AWS Lambda SnapStartを利用してJava Lambda関数高速化の可能性を探る
こんにちは、NRIデジタルの島です。
昨年のre:Inventにて、AWS Lambda(以下Lambda)にコールドスタートの性能を大幅に改善し、初回起動を高速化する「SnapStart機能」のリリースが発表されました。
New – Accelerate Your Lambda Functions with Lambda SnapStart
サーバレスアーキテクチャであるLambdaを使用してアプリケーションを構築する際、必ず課題となるのが「コールドスタートにおける処理遅延」です。特にJavaの場合フットプリントも大きく、またJIT(Just-In-Time)等アプリケーションアーキテクチャの特性上初動が遅いです。ひとたびコードが最適化されると他の言語よりも高速になりますが、初動時からスピードが求められるサーバレスアーキテクチャとの相性はあまり良くないです。これが原因で「LambdaにはJavaは向かない」と判断し、他言語実装への切り替えやコンテナベースの構築に舵を切る方々もいるのではないかと推測します。
しかしながら、Javaはエンタープライズな業務アプリケーションやWebAPI等を実装する上でも優れた言語ですので、Lambda上でも高速に動作させていきたいところです。本記事ではSnapStart機能を試しながらJava Lambda関数の高速化の可能性を探っていきたいと思います。
なお、AWSより2019年のre:Inventにて「Java Lambda関数のベストプラクティス」も提供されております。
Best practices for AWS Lambda and Java
特に性能のチューニングについて現時点でも有用な情報が含まれておりますので、LambdaをJavaで実装しようとしている開発者やアーキテクトの方々は是非ご確認いただければと思います。
Lambdaの課題
Lambdaを使用してアプリケーションを構築する場合、意識しなければならないのがそのライフサイクルです。Lambda関数はリクエスト受信すると以下のライフサイクルで処理を実行します。
Lambda execution environment lifecycleより

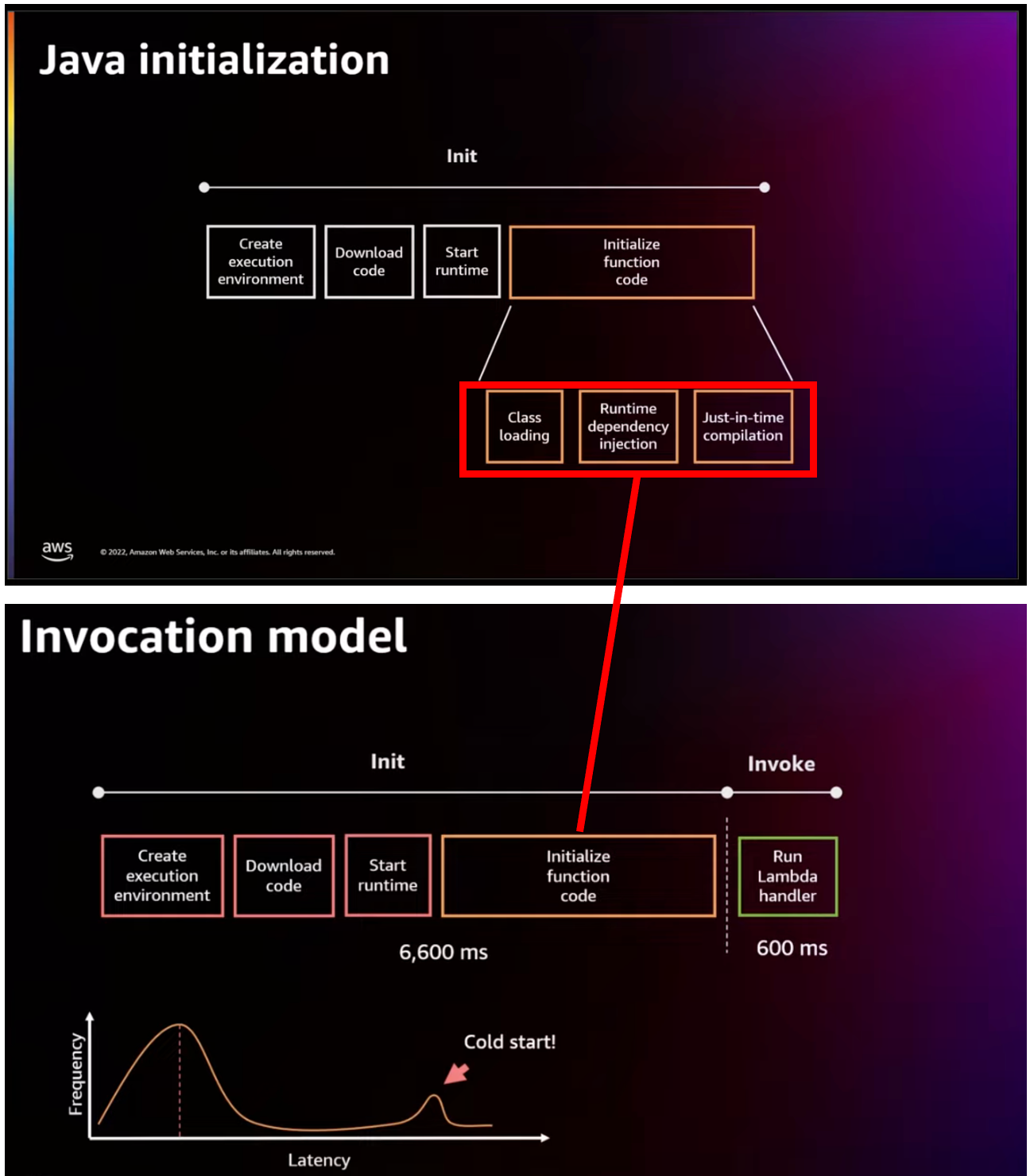
このライフサイクル上の「INITフェーズが実行されるかどうか」が前述した「コールドスタートが実行されるかどうか」であり、処理実行速度に大きく影響します。既に起動された実行環境を再利用する場合はコールドスタートが実行されずINVOKEフェーズから実行される為、INITフェーズのオーバヘッドはありません。しかしながら、既に起動済みの実行環境が時間等により破棄された場合や、捌ききれない多重のリクエストが送信された場合などは新しく実行環境を起動する為コールドスタートとなり、INITフェーズが実行され処理遅延が発生します。
