AWS Glue for Spark ジョブ開発の手引き(後編)
目次
こんにちは、NRIデジタルの松村です。
本記事は「AWS Glue for Sparkジョブ開発の手引き」の後編になります。前編では、AWS上でどのようにジョブ開発を進めていくべきかという議論からスタートし、その中で AWS Glue for Sparkジョブ(以下、Sparkジョブ)に着目して、その機能や構造について簡単に説明しました。中編では、 DynamicFrame や DataFrame とはなにか、その中で DynamicFrame を使用した開発の進め方と、その技術的背景について述べてきました。
後編では、 PySpark DataFrame も活用したジョブ開発の進め方や、これらを含めた技術をどのように自身のジョブ開発で使用していくべきかという調査方法、さらにはテストについての進め方まで言及します。特に、本記事から読み始められる方で DynamicFrame や DataFrame 周りの言葉や概念が今一つよくわからない、という場合は、中編でこれらを解説していますので、もしよければご参照ください。
それでは本編をどうぞ。
開発その2:DataFrameを使用する
Glueのドキュメントにも記載されていますが、 glueContext および DynamicFrame は、あくまで PySpark の拡張になります。そのため、元より全てを DynamicFrame で処理できるようなライブラリ体系になっていません。必要に応じて PySpark の機能を使用する必要があり、この際には DataFrame へ変換して処理を進める必要があります。もちろん、DynamicFrame クラスで対応できる処理についてはそのまま処理して問題ありません。ただ、処理によっては「可能ではあるが圧倒的に面倒」なものがいくつも存在します。例えば、1列属性を追加したい、という場合に、DynamicFrameで処理しようとすると非常に面倒ですが、 DataFrame であればすぐに実現できます。このように、DynamicFrame での処理を検討した際に中々やり方がわからない場合は、スッパリと PySpark 側の機能を使うように割り切っていくことも重要でしょう。変換方法については既に述べた通りですので、ここでは PySpark のドキュメントの読み方について説明します。
なお、後述しますが、 Glue Studio で構築する場合でも PySpark ライブラリを使うGUIコンポーネントが複数存在します。これらはAWSから公式に提供されているものですが、ここからも PySpark も活用しながら開発を進めていくべきであることが分かります。
PySpark の公式ドキュメントでは、様々なコンポーネントごとに QuickStart などの説明が記載されています。まずどのようなものかを見てみたい場合はこれらのドキュメントを参考にするとよいでしょう。ただ、開発したい対象が決まっている場合は、API Reference を見るのが良いと思います。PySpark が提供する機能を、ライブラリごとにわけて紹介してくれています。Webで探した処理方法などで、クラス名が分かるが import の仕方が分からない、という時もしばしば発生します。その時はここから探してください。
実際の使い方などは多くのチートシートなどが検索すれば見つかりますので、ここではイメージをつかんでいただくために主要なものだけを紹介していきます。
