LangChainによるChatGPTへの独自データ取り込み
こんにちは。NRIデジタルの大崎、佐々木です。今日は大規模言語モデルの機能拡張を効率的に実装するためのライブラリであるLangChain1)https://www.langchain.com/を用いて、Chat-GPT2)https://openai.com/chatgptに独自データを考慮させた応答をさせる実験を解説します。
概要
Chat-GPTのリリースから1年が経過した現在、様々なプラグインの登場や既存技術との組み合わせにより、その応用範囲はリリース当初から飛躍的に広がっています。特に、LangChainとGPTの組み合わせは、公開されているChat-GPTでは実現できない独自データに基づく応答を可能にします。この記事では、LangChainによって特定のデータセットやニーズに対してカスタマイズされた応答を提供できるかに焦点を当て、その技術的な解説と簡易的な実験結果を示します。
独自データに関するChatGPTの課題と解決策
今日、GPTモデルを企業内で活用する上での課題の一つに”機密性の高い独自データへのアクセス”が挙げられます。公開されているChat-GPTではウェブブラウジング機能の搭載により、学習していない最新のデータにもアクセスできるようになりました。当然ながらこの機能は公開情報に限られ、企業独自のデータへのアクセスには対応していません。
この問題に対応するためには、LangChainの活用が効果的です。LangChainを使うことで、企業は自身のセキュリティ基準を満たしながら、独自データへのアクセスを実現し、GPTモデルにこれらの情報を安全に統合することが可能になります。このようにLangChainを用いることで、企業はChat-GPTを経由してより個別化された、現実世界のデータに基づく応答を生成することができます。
RetrievalQA
