンタイプと一致する場合は、クラスタオーケストラが発生していることがわかりました。
#追加されたPodのリソース定義
resources:
limits:
cpu: 1000m
requests:
cpu: 1000m
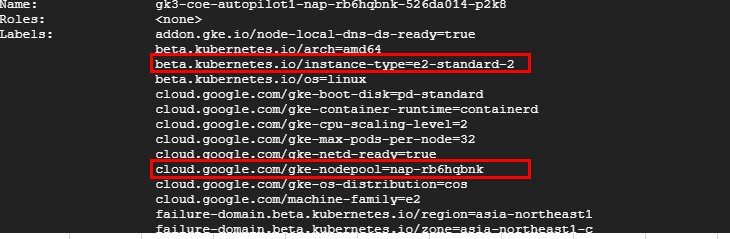
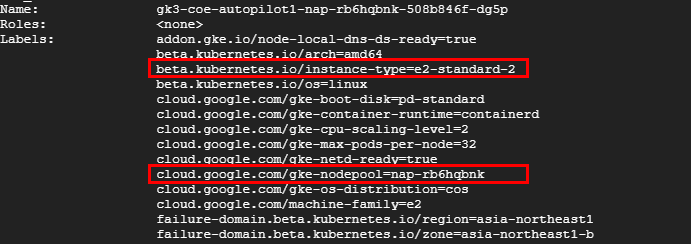
マシーンタイプは、既に存在していたノードと同じ
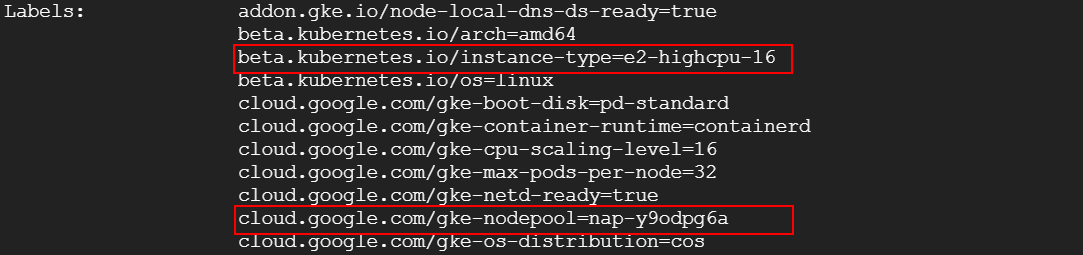
ii. 不足リソースに必要十分なマシーンタイプと一致するノードが存在しない場合
例えば、1CPUを要求するPodをデプロイしたときに、すでに立ち上がっているe2-highcpu-16のノードに空きリソースが不足している場合は、ノードプロビジョニングによりe2-standard-2のノードが作成されました。
#追加されたPodのリソース定義
resources:
limits:
cpu: 1000m
requests:
cpu: 1000m
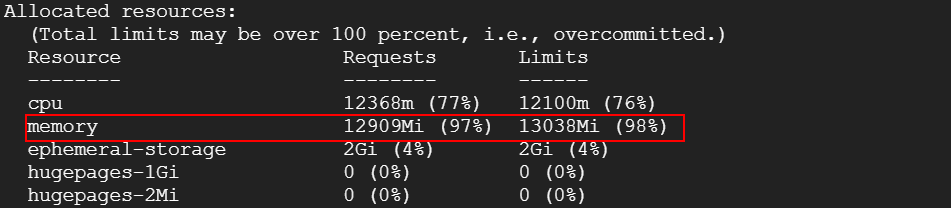
2. Javaアプリケーションをデプロイした場合に、プロセスが起動されるまでの時間
検証目的
ノードのスケーリング有無やスケーリング方法、ノードのマシーンタイプの大きさに応じてJavaアプリの起動にどれほどの影響があるかを調査する目的で、以下2つの検証を実施しました。
検証1
以下3パターンにおける、Javaアプリケーションのプロセスが起動されるまでにかかる時間を計測
a. Podに必要なリソースを確保可能なノードがある場合
b_i. クラスタオーケストラが発生する場合
b_ii. ノードプロビジョニングが発生する場合
検証2
「b_ii. ノードプロビジョニングが発生する場合」において、Podに必要なリソースが1000mcpuの場合と8000mcpuの場合でJavaアプリケーションのプロセスが起動されるまでにかかる時間にどの程度違いが出るのかを計測
検証結果
検証1
5回計測を行い、「Podが作成されてから、アプリケーションのプロセスが起動されるまで」の時間が最速および最遅の結果を除いた結果の平均値を以下に示します。
| Podが作成されてから、ノードがReady状態になるまで(s) | Podが作成されてから、JavaコンテナがStartするまで(s) | Podが作成されてから、アプリケーションのプロセスが起動されるまで(s) | |
|---|---|---|---|
| a. Podに必要なリソースを確保可能なノードがある場合 | – | 2 | 9 |
| b_i. クラスタオーケストラが発生する場合 | 106 | 124 | 132 |
| b_ii. ノードプロビジョニングが発生する場合 | 143 | 167 | 177 |
上記より、想定通りノードが追加されない「a. Podに必要なリソースを確保可能なノードがある場合」が最もアプリケーションの起動時間が短いという結果となりました。
また、「b_i. クラスタオーケストラが発生する場合」と「b_ii. ノードプロビジョニングが発生する場合」の比較より、ノードプロビジョニングのコストは約40秒で、クラスタオーケストラの方が、ノードプロビジョニング発生時よりも起動時間が短いことがわかりました。
