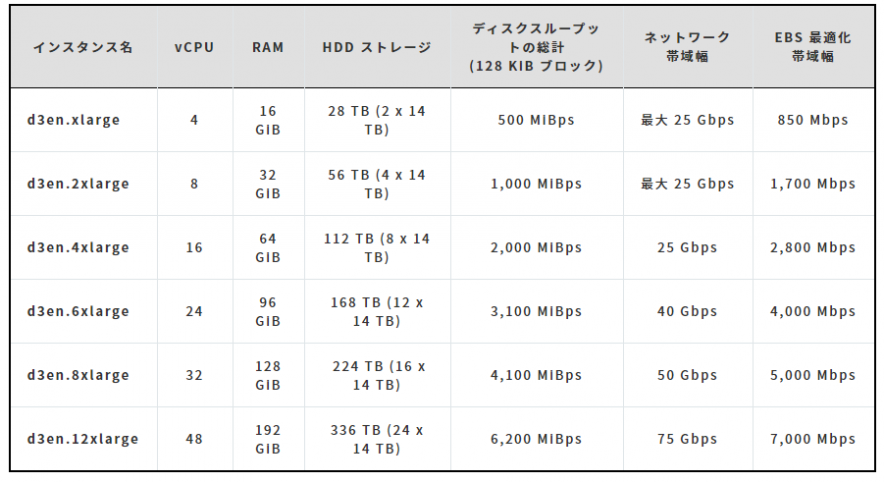
AWS re:Invent 2020 Andy Jessy Keynote 新インスタンスタイプまとめ
利用用途

表はAWS re:Invent 2020 blog よりNRIデジタルにて作成
マシンスペック

表はAWS re:Invent 2020 blog よりNRIデジタルにて作成
G4ad
AMD最新のGPUであるRadeon Pro V520 GPUと第2世代EPYCプロセッサを搭載したインスタンスであり、 特に高度なグラフィック作業やゲームストリーミングに強く、それまで用いられていたG4gnインスタンスと 比べグラフィック処理性能は40%近く、コストパフォーマンスは最大で45%改善するとのことです。 一方、小規模の機械学習推論、Nvidia関連の機能を用いるグラフィックアプリに 着手する際は既存のG4gnの方が適しているようです。それ以外のケースではまずはG4adを試すことが推奨 されています。 またDirectX 11/12、Vulkan 1.1、OpenGL 4.5 APIもサポートしています。 インスタンスサイズは以下の3つから選択できます。 ・参考:Coming Soon – Amazon EC2 G4ad Instances Featuring AMD GPUs for Graphics Workloads、Amazon Virtual Workstation (G4ad)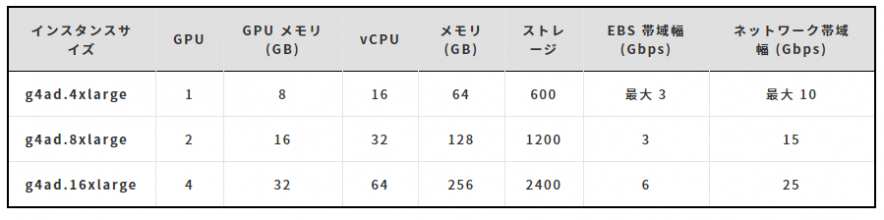
C6gn
64-bit ARM アーキテクチャを採用しており、LinuxOSの大半をサポートしているAWS Graviton2 プロセッサを搭載しており、またNitroSystem上で稼働するため、常時オン状態の 256-bit DRAM 暗号化機能等豊富なセキュリティ機能がサポートされています。 C6Gnインスタンスはネットワーク最適化に特化し、同世代のx86 ベースのネットワーク最適化インスタンス よりも最大40%高いコストパフォーマンスを出せるようです。 また、既存のC6Gと比較し、4倍のネットワーク帯域幅と 2 倍の EBS 帯域幅を提供し、 4 倍のパケット処理パフォーマンスを実現できる旨が発表されていました。 選択可能なインスタンスタイプは8つです。 ・利用可能リージョン(2020年12月10日現在):エリア:米国西部 (オレゴン)、アジアパシフィック (東京)、米国東部 (バージニア北部)、米国東部 (オハイオ)、アジアパシフィック (シンガポール)、および欧州 (フランクフルト) ・参考:Coming Soon – EC2 C6gn Instances – 100 Gbps Networking with AWS Graviton2 Processors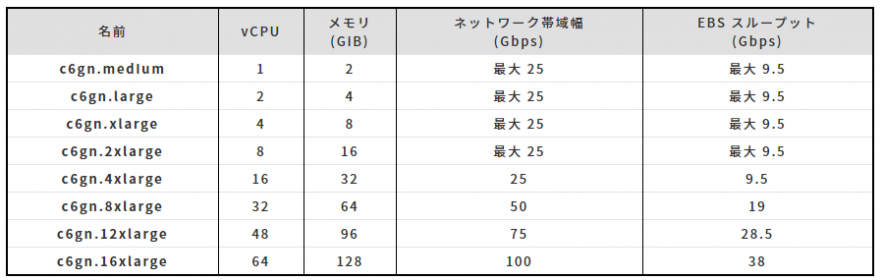
R5b
