FIS(Fault Injection Simulator) 機能調査
こんにちは、NRIデジタルの島です。
つい先日、マネージドなカオスエンジニアリングツールである「AWS Fault Injection Simulator(以下FIS)」が利用可能になりました。
日本では東京リージョン(ap-northeast-1)で利用可能となっておりましたので、早速試してみた内容を共有させていただきたいと思います。
(今回は「AWS Elastic Kubernetes Service(以下 EKS)」に向けて試しています)
カオスエンジニアリングとは
カオスエンジニアリングとは「稼働中のシステムに対し意図的に障害を発生させシステムの弱点をあぶり出し、その弱点を改善することで実際の障害にも耐えられるようにする」というシステムの耐障害性を高める為の手法です。
Netflix社はカオスエンジニアリングを導入し、2015年に発生したAWSのリージョン全断という大規模障害を乗り切っています。
AWS大規模障害を乗り越えたNetflixが語る「障害発生ツールは変化に対応できる勇気を与えてくれる」
マイクロサービスアーキテクチャなど、クラウドネイティブ技術を使用した分散システムにおいては、従来のモノリスなシステムに比べ障害の質も高度化、複雑化してきています。
もはや「障害を発生させない」システム作りは難しく、「障害が発生した際にいかに迅速に復旧できるか」が現在の分散システムに求められる要件になってきているように思います。
クラウドネイティブ技術の主軸であるKubernetesは「障害発生時にいかに迅速に回復できるか」に重点をおいた設計になっており、セルフヒーリング機能など自動回復機能を備えておりますが、障害パターンと回復パターン(自動復旧か手動復旧かなど)を整理しておかないと実際の商用障害には耐えられないと思います。
その障害訓練に最適なアプローチの1つに、このカオスエンジニアリングがあると考えられます。
FIS
FISはAWS上の各種リソースに障害注入できるマネージドなカオスエンジニアリングツールです。
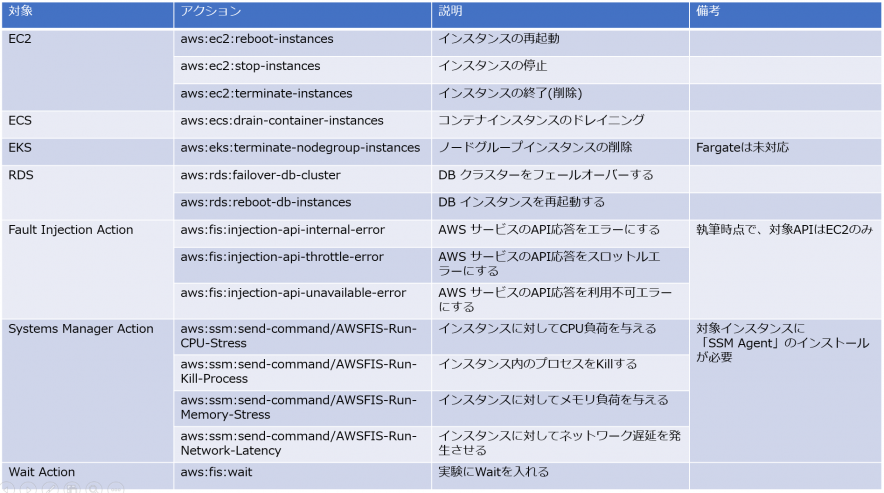
執筆時点で、実行できる主な障害は下記の通りです。
Action Refelence
基本的な実行手順は下記2ステップのみです。
公式マニュアル
①実験テンプレートの作成
②実験の実行
※執筆時点では、FISは「特定種類の障害を計画的に発生させる」というサービスになっており、この「計画した障害シナリオ」を「実験」と呼びます
※執筆時点では、AWS管理コンソールで「Fault Injection Simulator」と検索しても出てこないので、「FIS」で検索してください
今回は上記障害パターンのうち下記について、EKSに向けて実施してみました。
ノードグループ障害
・ノードグループインスタンスの削除
インスタンス障害
・インスタンスに対してCPU 負荷を与える
・インスタンスに対してネットワーク遅延を発生させる
機能検証
今回の検証イメージは下記の通りです。
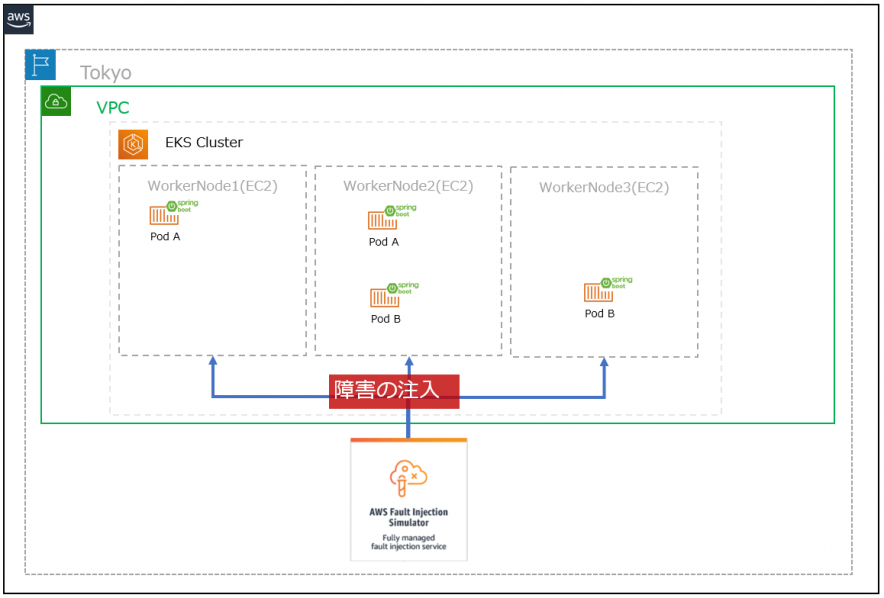
ノードグループ障害
1.EKS ノードグループインスタンスの削除
EKS ノードグループのインスタンス(ワーカーノード)を強制的に削除するシナリオです。
※ワーカーノードとは上図の通りPod等がデプロイされるサーバ(EC2)のこと
1-1. 実験テンプレートの作成
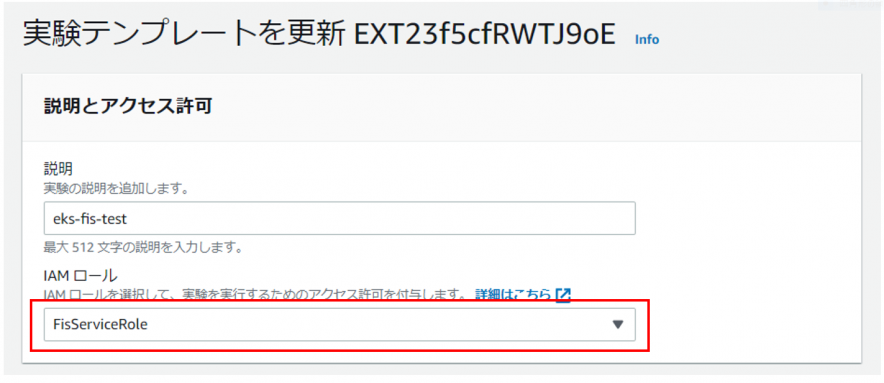
・IAM Roleの作成
FISの実行に必要なIAM Roleを作成します。
Set up IAM permissions – AWS Fault Injection Simulator
作成したRoleを実験テンプレートのIAM Roleに指定します。
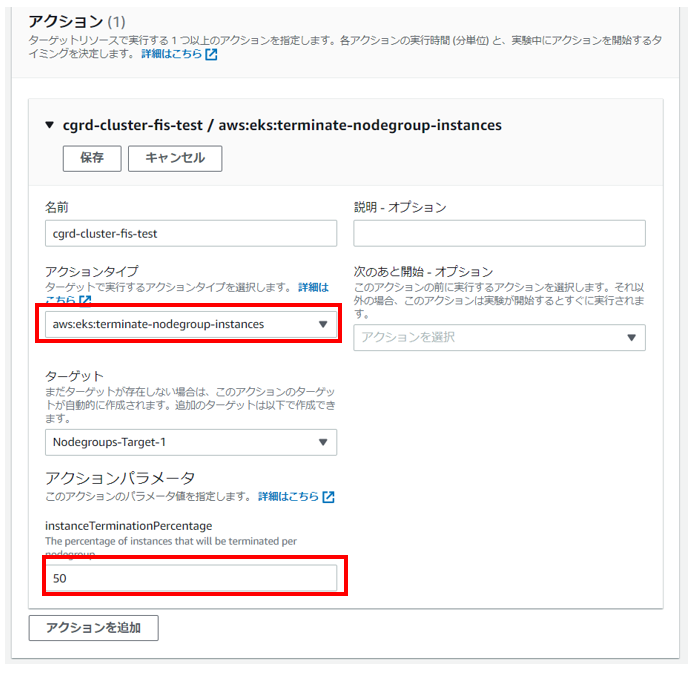
・アクションの設定
実際に実施するアクションを設定します。
※アクションタイプに「aws:eks:terminate-nodegroup-instances」を指定