LangChainのRetrievalQA機能は、質問応答(QA)システムの一つです。この機能は、質問に対する答えを見つけるために、様々な情報源からデータを収集し、検索することができます。具体的には、ウェブページ、データベース、ドキュメントなど多岐にわたるデータソースを利用し、関連情報を抽出してそれを基に回答を生成します。このプロセスは、従来のQAシステムよりもはるかに広範囲の情報にアクセスできるため、より深く正確な応答を提供することが可能です。RetrievalQAは、自然言語理解と情報検索の両方の技術を組み合わせることにより、複雑な質問に対しても効果的に対応できるように設計されています。これにより、ユーザーはより簡単かつ迅速に必要な情報を手に入れることができます。
手法説明
本記事ではLangChainのRetrievalQAを用いることで、独自データをChatGPTに取り込んで応答させてみます。手順は以下の通りです。
- ドキュメントのベクトル化:
まず、独自のデータセット内の各ドキュメントをベクトル化します。このプロセスでは、各ドキュメントのテキスト内容が機械学習モデルによって数値の配列(ベクトル)に変換されます。この変換は、ドキュメントの意味内容を数値的に表現するために行われます。 - ベクトルデータベースの作成:
ベクトル化されたドキュメントは、検索可能な形でベクトルデータベースに保存されます。このデータベースは、質問に対する最適なドキュメントを迅速に検索するためのものです。 - 質問のベクトル化:
ユーザーからの質問を受け取り、ドキュメントと同様に機械学習モデルを用いてベクトル化します。このベクトルは、質問の意味を数値的に捉えるためのものです。 - ドキュメントの検索:
質問ベクトルとベクトルデータベース内のドキュメントベクトルとを比較し、類似度に基づいて最も関連性の高いドキュメントを検索します。 - 応答の生成:
選ばれたドキュメントから情報を抽出し、それを用いて質問に対する回答を生成します。この時、抽出された情報が質問とどのように関連しているかを理解し、適切な回答を形成します。
LangChainによるデータ参照の検証
使用データ
