Kaggleに挑戦 ~鯨とイルカの画像から個体を識別する~
こんにちは。NRIデジタルの大崎です。昨年、NRIデジタルのKaggle部メンバーとして複数の分析コンペティションに参加させていただきました。本記事では、Kaggle部として楊、猪野、林、大崎の計4名でKaggleに初参戦し銅メダルを獲得したコンペティションとして印象に残っている「Happywhale – Whale and Dolphin Identification」1)https://www.Kaggle.com/competitions/happy-whale-and-dolphin/overviewについて紹介していきたいと思います。
コンペティション概要
今回私たちが参加した「Happywhale – Whale and Dolphin Identification」は鯨とイルカの画像から個体を識別(個体識別IDを予測)するタスクを解くコンペティションでした。Happywhaleは2019年にもコンペティションを開催しており、その際は鯨の尾から個体を識別するタスクを解くコンペティションでした。今回は尾ではなく、背びれや、背付近の身体から識別する点とイルカが新たに識別対象として追加された点が2019年時と異なりました。また、本コンペティションではテストデータの個体識別の際に未知の個体を判別(学習データに含まれない個体識別IDはnew_individualとして予測)することが求められました。そのため、単純な画像分類問題として解くことが難しい点が特徴的なコンペティションでした。
データ
本コンペティションでは教師データとして、51,033枚の画像が与えられており、画像に対する種別名、個体識別IDの情報をもつcsvファイルが用意されています。画像枚数が51,033枚に対して、個体識別IDのユニーク数が15,587枚であることから、平均して1個体あたりの画像枚数が3~4枚となっています。また、テストデータとして、27,956枚の画像が与えられており、これらの画像全てについて、個体識別IDが何か、もしくはnew_individualであるかを予測します。テストデータ1枚につき5つの予測値(個体識別IDもしくはnew_individual)を当てはまると思われる順に出し、予測値と正解ラベルをMAP@5から計算してスコアを算出します。
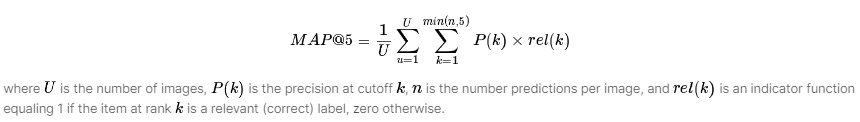
画像には背びれ付近がアップで取られている画像から、かなり遠くから背びれが取られており、背景を多く含む画像まで様々ありました。画像から人間の目で個体識別をすることは難易度が高く、個体追跡・調査を行うために大量の個体を識別することは困難です。したがって個体識別の自動化は研究への貢献度が高いことを実感することができました。本コンペティションの優勝チームのモデルは実際に、海洋生物・環境の保全と研究に活用される予定とのことです。

自チームの解法
私たちのチームは画像から生体部分をクロップしたデータを使用して、深層距離学習を用いた特徴量ベクトル(embedded)の抽出をした後、ベクトルの類似度から個体識別IDが何かもしくはnew_indivdualを予測する手法を採用しました。
- 学習用データセット
複数のクロップ方法で画像を切り出した公開データセットを学習に用いる手法を採用しました。実際に学習させたデータセットに用いた切り出した領域は、背びれ領域、全身領域の2つで、これらのデータセットを混ぜてモデルを学習しました。
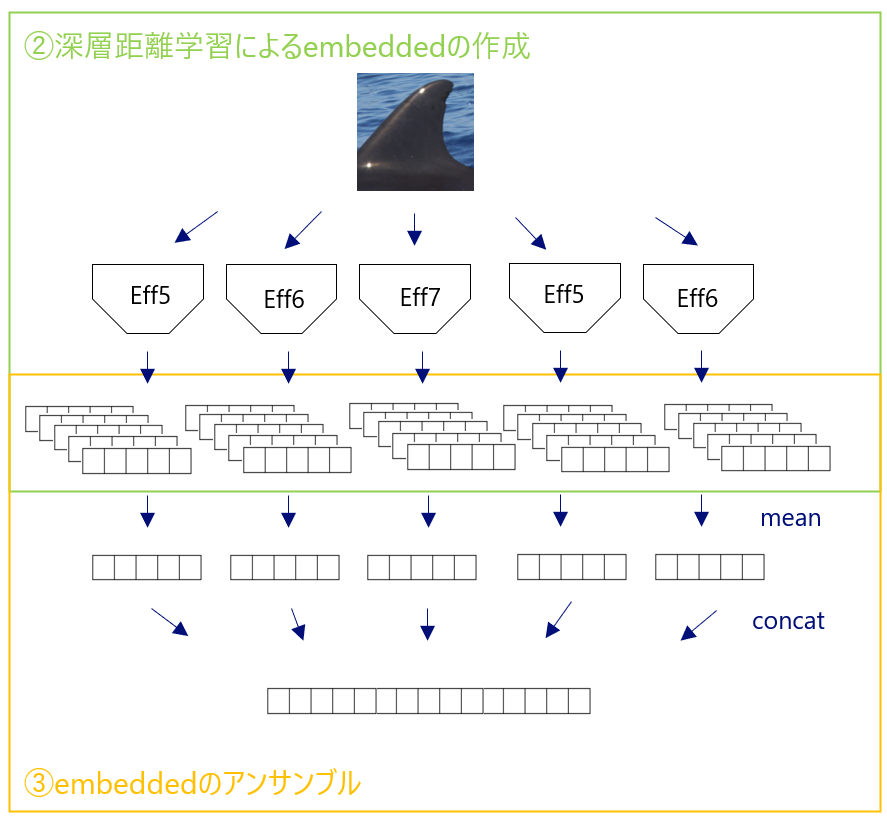
- 深層距離学習によるembeddedの作成