※アクションパラメータ(削除するインスタンスの割合)を指定(今回は50%を指定)
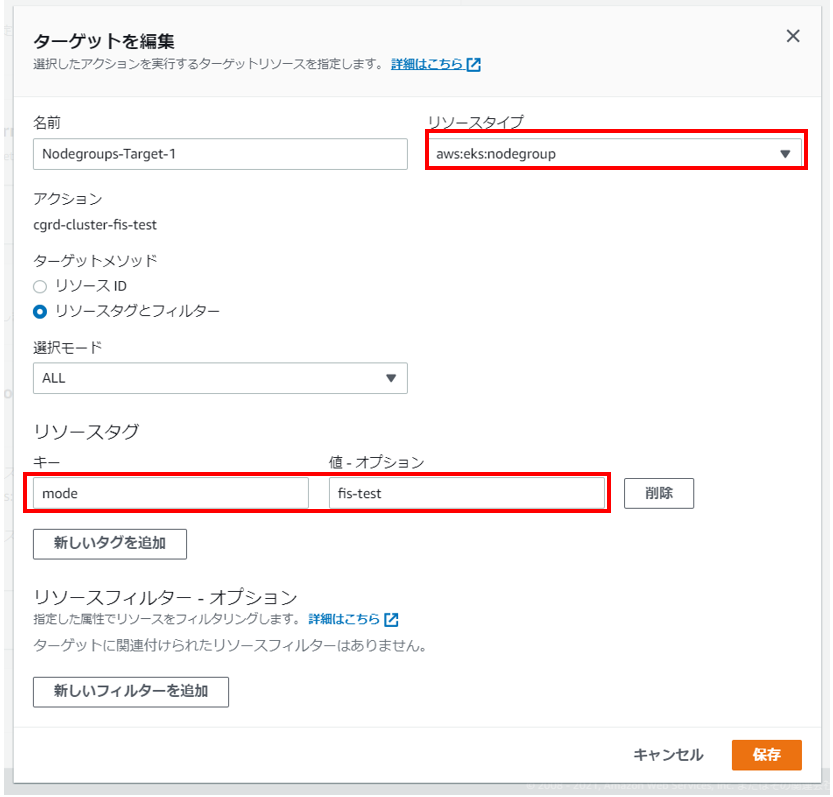
・ターゲットの設定
実験対象のターゲットリソースを指定します。
下記のリソースIDに対象が表示されなかった為、タグ(mode=fis-test)を該当のNodeGroupへ付与して実施しました。
※後日確認したらリソースIDも表示されましたので、リソースIDを指定しても問題ありません
※EKSのNodeGroupへ任意のタグを付与
※リソースタイプに「aws:eks:nodegroup」を指定
※ターゲットメソッドのリソースタグに上記「mode=fis-test」を指定
1-2. 実験の実行
実験を開始します。
下記の通り、稼働中のノードが強制停止・削除され、新たなノードが起動されます
#実験前のノードの状態 ※3つのワーカーノードが稼働中
[nri-shima@ip-10-0-6-205 ~]$ kubectl get node -o wide NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME ip-192-168-126-14.ap-northeast-1.compute.internal Ready 13d v1.18.9-eks-d1db3c 192.168.126.14 Amazon Linux 2 4.14.219-164.354.amzn2.x86_64 docker://19.3.13 ip-192-168-133-232.ap-northeast-1.compute.internal Ready 12d v1.18.9-eks-d1db3c 192.168.133.232 Amazon Linux 2 4.14.219-164.354.amzn2.x86_64 docker://19.3.13 ip-192-168-173-231.ap-northeast-1.compute.internal Ready 4h26m v1.18.9-eks-d1db3c 192.168.173.231 Amazon Linux 2 4.14.219-164.354.amzn2.x86_64 docker://19.3.13
#実験前のPodの状態 ※レプリカ数2、Affinityの設定により複数ノードに分散配置
[nri-shima@ip-10-0-6-205 ~]$ kubectl get po -n validation -o wide -w | grep eks-java eks-java-sample-59484d948-shgcs 2/2 Running 0 4h39m 192.168.128.189 ip-192-168-133-232.ap-northeast-1.compute.internal eks-java-sample-59484d948-x6qlp 2/2 Running 0 4h39m 192.168.181.128 ip-192-168-173-231.ap-northeast-1.compute.internal
#実験開始
・1ノードが停止される
[nri-shima@ip-10-0-6-205 ~]$ kubectl get node -o wide -w NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME ip-192-168-126-14.ap-northeast-1.compute.internal Ready 13d v1.18.9-eks-d1db3c 192.168.126.14 Amazon Linux 2 4.14.219-164.354.amzn2.x86_64 docker://19.3.13 ip-192-168-133-232.ap-northeast-1.compute.internal Ready 12d v1.18.9-eks-d1db3c 192.168.133.232 Amazon Linux 2 4.14.219-164.354.amzn2.x86_64 docker://19.3.13 ip-192-168-173-231.ap-northeast-1.compute.internal NotReady,SchedulingDisabled 4h30m v1.18.9-eks-d1db3c 192.168.173.231 Amazon Linux 2 4.14.219-164.354.amzn2.x86_64 docker://19.3.13 ←停止されたNode(Ready→NotReady)