ChatGPTにEDINET3)https://disclosure2.edinet-fsa.go.jp/WEEK0010.aspxから取得した株式会社野村総合研究所の2023年度の有価証券報告書(PDF形式)のデータを利用しました。本実験ではまず、pdfデータをテキストデータ(.txt)に変換しました。この変換は本来不要なのですが、有価証券報告書のpdfデータはUniJIS-UTF16-Hでエンコーディングされており、langchain.document_loadersのPDFloaderではサポートされていなかったためこの手順を挟むことで対処しました。また、有価証券報告書データ(.txt)の文章を適切なチャンクサイズで分割し、分割された文章ごとにベクトルを作成しました。
※ 現在GPT-4では、Bingによるウェブブラウジング機能が標準搭載されているので、本データを踏まえた応答は可能であるが、実験では本データを独自データとして実装している。
検証結果
GPT-3.5に外部データを取り入れる前後での応答結果を比較しました。
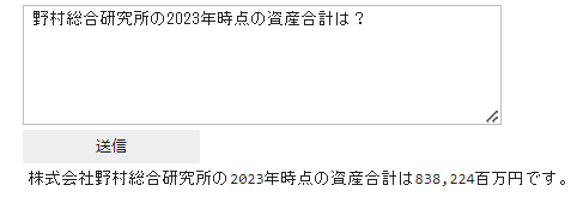
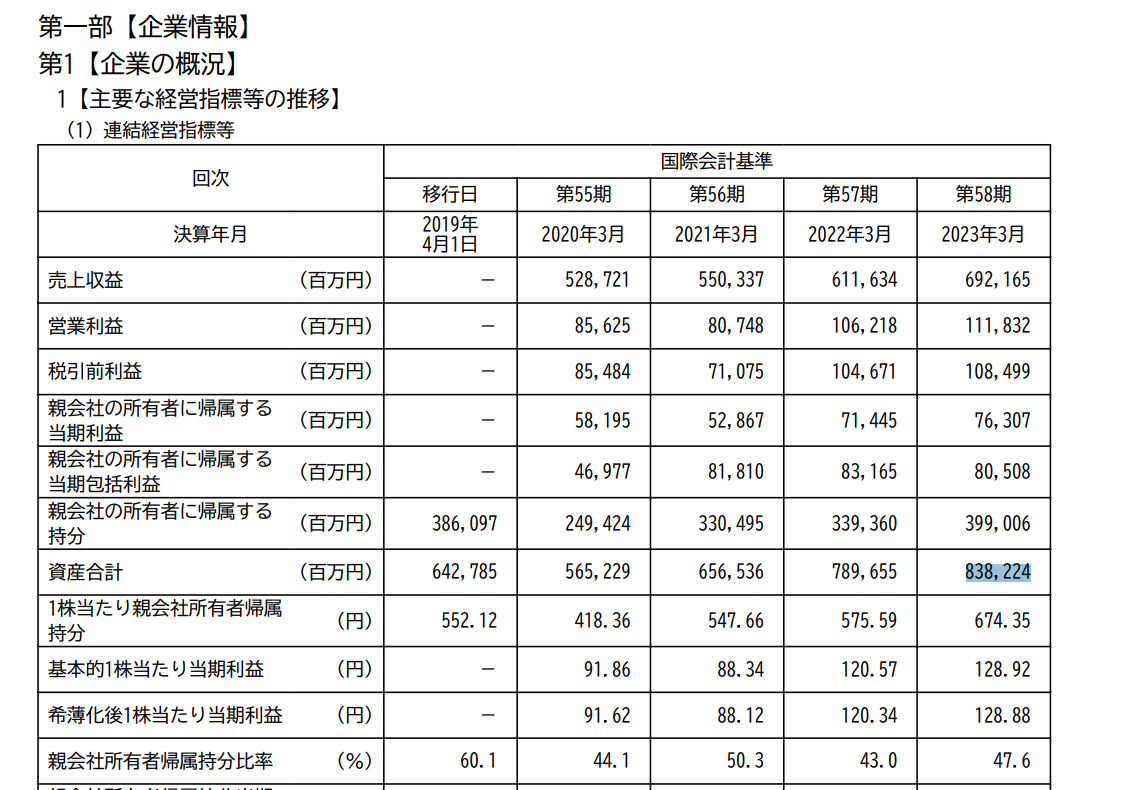
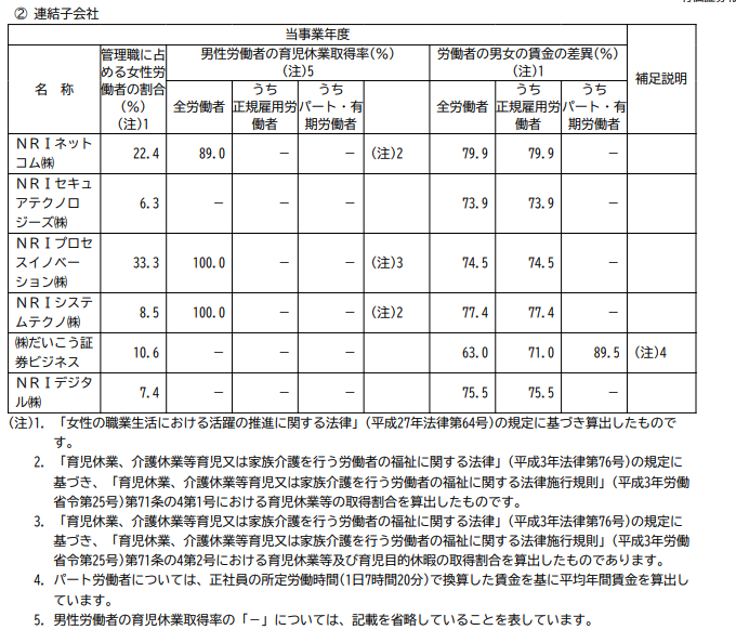
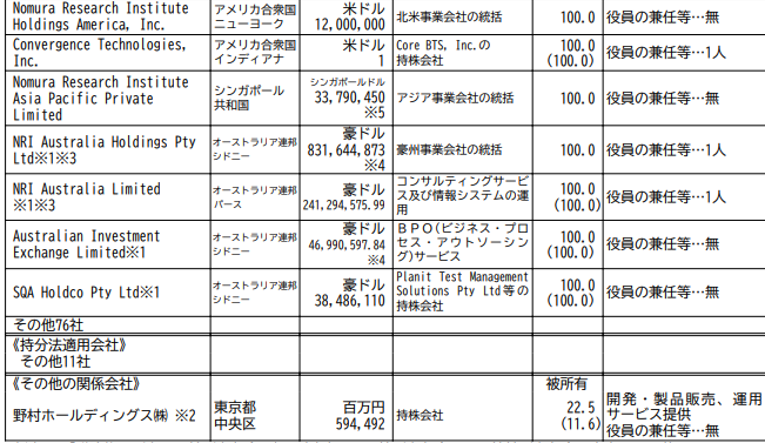
外部データ取り入れ前では正しく回答できなかったが、外部データ取り入れ後では有価証券報告書を加味した応答が返ってきました。本質問においては以下図のデータを参照したと思われます。
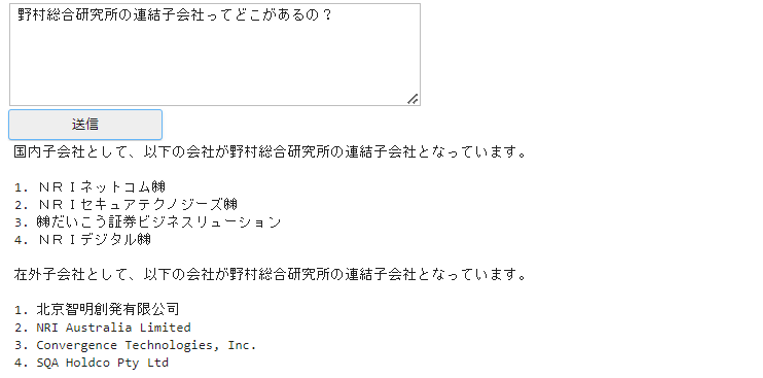
また、他にも有価証券報告書内の情報に関する質問を投げかけたところ、有価証券報告書内のデータを加味した応答結果が返されました。



おわりに
本記事では、LangChainを用いてChat-GPTに独自データを加味した応答ができることを確認しました。生成AIのビジネス活用を検討されている方に少しでも参考になれば幸いです。
References