新機能追加でどう変わる? Amazon SageMakerを用いた機械学習ワークフロー
NRIデジタルの新米エンジニアの内山です。
re:Invent2020にて様々なサービスの公開・機能のアップデートが発表されていますね。
Anddy Jassyの基調講演やspanMachine Learning Keynoteで多く取り上げられていたSageMakerについて、調査・考察した内容を本記事にまとめていきたいと思います。
「Amazon SageMaker」とは?
Amazon SageMakerは、機械学習モデルを高速に開発・学習デプロイできる完全マネージド型の機械学習サービスです。SageMakerがローンチされた背景として、AWSは以下のように述べています。
「従来の ML 開発は複雑、高価で、繰り返しプロセスを一層困難なものにしていました。その理由は機械学習ワークフロー全体の総合ツールが存在しないためです。ツールとワークフローを一緒に結び付けて行く必要がありますが、これは時間のかかる、誤りの多いプロセスと言えます。SageMaker はこの課題を解決するために1つのツールセットで機械学習用に使用できる全コンポーネントを提供し、モデルを本番環境へ送り出すまでの時間を短縮して、手間と費用を大幅に抑えられるようにしました。」
(SageMaker公式サイト1)https://aws.amazon.com/jp/sagemaker/より引用)
上記の背景からわかるように、SageMakerでは機械学習開発でのあらゆる作業を効率化するための機能が提供されています。re:Invent 2017で発表され、年々機能が拡張されており、re:Invent2020でもさまざまな機能のアップデートが発表されました。
re:Invent 2020で発表されたSageMakerの新機能の紹介
12/1に行われたAnddy Jassyの基調講演では、以下の機能が発表されました。

続いて、12/9に行われたMachine Learning Keynoteでは以下の機能が発表されました。

またKeynoteで取り上げられませんでしたが、以下の機能も公開されました。

今回の新機能が発表されたことで、SageMakerを用いた機械学習のワークフローはどのように変化するのでしょうか?
新機能によって変わる機械学習ワークフロー
自然言語処理・コンピュータビジョン
今回の機能追加によって最も大きく変わるのは、自然言語処理やコンピュータビジョンのタスクです。これらの領域では、近年Deep Learningを用いたモデル構築が主流となっています。Deep Learningのモデル構築の際にしばしば取られるアプローチが、学習済みモデルを用いた転移学習です。転移学習は、学習済みモデルを利用せずに学習する場合に比べ、短い学習時間で高い精度を出すことができるのが利点です。今回機能追加が発表されたSageMaker JumpStartによって、自然言語処理やコンピュータビジョンのタスクにおける転移学習によるモデル構築・学習・デプロイのプロセスが非常に容易になりました。
JumpStart提供以前は、SagaMeker Stadioにてnotebookを立ち上げ、タスクに合致した学習済みモデルを用意したのちに、モデルを実装・学習し、学習したモデルをSageMakerのホスティングサービスを用いてデプロイするという流れでした。一方、今回提供が開始されたJumpStartを用いると、これらのモデルの構築・学習・デプロイのプロセスをGUI操作によって、容易に行うことができます。

図1:転移学習を行う際のワークフローの比較(NRIデジタルが作成)
モデルの構築からデプロイまでの実際の手順は、以下の3ステップです。
- SageMaker StudioのLauncherにて、JumpStartを選択する。
- モデルの選択を行う。
- TensorFlow HubやPyTorch Hubに公開されているモデルなどが選択可能。
- 自然言語処理は全42種、コンピュータビジョンは全124種の学習済みモデルが容易されている。
- 転移学習の有無の選択を行う
- 転移学習を行う場合は、独自のデータセットの格納先のS3パスを指定する。
- 転移学習せず、学習済みモデルをそのままデプロイすることも可能。
無事にデプロイが完了すると、デプロイしたリソースの使い方を示したサンプルソースがNotebook形式で自動生成されるため、その後の使い方に困ることもありません。また、リソースが不要になった場合には、ワンクリックでエンドポイントを削除できるため、無駄な料金が発生しないのも本サービスの特徴です。