・停止されたノードにデプロイされていたPodが削除される
[nri-shima@ip-10-0-6-205 ~]$ kubectl get node -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES eks-java-sample-59484d948-x6qlp 2/2 Terminating 0 4h47m 192.168.181.128 ip-192-168-173-231.ap-northeast-1.compute.internal
・EKSのセルフヒーリング機能により別ノードが起動される
[nri-shima@ip-10-0-6-205 ~]$ kubectl get node -o wide NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME ip-192-168-126-14.ap-northeast-1.compute.internal Ready 13d v1.18.9-eks-d1db3c 192.168.126.14 Amazon Linux 2 4.14.219-164.354.amzn2.x86_64 docker://19.3.13 ip-192-168-133-232.ap-northeast-1.compute.internal Ready 13d v1.18.9-eks-d1db3c 192.168.133.232 Amazon Linux 2 4.14.219-164.354.amzn2.x86_64 docker://19.3.13 ip-192-168-176-178.ap-northeast-1.compute.internal Ready 50s v1.18.9-eks-d1db3c 192.168.176.178 Amazon Linux 2 4.14.219-164.354.amzn2.x86_64 docker://19.3.13 ←新規に起動されるNode(NotReady→Ready)
・停止されたノードにのっていたPodが別ノードにデプロイされる
[nri-shima@ip-10-0-6-205 ~]$ kubectl get po -n validation -o wide -w NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES eks-java-sample-59484d948-4bx6b 0/2 Pending 0 107s ip-192-168-176-178.ap-northeast-1.compute.internal eks-java-sample-59484d948-4bx6b 0/2 Init:0/1 0 2m5s 192.168.162.38 ip-192-168-176-178.ap-northeast-1.compute.internal eks-java-sample-59484d948-4bx6b 0/2 PodInitializing 0 2m7s 192.168.162.38 ip-192-168-176-178.ap-northeast-1.compute.internal eks-java-sample-59484d948-4bx6b 1/2 Running 0 2m56s 192.168.162.38 ip-192-168-176-178.ap-northeast-1.compute.internal eks-java-sample-59484d948-4bx6b 2/2 Running 0 3m34s 192.168.162.38 ip-192-168-176-178.ap-northeast-1.compute.internal