本コンペティションは1個体に対する学習用画像枚数が少ないことと、未知の個体を判別する必要があることから単純な分類問題としてではなく、深層距離学習を用いた特徴量ベクトル抽出を使用する手法を採用しています。抽出した特徴量ベクトルの類似度を算出することで、ある閾値以上を満たす個体がない場合は未知の個体と判別できます。私たちのチームでは、Efficientnet v1 b5~b72) https://arxiv.org/abs/1905.11946、Efficientnet v2 large3)https://arxiv.org/abs/2104.00298、Swin Transformer4)https://arxiv.org/abs/2103.14030をバックボーンとして、ArcFaceをヘッドとしてタスクを解きました。
- embeddedのアンサンブル
各モデルについて5foldで学習した後、抽出したembeddedをアンサンブルしました。アンサンブルの手法としては、各モデルで抽出された5fold分のembeddedを平均化した後、concatして一つのembeddedとしました。 - embeddedのコサイン類似度による類似度算出
各testデータのembeddedとtrainデータのembeddedから類似度を算出しました。類似度としてはコサイン類似度を採用しました。
- 後処理、テクニック
各testデータの類似度の最も高い個体の値が閾値未満の場合、予測の1番目を「new_individual」に、それ以外の場合は予測の2番目を「new_individual」としました。また、それ以外の予測は類似度が高い順に残りの4枠を埋めて、各testデータの5つの予測を作成しました。この処理によって、類似する個体が学習用データセットに含まれない場合は未知の個体を最有力候補として予測して、類似する個体が学習用データセットに含まれる場合はその個体を最有力候補、2番手に未知の個体として予測することができます。類似する個体が学習用データセットに含まれる場合に2番手に未知の個体として予測する理由は、実験的にcvスコアが最良であったからです。
また、学習時のテクニックとしてpseudo-labelingを採用しました。本コンペティションでは学習データ数を増加させることで精度が増加しました。
結果と反省点
私たちのチームの最終順位は1589チーム中85位で、銅メダルでした。79位までが銀メダル圏内だったのであと少しで届かなかったことが悔やまれますが、Kaggle部としての初参加のコンペティションでメダルを獲得できて良かったです。
上位チームとの差分としては、学習データセットとして、公開データセットである背びれ領域、全身領域に加えて自らでYolov5を学習して生成した全身領域のデータセットをランダムに混ぜるAugmentation手法を採用していたり、個体識別と同時に種別を分類するモデルも解かせるマルチタスク化を採用していたりと試せていなかった施策が多くあり、解法を読んで勉強になりました。
おわりに
今回はKaggle部として出場したHappywhaleのコンペティションを紹介させていただきました。Happywhaleは今後も再びKaggleでコンペティションを開催する可能性があるのでその時はまた参戦したいと思っています。
Kaggleでは今回のような画像コンペティションに限らず、金融会社が所有している債務に関するテーブルデータから鳥の鳴き声の音声データなど様々な種類のデータが題材とされています。また、コンペティション中に解法のソースコードを参加者が公開している場があったり、コンペティションについて自由に議論が行われている場があったりすることから、初心者にもとりかかりやすいプラットフォームであると感じています。私自身も最初は機械学習がほとんど何もわからない状態からKaggleに参加して、機械学習に少しずつ興味をもつようになりました。まだKaggle初参戦から1年半程度ですが、Kaggleで得た知見を業務や社内コンペティションで活かしたり、反対に業務や社内コンペティションで得た知見をKaggleで活かしたりできている場面もあると実感しています。また、スコアを競って順位をあげていくのが単純にゲーム感覚で楽しいということもあり、今後もKaggleの様々なコンペティションに参加していきたいと思います。
本記事を見て少しでも興味を持っていただけた方は、ぜひ一度参加してみていただけると嬉しいです。
References