図2 : JumpStartを用いたモデル構築の手順(NRIデジタルが作成)
また転移学習による独自モデルを構築するためには、当然ながら、教師データの準備が必要となります。SageMakerにはSageMaker Ground Truthという機能があり、多大な時間がかかる教師データの作成も強力にサポートしてくれます。(こちらはre:Invent2018で発表された機能です。)
Ground Truthでは、画像分類や物体検出、セグメンテーションなどのコンピュータビジョンタスク、テキスト分類や名前付きエンティティ認識などの自然言語処理タスクのためのラベル付け作業を行うことができます。自分たちで作業するだけでなく、外部ベンダーに委託することもできるようになっているのも特徴です。この機能を使うことで、データのラベル付けコストが最大70%削減される、とAWSは述べています。2)https://aws.amazon.com/jp/sagemaker/groundtruth/
テーブルデータ解析
ここまで、自然言語処理・コンピュータビジョンにフォーカスを当てて話をしてきましたが、テーブルデータの解析についても、今回アップデートされた機能を活用することで、より高速に機械学習モデルを構築することができるようになります。
テーブルデータの解析において、最も重要な要素の一つとして、データの前処理があります。前処理は処理が複雑になるケースもしばしばあり、職人芸とも言われる工程です。この工程において、今回アップデートのあったSageMaker Data Wranglerが大きな効力を発揮します。
Data WranglerもJumpStartと同様に非常に簡単に機能を使いはじめることができます。利用の流れを以下に示します。
- SageMaker StudioのLauncherにて、Data Wranglerを選択する。
- S3, Athena, Redshiftからデータをインポートする。
- Data flowに前処理工程を追加する。
- GUIで選択可能な前処理パターンは13つ。
- PythonやSQLで前処理を実装することも可能。
- 前処理のプレビュー画面もあるため、処理内容を即時確認できる。(図3参照)
- 作成した前処理工程をエクスポートする。エクスポートできるソースは以下の通り。
- 作成したData flowの実行ソース(notebookまたはpyファイル)
- SageMaker piplines, Feature Storeへの連携ソース(notebook)
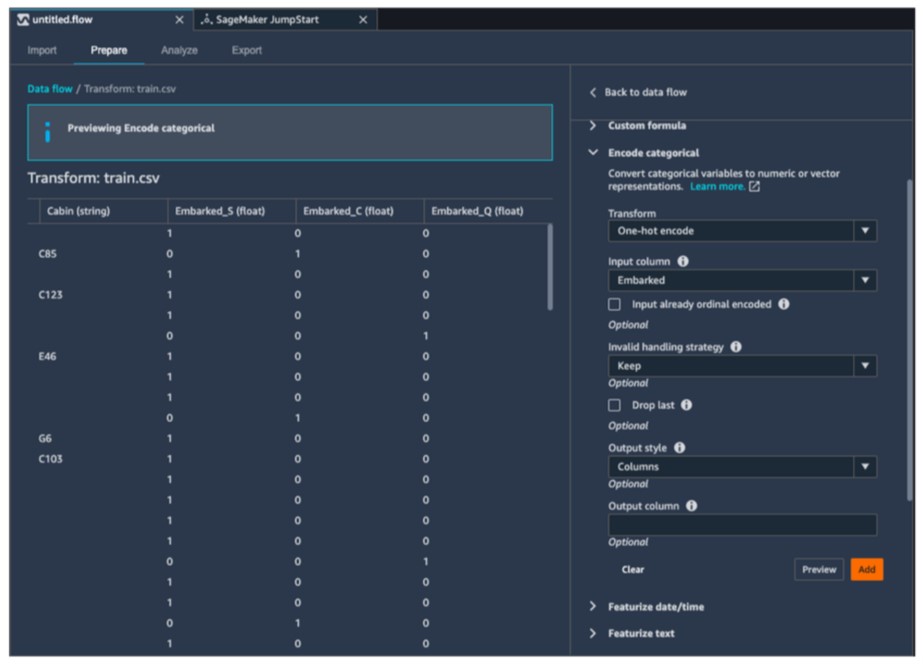
図3 : データ前処理画面のイメージ
DataWranglerでは、カテゴリ変数をonehotベクトル化する、欠損値や外れ値に対する処理をかけるなど、テーブルデータ解析時に必ず実施するようなことはGUIで操作できるようになっています。一方、複数のカラムを組み合わせて特徴量を生成したり、表記ゆれがあるデータの名寄せを行ったりするなど、GUIでは行えない前処理もあるので、そのような処理は今まで通りソースを書くことになります。全ての前処理がGUIの操作で完結するわけではないですが、必ず実施するような前処理の実装の手間が削減され、モデル構築に時間をかけることができるのはとても良いことだと感じました。
また、データの前処理から、モデル構築・パラメータチューニングまで自動で行ってくれる機能として、re:Invent2019で発表されたSageMaker AutoPilotという機能もあります。まずは素早くベンチマークとなるモデルを作りたいという場合は、AutoPilotを利用するのもおすすめです。
最後に
今回はSageMakerの大幅な機能アップデートに伴って、機械学習のワークフローがどのように変わるのかについて、考察をまとめました。本記事では言及できませんでしたが、機械学習モデルの解釈性の向上を支援するSageMaker Clarifyや、エッジデバイスでのMLモデル運用を支援するSageMaker Edge Managerなど、他にも面白そうな機能がたくさん公開されているので、それらについても知見を深めたいです。また、AWSではSageMaker以外にも数多くの機械学習系サービスが公開されているため、他サービスについても今後テックブログで公開していきたいと思います。
References
| 1. | ↑ | https://aws.amazon.com/jp/sagemaker/ |
| 2. | ↑ | https://aws.amazon.com/jp/sagemaker/groundtruth/ |