画像生成AIの技術紹介とAI生成画像の判別モデル
こんにちは。NRIデジタルの永間です。
昨今のAIトレンドとして、DALL・E2やStable Diffusionといった画像生成AIが注目を集めています。本記事では、筆者が画像生成AIについて調査した内容と、AI生成画像の自動判別を目的に実装したソリューションについてご紹介します。
画像生成AIについて
画像生成AIとは、ユーザが生成したい画像のイメージを単語や文章で入力することで、そのテキストに沿った画像を生成してくれるAIモデルを指します。
今年の4月にアメリカのAI開発企業Open AIがDALL・E2を発表したのを皮切りに、2022年は数多くの画像生成AIが発表され注目を集めました。写実的でリアリティのある画像を生成するモデルや、幻想的でアーティスティックなイラストを生成するモデルなど、一口に画像生成AIと言ってもその特徴は様々です。下記に画像生成AIの一例をご紹介いたします。
| 開発者 | 発表時期 | 特徴 | |
|---|---|---|---|
| DALL・E2 | Open AI | 2022年4月 | 120億のパラメータを持つ大規模な画像生成モデル |
| Midjourney | Midjourney | 2022年7月 | 高品質なイラスト生成を得意とする画像生成AI |
| Stable Diffusion | Stability AI | 2022年8月 | ソースコードがGitHubにて公開されている |
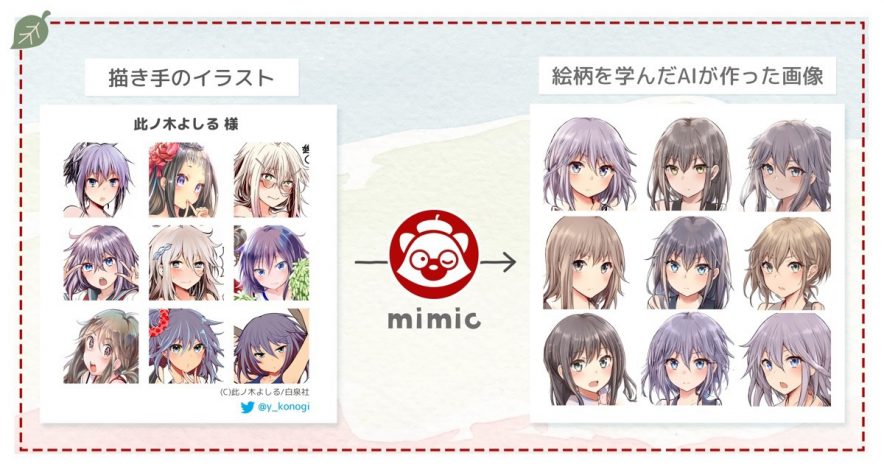
| mimic | RADIUS5 | 2022年8月 | 描き手の個性を反映したイラスト生成AI |
画像生成AIが抱える課題
イラストやアート作品などクリエイティブな領域に進出する新しいAI技術として多くのビジネス機会創出が期待される画像生成AIですが、その反面AIが生成した画像について議論を呼ぶ場面もあります。
日本のAI開発企業RADIUS5が今年の8月にベータ版をリリースしたAIイラストメーカーmimic1)https://illustmimic.com/は、15枚~100枚程度のイラストをアップロードすることで、AIがイラストの特徴を学習し、描き手の個性を反映したイラストを生成してくれる画像生成AIサービスです。このサービスはクリエイターが自分の描いたイラストに基づいて画像生成を行うことで、イラスト制作の参考資料とすることを目的に作られたサービスになります。
ここで問題となったのは「生成画像の著作権」です。RADIUS5は利用ガイドラインで他者のイラストをアップロードすることを禁止したうえで、「作成されたイラストの権利は全てクリエイター(イラストの権利者)に帰属」としています。これに対し、「第三者のイラストをアップロードし、生成された画像を自身の著作物だとして公表するケースが起こりうる」としてSNS上で物議を醸しました。
これを受けてRADIUS5はmimicのベータ版を全機能停止、不正利用の対策を講じたうえで後日改めてベータ版2.0としてリリースすると発表しています。
実際にAIが生成する画像が悪用されたケースも存在します。
2022年9月、中部地方に大雨をもたらした台風15号について、その水害被害を訴えるTwitter上の投稿が大きな波紋を呼びました。この投稿画像には建物の形状や河川の流れなど一部不自然な点があり、投稿内容に対して疑問の声が上がっていたところ、投稿者は数時間後に投稿画像が画像生成AIによって生成された「フェイク画像」であったことを公表しています。

AI生成画像の判別ソリューション
このように、生成画像の中には「AIが生成した画像か否か」の判断が人間であっても難しいケースが存在しますが、すべての画像を人手で注意深く判別することは不可能だと言えます。
そこで、筆者は「AIが生成した画像か否かをAIに自動判別させる」ことを目的にAI生成画像の判別ソリューションを実装しました。
本ソリューションは大きく2ステップに分けて実装されています。
1ステップ目はデータセットの作成です。AIに「この画像かAI生成画像か否か」を判別させるためには、画像の特徴を学習させるための学習用データが必要になります。本ソリューションではオープンソースの画像生成AIであるStable Diffusion2)https://github.com/CompVis/stable-diffusionを用いてデータセットを作成しました。