このコールドスタート発生がJavaの場合、より表面化します。Javaは初期処理でクラスロードやDI(Spring等のDIベースのフレームワーク利用の場合)が発生すること、またJIT方式の特性上初動が非常に遅い為です。
re:Invent 2022より
SnapStartの概要
この課題を改善する為に登場したのが「SnapStart」です。SnapStartを利用することで、追加費用なしで最大90%(10倍)の待ち時間を削減可能とのこと。利用ニーズや上記課題を考慮し、現時点ではJava11(Corretto)のみが対象ですが、今後他言語にも展開されると思われます。
re:Invent 2022より

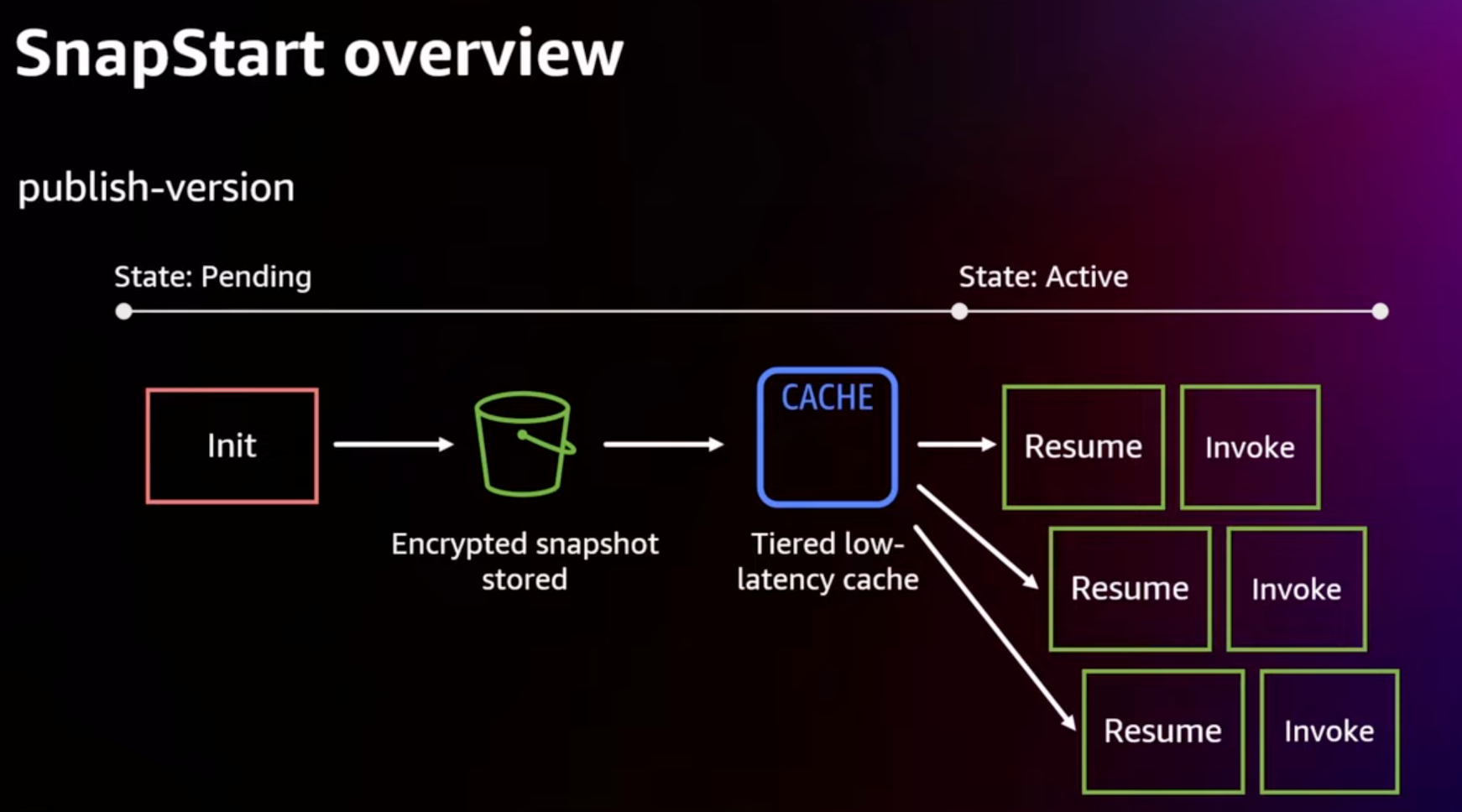
SnapStartを有効にすると、 Lambdaサービスは関数のコードを初期化(=INITフェーズを実行)し、階層化されたキャッシュに初期化済み実行環境のスナップショットを永続化することで、低レイテンシーでのアクセスを可能にします。
re:Invent 2022より
処理性能検証
では、実際にサンプルアプリケーションを用いて処理性能の検証を実施したいと思います。今回実装したサンプルアプリケーションは、ユーザID(UserId)をLambdaで受信し、Amazon DynamoDBに登録されている商品リスト(Items)を応答するというシンプルなアプリケーションです。
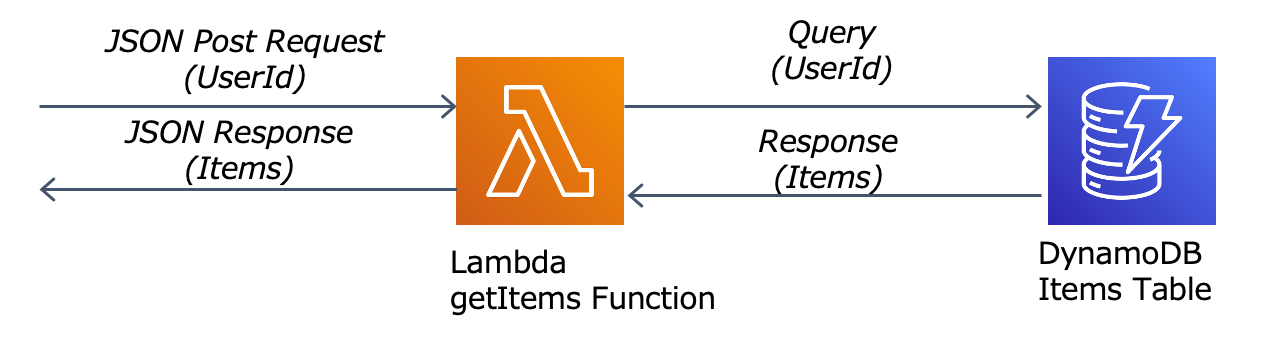
※関数の実装は「Spring Cloud Function」を利用
Spring Cloud Function
処理性能(コールドスタートあり)
まず、コールドスタートが発生した場合の実行処理性能について、SnapStartの有無でどのくらいの違いがあるか比較したいと思います。
※AWS ConsoleのLambdaテストにて実行します
※処理時間が早すぎると差分がわかりにくい為、Lambdaへの割り当てリソースはあまり大きくない値(512MB)としております
・SnapStartなし
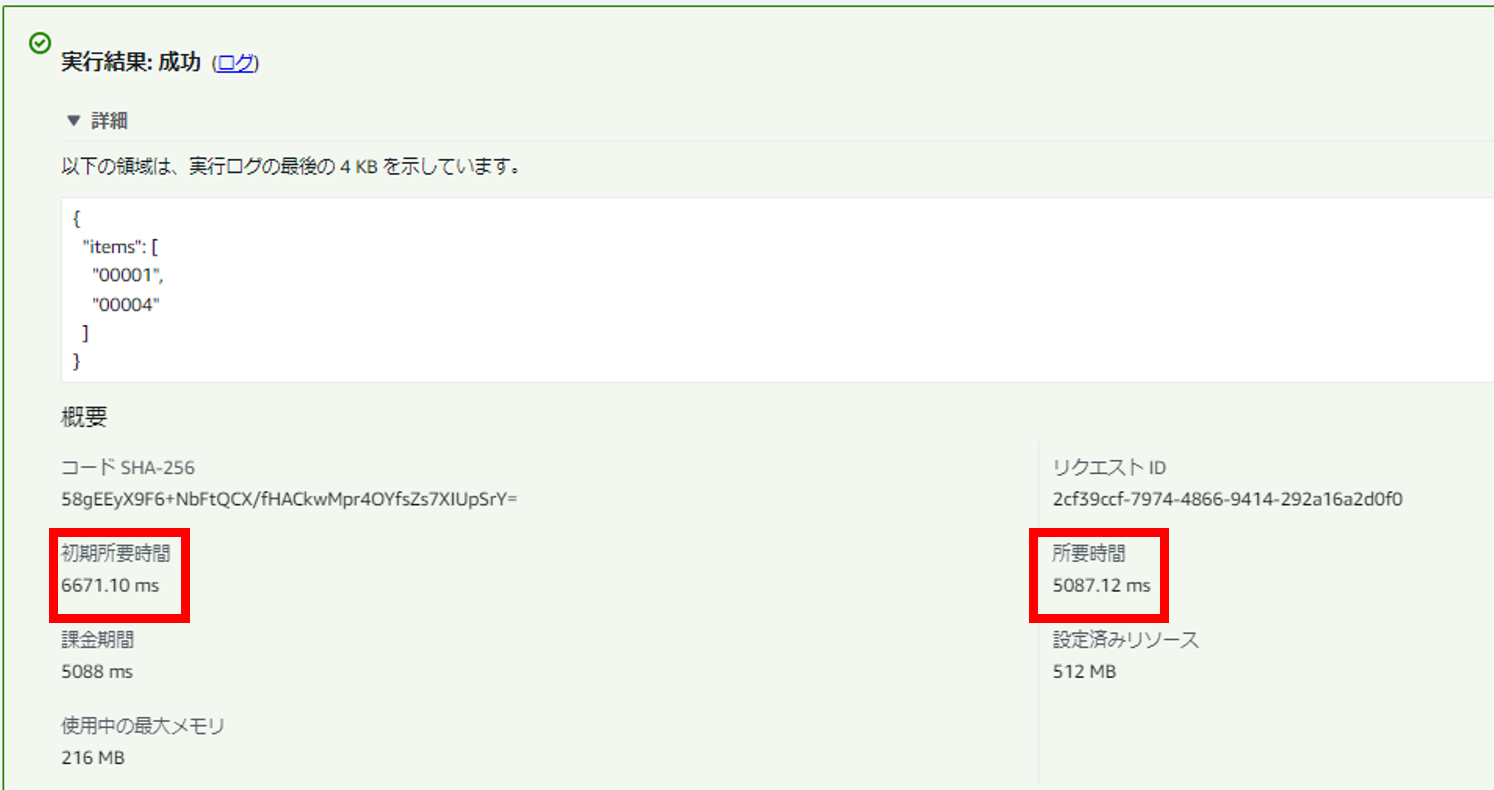
上記「初期所要時間」がINITフェーズでの所要時間となり、実際の処理「所要時間」と合わせておよそ「12秒」もの時間がかかっています。
・SnapStartあり
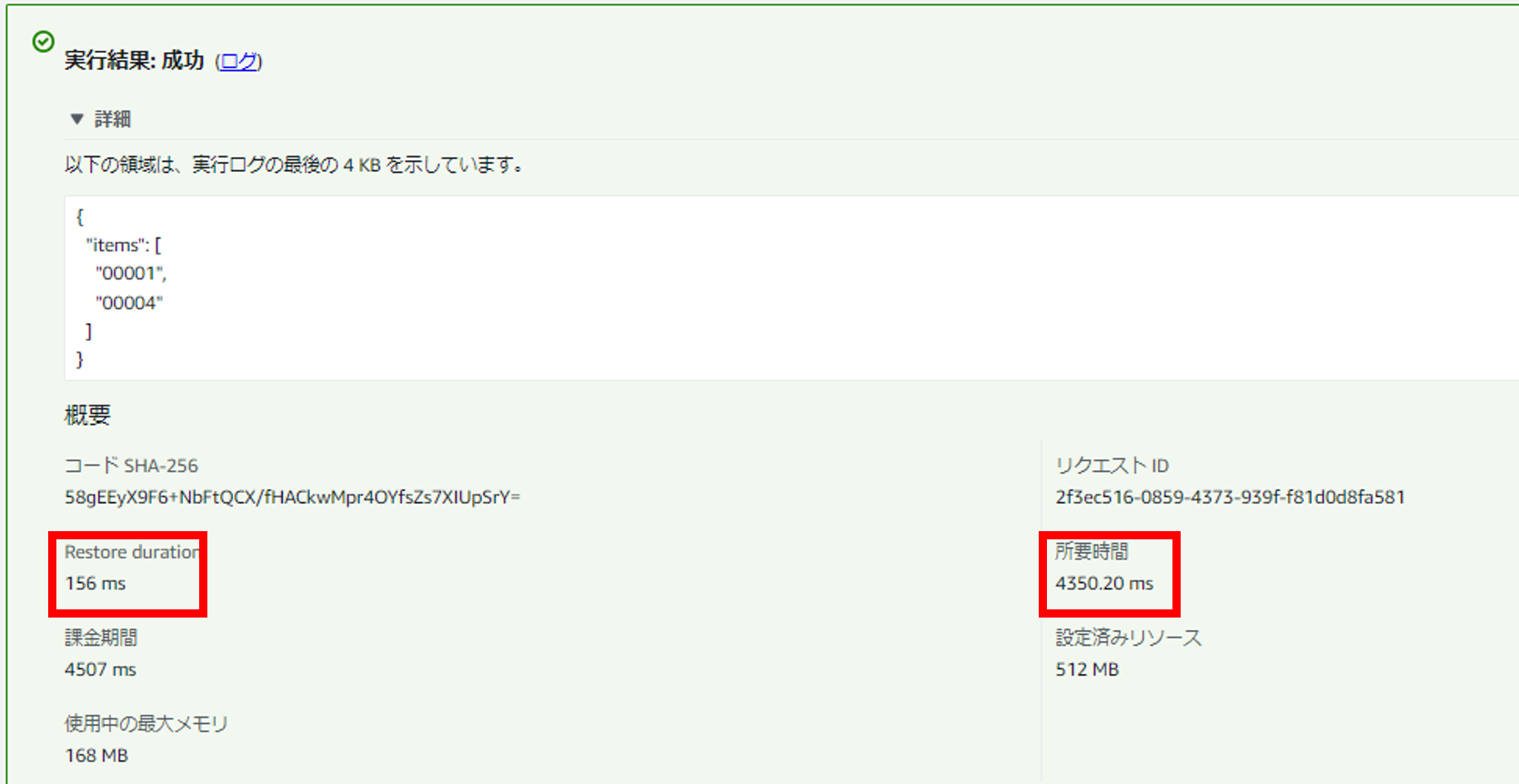