まずは DataFrame クラスです。基本的な DataFrame の取り扱いについてはこのクラスに付属する関数を使えば一通りできる、と考えても問題ないでしょう。I/O以外の処理でいくと、 count(行数算出), collect(辞書オブジェクト化), show(サンプルデータの画面出力)などのユーティリティの他、select(列の選択や処理), filter(条件による行の絞り込み), withColumn(列の追加)などのデータ処理、join(列結合), agg(集合演算), union(行結合)などの集合演算系などがあります。大体、SQLで処理するようなものがある、というイメージでよいかと思います。なお、当該 DataFrame が属している SparkSession に対して直接SQLとして記述する方法もあります。
次に functions です。これは、filterなどの条件として設定するために使用するほか、数値演算や集計などの実際のロジックを記述するために使用します。SQLで言う、JOIN句は DataFrame クラスの関数ですが、その中のON xxx のような条件指定は functions を使用する、というイメージです。また、多くの function はcol 、つまり列を引数に取ります。これは、DataFrame では特定の「セル」、つまり行×列の1マスを処理するのではなく、列単位で処理をする考え方で記述するからです。例えば、苗字の列と名前の列があった時に結合して氏名の列を作る、という場合、通常のプログラムでループをするような
for row in table: row['氏名'] = row['苗字'] + row['名前']
という考え方で記述するのではなく、
df.withColumn('氏名', concat_ws('', df.苗字, df.名前))
のように、列単位で処理を記載していきます。
この考え方で処理を記述するために重要なクラスが Column です。直接使用することはあまりありませんが、特定の列を指定するような場合、例えば上述のdf.苗字 などは Column 型になります。そのため、例えば filter 関数のサンプルで書かれているような
df.age > 3
一つとっても、これはColumn > Column => Column(Boolean) であり、 True/False の入った列を表現している、というように理解する必要があります。慣れるまではかなりつらいので、様々なサンプルを見たり、実際に処理を書いてエラーを出したりしながら使いましょう。
Glue Studioを使った学習
ここまで読んで頂いて、「これは結構開発するのはハードだな」と思われている方も多いのではないでしょうか。正直、プログラミングに慣れている方でも、一般的な制御構文ベースで記述するプログラミングや、オブジェクト指向型、コールバック処理タイプなどとも違った雰囲気で戸惑うことが多いでしょう。そこで、Glue では自動生成によるサポートが様々な形で提供されています。特に、ここ数年でかなり充実してきている Glue Studio を使って、基礎となるソースを作ってみることをお勧めします。
特に強力なのは、「マネージドデータ変換ノード」で、実際のサンプルデータソースをS3などに配置し、これを読み込んで処理をする、という流れをGUI上で設定してみることで、どのような処理ができるのか、およびこれをソースコードではどのように表現するのか、ということを知ることができます。やりたい処理のイメージをした後で、
- Glue Studio で提供された変換処理でサポートされていないかを確認する
- PySpark のライブラリで実現できないかを確認する
の2アプローチで探してみると、存外見つかるのではないでしょうか。
なお、マネージドデータ変換ノードを順番に配置してコードを見るとわかりますが、以下の3種類で構成されています。
- DynamicFrame の機能をそのまま使用したもの(これが一番多い)
- PySpark の機能を使用するために一度 DataFrame へ変換するもの
- Glue Studio の独自拡張を使用するもの