ノードの停止・削除を再現することが出来ました。
デプロイされていたノードが停止されると、そのノードにデプロイされていた「eks-java-sample」というPodが健全な別ノードへ退避されます。
この間該当Podに対してHTTPのリクエストを送って正常性の確認をしてみました。
(固定値をJSONで返却だけの単純なAPIです)
レプリカ数2で複数ノードに分散デプロイしているにもかかわらず、一部リクエストにエラーが発生しています。
{"firstName":"Ryota","lastName":"Shima"} 200
{"firstName":"Ryota","lastName":"Shima"} 200
{"firstName":"Ryota","lastName":"Shima"} 200
{"firstName":"Ryota","lastName":"Shima"} 200
{"firstName":"Ryota","lastName":"Shima"} 200
upstream connect error or disconnect/reset before headers. reset reason: local reset 503 ←エラーが発生
upstream connect error or disconnect/reset before headers. reset reason: local reset 503 ←エラーが発生
upstream connect error or disconnect/reset before headers. reset reason: local reset 503 ←エラーが発生
upstream connect error or disconnect/reset before headers. reset reason: local reset 503 ←エラーが発生
upstream connect error or disconnect/reset before headers. reset reason: local reset 503 ←エラーが発生
upstream connect error or disconnect/reset before headers. reset reason: local reset 503 ←エラーが発生
{"firstName":"Ryota","lastName":"Shima"} 200
{"firstName":"Ryota","lastName":"Shima"} 200
upstream connect error or disconnect/reset before headers. reset reason: local reset 503 ←エラーが発生
これはノード障害時、しばらく障害ノードのPodへもリクエストが振られてしまう為と推測できます。
この結果により、障害から復旧時までの間のエラー率を下げる為には、例えばサービスメッシュ層でリトライを入れるなど、何らかの対策が必要となることがわかります。
インスタンス障害
次にAWS SystemManager(以下SSM)を利用した実験についても試してみました。
今回は下記2点について実施しております。
・インスタンスに対してCPU 負荷を与える(aws:ssm:send-command/AWSFIS-Run-CPU-Stress)
・インスタンスに対してネットワーク遅延を発生させる(aws:ssm:send-command/AWSFIS-Run-Network-Latency)
事前準備
まず、SSM関連のシナリオを実施するには、該当のノードにSSMエージェントがインストールされている必要があります。
現時点でEKSに最適化されたAMIにはプリインストールされていないようです。