上記「Restore duration」がスナップショットからのリストア時間です。実際の処理の「所要時間」と合わせて「5秒」以内にとなっており、初期処理がなくなっている分改善していることがわかります。
しかしながら、実際の処理の「所要時間」は上記の通り遅いままです。これはJITコンパイルの仕組みによるもの(※1)だったり、Lambda上でJVMを実行する際に発生する諸々のオーバヘッド(※2)が要因かと思います。
※1 JavaはJITコンパイラにより、メソッドが実行されるたび蓄積するプロファイル情報を元にアプリケーションコードを最適化(動的なバイトコード変換)していくので、起動直後は最適な処理性能を発揮できない可能性がある
※2 先に案内済みの「Java Lambda関数のベストプラクティス」には、AWS SDK for Java(DynamoDB Client)利用時のオーバヘッドやクラス遅延読み込みによる大量I/Oなどが指摘されている
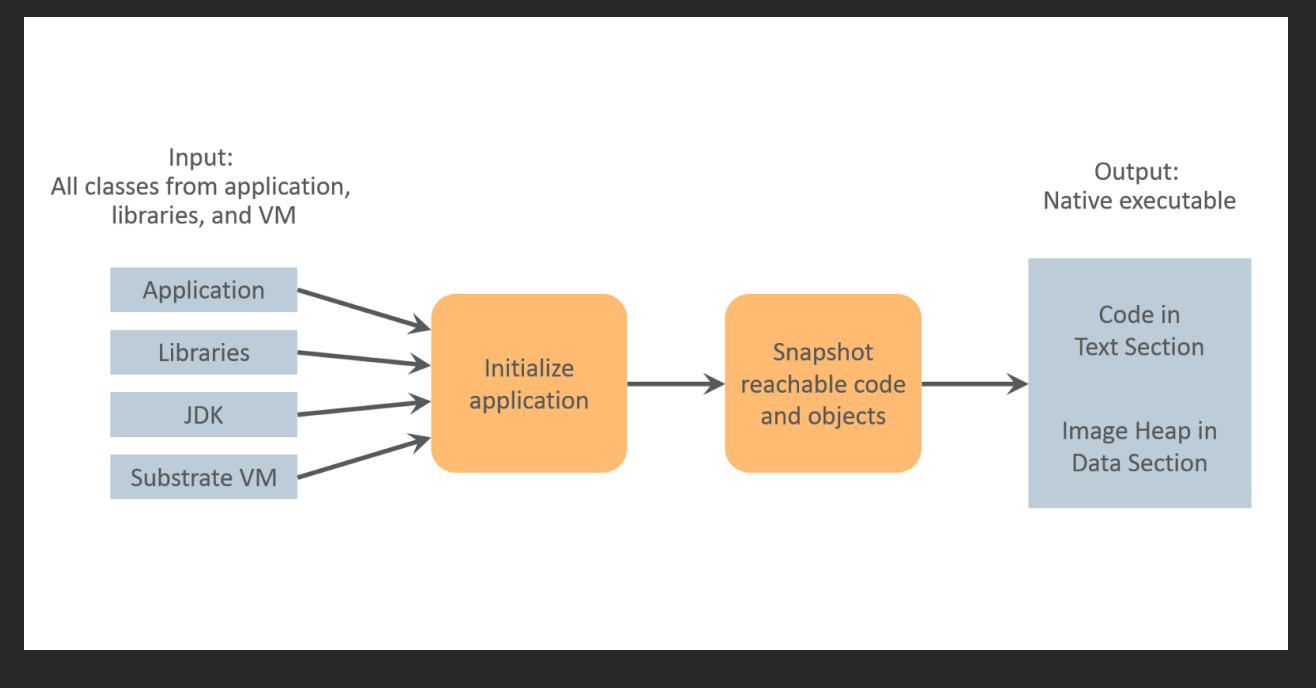
Javaアプリケーションで、実際の処理の「所要時間」を含めた全体処理時間を改善するアプローチとして考えられるのは、アプリケーションをNative化してJVM上で実行することによるオーバヘッドを排除することです。前述した「Java Lambda関数のベストプラクティス」でもコールドスタートを回避し、高速化する為のアプローチとして提案されています。
re:Invent 2019より

では、上記サンプルアプリケーションをGraalVMにてNative化して処理性能を計測してみたいと思います。
※サンプルは「Spring Cloud Function」を利用している為、「Spring Native」を利用してNative化します
GraalVM Native Image Support
・Native版
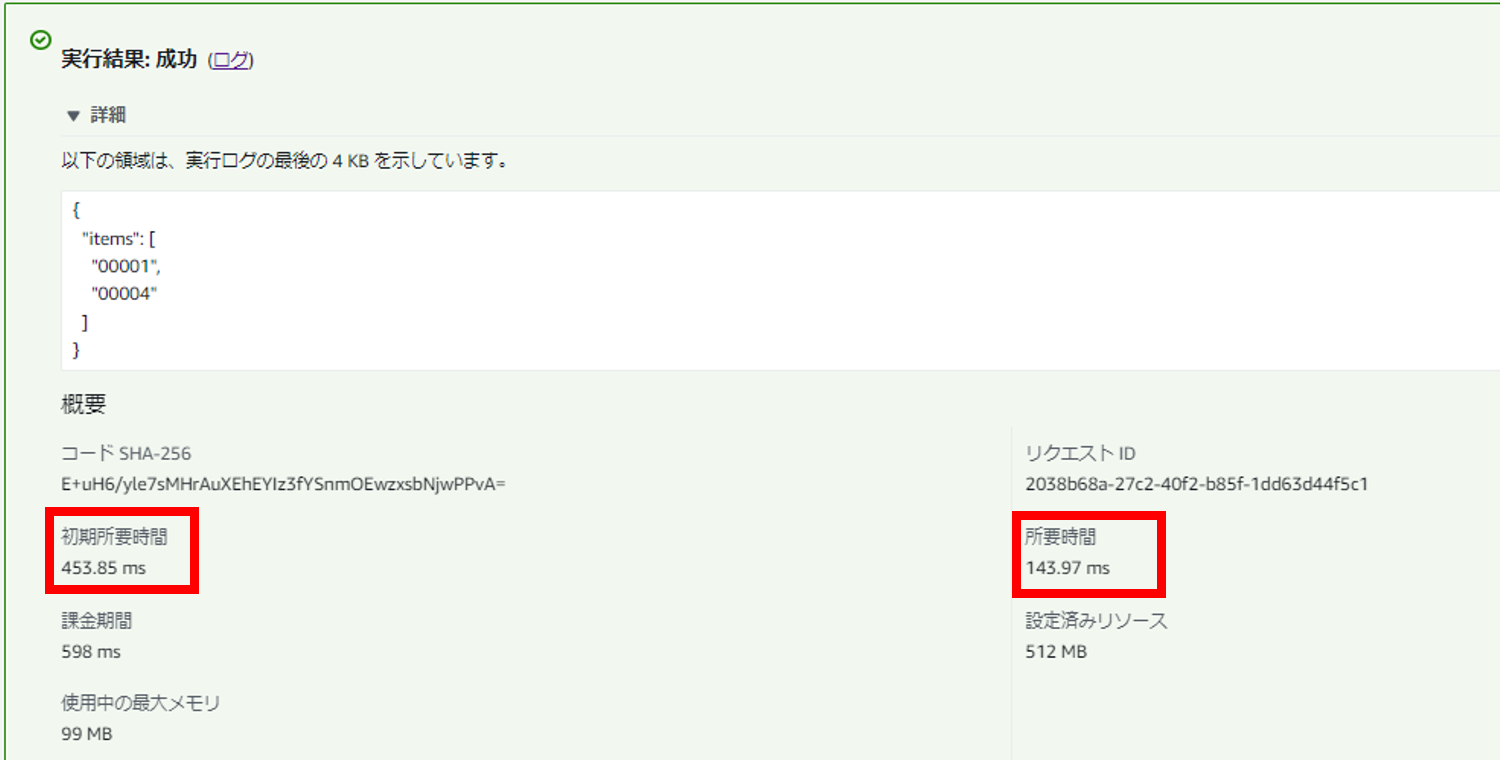
全体処理時間(初期所要時間+所要時間)がおよそ「600ミリ秒」に大幅に改善されました。この結果だけ見ると、SnapStartの有効化よりもNative化した方が断然効果が高いということになります。
しかしながら、Native化に向けたアプリケーションの移行はかなり大変です。本検証のサンプルは規模が小さい為、比較的スムーズに移行できましたが、大規模なアプリケーションコードとなると簡単にはいきません。昨年のre:Inventの以下ページにおいても、Native化は「効果は絶大だが、労力が特大」というのが表されています。
re:Invent 2022より
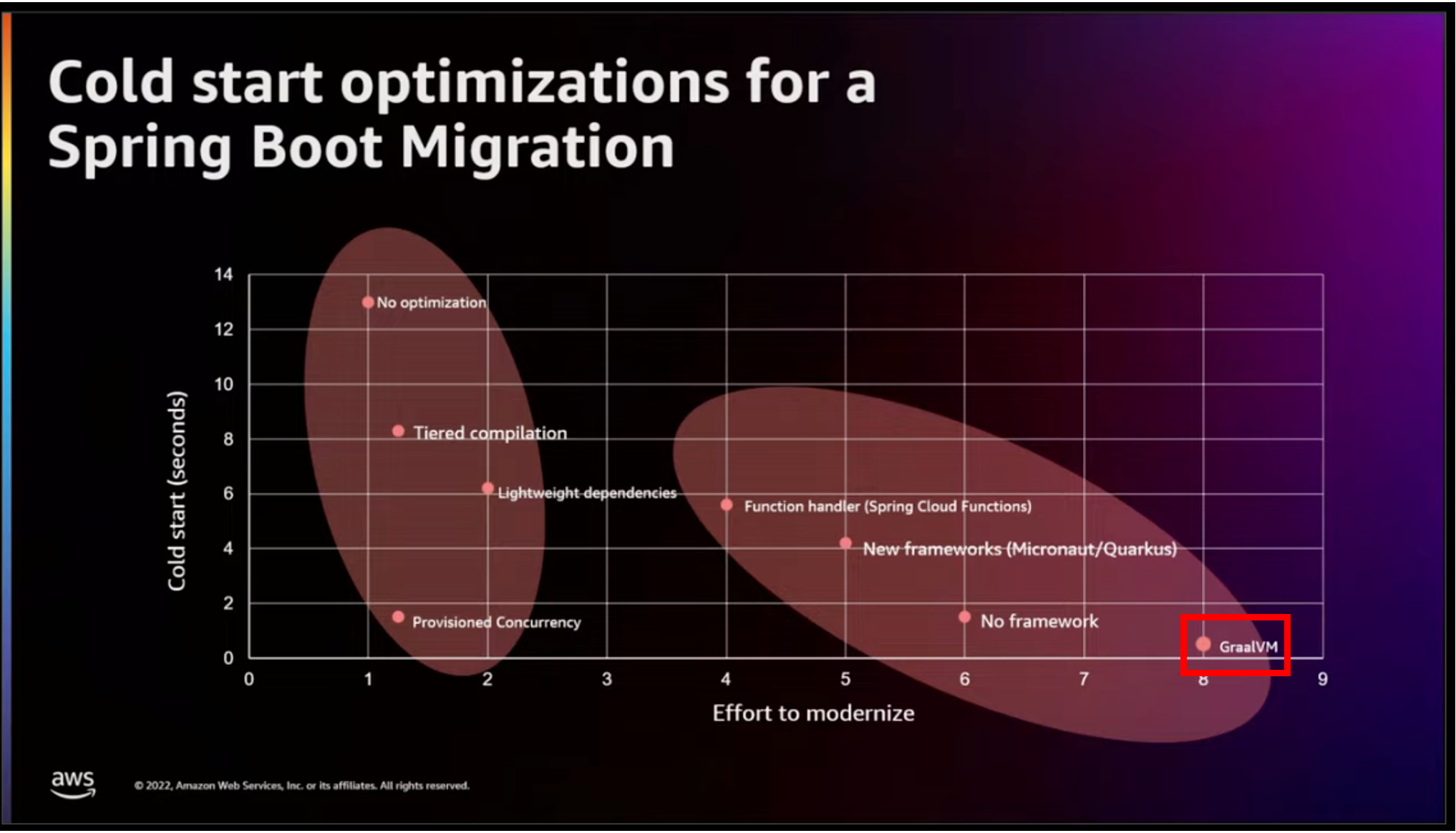
では、他に方法はないでしょうか?