この、3つ目が意外なもので、ドキュメントに記載されている、公式に提供されている awsglue 以外に、Glue Studio 用(と思われる)に拡張しているライブラリ群が存在します。恐らく、Glue Studio の Transforms で提供されている Dynamic Transform と表現されているものが対象ではないかと思います。
例えば、上記のFlattenノードを選択すると、コードビューに今まで見おぼえがないような関数が並びます。
Flatten_node1708962077003 = xxx_node1708961487327.gs_flatten()
gs_flatten() ? この状態で保存すると、Job Details の Libraries > Python library path に何やら追加されていることが分かります。
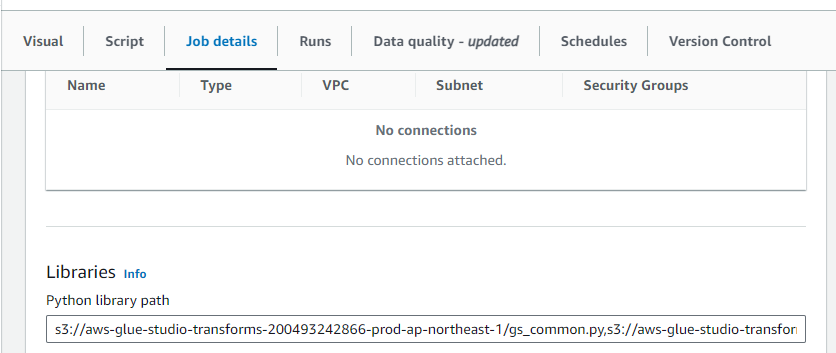
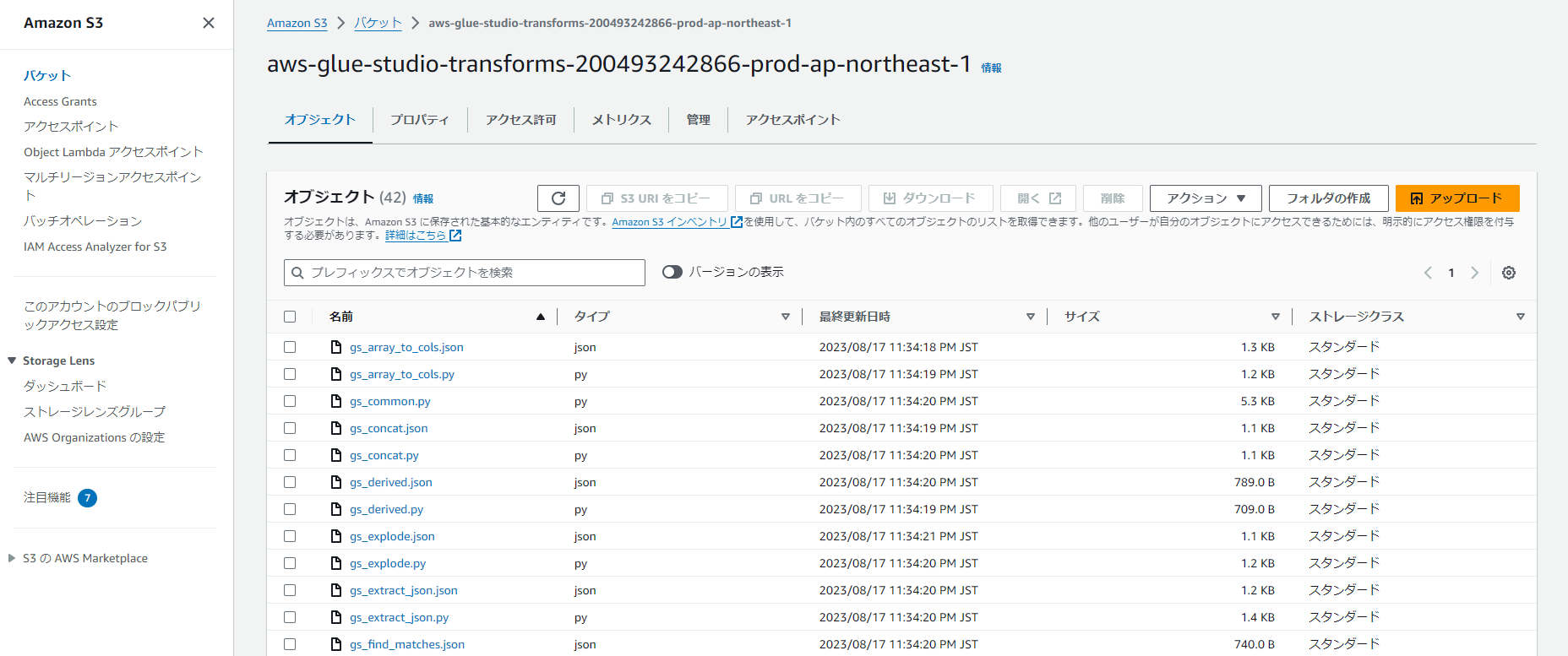
このバケット、どうやらAWSが提供している変換スクリプトが並んでいるようで、S3のマネジメントコンソールで直接指定をすることで参照することも可能になっています。
ソース自体は著作権の問題があるのでここで記述しませんが簡単に構造の説明をすると、 gs_common という共通関数があり、ここでenrich_df という関数が定義されています。これは、それぞれのモジュール、例えば上で言うgs_flatten などが読み込まれたときに、各モジュールで定義している関数を DynamicFrame, DataFrame にsetattr() 関数を使用して追加拡張する関数になっています。これにより、DynamicFrame に本来備わっていなかったはずのgs_flatten() 関数を使用できるようになっている、ということになります。これらは、もちろん Glue Studio を使わずに直接開発する場合でも利用可能です。
ここから読み取れることは3つです。
- 独自拡張を行いたい場合、拡張用モジュールをS3バケット上に配置し、 Python library path として指定することで簡単に共通関数を定義して拡張することが可能
- Glue は Lambda 等と異なり、複数のファイルを1つのパッケージにするような構成が取れず、共通関数化をどのようにするかが悩ましいという側面がありました。それほど複雑な構造でないなら、このようなファイル参照で利用できることが分かります。なお、複雑な構成の場合は whl パッケージにして読み込ませる方法もあります
- PySparkの素の関数だけではなく、tooltip のようなものを作って拡張させることもできる。便利なセットをAWSが用意してくれている
- 例えば、DataFrame 部分で記載したような複数の列を結合して新しい列を作る処理は、gs_concat として開発され、用意されています。実態は PySpark の関数群を使用した変換関数になっています。なお、DynamicFrame へ適用する際には、都度 fromDF/toDF で変換しています
- 案外、簡単な処理でもそれなりのコードを書かなければ実現できないことがある(上記の flatten など)
2024/2 現在、筆者が確認したライブラリは以下のリストになります。(筆者が開発時に検索をかけても全くヒットせずに困ったことがあるため、あえてリストを記載しておきます)
- gs_array_to_cols.py
- gs_common.py(共通関数)
- gs_concat.py
- gs_derived.py
- gs_explode.py
- gs_extract_json.py
- gs_find_matches.py
- gs_flatten.py