今回の計測は比較的軽量なサンプルアプリケーションを使用しているため、アプリケーションがデプロイされてから開始されるまで10秒弱という結果でした。そのため、実用的なアプリケーションの場合は上記結果よりもプロセスが起動されるまでの時間が多少長くなることが予想されます。
検証2
5回計測を行い、「Podが作成されてから、アプリケーションのプロセスが起動されるまで」の時間が最速および最遅の結果を除いた結果の平均値を以下に示します。
| Podが作成されてから、ノードがReady状態になるまで(s) | Podが作成されてから、JavaコンテナがStartするまで(s) | Podが作成されてから、アプリケーションのプロセスが起動されるまで(s) | |
|---|---|---|---|
| Podに必要なリソースが1000mcpuの場合 | 143 | 167 | 177 |
| Podに必要なリソースが8000mcpuの場合 | 145 | 158 | 160 |
検証2の結果から、ノードがReady状態になるまでの時間は、作成されたマシーンタイプがe2-standard-2とe2-standard-8の場合でほとんど差がない結果となりました。
一方で、Podが配置されてからJavaプロセスが起動するまでの時間はe2-standard-8の方が17秒ほど早い結果となりました。マシーンスペックが大きい方が、アプリケーションの起動スピードが速いという想定通りの結果が得られました。
3. チューニング方法
検証結果より、ノードを新しく作るために多くの時間を要しているため、あらかじめリソースに余裕のあるノードを作っておくことができれば、Podがデプロイされたときにノードを作らずにともPodを起動させる状態を作り出すことができます。
しかし、Autopilotではユーザがノードの管理を行えないため、あらかじめリソースに空きのあるノードを作っておいて、Podを配置するということはできません。
上記のようなチューニングを行う方法の1つとして、PriorityClassを使用して、あらかじめ優先度の低いdummyPodをデプロイしておくことで、優先度が高いPodをデプロイしたときにノードが1から再作成されないようにすることができます。
マニフェストの実装例は以下です。
PrioristyClassの定義マニフェスト(優先度が高いもの)
apiVersion: scheduling.k8s.io/v1 kind: PriorityClass metadata: name: high-priority value: 10 globalDefault: false
PrioristyClassの定義マニフェスト(優先度が低いもの)
apiVersion: scheduling.k8s.io/v1 kind: PriorityClass metadata: name: low-priority value: -1 globalDefault: false
PrioristyClassを定義したDeploymentマニフェスト(優先度が高いもの)
apiVersion: apps/v1
kind: Deployment
metadata:
name: helloworld-gke-test1000mcpu-high-priority
spec:
selector:
matchLabels:
app: hello-gke-test1000mcpu-high-priority
replicas: 1
template:
metadata:
labels:
app: hello-gke-test1000mcpu-high-priority
spec:
containers:
- name: hello-gke-test1000mcpu-high-priority
image: asia-northeast1-docker.pkg.dev/project-name/coe-test/java-api:latest
resources:
limits:
cpu: 1000m
requests:
cpu: 1000m
ports:
- containerPort: 8080
env:
- name: PORT
value: "8080"
priorityClassName: high-priority //★ priorityClassNameを指定する。
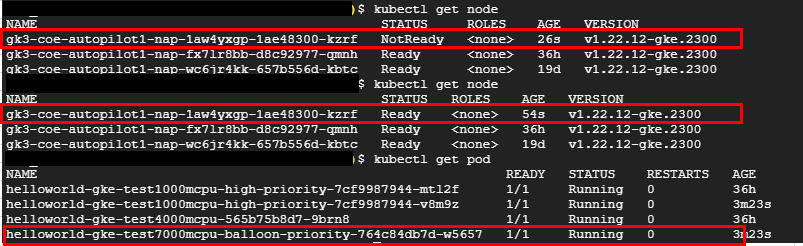
実機検証の結果は以下です。
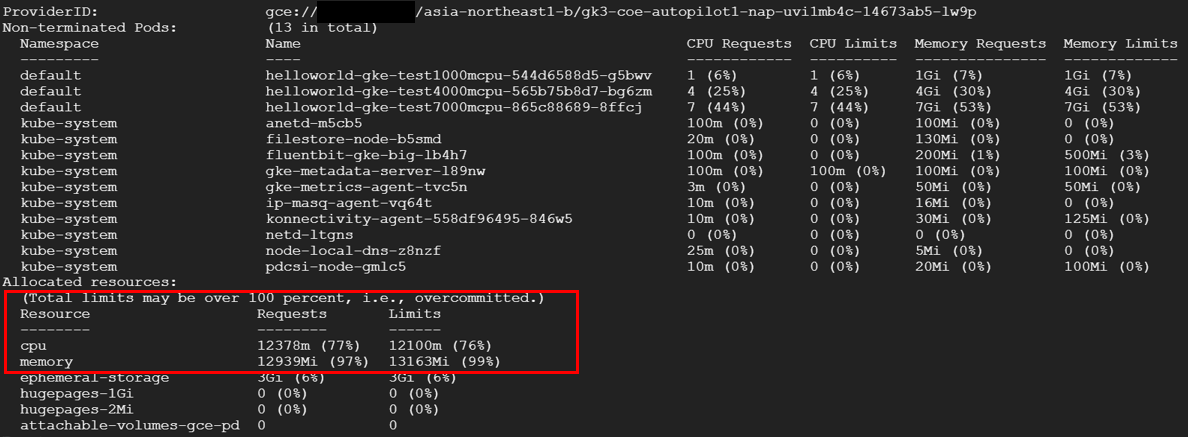
PriorityClassを使用していない場合


PriorityClassを使用している場合
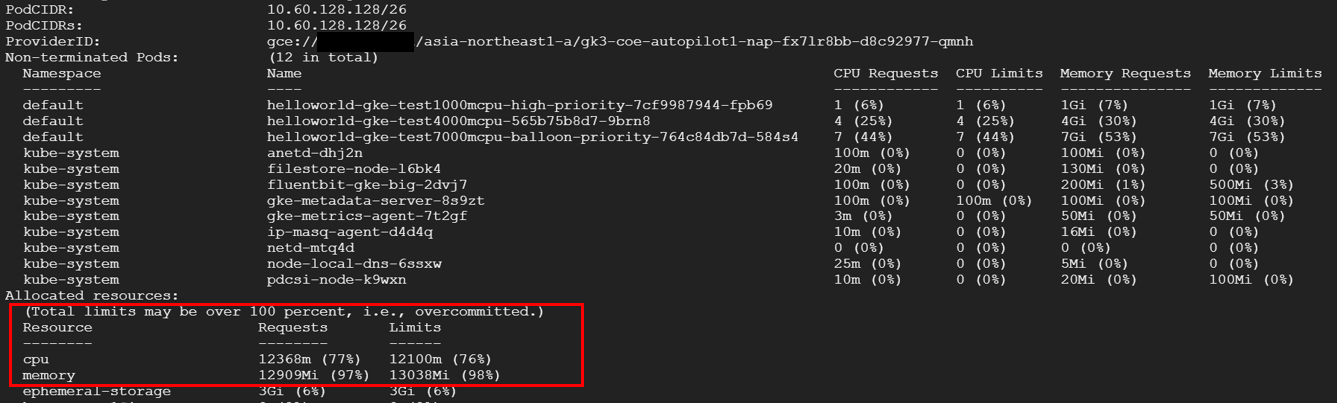

計測結果は下記です。ノードが作成されないため、Podがスケールしてから比較的に短時間でアプリケーションが開始されます。
| Podが作成されてから、ノードがReady状態になるまで(s) | Podが作成されてから、JavaコンテナがStartするまで(s) | Podが作成されてから、アプリケーションが開始されるまで(s) | |
|---|---|---|---|
| PriorityClassを使用して優先度が高いPodを作成した場合 | – | 4 | 6 |
また、優先度の低いPodは一度pendingになったのちに、ノードが再作成されて再度デプロイされます。
そのため、再びPodがデプロイされた際にリソースに空きがない場合でも、同じようにdummyPodがPendingになり、優先度の高いPodは高速にデプロイすることができます。
この方法を使用する場合の注意点は、AutopilotはPodごとに課金されてしまうため、dummyPodも課金対象となってしまう点です。システム運用費よりも、性能を重視したい場合は上記の方法も検討できるのではないかと思います。
まとめ
本稿では、GKEのAutopilotにおけるスケーリングパターンとJavaアプリケーション起動への影響、そして、チューニング方法について調査しました。
ノードの立ち上がり有無によって、アプリケーションの起動までの時間が大きく異なります。
ステートレスなAPIとしてGKEのAutopilotモードを利用するケースでは、dummyPodを使用することで高速にアプリケーションをスケーリングさせることができ、予期せぬスパイクの影響を最小限にとどめることができそうです。
References