もう一つのアプローチは、SnapStartの仕組みを利用して、「初期化処理内にJVMの暖機運転コードを埋め込む」方法です。前述の通りSnapStartは初期化処理済みのコードをスナップショットしますので、初期化処理内で事前に複数回コードを実行することで「リストア時に暖機運転済みの状態(=JVMがある程度適正化された状態)で処理が開始できるのでは?」という考え方です。
では、実際に本サンプルにおいて、初期化処理内に暖機運転処理を実装します。
※指定回数分Controllerの該当メソッドをコールしているだけです
@SpringBootApplication
public class CoeLambdaSampleApplication implements ApplicationRunner {
private final SampleController controller;
public CoeLambdaSampleApplication(SampleController controller) {
this.controller = controller;
}
public static void main(String[] args) {
SpringApplication.run(CoeLambdaSampleApplication.class, args);
}
@Override
public void run(ApplicationArguments args) throws Exception {
int warmUpCnt = 0;
try {
warmUpCnt = Math.min(Integer.parseInt(System.getenv("WARMUP_COUNT")), 999);
} catch (Throwable t) {}
IntStream.range(0, warmUpCnt).mapToObj(
i -> "user" + String.format("%03d", i + 1)
).forEach(userId -> {
System.out.println("warmUp request=[" + userId + "]");
this.warmUp(userId);
});
System.out.println("warmUp complete!");
}
private void warmUp(String userId) {
Response response = this.controller.apply(new Request(userId));
System.out.println("warmUp response=" + userId + "=>" + response.getItems());
}
}
・SnapStartあり+ 暖機運転あり
「WARMUP_COUNT=100」に設定して実行した結果です。
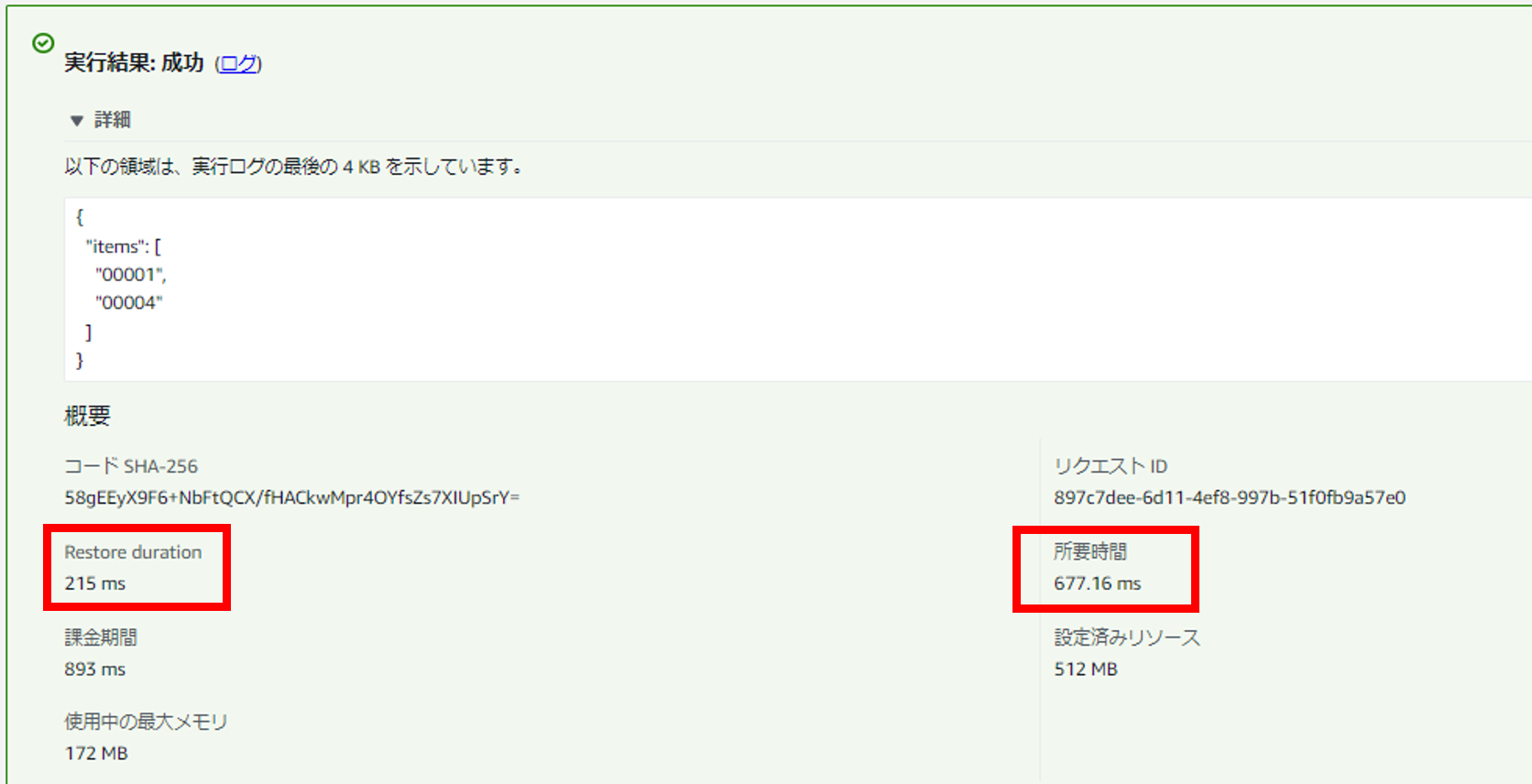
所要時間がおよそ「700ミリ秒」に改善され、全体処理時間(リストア時間+所要時間)でも暖機運転なしの場合の「5秒」以内から「1秒」以内に改善しています。Native版には劣りますが、かなりの処理性能改善となりました。