SSM エージェント について – AWS Systems Manager
事前にSSMエージェントをインストールしたAMIを使用するか、DaemonSetを利用するか、方法はいくつかありますが今回はDeamonSetで導入しました。
DaemonSetは「kube-ssm-agent」使用しております。
# 現在のノード
[nri-shima@ip-10-0-6-205 ~]$ kubectl get node NAME STATUS ROLES AGE VERSION ip-192-168-126-14.ap-northeast-1.compute.internal Ready <none> 7d21h v1.18.9-eks-d1db3c ip-192-168-133-232.ap-northeast-1.compute.internal Ready <none> 7d20h v1.18.9-eks-d1db3c ip-192-168-184-16.ap-northeast-1.compute.internal Ready <none> 7d20h v1.18.9-eks-d1db3c
# DaemonSetをデプロイ
[nri-shima@ip-10-0-6-205 ~]$ kubectl apply -f daemonset.yaml [nri-shima@ip-10-0-6-205 ~]$ kubectl get po -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES ssm-agent-275dp 1/1 Running 0 23h 192.168.133.232 ip-192-168-133-232.ap-northeast-1.compute.internal <none> <none> ssm-agent-gmfxv 1/1 Running 0 23h 192.168.184.16 ip-192-168-184-16.ap-northeast-1.compute.internal <none> <none> ssm-agent-pmj95 1/1 Running 0 23h 192-168-126-14 ip-192-168-126-14.ap-northeast-1.compute.internal <none> <none>
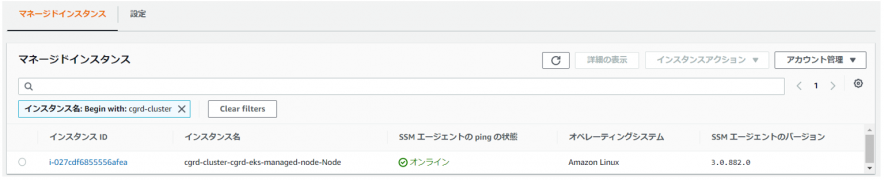
# 実験対象のノードに正常にエージェントが導入されていることを確認
1.EKS ワーカーノードへCPU負荷を与える
EKSの対象ノードにCPU負荷をかけるシナリオです。
1-1. 実験テンプレートの作成
・アクション設定
※アクションタイプに「aws:ssm:send-command/AWSFIS-Run-CPU-Stress」を指定。
※documetParametesにパラメータをJSONで記載。※1
※durationに実験の実行時間を指定。
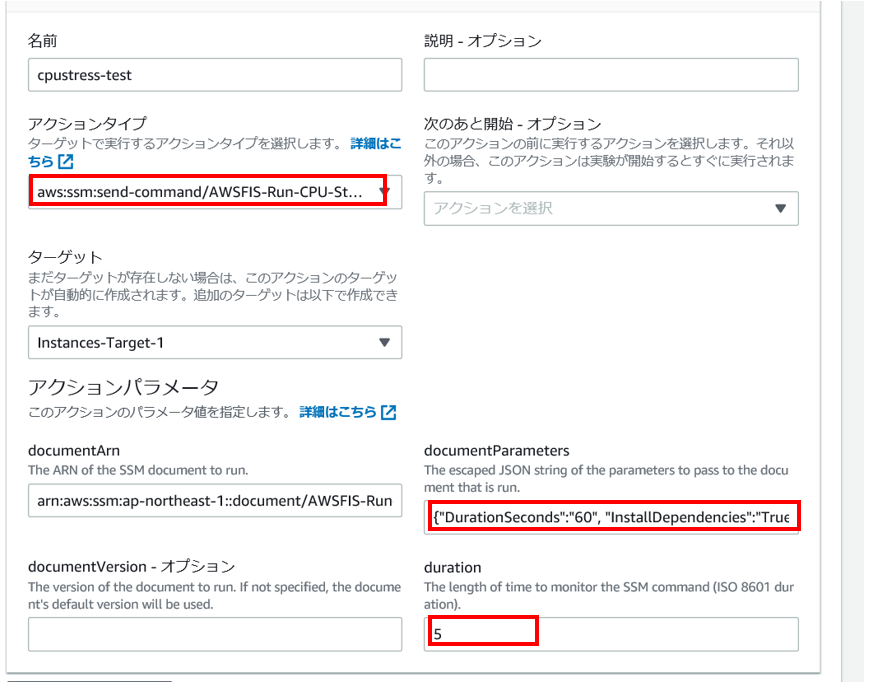
※1 パラメータ説明
| 項目 | 説明 | 必須 | デフォルト |
|---|---|---|---|
| DurationSeconds | CPU負荷を与える時間 | 〇 | – |
| CPU | 負荷を与えるCPU数 | 0(全CPU) |
・ターゲット設定
※リソースタイプに「aws:ec2:instance」を指定
※ターゲットメソッドのリソースIDに「対象となるEKSノードのインスタンスIDを指定」
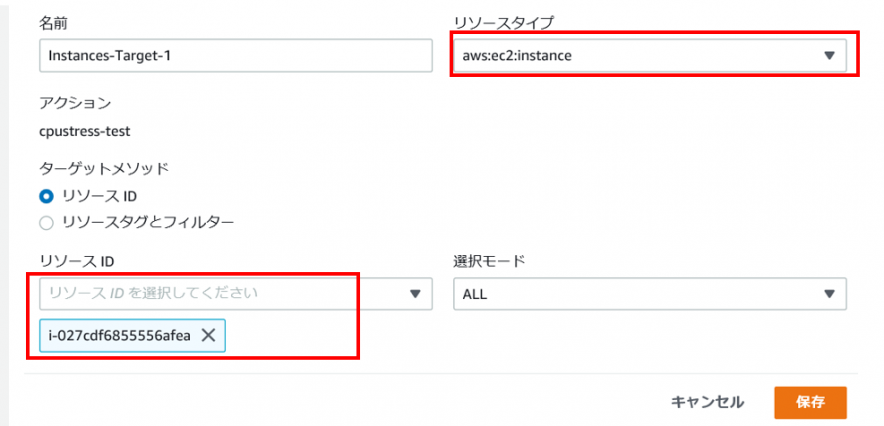
1-2. 実験の実行
実行前の状態(Grafana)です。
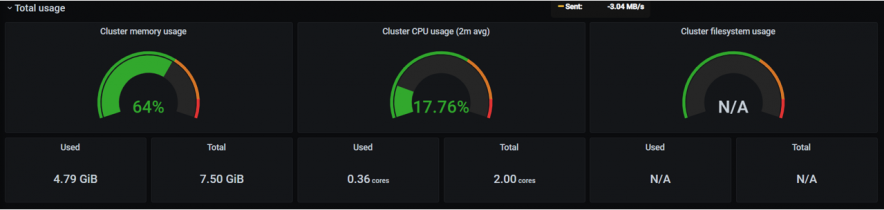
実験を開始します。
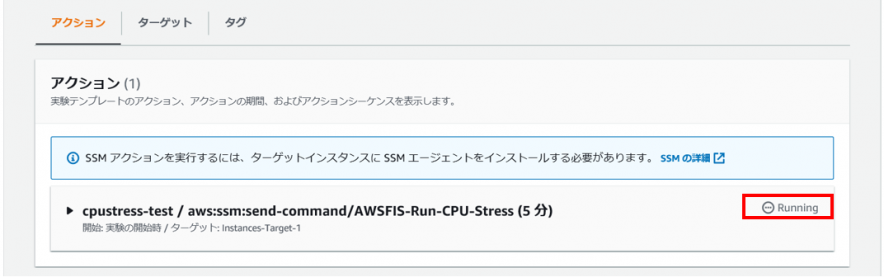
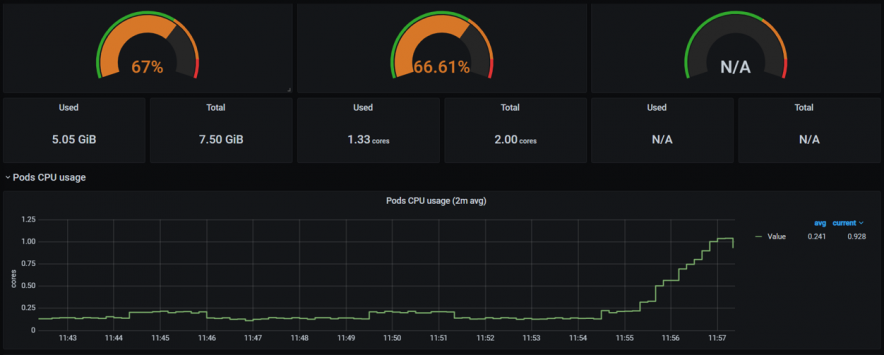
ターゲットにしたノードのCPUが高まります。
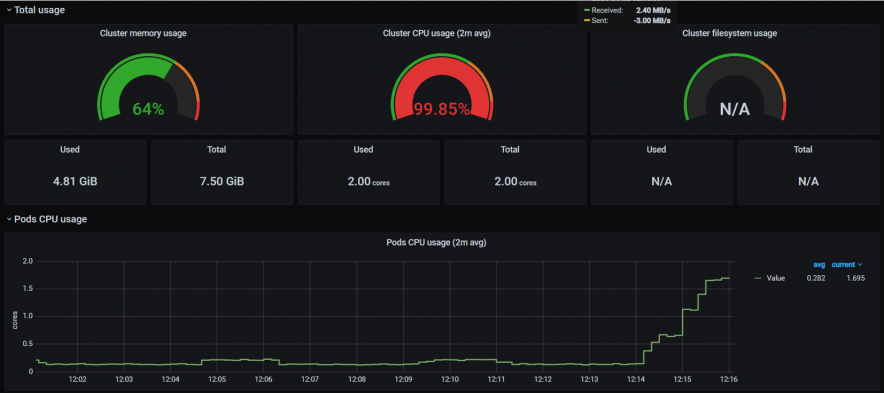