R5bインスタンスはメモリ最適化に特化したR5系インスタンスのうちAmazon Elastic Block Storeで動作します。 分散キャッシングやインメモリデータベースを用いるようなメモリの使用量が多くなるケースに向いており、 特にストレージパフォーマンスを重視する際は他のR5系インスタンスから移行することで最大3倍パフォーマンスが 向上することが見込めます。 インスタンスタイプは8種類です。 ・利用可能リージョン(2020年12月10日現在):米国西部 (オレゴン)、アジアパシフィック (東京)、米国東部 (バージニア北部)、米国東部 (オハイオ)、 アジアパシフィック (シンガポール)、および欧州 (フランクフルト) ・参考:New – Amazon EC2 R5b Instances Provide 3x Higher EBS Performance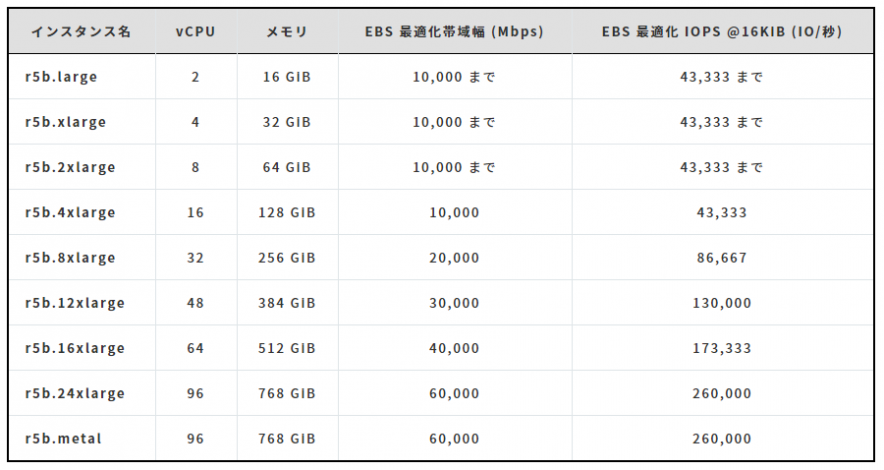
habana gaudi
Habana Labsが開発しているAIプロセッサを搭載したインスタンスタイプです。 現在の深層学習向けインスタンスと比較し、最大40%ほどコストパフォーマンスが改善しています。 主に自然言語処理や物体検知等の学習処理を行うのに適しているとのことです。 また、内部にPyTorchやTensorFlowを含んだGaudi専用のSDKも提供され、既存のGPUで動かしていた 学習モデルを簡単にとりこめるようになります。開発時にはこちらのWhitepaperが参考になりそうです。 SDKのサンプルコードも一部公開されています。
import tensorflow as tf
from demo.library_loader import load_habana_moduke
tf.compat.v1.disable_eager_execution()
load_habana_mobule()
(x_train,y_train),(x_test,y_test) = tg.keras.datasets.mnist.load_data()
x_train,x_test = x_train/255.0,x_test/255.0
model = tf.keras.models.Sequential({
tf.keras.layers.Flatten(input_shape=(28,28)),
tf.keras.layers.Dense(10),
})
loss = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)
optimizer = tf.keras.optimizers.SGD(learning_rate=0.01)
model.compile(optimizer=optimizer,loss=loss,metrics=['accuracy'])
model.fit(x_train,y_train,epochs=5,batch_size=128)
model.evaluate(x_test,y_test)
リージョンやインスタンスタイプ等、判明次第更新致します。
・対応OS: Ubuntu 18.04 and 20.04、 AWS linux2
・参考:Amazon EC2 instances powered by Habana Gaudi