処理性能(コールドスタートなし)
では、次にコールドスタートの発生がなかった場合、暖機運転ありなしで差があるか確認してみます。
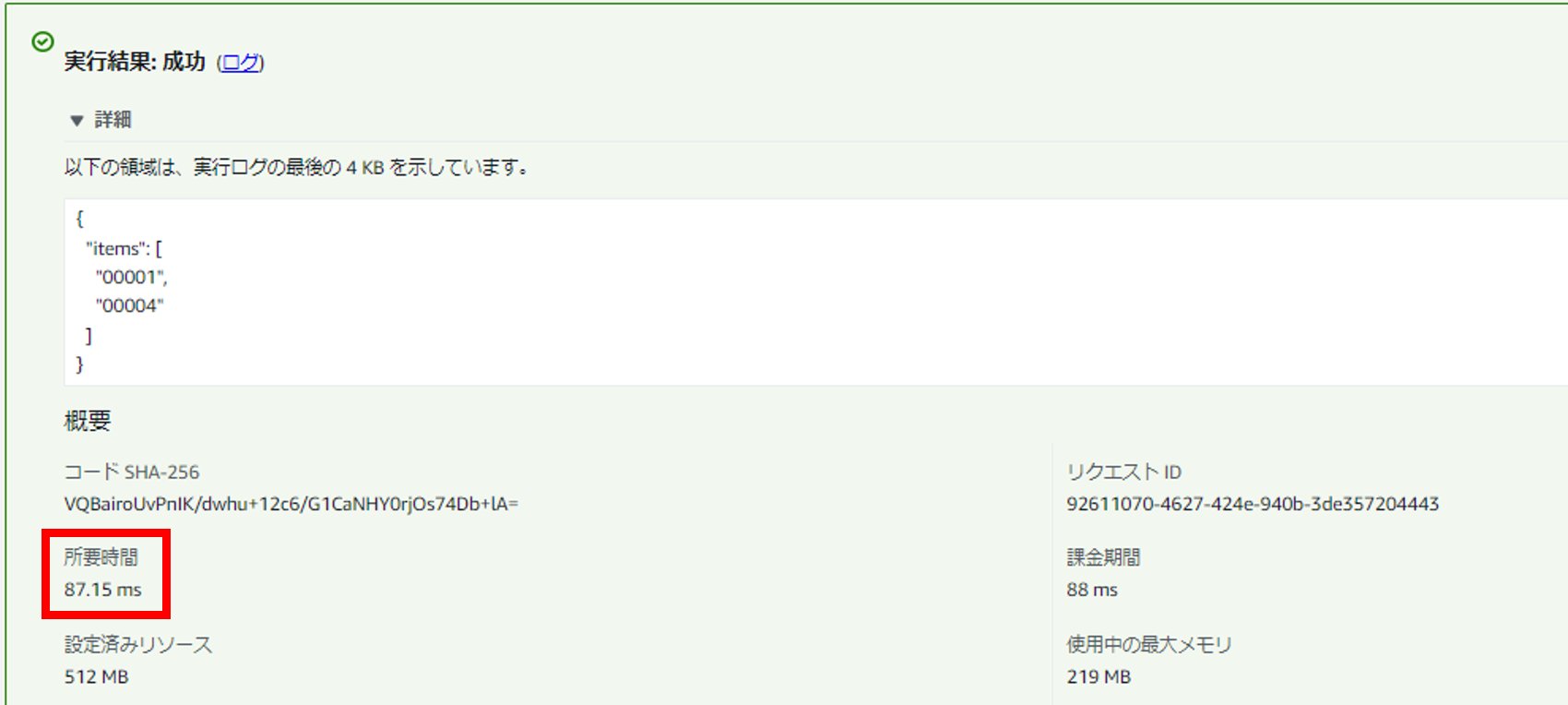
・暖機運転なし
・暖機運転あり
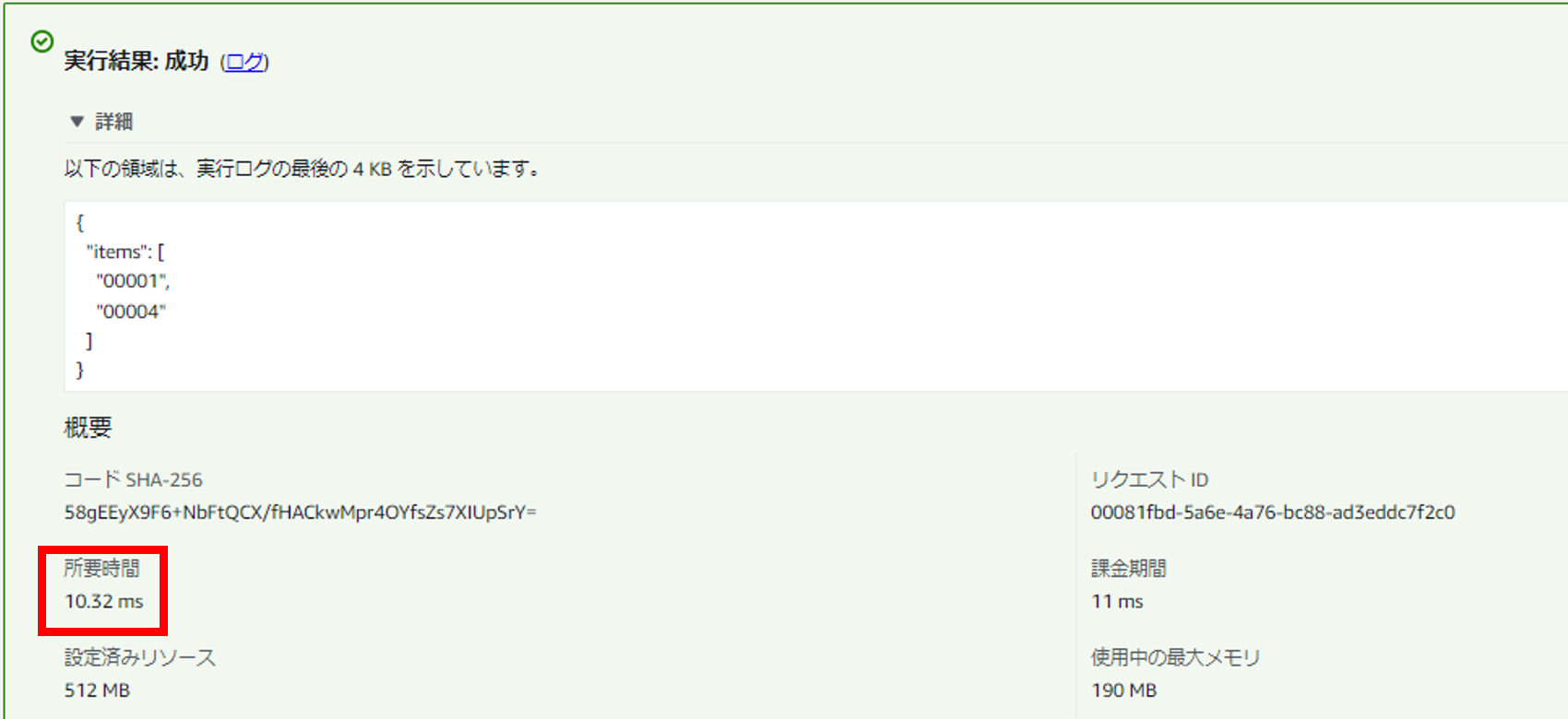
タイミングによるものかもしれないので確実なことは言えませんが、こちらもそれなりの差(つまり暖機運転効果)がありそうでした。
(複数回実行してみましたが、「暖機運転なし」はしばらくの間「50〜100ミリ秒」の速度でした)
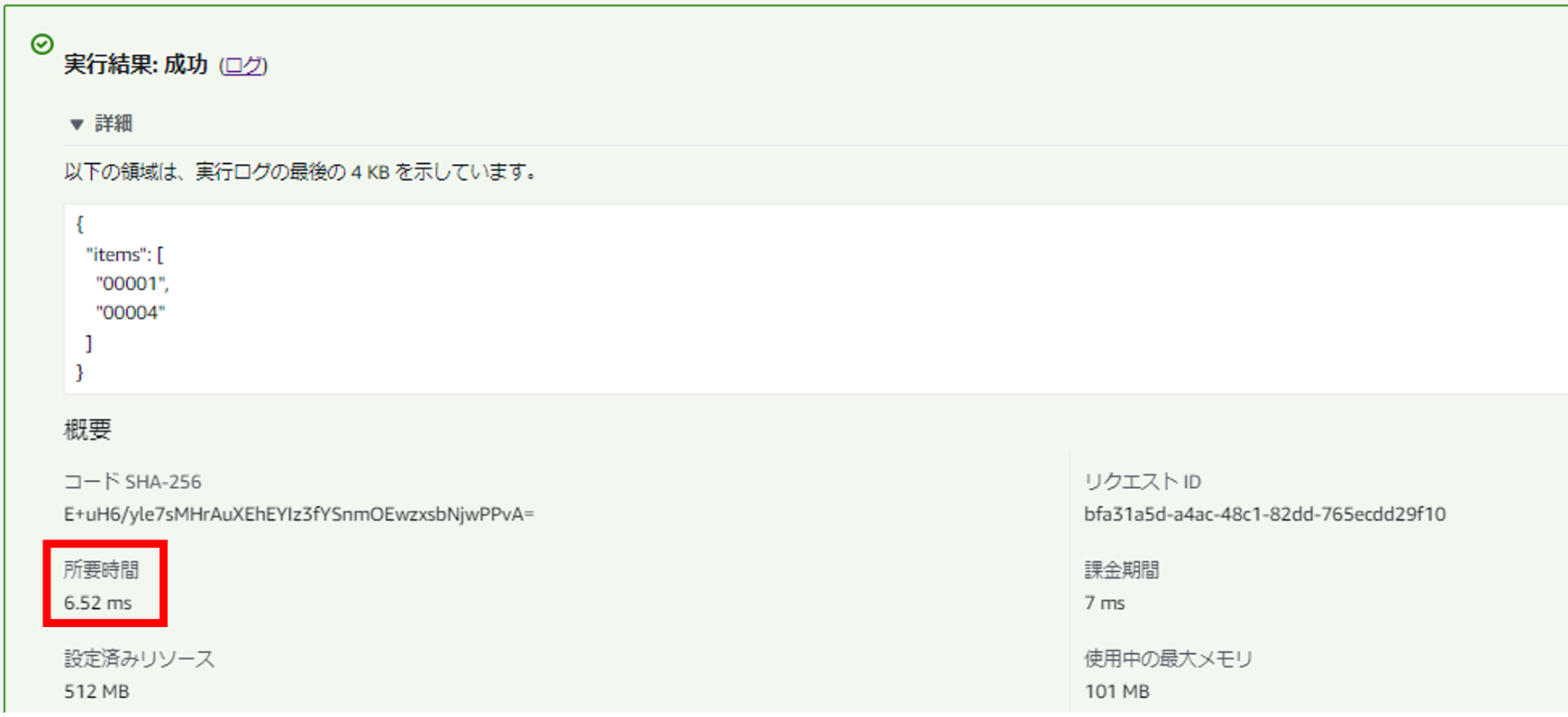
なお、Native版は以下の通り、より高速でした。
・Native版
処理性能(ラッシュテスト)
テスト実行にて効果が確認できたところで、以下の要領にてラッシュテストを実施してみたいと思います。
ラッシュテストにはWebアプリケーション向けの負荷テストツールである「Gatling」を使用します。
Gatling(OSS版)
Open Source Load testing – Gatling
パターン
- JVM版(SnapStartなし/暖機運転なし)
- JVM版(SnapStartあり/暖機運転なし)
- JVM版(SnapStartあり/暖機運転あり)
- Native版
シナリオ
TPS:10
実行時間: 1分間
RampUp:なし
❶ JVM版(SnapStartなし/暖機運転なし)
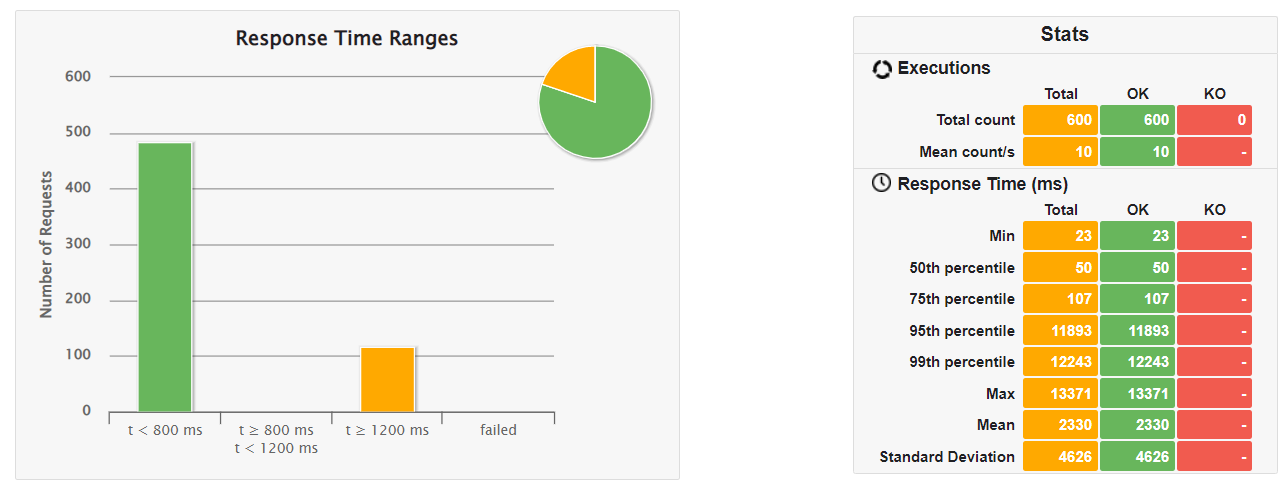
❷ JVM版(SnapStartあり/暖機運転なし)
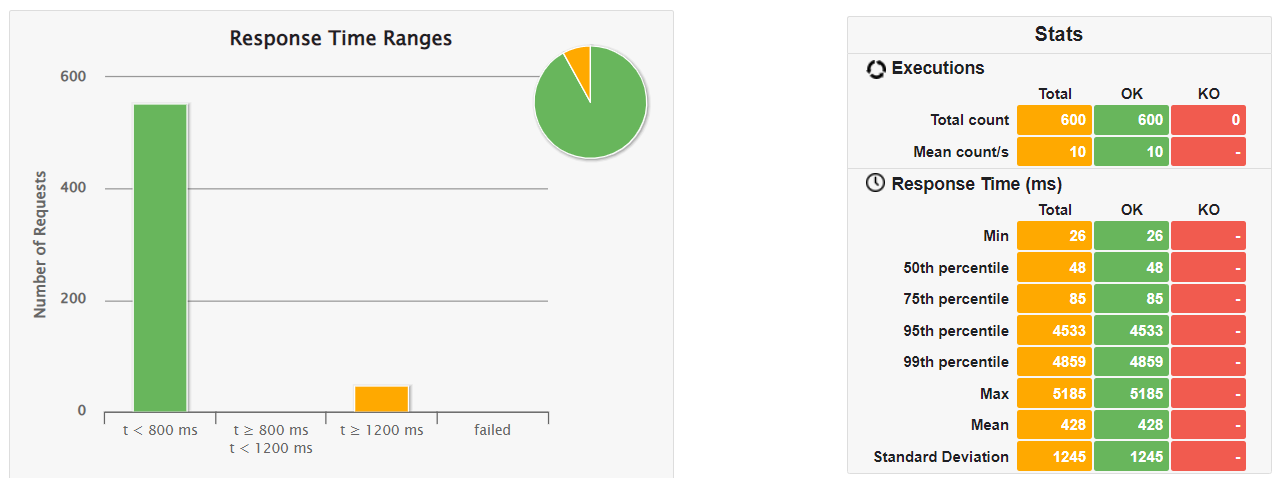
❸ JVM版(SnapStartあり/暖機運転あり)
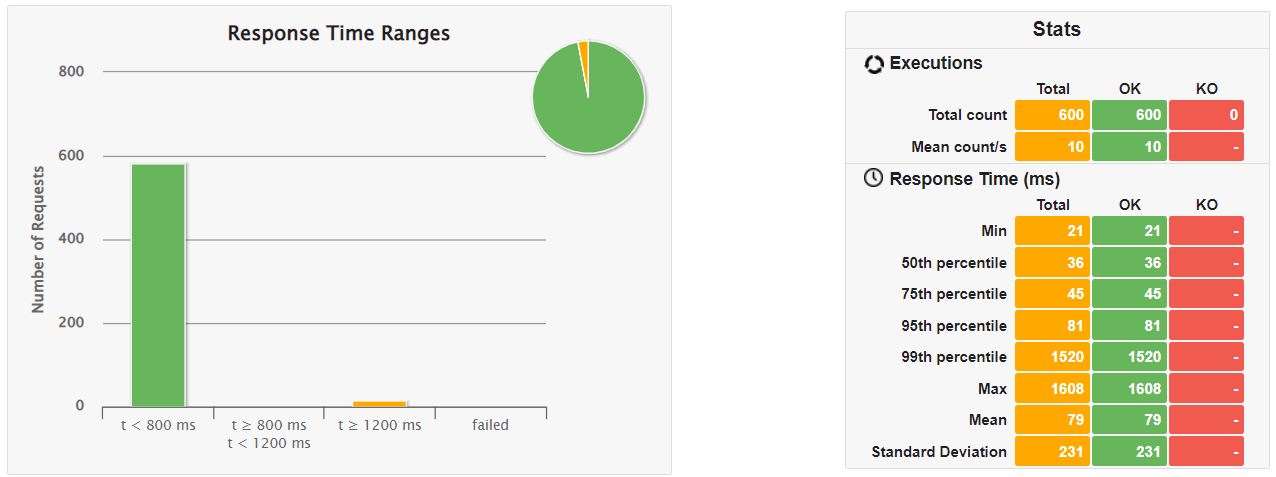
❹ Native版
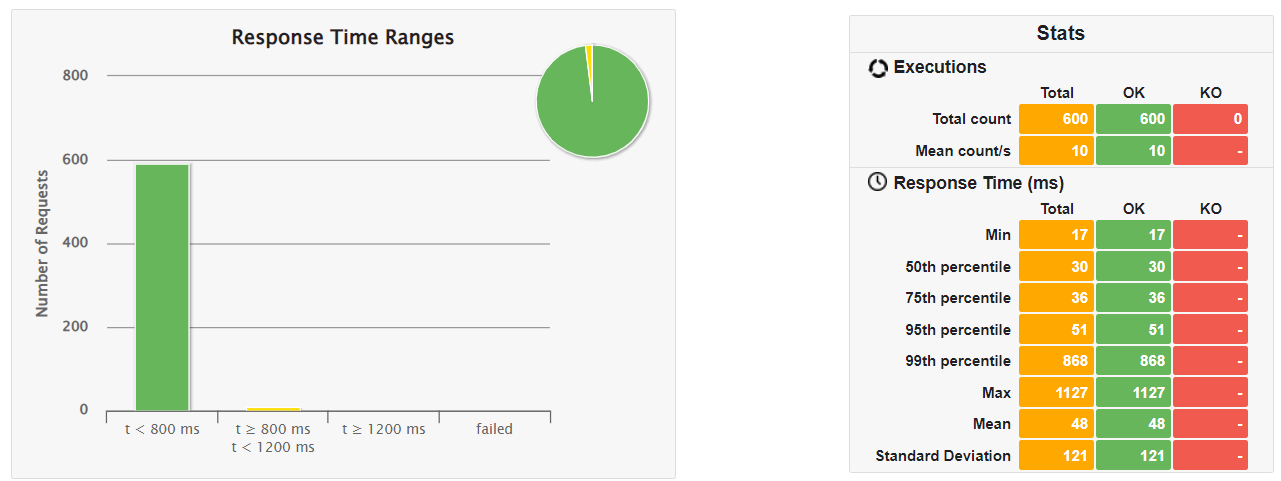
以下結果サマリです。
| Min | 50th percen tile |
75th percen tile |
95th percen tile |
99th percen tile |
Max | Mean | |
|---|---|---|---|---|---|---|---|
| ①SnapStartなし/暖機運転なし | 23ms | 50ms | 107ms | 11893 ms |
12243 ms |
13371 ms |
2330 ms |
| ②SnapStartあり/暖機運転なし | 26ms | 48ms | 85ms | 4533 ms |
4859 ms |
5185 ms |
428ms |
| ③SnapStartあり/暖機運転あり | 21ms | 36ms | 45ms | 81ms | 1520 ms |
1608 ms |
79ms |
| ④Native | 17ms | 30ms | 36ms | 51ms | 868ms | 1127 ms |
48ms |