対象のノードに対し、CPU負荷を与えることが出来ました。
本状況において、各Podに対しては予めリソースリミットが設定されてますが、その範囲内でCPUリソースを取得できなくなる為にレスポンス遅延が発生する可能性が高い状況に陥っています。
k8sにはPodのヘルスチェック(Probe)機能を具備しており、ヘルスチェックNGの場合は自動的にサービスから切り離してくれます。参考:コンテナのProbe
しかしながら、EKSコントロールプレーンは該当ノードに対しては特別な対処はしてくれません。
その為、原因不明で長期化する場合などは、該当NodeをDrainし各Podを別ノードへ退避させるような運用対処も必要になってくるかと思います。
また、Drainする際はサービス提供に必要なPod数を確保する「PDB(Pod Disruption Budgets)」の考慮も必要となります。参考:Pod disruption budgets
その他、回復までの間レスポンス遅延が発生しているPodに極力トラフィックを振らないようにサービスメッシュ層でLeastConnectionでバランシングするなどの考慮も必要となるかもしれません。
なお、PodのCPU使用率があがっているのは本実験シナリオにより、ssmエージェントPodがCPU負荷を与えている為です。
[nri-shima@ip-10-0-6-205 ~]$ kubectl top pod NAME CPU(cores) MEMORY(bytes) ssm-agent-5m6sf 1635m 50Mi
※導入したDaemonSetのPodに対してCPUリソースリミットを設定していると十分なCPU負荷を与えられないので注意
2.EKS ワーカーノードにネットワーク遅延を発生させる
EKSの対象ノードにネットワーク遅延を発生させるシナリオです。
2-1. 実験テンプレートの作成
・アクション設定
※アクションタイプに「aws:ssm:send-command/AWSFIS-Run-Network-Latency」を指定。
※documetParametesにパラメータをJSONで記載。※2
※durationに実験の実行時間を指定。
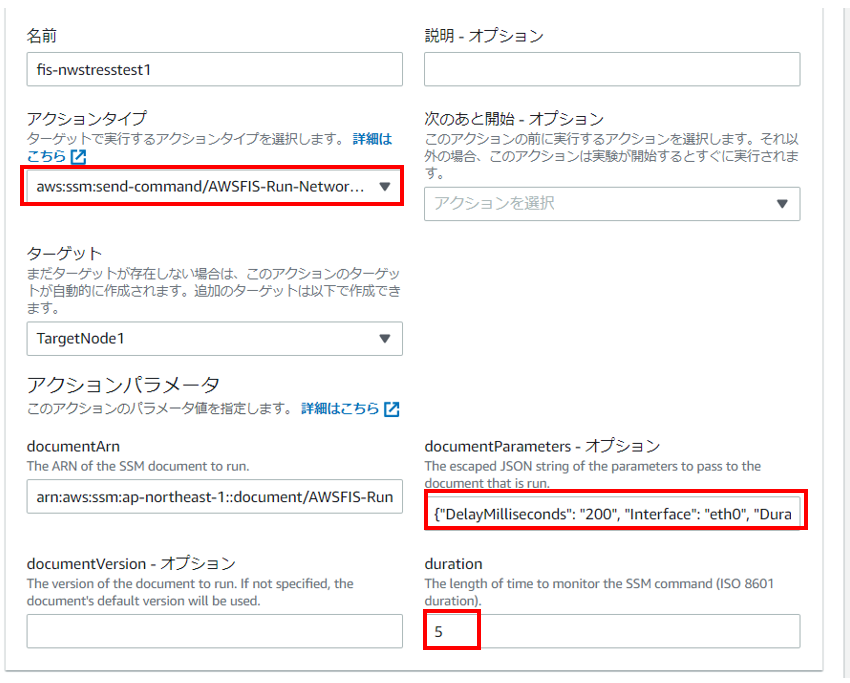
※2パラメータ説明
| 項目 | 説明 | 必須 | デフォルト |
|---|---|---|---|
| Interface | 遅延させるネットワークインターフェース | eth0 | |
| DelayMilliseconds | 遅延させる時間(ms) | 200ms | |
| DurationSeconds | 遅延を発生させる時間(s) | 〇 |
「ターゲット設定」「実験の実行」は上記「CPU負荷を与える」の項と同様の為割愛します。
2-2. 実験の実行
本実験では先ほど使用したPod(eks-java-sample)を使用します。
実験を実行する前にまず、本PodがデプロイされているノードとアサインされたIP(セカンダリIP)を確認します。
[nri-shima@ip-10-0-6-205 tool]$ kubectl get po -o wide -n validation NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES eks-java-sample-5bd9694f5d-ftkkm 3/3 Running 0 54m 192.168.154.183 ip-192-168-133-232.ap-northeast-1.compute.internal <none> <none>
「ip-192-168-133-232.ap-northeast-1.compute.internal」というノードにデプロイされ、「192.168.154.183」のセカンダリIPがアサインされていることがわかります。
該当のIPアドレスは3番目のNICに紐づいています。(管理コンソールで確認)
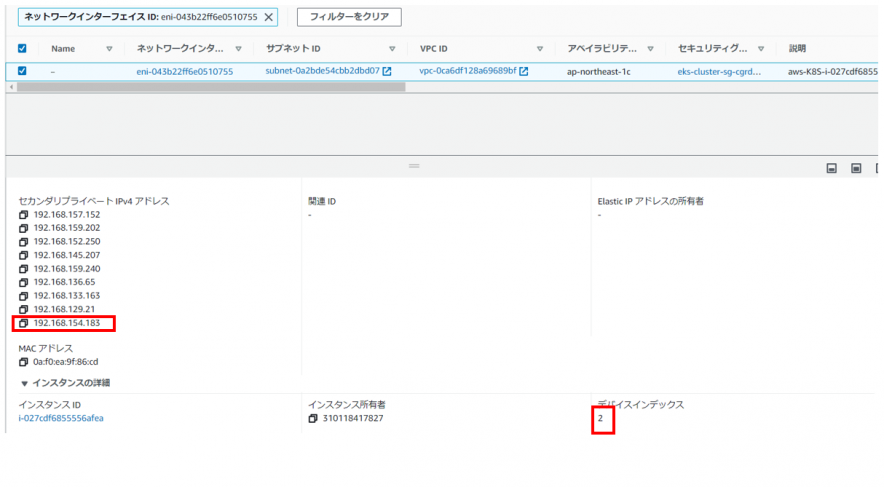