- gs_format_timestamp.py
- gs_lookup.py
- gs_now.py
- gs_null_rows.py
- gs_parse_json.py
- gs_pivot.py
- gs_regex_extract.py
- gs_repartition.py
- gs_sequence_id.py
- gs_split.py
- gs_to_timestamp.py
- gs_unpivot.py
- gs_uuid.py
かなり脱線しましたが、このような便利なツール群を含め、Glue Studio で処理の簡単なシミュレーションを作り、コードを確認することで処理のイメージアップやどのライブラリを使うべきかの指針を得られます。PySpark の処理は、Webで検索してもどのように書けばよいかがうまくヒットしないことも多いです。原典のライブラリを調査・探索することももちろん有効ですが、こういったサポートツールを使うことでうまく実装への道筋を見つけてみてください。
テスト
テストについても少し述べておきます。というのも、 awsglue ライブラリはローカルでテストをするという観点では結構扱いにくいからです。
awsglue のライブラリにあるREADMEでは結構ひどいことが書かれていまして、曰く
- このライブラリはGlue上でなければ動かないため、単独では動かない
- IDE上での auto-completion や、実装の理解のために使用すること
とのことです。同リポジトリ内にはbin というディレクトリもあり、こちらではインタラクティブモードで起動させることができる、という記載がされています。が、筆者はこちらの試用はしたことがないため、コメントは控えます。ただ、シェルスクリプトが数本入っているというものなので、ユニットテストでは使用できないと思われます。ちなみに、それではユニットテストをするにはどうすればよいかというと、AWSベストプラクティスのDevOps内に記載されている内容では、Glue環境を実行できるコンテナイメージをECRに入れてあるので、これを使ってテストをする、ということが推奨されています。
ただ、ローカルでテストできないというのは非常に手間がかかります。そのため、筆者が開発をする際には以下のようなパターンに分けて進めています。
- 単純な DynamicFrame を使用した変換だけで済む場合 → DynamicFrame ベースで開発し、テストはあきらめてAWS環境上での連結テストからスタートする
- 少し複雑な変換処理などを含む場合 → 基本は PySpark ベースで開発し、関数化する。実行関連部分だけを
if __name__ == '__main__'分岐内に入れ、PySpark ベースの関数はローカルにpysparkモジュールをインストールしてユニットテストフレームワークで実行する - 複数のジョブで共通的に使用したい関数がある場合 →
gs_xxパターンで見たように、Pythonファイルを分離し、そのファイル単体をモジュールとみなし、 PySpark ベースで開発してテストする
もしよければご参考ください。
おわりに
SparkジョブはETL処理を行うための非常にパワフルなツールではありますが、中々の開発難易度ではあると感じています。ただし、もちろん、うまく使うことができればAWSのデータ関連領域で様々なシステム開発を促進できることは間違いありません。本稿で少しでも多くの方が AWS Glue for Spark ジョブの開発を進められるようになることを、心より願っています。
また、本稿では記載していませんが、開発を進めていく際には他にも環境面や構成管理面など、配慮することは多くあります。 Job Atelier ではこれらのサポートを行うことも可能ですので、課題を感じられるようなことがあれば、是非ご相談ください。