本ラッシュテストの結果において、Mean(平均)、Max(最大)、Min(最小)、各パーセンタイル、どのレスポンスタイムからも予想通りNative版が最も良い結果となりましたが、暖機運転込みのSnapStartもかなり良い結果でした。
性能チューニングを実施しようとした場合、移行コストや品質等とのバランスも考慮する必要があります。Native化は前述した通り移行コストが膨大で、品質的なリスクも大きいかと思いますが、SnapStartはアプリケーションの変更は少なく、追加コストもなくかなりの性能メリットを享受できます。その為、筆者は、まずはSnapStartを使用したチューニングのご検討をいただくのが良いのではないかと思います。その際、前述した暖機運転処理の導入も是非ご検討いただければと思います。
なお、INITフェーズを短縮するという目的としては、以下「Provisioned Concurrency」機能も存在します。
https://aws.amazon.com/jp/blogs/aws/new-provisioned-concurrency-for-lambda-functions/
SnapStartと目的が類似してはおりますが、「Provisioned Concurrency」は事前プーリングにより処理時間短縮を実現します。実際に実行環境をプールしている為、SnapStartのようなリストアも不要でSnapStartよりも高速に処理出来るようです。一方、以下がデメリットとなります。
- 実際に実行環境をプールしている為、その実行環境稼働分のコストが課金される
- 事前プール方式の為、アクセス数の事前予測が必要でプールする実行環境数の調整が難しい。
→一定数にした場合、繁忙期等にはプール数が足りなくなりコールドスタートが発生、逆に繁忙期に合わせると通常時に余分なコストが発生する為、プール数をスケジューリングするような工夫が必要。
この辺りはシステムの要件(コスト優先か性能優先か)や業務量・アクセス数の予測が可能か、等でどちらを利用するか考えていく必要があると思います。
また、SnapStartを採用する場合は、いくつか考慮しなければならない事項がございますので、最後にそれらについて共有させていただきたいと思います。
考慮事項
SnapStart利用時には以下のような点を考慮する必要があります。
ネットワークコネクションの切断
INITフェーズ内でデータベース等へのコネクションを確立している場合、スナップショットからの復元時にはそのコネクションが維持されてない可能性が高いです。その為、コネクションが無効な場合は再接続するロジックが必須となります。
サンプルコードに「RDBからユーザの名前を取得する」機能を追加してみます。
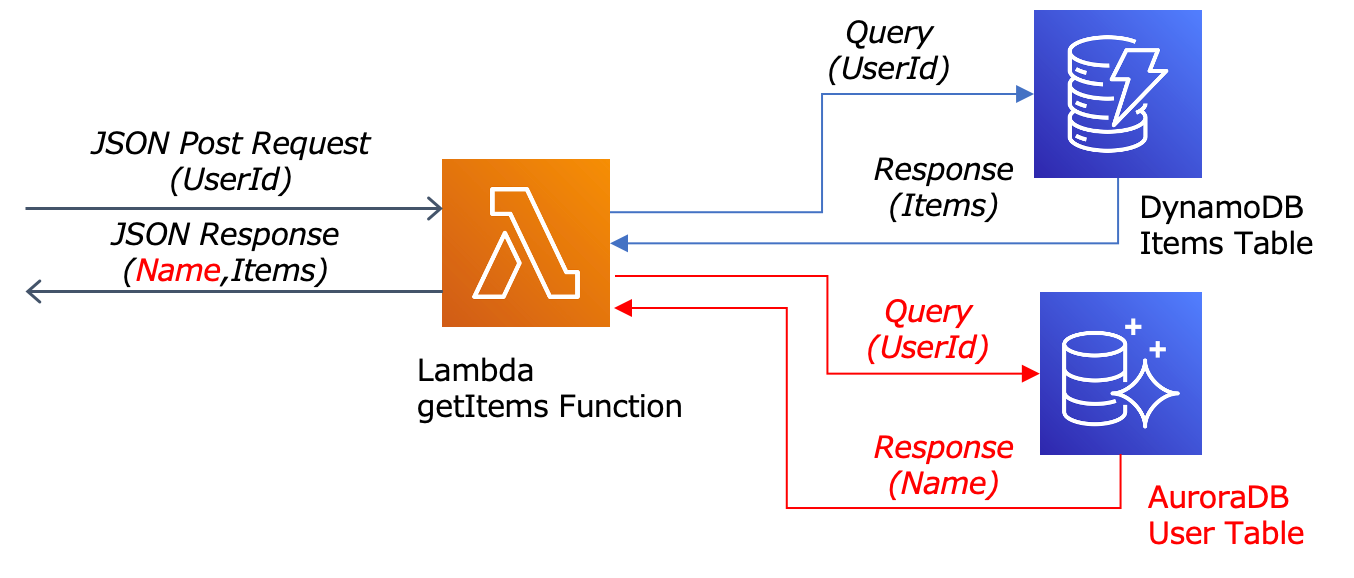
コネクションの生成は、INITフェーズで実行されるように以下のようなローレベルコードで実装してみます。
@Component
public class ConnectionManager {
private Connection connection;
public ConnectionManager() {
this.connect();
}
private void connect() {
try {
this.connection = DriverManager.getConnection(