よって、実験テンプレートへ登録するパラメータは下記のようになります。
#「eth2」に対して200ms遅延させる
{"DelayMilliseconds": "200", "Interface": "eth2", "DurationSeconds":"300"}
では、実際にCurlを使用し、該当のPodをAPI呼び出ししてみます。
実行前の状態は下記です。(50ms以内でレスポンスが返ってきます)
nri-shima@ip-10-0-6-205 tool]$ time curl -v xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx.ap-northeast-1.elb.amazonaws.com/api/hello
・・・
{"firstName":"Ryota","lastName":"Shima"}
real 0m0.028s ←
user 0m0.009s
sys 0m0.000s
[nri-shima@ip-10-0-6-205 tool]$ time curl -v xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx.ap-northeast-1.elb.amazonaws.com/api/hello
・・・
{"firstName":"Ryota","lastName":"Shima"}
real 0m0.017s ←
user 0m0.006s
sys 0m0.003s
[nri-shima@ip-10-0-6-205 tool]$ time curl -v xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx.ap-northeast-1.elb.amazonaws.com/api/hello
・・・
{"firstName":"Ryota","lastName":"Shima"}
real 0m0.033s ←
user 0m0.002s
sys 0m0.008s
・・・
Kiali上でも99%タイルで50ms以内となっています。
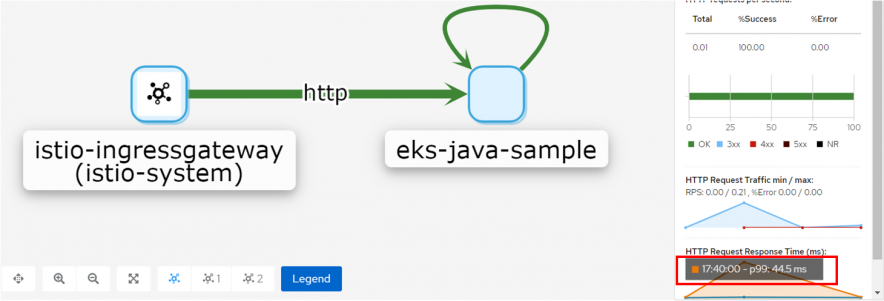
実験を開始します。
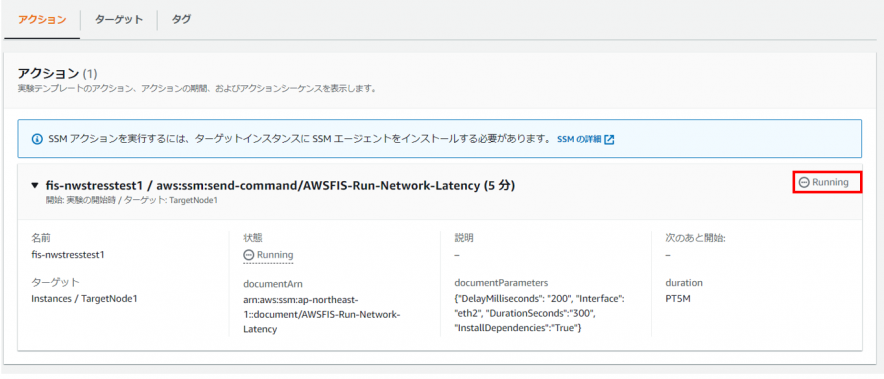
※実行が失敗する場合はSSMエージェントのログを確認し、下記のようなエラーになっている場合は該当のノードに「atd」をインストールしてください(内部のシェルで「atd」を使用している為)
SSMエージェントエラーログ
{"runtimeStatus": {
"FaultInjection": {
"status": "Failed",
"code": 1,
"name": "aws:runShellScript",
"output": "\n----------ERROR-------\n/var/lib/amazon/ssm/i-027cdf6855556afea/document/orchestration/bc82470e-19f4-4b5c-8f73-d7d10f46036e/FaultInjection/_script.sh: line 35: atd: command not found\nFailed to run atd daemon, exiting...\nfailed to run commands: exit status 1"
}
}
}
しばらくするとレスポンスが遅延し始めます。
[nri-shima@ip-10-0-6-205 tool]$ time curl -v xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx.ap-northeast-1.elb.amazonaws.com/api/hello
・・・
{"firstName":"Ryota","lastName":"Shima"}
real 0m0.225s ←遅延発生
user 0m0.010s
sys 0m0.000s