2ステップ目はAI生成画像判別モデルの構築です。学習済みの画像認識モデルを数多く扱えるオープンソースライブラリのtimm(PyTorch Image Models)3)https://github.com/rwightman/pytorch-image-modelsをベースとし、AIが生成した画像と本物画像それぞれの特徴を学習させることでAI生成画像の判別モデルを構築します。
データセットの作成
本ソリューションでは判別モデルの学習のために、AIが生成していない本物画像と画像生成AIにより作られた生成画像を含む画像データセットが必要になります。
AIが生成していない本物画像にはMicrosoftが提供するアノテーション付きの画像データセットであるCOCO 4)https://cocodataset.org/#homeを使用しました。COCOに含まれる画像はすべてキャプション(画像の説明文)がアノテーションされており、AI画像生成時にはこのキャプションを画像生成AIの入力文として使用しています。
画像生成AIにはオープンソースの画像生成AIであるStable Diffusionを使用しました。Stable Diffusionの入力として本物画像にアノテーションされたキャプションを使用することにより、1つのキャプションに対して本物画像とAI生成画像のペアを持つデータセットを構築しています。
今回は2,000枚の本物画像とそれらの画像に付与されたキャプションに基づいて生成された2,000枚のAI生成画像で構成される4,000枚の画像を訓練データ、同様に本物画像200枚、AI生成画像200枚をテストデータとしてデータセットを構成しました。実際に作成したデータセットの一部をご紹介いたします。
①②のようにAIが高い品質で画像を生成するケースもあれば、③のように人間の指の本数や顔のパーツなど細かな特徴を表現できていない画像も見受けられました。
こうした事象への対策としてはAI生成画像に対する定量的な品質評価を行い生成画像の質を担保することなどが考えられますが、今回はStable Diffusionが生成した画像をそのままデータセットとして使用しています。
| キャプション | 本物画像 | AI生成画像 | |
|---|---|---|---|
| ① | Multiple wooden spoons are shown on a table top. |
 |
 |
| ② | Two brown teddy bears sitting on top of a wooden table. |
 |
 |
| ③ | A dated image of a newly married couple cutting a wedding cake. |
 |
 |
AI生成画像判別モデルの構築
次のステップでは作成したデータセットに基づき、AI生成画像の判別モデルの学習を行います。
生成画像判別モデルのBackboneの候補として、timmで実装されている学習済み画像認識モデルの中からEfficient Net系やRes Net系, Vision Transformer系のモデルなど合計15種類のモデルを選定しました。この各モデルについて、シンプルな線形結合の構造をHead、各種モデルをbackboneとして学習を行った際のvalidationスコアを評価し、最終的にResNet-RS5)https://arxiv.org/pdf/2103.07579v1.pdfを判別モデルのBackboneとして採用しました。
学習済み判別モデルの性能を評価するため、AI生成画像200枚, 本物画像200枚を含む400枚のテストデータに対する判別を行ったところ、93%のaccuracyでAI生成画像か否かを判別することができました。
下記画像は判別モデルが予測を誤ってしまったAI生成画像の一例です。画像生成AIの生成結果を定性評価した所感として、無機質な画像や人物が写り込んでいない画像に関してはうまく生成できている印象がありましたが、判別モデルとしてもこうした画像は判断が難しい部分のようです。
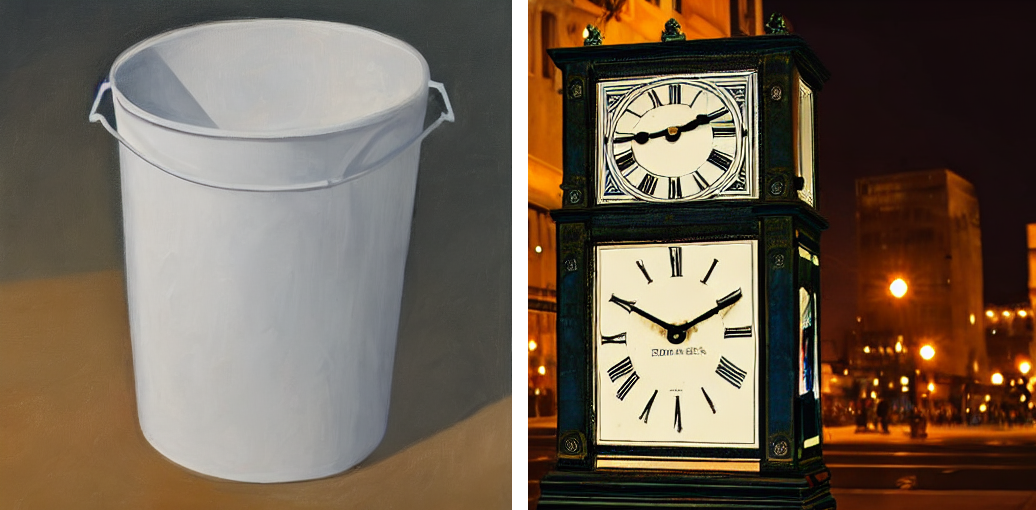
まとめ
本記事では「Stable Diffusionを用いたAI画像生成」「画像認識モデルを用いたAI生成画像と本物画像の判別モデル学習」によって、AI生成画像の判別モデルを構築しました。
「画像生成AIに得手不得手がある」「AI生成画像の生成品質に対する定量評価が難しい」などまだまだ課題はありますが、画像生成AIの奥深さと可能性を感じる良い機会となりました。2022年11月にはDALL・E 2のAPIがパブリックベータ版として提供開始されるなど、画像生成AIに触れる場は徐々に増えてきています。本記事を見て少しでも興味を持っていただけた方は、ぜひ一度その魅力に触れてみていただけると嬉しいです。
References