"jdbc:mysql://" + System.getenv("DB_URL"),
System.getenv("DB_USER"),
System.getenv("DB_PASSWD")
);
System.out.println("connect success...");
} catch (SQLException e) {
throw new RuntimeException(e);
}
}
public Connection getConnection() {
return this.connection;
}
}
通常(SnapStartを利用しない)は正常に動作します。
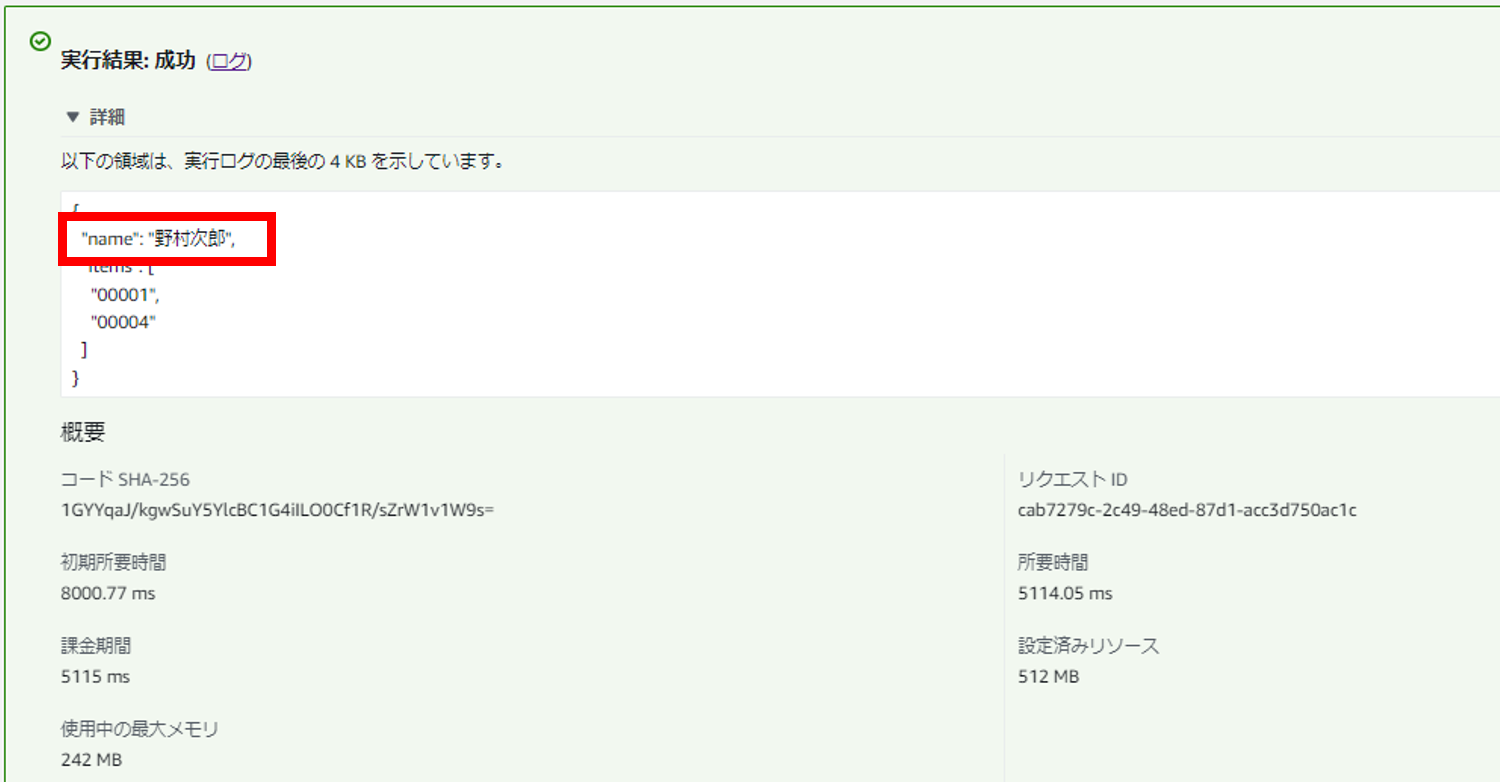
SnapStartを有効化し、RESTOREフェーズが発生する場合はやはりエラーになりました。
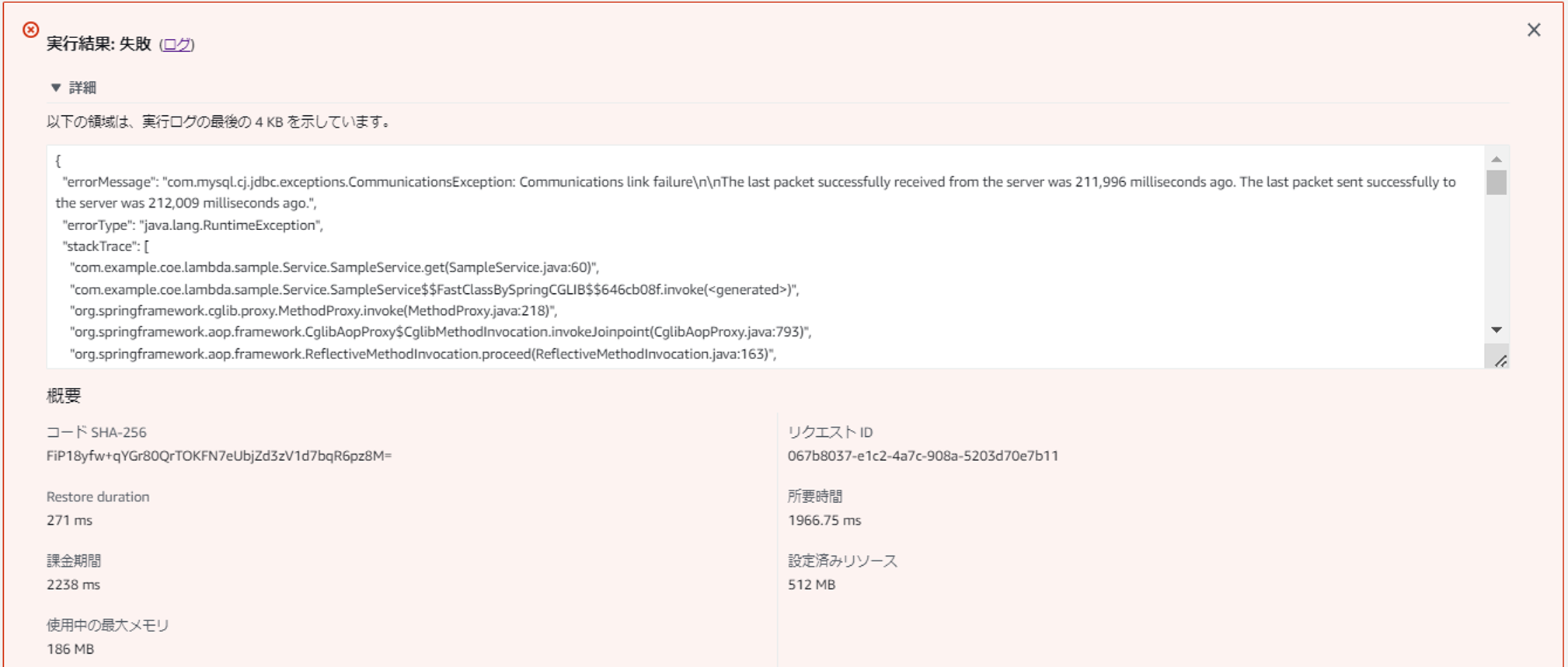
回避方法は前述の通り再接続のロジックを実装することです。上記「getConnection」メソッドに再接続の処理を追加することで正常に動作しました。
・・・
public Connection getConnection() {
try {
if (!this.connection.isValid(1)) {
this.connect();
}
} catch (SQLException e) {
throw new RuntimeException(e);
}
return this.connection;
}
・・・
なお、コネクションの検証や再接続の実装場所は、以下公式ページになる「afterRestoreランタイムフック」を利用することも可能です。
Runtime hooks for Lambda SnapStart – AWS Lambda
一意性の欠如
SnapStartはINITフェーズ実行後のスナップショットをキャッシュする為、動的に生成したい値があったとしてもINITフェーズで生成した値が再利用されてしまいます。(実行環境が変わっても毎回同じ値)
サンプルコードに「実行環境ごとに一意にしたい実行IDを生成する」機能を追加してみます。
以下のようにStaticな変数を定義し、INITフェーズでUUID値を生成します。
@Service
public class SampleService {
private static UUID execId = UUID.randomUUID();
public SampleService(DynamoDbClient dynamoDbClient) {
this.dynamoDbClient = dynamoDbClient;
}
public Response get(String userId) {
・・・
return new Response(items, execId.toString());
}
}
複数回実行してみます。
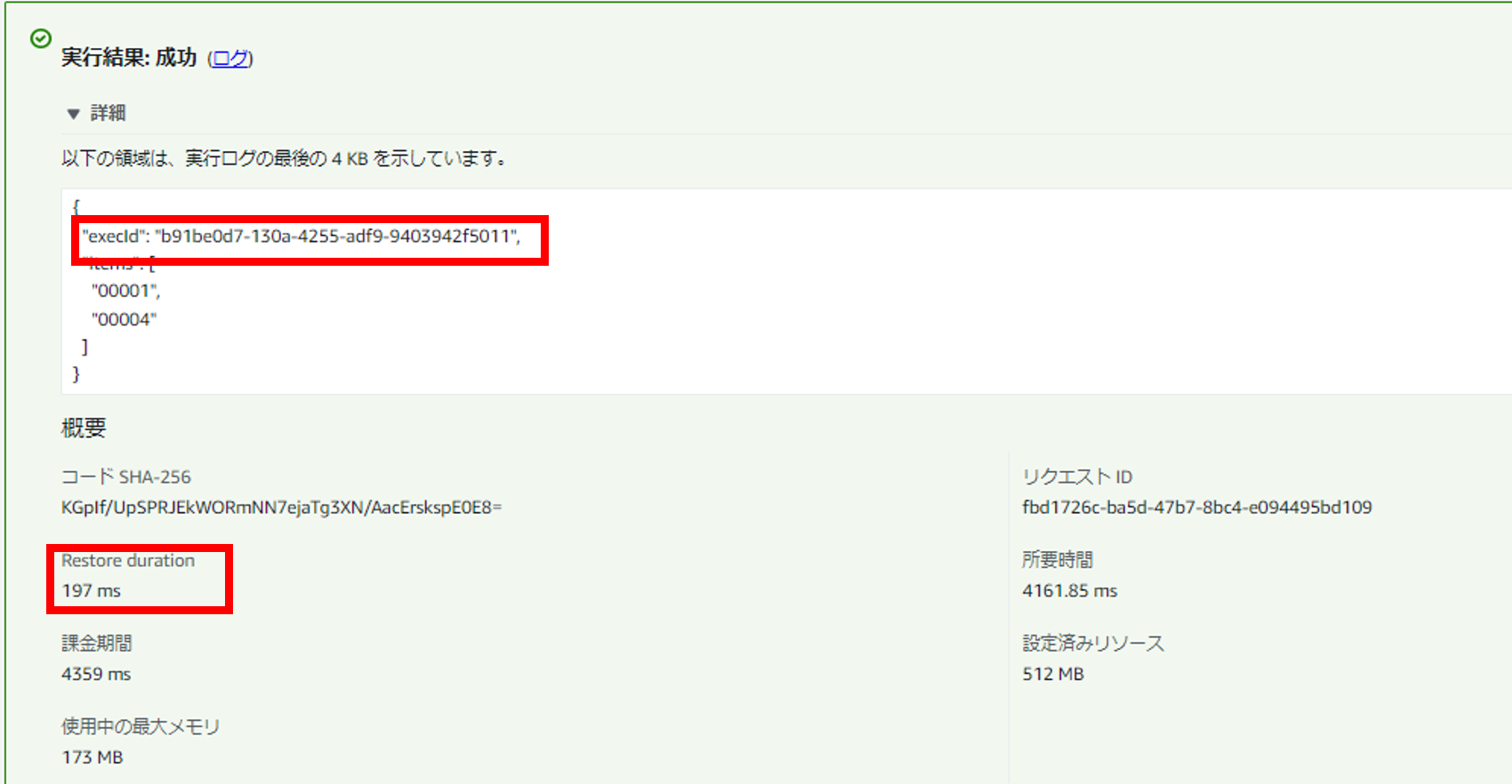
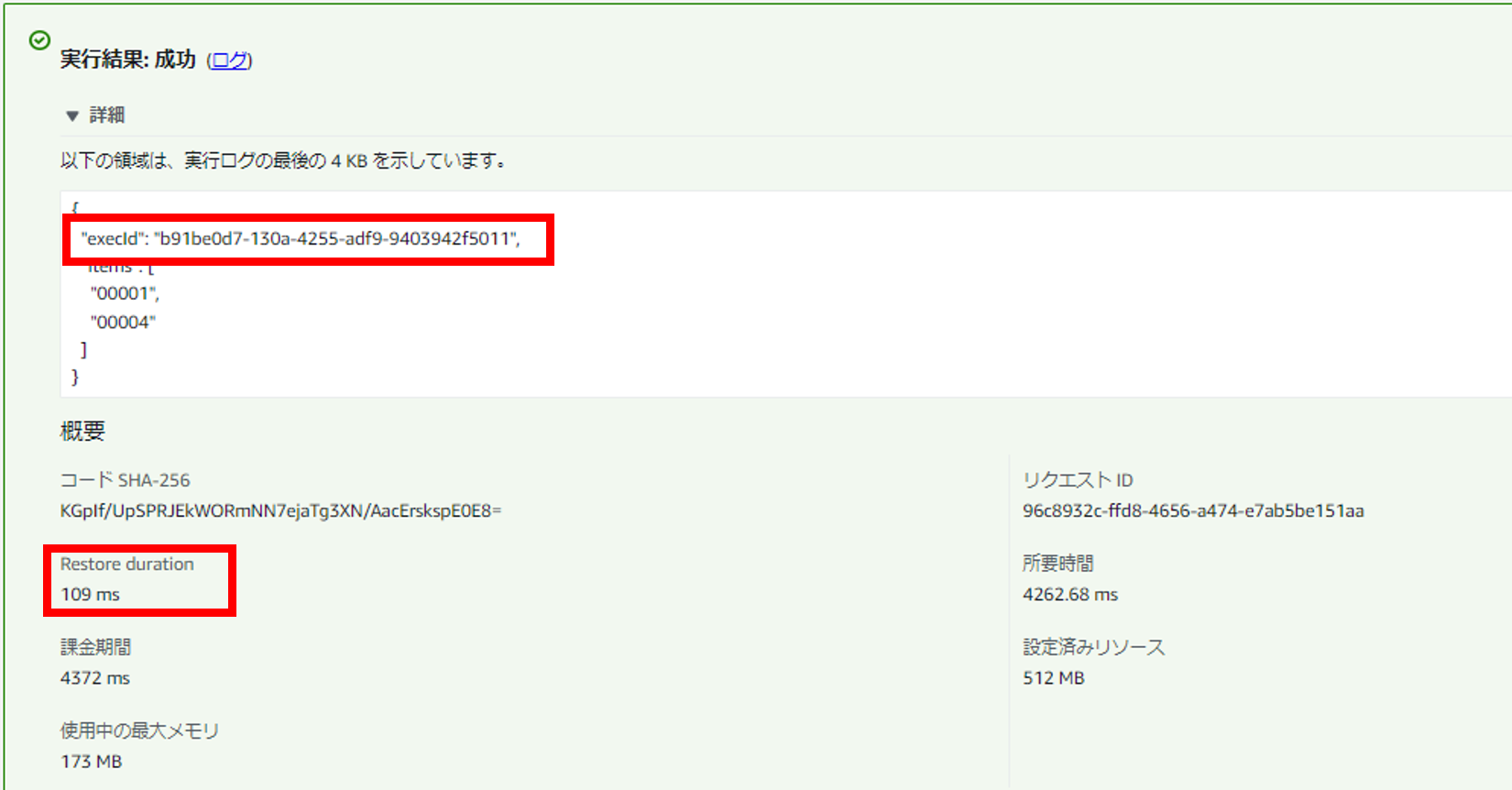