[nri-shima@ip-10-0-6-205 tool]$ time curl -v xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx.ap-northeast-1.elb.amazonaws.com/api/hello
・・・
{"firstName":"Ryota","lastName":"Shima"}
real 0m0.226s ←遅延発生
user 0m0.003s
sys 0m0.007s
[nri-shima@ip-10-0-6-205 tool]$ time curl -v xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx.ap-northeast-1.elb.amazonaws.com/api/hello
・・・
{"firstName":"Ryota","lastName":"Shima"}
real 0m0.219s ←遅延発生
user 0m0.006s
sys 0m0.004s
・・・
Kiali上でも遅延が確認できました。
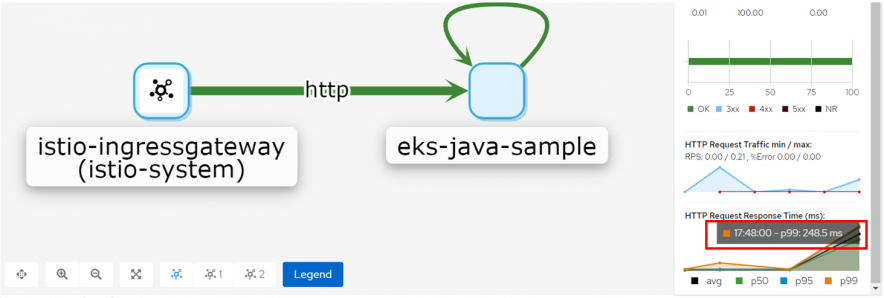
ネットワーク遅延を再現することが出来ました。
ネットワーク遅延が発生した場合もEKSコントロールプレーンは特別な対処はしてくれません。
その為、「CPU負荷を与える」シナリオと同様の対処が必要になってくるかと思います。
以上、単独の障害シナリオについていくつか試してみた結果となります。
最後に各シナリオを組み合わせて実施する方法について共有させていただきたいと思います。
複合障害シナリオ
複数の障害シナリオを複合させ実験することが可能です。
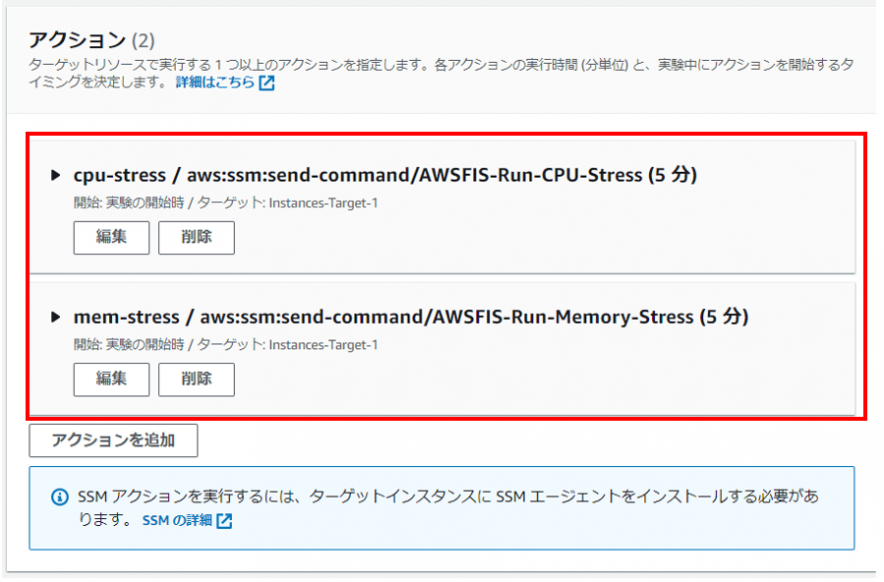
1.複数障害シナリオ同時実行
アクション設定で複数定義することで実現可能です。
※CPU負荷とメモリ負荷を同時に実行する例
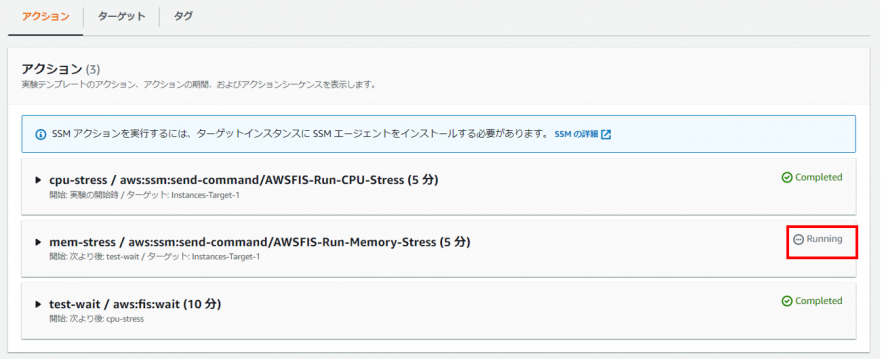
2.複数障害シナリオ順次実行
アクション設定で、下記の通り前提アクションを指定することで実現可能です。
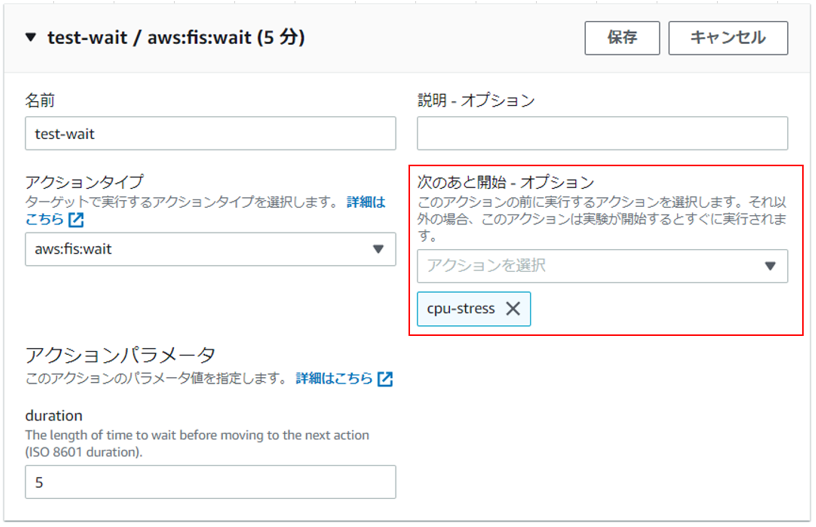
※ CPU負荷シナリオ(5分間)実行後、10分待ってメモリ負荷シナリオ(5分間)を実行する例
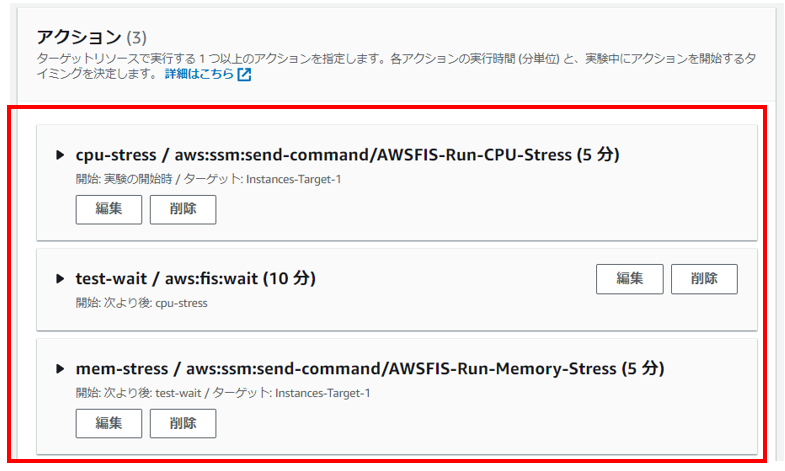
まず、CPU負荷シナリオが実行されます
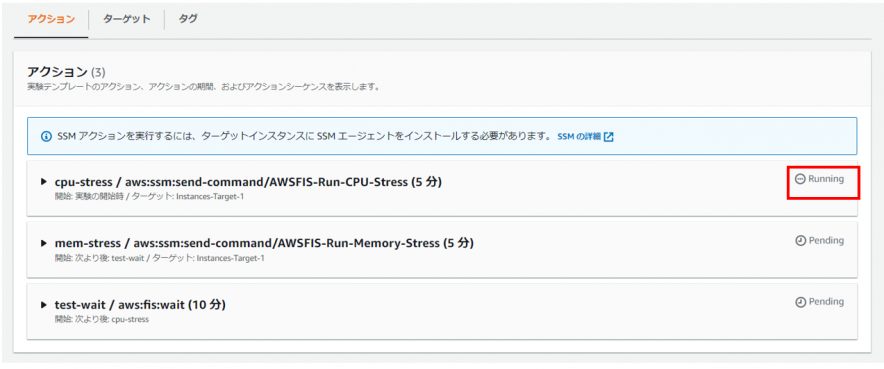
次に10分間Waitするシナリオが実行されます
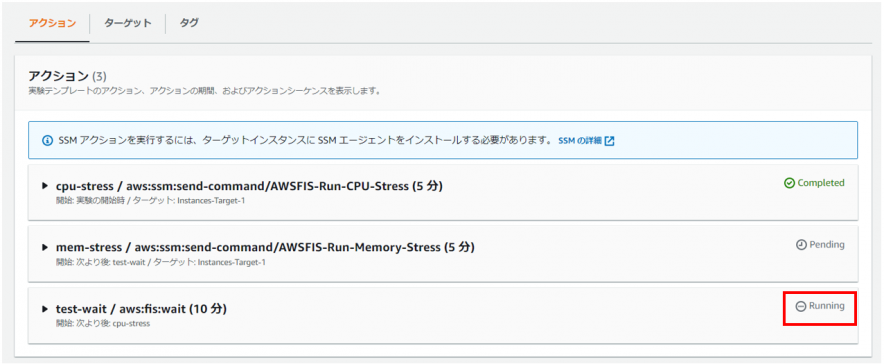
最後にメモリ負荷シナリオが実行されます
3.障害シナリオのスケジューリングやランダム実行
現時点で手動実行のみ可能で、定期実行等はサポートされてないようです。
また、複数の障害シナリオや値をランダムに組み合わせて実行するようなことは出来なそうです。
(FISのAPIを利用し自作することも可能ですが結構な工数がかかりそうです…)
さいごに
FISについて試してみましたが、対象のアクションも不足(手動でも実施できるものが多い)していたり、実行が手動のみだったり、複数障害をランダムに組み合わせて発生させることが出来なかったたりと、正直本格利用するにはまだ機能が不足している印象です。
特に著者のプロジェクトではEKSをメインに使用しているので、EKS関連の障害シナリオの充実(コントロールプレーンのコンポーネント落としたり、特定のPodに負荷かけたり…)に期待したいところです。
ただ、GUI上で簡単に障害シナリオを設定、実行できることは試験工数削減の面でもメリットあることですし、不明な点はAWSサポートに問い合わせることも出来るので、
他のカオスエンジニアリングツールと比べて導入の敷居は低いと思われます。
まだまだ出たばかりのサービスで、これから色々出来ることが増えてくると思いますので、引き続きウォッチしていきたいと思います。
以上