結果の通り、コールドスタートが発生して実行環境が切り替わっても実行IDが同値になってしまいます。
実行環境ごとに値を切り替えたい場合は、公式ページにあるように初回実行時に値を生成します。
Handling uniqueness with Lambda SnapStart – AWS Lambda
・・・
private static UUID execId = null;
public SampleService(DynamoDbClient dynamoDbClient) {
this.dynamoDbClient = dynamoDbClient;
}
public Response get(String userId) {
if (execId == null) {
execId = UUID.randomUUID();
}
・・・
return new Response(items, execId.toString());
・・・
こうすることで、以下の通り実行環境ごとに実行IDが別値となりました。
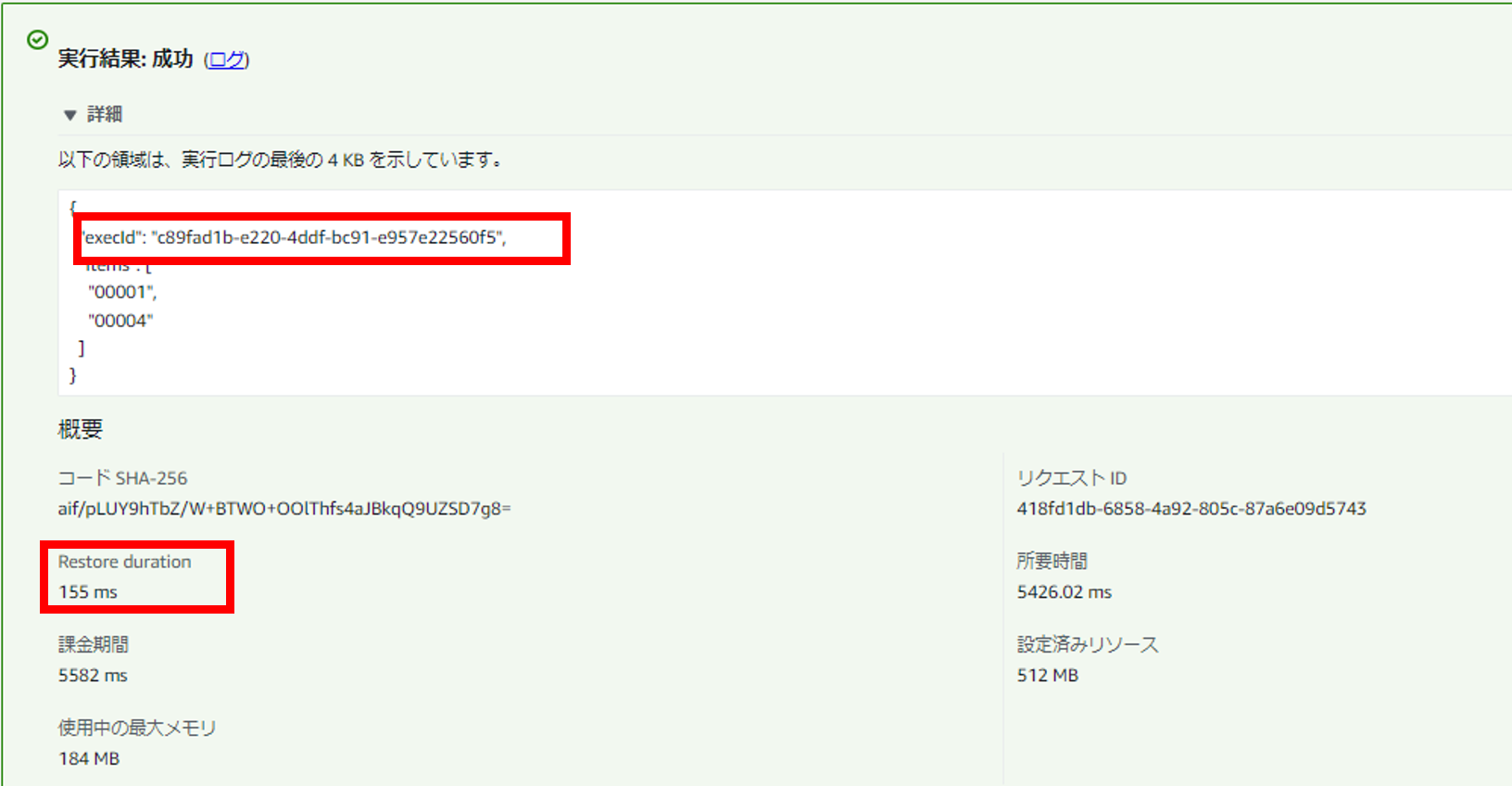
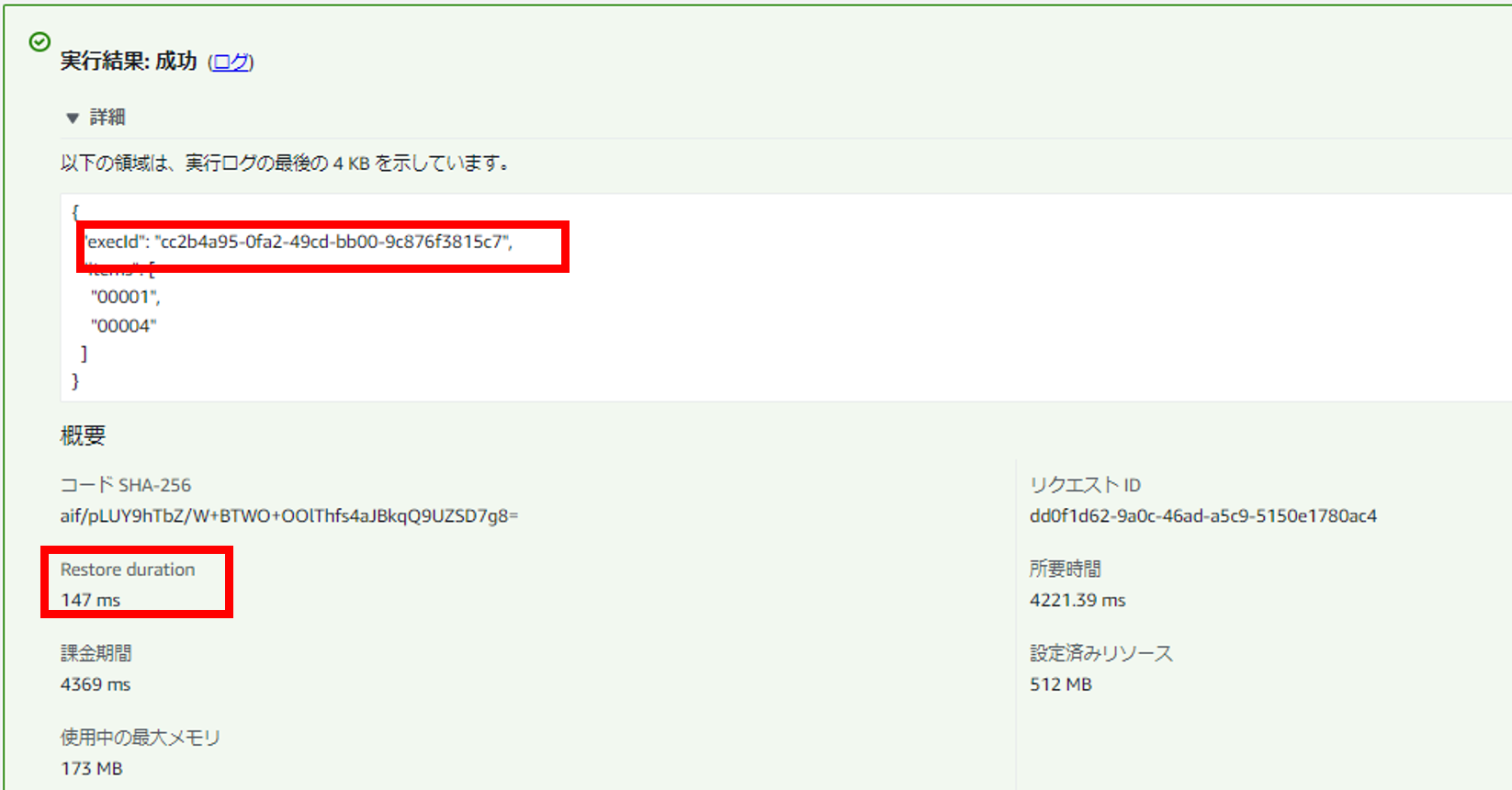
なお、上記は「実行環境ごと」に一意にしたい場合ですが、このような要件は稀で、どちらかというと「実行ごと」に一意にしたい要件の方が多いかと思います。そのような場合はSnapStart云々関係なく、コールドスタートによるINITフェーズが実行されなくとも、一意性が担保されるような実装の考慮が必要となります。AWSでは以下公式ページに記載の通り、「疑似乱数ジェネレーター (CSPRNG)」の利用を奨励しているようです。
Use cryptographically secure pseudorandom number generators (CSPRNGs)
アプリケーションの要件でランダム値の生成が必要な場合は、考慮いただければと思います。
関数バージョンの非アクティブ化
SnapStartは関数バージョンの作成で有効化されますが、呼び出しのない状態が14日続くとその関数のバージョンは非アクティブになりスナップショットが削除されます。この状態で関数バージョンの呼び出しが行われると、そのタイミングでINITフェーズを含んだコールドスタートが実行されてしまいます。INITフェーズに前述した暖機運転コード等時間がかかる処理を入れていると、長い時間処理遅延が発生することになってしまう為注意が必要です。
詳細は以下公式ページをご参照ください。
Activating and managing Lambda SnapStart – AWS Lambda
さいごに
冒頭でも述べた通り、これまでLambdaとJavaとの相性はあまり良くないと考えていましたので、今回のSnapStartのリリースは、筆者のようなJavaをメインに扱うアプリケーションアーキテクトには大変嬉しいものとなりました。
システムをモダナイゼーションする際のアーキテクチャの選択肢として、コスト効率に優れたサーバレスアーキテクチャの採用は有力です。今回の検証を通して、Java Lambda関数の高速化に向けた手応えを感じることができたので、引き続き実用化に向けた検証を進めてまいりたいと思います。
以上